預測模型中遺失值之選填順序研究 - 政大學術集成
54
0
0
全文
(2) 致謝詞 在政大企研所兩年時間匆匆的過了,一轉眼間就到了完成論文、口試並且撰 寫致謝詞的時刻,此刻心中充滿了無限的感激。 首先要向我的指導老師唐揆致上最誠摯的感謝,從一年多加入老師門下開始, 我們便開始培養了閱讀論文的習慣,雖然當時對自己有興趣的題目仍然不是很清 楚,但是老師每週都會給我建議和協助。由於中間去英國當交換學生論文起步得 較晚,因此也特別感謝我回國後老師讓我迅速進入論文的軌道,不斷協助我修改 實驗方法以及在口試報告上的建議。除此之外一年多來在 meeting 上老師聊到的. 政 治 大. 道理或是研究的精神也都讓我受惠良多,很榮幸可以在老師的指導下完成碩論。. 立. 感謝兩位口試委員,陳彥良老師和方郁惠老師,給予我修改碩論的建議以及. ‧ 國. 學. 點出我思考不周延之處;感謝吳家齊學長這段時間和我討論碩論並不時給予想法 和建議;謝謝我的好朋友秋芸和書庭,在這半年不時和我討論方向、修改程式、. ‧. 實作實驗到最後的論文撰寫,中間遇到了很多次的改變和瓶頸,但是在你們的協. y. Nat. sit. 助、陪伴下都一一解決了問題。. n. al. er. io. 謝謝唐門的君愷、思瑜和彥騰一起互相討論題目、相互支持和鼓勵;謝謝沛. i n U. v. 盈學姊給我們的經驗傳承和建議。感謝在身邊給予過無數幫助的人們:婉柔、珉. Ch. engchi. 君、健揚、宜豪、元莆、傑全、奕丰、李俊、柏儒、雍然和司律。謝謝政大企研 的大家和這個環境,在過程中相互切磋、互相鼓勵讓我們一路上都不孤單。最後 要感謝我的媽媽,在求學的路上給予我最大的支持和陪伴。 就像唐揆老師說過的,完成一篇碩論的過程中,會從過程中學習到許許多多 的事物,不論是尋找文獻、發想題目、設計程式、整理結果和撰寫論文,大大小 小的事都會累積成為自己的經驗,很開心終於完成了可以往下一個階段邁進。 最後,感謝碩士這兩年中的遇到的一切人事物讓我成長。 施雲天 謹致 2014.07.01 於政大商學院 i.
(3) 摘要 預測模型已經被廣泛運用在日常生活中,例如銀行信用評比、消費者行為或 是疾病的預測等等。然而不論在建構或使用預測模型的時候,我們都會在訓練資 料或是測試資料中遇到遺失值的問題,因而降低預測的表現。面對遺失值有很多 種處理方式,刪除、填補、模型建構以及機器學習都是可以使用的方法;除此之 外,直接用某個成本去取得遺失值也是一個選擇。 本研究著重的議題是用某成本去取得遺失值,並且利用決策樹(因為其在建 構時可以容納遺失值)來當作預測模型,希望可以找到用較低的成本的填值方法. 政 治 大. 達到較高的準確率。我們延續過去 Error Sampling 中 Uncertainty Score 的概念與. 立. 邏輯。提出 U-Sampling 來判斷不同特徵值的「重要性排序」。相較於過去 Error. ‧ 國. 學. Sampling 用「受試者」(row-based)的重要性來排序。U-Sampling 是根據「特徵值」 (column-based)的重要性來排序。. ‧. 我們用 8 組 UCI machine Learning Repository 的資料進行兩組實驗,分別讓. y. Nat. sit. 訓練資料以及測試資料含有一定比例的遺失值。再利用 U-Sampling、Random. er. io. Sampling 以及過去文獻所提及的 Error Sampling 作準確率和錯誤減少率的比較。. al. n. v i n Ch 較佳;而在測試資料有遺失值的情況,U-Sampling e n g c h i U則是在 87.5%的檔案表現較. 實驗結果顯示在訓練資料有遺失值的情況,U-Sampling 在 70%以上的檔案表現. 佳。. 另外,我們也研究了對於不同的遺失比例對於上述方法的效果是否有影響, 可以用來判斷哪種情況比較適用哪一種選值方法。希望透過 U-Sampling,可以 先挑選重要的特徵值來填補,用較少的遺失值取得就得到較高的準確率,也因此 可以節省處理遺失值的成本。 關鍵字:遺失值填值、決策樹分類、Uncertainty Score. ii.
(4) Abstract Predictive model has been widely utilized in our lives. For example, bank credit evaluation, consumer behavior and disease prediction, etc. While building and using a predictive model, however, we often encounter missing values in either training data or testing data, which leads to inferior prediction performance. There are several ways to deal with missing values like deletion, imputation, model construction and machine learning. Besides, we can also acquire true value for a missing value at a certain cost. In our research, we focused on the issue of acquiring missing values at certain cost, and used decision tree as a predictive model, for it can accommodate missing. 政 治 大 Sampling decides the importance of each participant method, U-Sampling. Error立. values. We used the concept in Error Sampling and Uncertainty Score to develop our. (row-based method). However, the method we propose is a column-based method that. ‧ 國. 學. can decide the importance of each attribute. Based on the rank of importance we can get an order for acquiring missing values.. ‧. y. Nat. We conducted two experiments on 8 database from UCI machine Learning. sit. Repository. In the first experiment the training data is missing, while in the second. er. io. experiment the test data is missing. We use Random Sampling, Error Sampling and. al. n. v i n U-Sampling over 70% data setsC in h Exp1 and 87.5% data e n g c h i U sets in Exp2.. U-Sampling in both experiments. The result shows superior performance on. Besides, we also took research on the impact of different missing ratios and patterns on our method so that we can choose a better method in various situations. By using U-Sampling under right circumstances, we can achieve higher performance on accuracy at lower costs. Keywords: missing value acquisition, decision tree, uncertainty score. iii.
(5) 目錄 致謝詞. ................................................................................................................. i. 摘要. ................................................................................................................ii. Abstract. .............................................................................................................. iii. 表目錄. ............................................................................................................... vi. 圖目錄. ..............................................................................................................vii. 第一章 緒論................................................................................................................ 1 第一節 研究背景................................................................................................ 1 第二節 研究動機與目的.................................................................................... 2. 政 治 大. 第三節 研究架構................................................................................................ 3 第四節 研究結果與貢獻.................................................................................... 4. 立. 第五節 論文架構................................................................................................ 4. ‧ 國. 學. 第二章. 文獻回顧........................................................................................................ 6. 第一節 遺失值.................................................................................................... 6. ‧. 2.1.1 遺失值的數量 .......................................................................................... 6 遺失值的型態 .......................................................................................... 6. sit. y. Nat. 2.1.2. 2.1.3 遺失值處理方式 ...................................................................................... 7. io. n. al. er. 第二節 決策樹的原理...................................................................................... 13. i n U. v. 第三章 研究方法...................................................................................................... 19. Ch. engchi. 第一節 研究架構.............................................................................................. 19 第二節 U-Sampling 說明 ................................................................................. 20 3.2.1 研究想法 ................................................................................................. 20 3.2.2. 程式撰寫 ................................................................................................. 22. 3.2.3. 假設與限制 ............................................................................................. 22. 第三節. U-Sampling 評估 ................................................................................. 23. 3.3.1 評估指標 ................................................................................................. 23 3.3.2. 檢驗方式 ................................................................................................. 24. 3.3.3. 和 Random Sampling、Error Sampling 的比較 ............................... 25. 3.3.4. 不同資料型態比較 ................................................................................ 25 iv.
(6) 第四章 研究結果...................................................................................................... 26 第一節 實驗數據.............................................................................................. 26 4.1.1 研究資料介紹 ........................................................................................ 26 第二節. 實驗結果.............................................................................................. 28. 4.2.1. 十折交叉驗證-training data 含有遺失值 .......................................... 28. 4.2.2. 十折交叉驗證-test data 含有遺失值 .................................................. 35. 4.2.4 不同資料型態 ........................................................................................ 40 第五章. 結論與建議.................................................................................................. 42. 第一節 結論...................................................................................................... 42 第二節 研究限制及建議.................................................................................. 43 5.2.1 5.2.2. 政 治 大 未來建議立 ................................................................................................. 43 研究限制 ................................................................................................. 43. ‧. ‧ 國. 學. 參考文獻...................................................................................................................... 44. n. er. io. sit. y. Nat. al. Ch. engchi. v. i n U. v.
(7) 表目錄 表 1.1 表 2.1 表 4.1 表 4.2 表 4.3 表 4.4 表 4.5. 機器學習類別.................................................................................. 11 常用決策樹演算法的比較.............................................................. 14 研究資料基本介紹.......................................................................... 26 實驗數據的資料型態...................................................................... 27 遺失值從 10%到填滿的平均準確率 ............................................. 29 遺失值從 30%到填滿的平均準確率 ............................................. 29 遺失值從 50%到填滿的平均準確率 ............................................. 29. 表 4.6 研究資料 10 折交互驗證的結果.................................................... 30 表 4.7 不同遺失比例的錯誤減少率.......................................................... 35 表 4.8 test data 有遺失值的平均準確率 ................................................. 36 表 4.9 比較三種方式在不同資料遺失比例下的表現............................... 41. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. vi. i n U. v.
(8) 圖目錄 圖 1.1 研究架構............................................................................................ 5 圖 2.1 遺失值的處理方式............................................................................ 8 圖 2.2 AFA 演算法架構 .............................................................................. 12 圖 2.3 Uncertainty Score 計算示意圖........................................................ 13 圖 3.1 研究架構圖...................................................................................... 19 圖 3.2 完整資料的 Uncertainty score ......................................................... 20 圖 3.3 特徵值 A1 遺失時的 Uncertainty Score .......................................... 21 圖 3.4 U Sampling 程式架構 ..................................................................... 22 圖 4.1 實驗資料的結果分布...................................................................... 27 圖 4.2 Audiology 10 折交互驗證時的學習曲線 ........................................ 31 圖 4.3 Breast tissue 10 折交互驗證時的學習曲線 .................................... 31 圖 4.4 Glass 10 折交互驗證時的學習曲線 ................................................ 32. 立. 政 治 大. ‧. ‧ 國. 學. 圖 4.5 Leaf 10 折交互驗證時的學習曲線 ................................................. 32 圖 4.6 Lung cancer 10 折交互驗證時的學習曲線 ..................................... 33 圖 4.7 Parkinsons 10 折交互驗證時的學習曲線 ....................................... 33 圖 4.8 Pima 10 折交互驗證時的學習曲線 ................................................ 34. n. al. er. io. sit. y. Nat. 圖 4.9 Zoo 10 折交互驗證時的學習曲線 .................................................. 34 圖 4.10 Audiology-10 折交叉驗證的學習曲線(測試資料有遺失值)....... 37 圖 4.11 breasttissue-10 折交叉驗證的學習曲線(測試資料有遺失值) ..... 37 圖 4.12 Glass-10 折交叉驗證的學習曲線(測試資料有遺失值)............... 38 圖 4.13 Leaf-10 折交叉驗證的學習曲線(測試資料有遺失值) ................ 38 圖 4.14 Parkinsons-10 折交叉驗證的學習曲線(測試資料有遺失值) ...... 39 圖 4.15 Pima -10 折交叉驗證的學習曲線(測試資料有遺失值) .............. 39 圖 4.16 Zoo-10 折交叉驗證的學習曲線(測試資料有遺失值) ................. 40. Ch. engchi. vii. i n U. v.
(9) 第一章 緒論 第一節. 研究背景. 預測模型的建立在許多商業智慧中都扮演重要的腳色,不論是運用歷史資料 來判斷消費者行為,或是建立模型偵測詐騙行為。而一個預測模型的品質往往跟 他的訓練資料有關 (Saar-Tsechansky, Melville, & Provost, 2009)。而在訓練資料中, 遺失值是一項常見的困難。試想一分消費者意見調查中遺失的意見、看法和答案, 或是在一份醫療檢驗報告中未完成或是未紀錄的數據,或是在銀行借貸的時候缺. 政 治 大 生很大的影響。因此,若能找到有效處理遺失值方法,在未來資料處理上將會使 立. 少顧客的信用資料所導致訓練資料不完整,都可以對其所建立的模型預測能力產. 預測模型的建立有很大的助益。. ‧ 國. 學. 在處理訓練資料的遺失值時,可以使用刪除法,包括成批或成對刪除法,也. ‧. 可以使用現有的資料對其做預測,例如平均數填補、回歸填補、最大可能性法等. sit. y. Nat. 等。其計算成本和效果各有優缺點 (Schlomer, Bauman, & Card, 2010)。使用刪除. io. er. 法可以節省許多成本,但是相對的可能大幅減低樣本數量,也可能無法比較每個 不同分析方式,因為其刪除的訓練資料可能不同。另外其他填補式的方法則試著. n. al. Ch. i n U. v. 去模擬整體資料的各種參數(平均數、變異數),既然是預測就會產生誤差,因此. engchi. 有些太單純的方式,例如平均數填補法被很多專家反對 (Allison, 2001;Bennett D. A., 2001;Graham, 2003;Pallant, 2007)。 另一種作法是實際去取得遺失值,則資料就會變得更為完整。但是此種方法 將會花費額外的成本,若是要取得全部的遺失值則可能產生無法負擔的高成本 (Melville, Saar-Tsechansky, Provost, & Mooney, 2004)。因此,若是要採用這個方法, 就必須在實際花成本取得遺失值時用對的方法去挑選對於整個模型的預測能力 貢獻比較大的特徵值。這也是本研究探討的主題,希望可能找出節省成本的方式 去取得需要的遺失值,來增加整體模型的預測能力。. 1.
(10) 第二節. 研究動機與目的. 很多時候預測模型的工作涵蓋了許多遺失值,而這些遺失值是可以用成本 去取得他的,但如果想要取得所有的遺失值,其成本可能高到難以負荷 (Melville et al., 2004)。但是在建立分類模型時,如果訓練資料含有遺失值會導致其表現變 差,如果直接忽略遺失值,更可能使模型的預測能力降低 (Quinlan, 1989)。 在很多預測模型的研究中關鍵的資料並不完整,但可以用成本去取得他。但 傳統上「資訊取得」和「建立模型」是兩個獨立的議題。也就是說蒐集資料時並 沒有考慮到預測模型想達到的目標。不過這兩者應該是要具有相關性,因為新取. 政 治 大. 得的資訊或影響到從訓練資料建立的模型,而且這可以用來幫助決定取得哪一些. 立. 新資訊會是最有用的 (Simon & Lea, 1974)。. ‧ 國. 學. AFA(Active Feature Acquisition)是關於選值順序的相關研究,其背後的原理. ‧. 是依照成本/效率的考量,逐步選出要取得的特徵值 (Saar-Tsechansky, Melville, & Provost, 2009)。因此,本研究延續 AFA 的概念,目的在於取得新資訊的同時,. Nat. sit. y. 觀察其對預測模型的影響,知道其影響力大小的順序之後便可以先取得影響力較. er. io. 大的資訊,如此一來便可以用較低的成本,獲得資訊含量較高的資料。 在提出. al. v. n. 方法後,將透過和過去文獻中提出的方法比較,測試其在準確率及錯誤減少率上. i n C 是否有進步,並分析不同的資料型態一窺其適用性。 hengchi U 本研究的研究目的整理如下:. 1.在一份訓練資料中,判斷每個特徵值的重要性順序來決定填值順序 2.比較現有的填值順序方法與本研究的優缺點 3.試驗本方法在不同的資料遺失型態中的適用性. 2.
(11) 第三節. 研究架構. 在本研究中,我們提出 Uncertainty Score(不確定性值)的架構來判斷在一組 資料中哪一些特徵值對於預測結果影響較大,並且把影響較大的特徵值定義為較 重要的。之後使用 8 組美國 UCI Machine Learning Repository 網站提供的公開資 料集作為測試資料。 我們使用資料包含類別型、數值型、混合型等數據形式,其中以疾病、生物 體檢測為主要的研究對象。因為疾病確認、生物體檢測通常需要有高成本、高複 雜度的辨識程序,可能是昂貴的實驗過程或是測試儀器。所以當資料有遺失值時,. 政 治 大. 選定每個特徵值的重要性會嚴重的影響成本的大小,因此在本研究中填值的時候. 立. 是一次只填某個受試者的某個特徵值,而非一次就填完所有該受試者的所有特徵. ‧ 國. 學. 值。. ‧. 過去不論是 Random sampling 或是 Error sampling 都不需要原始的完整資料, 隨時都可以應用在決策樹上,而本研究中提出的 U-sampling 需要先有一小筆完. Nat. sit. y. 整的訓練資料來判斷不同特徵值的重要性,因此我們將會採用一開始完整的資料. n. al. er. io. 並且用人工的方式把部分資料用遺失值來取代。. Ch. i n U. v. 本研究的架構共分成三大部分:「研究動機及目的及資料挑選」、「建立特徵. engchi. 值的重要順序」、「填值方式的測試與比較」以及「不同遺失值型態的影響」。在 第一部分中先釐清資料來源的類型範疇,第二部分「建立遺失值選值的方式」根 據過往的方法提出一套新的特徵值重要性排列方式,並依此決定填值順序,第三 部分「填值方式的測試與比較」,利用 8 組生物檢驗、疾病判斷相關數據與先前 文獻所提出的方式進行比較,第四部分「不同遺失值型態的影響」用不同的遺失 值型態當作測試資料來觀察是否對於實驗的結果有影響。. 3.
(12) 第四節. 研究結果與貢獻. 本研究中提出的 U Sampling 架構期望能從過去的歷史資料歸納出各個特徵 值的重要性順序,並且依照這個順序來填補遺失值,並且同時建立決策樹模型來 預測資料的分類結果,最後在觀察不同資料型態的遺失值是否對於實驗結果有影 響。其主要貢獻如下 1. 提供一套新的架構衡量每個特徵值分類結果的重要性排序。 2. U-sampling 在 UCI 地 8 組資料中的準確率表現較 Random Sampling 以及. 政 治 大 可觀察在不同遺失比例下不同方法的適用性。U-sampling 應用在遺失值 立 Error Sampling 為佳,並且我們把遺失比例從 0.1 到 0.7 分成四組比較,. 的取得上可以以較低的成本達到相同的準確率。. ‧ 國. 學. 3. 分析和比較不同遺失值資料型態對於結果的影響,可以提供在不同資料. sit. y. Nat. er. 論文架構. io. 第五節. ‧. 形態下各個模型的表現差異及優缺點。. al. n. v i n 本論文將分成五個章節,第一章介紹本研究的動機與目的,第二章整理研究 Ch engchi U 相關的文獻資料,建立本研究的基礎,第三章則說明本研究提出的填值方法、程 式架構,第四章將呈現研究的結果,最後,在第五章則整理本研究的結論,並提 出研究限制與相關建議,以供後續研究參考。. 4.
(13) 研究動機與目的. 文獻回顧. 設計遺失值選填方法. 不同填補方式結果比較. 學. ‧ 國. 立. 政 治 大. sit. y. ‧. io. n. al. er. Nat. 不同遺失值型態對結果的影響. Ch. engchi. i n U. v. 結論與貢獻/未來研究方向. 圖 1.1 研究架構. 5.
(14) 第二章 文獻回顧 本研究欲探討遺失值填補順序的相關議題,並且提出一個新的方法,使得填 值後的訓練模型可以達到更精準的預測結果,因此,本章將先從遺失值的特性與 處理方式開始研討,並且針對現有的機器學習領域、模型建立方法有所了解,最 後整理相關 AFA(active feature-acquisition)的理論與方法,找出目前還可以研討的 方向與議題。. 第一節. 遺失值. 治 政 大 身的屬性、遺失值的處理方式,並且對於現在使用機器學習的填值方式有進一步 立 的認識,因此,以下將針對上述所提到的主題逐一整理文獻。. 欲在有遺失值的資料集中建立一個準確率高的模型,我們必須了解遺失值本. ‧ 國. 學. 2.1.1 遺失值的數量. ‧. 在不同研究中對於遺失值的數量認知標準不盡相同,Schafer (1999)提到超過. y. Nat. sit. 5%的遺失值就必須要被處理,Bennett (2001)則認為 10%是臨界值,甚至也有人. al. er. io. 認為 20%以上才需要被處理(Peng, 2006)。Schlomer et al.(2010)提出了新的觀點,. v. n. 認為遺失值的數量並沒有一定的標準,而是要看兩種資料特性決定遺失值是否應 該被正視。. Ch. engchi. i n U. 1. 是否已經有足夠的資料量能在統計上達到實驗想驗證的效果,這也是為 什麼很多研究中偏向「刪除」遺失值。 2. 遺失值的型態,遺失值的之間是否相關,或是完全隨機遺失,這在下一 小節會有詳細介紹。. 2.1.2 遺失值的型態 除了遺失值的數量和來源之外,在研究時也常常需要考慮到遺失值的型態, 這一小節將會介紹三種遺失值型態。 (Schlomer et al., 2010) 6.
(15) 1.. 完全隨機遺失(MCAR, missing completely at random) 遺失值的出現與否完全不受任何因素的影響,單純為隨機發生並且和任何研. 究內的變數不相關;完全隨機的遺失隱含著任何該資料檔案的子集合和整個檔案 的遺失型態應該相同。在實務上很難有方法去證明一個資料集合是完全隨機遺失, 另外也有人將此種型態列為隨機遺失(MAR)的一種特例(下面即將說明)。. 2.. 隨機遺失(MAR, missing at random) 這個名稱在某種程度上會誤導讀者,因為 MAR 的型態並不是隨機分布的,. 至少不是完全隨機。MAR 的資料遺失與否不受其他變數的影響,而是與被觀察. 政 治 大. 的結果有關,例如服務業的人比較不願意回報自身的收入情況。. 立. 非隨機遺失(NMAR ,Not missing at random). ‧ 國. 學. 3.. ‧. 這種型態的遺失值又稱為 non-ignorable nonresponse,也就是不可以被忽略。 非隨機因素產生的遺失值與其他遺失值有關,但與觀察到的部分無關。可能是問. Nat. sit. y. 題本身太過尖銳、受訪者刻意不填答或問卷太過冗長而隨便跳題亂答。在判斷為. al. er. io. 什麼受試者會產生這個遺失值時會遇到困難,因為資料本身並沒有遺失值的資料,. v. n. 所以大部分的時候原因的探討會變成邏輯上的討論,例如高收入者可能因為不想. Ch. 被別人知道自己的高收入而鮮少填答收入情況。. engchi. i n U. 2.1.3 遺失值處理方式 遺失值的處理方式有非常多種(見圖 2.1),主要分成刪去法、插補法、模型 建構法以及機器學習法四大類,以下我們將會用範例分別說明各種方法。. 7.
(16) 遺失值處 理. 刪去法. 模型建構 法. 插補法. 機器學習 法. 圖 2.1 遺失值的處理方式 資料來源: Pedro J. Garcı´a-Laencina Æ Jose´-Luis Sancho-Go´mez Æ (2010). 1.. 政 治 大. 刪除法(deletion). 立. 一般而言,利用剩餘完整的資料來做分析,然而這種方法往往造成有用的訊. ‧ 國. 學. 息無法突顯出來,導致分析結果不佳。刪除的方式有以下幾種:. ‧. (1) 成批刪除法(list-wise). y. Nat. sit. 收集的資料當中若有一變數為遺失值,則將整筆資料刪除。其優點是很簡單. n. al. er. io. 並且適用於不同資料。但當很多資料遺失值時,會降低統計上的效力;再者,若. i n U. v. 資料並不屬於完全隨機遺失,子集合無法代表整體資料,也會產生偏差。. Ch. (2) 成對刪除法(pair-wise). engchi. 將遺失值保留,若是某種分析方式有使用到在予以刪除。其優點是把能用的 資料全數用盡,但是此方法會使不同分析的樣本量不同,進而無法互相比較。通 常在樣本量很大、遺失值很少、變數之間不是高度相關的時候較適合本方法。. 2.. 插補法(imputation) 插補法(imputation)為一種常見的遺失值處理方式,藉由其他輔助變數所提供. 的資訊,用一個(組)相近於遺失值的數值取代遺失值。插補方式又分為隨機插補 8.
(17) (Stochastic )和非隨機插補(Stochastic imputation)。在這一節當中將介紹各種不同 的插補方式。 (1) 非隨機插補法(Non-stochastic Imputation) . 平均數插補(Mean Substitution ). 只要是遺失值都用平均數來代替,該變數的平均值會保持不變,而其他的統 計量例如標準差和相關係數等也不會受很大的影響。特別適合用在完全隨機遺失 (MCAR)的型態。但許多專家反對這個方法(Allison, 2001; Bennett, 2001; Graham et al., 2003; Pallant, 2007),因為會造成變異量低估的問題,也無法應用在非數值 或是 MAR、NMAR 的資料上。. 立. ‧ 國. 迴歸插補(Regression Substitution). 學. . 政 治 大. 迴歸插補法用現有的資料產生迴歸式,用現有的資料去預測遺失值。迴歸法. ‧. 的優點為對同一變數不同觀察值的遺失值考量了變數間的關聯性,而雖然對於平 均不會產生偏差,但是會產生有偏差的變異數和共變異數。. er. io. al. sit. y. Nat. (2) 隨機插補法(Stochastic Imputation). v i n 資料無關的輔助資料(auxiliaryC variables)來預測遺失值 h e n g c h i U 。例如關於遺失值型態的資 n. 隨機插補法和前面的插補法最大的不同於,在這個方法中會使用和原本分析. 料,或是引入其他和遺失值有關的資料(但不被包括在分析資料中)。 . 隨機回歸插補(Stochastic Regression Substitution). 這個方法和迴歸法相似,但是因為其用其他輔助變數,這些變數的平均為零 但是卻也有變異數,因此相較於單純的迴歸插補法,可以改善變異數被降低的問 題。. 9.
(18) (3)多重插補法(Multiple imputation) 這個方法是 EM 的延伸,因為其關係到不同組的填補資料集合還有他們之前 的關聯性。首先是建立幾組填補資料集合,分別使用之後紀錄各自的每種參數, 並且用這些參數的平均作為最後填補資料集合的參數。考量到不同插補方法的隨 機波動,MI 提供了較為精準的標準差因而提供比較精準的推測結果。. 3. 模型建構法 (1) 預期最大化 Expectation maximization (EM) 這個方法是 Maximum Likelihood 的其中一種,ML 的方法在統計上顯著比刪 除、隨機回歸及其他非隨機插補法。ML 就是根據已觀察到的樣本,以使這個母. 政 治 大 求出使概似函數(likelihood function)有最大值的參數聯立方程組,接著求出方 立 群的機率(概似函數值)達到最高為原則來估計未知參數的方法。具體作法是先. ‧ 國. 學. 程組的初始解,再持續修正參數值,直到達到最高概似值為止,而最後具有最高 概似值的參數值即為該參數的最大概似估計值。. ‧. EM 的方法是一種重複性的步驟,首先先用獲得最初的母體數據,接著用迴 歸法將遺失值填滿,獲得了新的一組母體數據,再重複一次步驟,直到遺失值的. Nat. sit. n. (1) 發展與原理. al. er. io. 4. 機器學習. y. 參數預估變動非常小為止,一般認為這個方法相對沒有偏差並且有效率。. Ch. engchi. i n U. v. 當我們需要解決一個問題的時候,會需要一個演算法,也就是一個從輸入到 輸出的完整指令,例如把一群資料做排序的動作。但是對於一些問題,並沒有一 個一定的對應演算法,例如從一堆 Email 中找到垃圾郵件。我們可以從幾千筆資 料中把它們找出來,但是卻無法確定這個分類方法可以用來分類未來的資料,於 是機器學習因應而生。機器學習配合電腦的計算能力,不斷的從新的資料中取得 額外的資訊同時不斷改善分類的機制 (Alpaydın, 2010)。 機器學習共分成「監督學習」 、 「無監督學習」與「半監督學習」三個類別, 各別的說明整理如。. 10.
(19) 表 1.1 機器學習類別. 類別. 說明 . 監督 學習. 範例. 從給定的訓練資料集中學習出一個函數(模型),當擁 有新的數據時,則可以根據函數預測出結果。. . 迴歸分析、. 監督學習的訓練集要求是包括輸入和輸出,包含特徵 統計分類。 值和目標值,其中訓練資料集的目標是由人標註的。. 學習 半監督 學習. 無監督學習的訓練資料集是沒有人為標註的結果。. 群聚(cluster). 半監督式學習介於「監督學習」與「無監督學習」之間,. 政 治 大 做訓練的模型,以解決資料量稀少與分散的問題。 立. 其利用大量未標記過的資料結合一些已經標記過的資料來 自主學習. 學. ‧ 國. 無監督. 在資料探勘領域中,最常使用的機器學習法包含類神經網路、決策樹歸納等, 本研究將以機器學習理論中的 AFA 模型為參考基準,提出一套新的遺失值選值. ‧. 填補方法。. y. Nat. er. io. sit. (2) AFA (Active feature-value acquisition). al. v. n. AFA 是機器學習領域中半監督式學習特別的方法,該學習演算法可以從部. i n C 分訓練的資料集中建立的模型運用到新的資料上。 hengchi U. 11.
(20) 圖 2.2 AFA 演算法架構. 學. ‧ 國. 立. 政 治 大. ‧. AFA(Active feature-value acquisition)是指在給定一個取得資訊的預算之下,找 出需要填補的遺失值使得整個預設的模型有更好的準確率。根據 (Zheng &. y. Nat. er. io. 效率的建立模型。. sit. Padmanabhan, 2002)的研究結果顯示,使用自動學習法取得該填的資料可以更有. al. n. v i n Ch 在填值時,我們將會考慮:填值偵測、填值順序、填值方式三個重點。但是 engchi U 本研究以取得真正的遺失值做為填值方式,因此重點將會聚焦於填值順序的研究。 而以下我們先逐一介紹填值偵測與填值順序的方法,其中包括我們主要得比較對 象 Error Sampling。 . Random Sampling. Random Sampling 是從遺失值中隨機挑取欲取得的資料, (Melville et al., 2004)的研究顯示此方法與其他方法相比,欲達成相同的模型準確率時需要填入 最多的值。. 12.
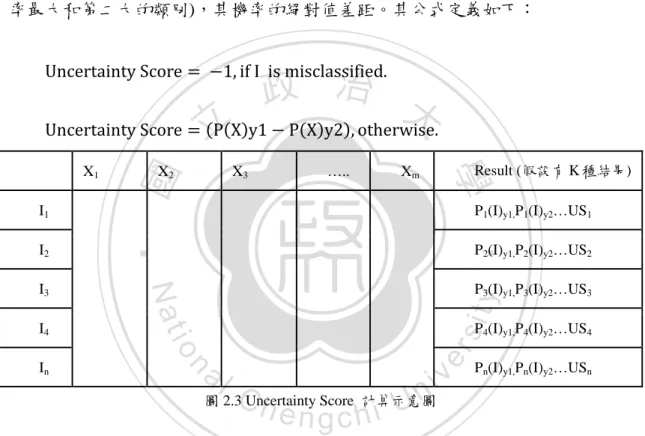
(21) . Error Sampling. Error Sampling 背後的原理是從希望新取得的資料可以為本來的模型帶來有 區別的型態(Discriminative Patterns)。而若是把一筆含有遺失值且被分類錯誤的受 試者填滿,其比較有可能為本來的模型帶來新的區別型態 (Melville et al., 2004)。 因此 Error Sampling 在選擇填值順序的標準是先從被分類錯誤的受試者開始。被 分類錯誤的受試者不含有任何遺失值之後,會依據 Uncertainty Score 的大小,從 小到大來填值。Uncertainty Score 的定義如下:對於兩個最可能被分到的類別(機 率最大和第二大的類別),其機率的絕對值差距。其公式定義如下: Uncertainty Score = −1, if I is misclassified.. 政 治 大. 立. Uncertainty Score = (P(X)y1 − P(X)y2), otherwise.. P2(I)y1,P2(I)y2…US2 P3(I)y1,P3(I)y2…US3. y. sit. al. er. P4(I)y1,P4(I)y2…US4. n. In. P1(I)y1,P1(I)y2…US1. io. I4. Result (假設有 K 種結果). Xm. Nat. I3. …... ‧. I2. X3. ‧ 國. I1. X2. 學. X1. Ch. engchi U. v ni. Pn(I)y1,Pn(I)y2…USn. 圖 2.3 Uncertainty Score 計算示意圖. 在計算過 Uncertainty Score 之後,便可以把它從低到高排序,Error Sampling 便是依據此順序來填值。. 第二節 決策樹的原理 1. 決策樹的原理介紹: 決策樹屬於一種監督式學習,可從分類已知的實例來建立一個樹狀結構,並 從中歸納出每筆數據、類別欄位及其他欄位之間的隱藏規則。所有決策樹的分類 都是基於同樣的結構,皆由一個樹根節點(root node)開始透過特定的演算法規則, 長出分枝(branches)與樹葉(leaves),而每一個分支都是演算法得出的最佳路徑, 13.
(22) 由樹根節點將會長出許多子節點(children node),若是這些子節點為達到終點原 則(terminal rules)的規定,將可繼續衍生出許多的子節點,相對新的子節點而言, 舊的子節點即為他的父節點(father node),若是子節點已到達終結原則的要求, 則不會繼續分支,此時便稱為終結節點(terminal node) (Levin & Zahavi,2001)。 決策樹的其中一個缺點是,它會迅速的將所有訓練資料都用盡,並且會嘗試 著把訓練資料的細節都表現出來,因此會產生過度配適的問題,過度配適發生在 決策樹過度學習訓練資料的細節,記憶住它的特性,因而在用來預測未來資料時, 決策樹的表現會受到大幅的影響 (Jackson, 2002)。 因此,決策樹建構完成後還需要是當的修剪(pruning),常見的決策樹修剪方 式有以下兩種。. 立. 政 治 大. (1) 預先修剪(Pre-Pruning):. ‧ 國. 學. 預先修剪以提早停止決策樹生長來達到修剪的目的,直到樹停止生長時,末. ‧. 端節點即成為樹的樹葉。樹葉的標籤(Label),為該節點訓練集合(Training Set)中. y. Nat. 佔有比例最大的類別。停止決策樹生長的時機是在決策樹建立前,事先設定好一. n. al. er. io. sit. 個閥(Threshold),當分支節點滿足該閥值的設定,就停止該分枝繼續成長。 (2) 事後修剪(Post-Pruning):. Ch. engchi. i n U. v. 事後修剪是先建立一個完整的樹,再將其分支移除的做法,移除分支的依據 是計算該分支的錯誤率(Error Rate),未被移除的分支節點就變成樹葉。一般認為 此方法比事前修剪來的好,因為決策樹在判斷的時候是由上而下的貪婪演算法, 從未回朔前面的分類是否有其他的可能 (Alpaydın, 2010)。 2. 常見的決樹樹種類 Hastie、Friedman &Tibshirani(2001)曾提及目前最被廣泛使用的決策樹演算 法包含 C5.0、CHARD 及 CART 等,下表為常用決策樹的比較。 表 2.1 常用決策樹演算法的比較. 14.
(23) 演算法. CHAID. CART. C5.0. 時間. 1980. 1984. 1998. 作者. Kass. Breiman, Friedman,. 以統計分析(卡方檢. 特點. Ross Quinlan. Olshen, Stone. 定)為主要分類方法. 產生分類樹、迴歸樹 從 C4.5 改良. 決策樹 Non-Binary Tree. Binary Tree. Non-Binary Tree. 分類型. 分類型、連續型. 分類型、連續行. 決策樹修剪方式. Pre-pruning. Post-pruning. Post-pruning. 變數分裂點選擇. 卡方檢定、F 檢定. 型態 應用資料型態. 立. 治Index 政 Gini 大. Information Gain. 由於近年來的實證研究中,透過 C4.5、C5.0 演算法所建構的決策樹成果顯. ‧ 國. 學. 示相當成功,且由於 C5.0 模型具有「面對遺失值非常穩定」、「不需要長時間的 訓練次數」 、 「較其他類型的模型易於理解」 、 「提高分類的精準度」四項優點,因. ‧. 此本研究將以 C5.0 演算法為研究工具,以下我們將針對 C5.0 演算法做更詳細介. n. al. er. io. sit. y. Nat. 紹。. Ch. engchi. 15. i n U. v.
(24) 3. C5.0 的原理 C5.0 演算法為 Quinlan(1998) 提出的演算法,為 C4.5 的商業改進版,可應 用在海量資料集合上的分類,主要是在執行準確度、記憶體耗用上做了改進。 在建構決策樹的過程中,C5.0 以資訊獲利(Information Gain)為準則,選擇最 佳屬性當成決策樹的節點,使最後得到的為一最簡單(或接近最簡單)的決策樹。 資訊獲利(Information Gain)是當一屬性為決策樹節點時,其分支節點的加權亂度 (Entropy)與原物件集合的亂度差距。 若某一資料集合 S 分屬於 c 個不同類別,則此物件集合的亂度 E(S)為:. 政 治 大 E(S) = − ∑ 𝑃 log 𝑃 𝑐. 𝑖. 2. 𝑖. 𝑖=1. 學. 其中𝑃𝑖 為類別 i 在資料集合 S 出現的機率。. ‧. ‧ 國. 立. 屬性 A 在資料集合 S 的資訊獲利 Gain(S,A)被定義為:. 𝑗=1. n. al. Ch. |𝑆𝑗 | 𝐸𝑛𝑡𝑟𝑜𝑝𝑦(𝑆𝑗 ) |𝑆|. engchi. er. io. Gain(S, A) = Entropy(S) − ∑. sit. y. Nat. 𝑣. i n U. v. 假設屬性 A 有 v 個不同值{𝑎1 , 𝑎2 , 𝑎3 , … … … 𝑎𝑣 },而資料集合 S 會因為些不同 值而產生(分割)出 v 個不同的資料子集合{𝑆1 , 𝑆2 , 𝑆3 , … … … 𝑆𝑣 }。 . Entropy(S):資料集合 S 整體的亂度. . 𝐸𝑛𝑡𝑟𝑜𝑝𝑦(𝑆𝑗 ):資料集合 𝑆𝑗 整體的亂度,其中j = 1,2,3 … . . v. . . |𝑆𝑗 | |𝑆|. :第j 個子集合之資料個數占總資料集合的比率(權重). ∑𝑣𝑗=1. |𝑆𝑗 | |𝑆|. 𝐸𝑛𝑡𝑟𝑜𝑝𝑦(𝑆𝑗 ):依據屬性 A 來判定資料集合的亂度 16.
(25) . Gain(S, A):利用屬性 A 對資料集合 S 進行分割的權利. 其中當Gain值越大,表示屬性 A 內資料的凌亂程度越小,用來分類資料會 越佳,反之,當Gain值越小,表示屬性 A 內資料的凌亂度越大,用來分類資料 會越差。 . C5.0 的改善:Boosting. 為了改善分類樹預測的表現,C5.0 使用 Boosting 方法,利用重抽機制產生 不同的學習樣本,再利用這些樣本來製造分類樹。C5.0 使用的 Boosting 方法介 紹如下:. 立. 政 治 大. 考慮一組學習樣本 𝐿1 = {(𝑦𝑛 , 𝑥𝑛 ), 𝑛 = 1, … . . , 𝑁},其中𝑥𝑛 代表預測變數,. ‧ 國. 學. 𝑦𝑛 ∈ {1, … … 𝐽}族群,N 為樣本個數,由 Freund and Schapire(1996)提出的 Boosting (𝐵). 方法中,首先以原始的學習樣本𝐿1 產生分類樹 {𝜑(𝑥, 𝐿1 )},為了讓分類樹對分. ‧. (𝐵). 錯的資料多學習,我們依照 {𝜑(𝑥, 𝐿1 )}的分類結果將分錯的資料給予較大的機. (𝐵). sit. y. Nat. 率值,接著以取出放回方式對 𝐿1 依不同的抽取機率抽出 𝐿2 ,此時 𝐿2 中分錯. al. er. (𝐵). io. 的資料比例較 𝐿1 高,再利用𝐿2 產生分類樹{𝜑(𝑥, 𝐿2 )},重複此步驟 T 次來產. v. n. 生分類樹{𝜑(𝑥, 𝐿2 )},∀1 ≤ t < T,接著將此 T 個分類器的分類結果投票決定,. Ch. engchi. i n U. 最多票者即為 Boosting 方法的預測結果,也就是說 𝑇. (𝐵). 𝜑𝐵(𝑥) = 𝑎𝑟𝑔𝑚𝑎𝑥 ∑ 𝐼 [𝜑(𝑥, 𝐿𝑡 ) = 𝑗] , 𝑡=1. 其中j ∈ {1, … … J}族群。 . C5.0 處理遺失值的方式. 在 C5.0 中,若遺失值出現在學習樣本中,C5.0 用沒有遺失值的資料作變數 和切點的選取,因此,不論遺失值出現在學習樣本或是測試樣本,通過節點時將 17.
(26) 此資料依比例分到每個分支,此比例即為節點內不具遺失值的資料至每個分點的 個數比例,例如,若在此節點中不具遺失值的資料有 n 筆資料分到左節點,m 筆 資料分到右節點,則具遺失值的資料有. n (𝑚+𝑛). 的機率分到左節點,. 率分到右節點,即若該節點有 K 比遺失值資料,通過該節點時有 mk. 左節點,(𝑚+𝑛) 筆分到右節點。. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 18. i n U. v. m (𝑚+𝑛) nk. (𝑚+𝑛). 的機. 筆分到.
(27) 第三章 研究方法 第一節 研究架構 在本研究中我們提出一種新的排序方式,U-Sampling,來為每一種特徵值做 排序,在本章中將會說明 U-Sampling 的想法、程式撰寫方式及其研究限制。另 外在介紹完 U-Sampling 之後會介紹衡量表現好壞的指標,然後分別用訓練資料 遺失、測試資料遺失的 10 折交叉驗證來衡量其效果。最後有關於不同資料型態 間的比較,結果會呈現在第四章當中。. Sampling. 學. 說明. 評估. ‧. 10折交叉 驗證. 指標. y. Nat. 想法. io. sit. ‧ 國. 立. 政 治 大 U. er. 訓練資料 遺失 i v. n. 程式撰寫 a. l C hengchi Un 研究假設 不同遺失 與限制. 比例 不同遺失 分布 圖 3.1 研究架構圖. 19. 測試資料 遺失.
(28) 第二節 U-Sampling 說明 3.2.1 研究想法 在第二章的文獻中我們引用了 Error Sampling 的原理,其希望透過 Uncertainty Score 的「大小」去判斷每個「受試者(row)」的遺失值重要性,而有 別於此,我們提出了新的方法 U-Sampling,希望可以用「特徵值(column)」來排 序遺失值的填補順序。 U sampling 的方法源於 Uncertainty Score,其假設為「某特徵值的遺失若影 響到 Uncertainty Score 越多,其對分類結果正確率的影響也會越大」 ,因此在本. 政 治 大 對值變化大小│Uncertainty Score –Uncertainty Score 立 來判斷該特徵值的重要性。. 研究中,將會輪流把不同的特徵值用遺失值取代,觀察其 Uncertainty Score 的絕 original data. data with empty column. │,. ‧ 國. 學. 接下來我們用一系列圖示來說明 U-Sampling 的應用方式。圖 3.2 為我們拿. ‧. 到的原始資料,其中包含一些遺失值,而原始資料可以計算出第一組的. I2 I3 …... sit. y. al. …... Result (假設有 K 種結果). Xm. er. X3. n. I1. X2. io. X1. Nat. Uncertainty Score,我們將其記錄下來並標註為 USoriginal data。. Ch. engchi. i n U. Original Data. (with missing values). v. US1 US2 US3 … USn. In 圖 3.2 完整資料的 Uncertainty score. 在圖 3.3 中,當 A1 特徵值遺失的時候,我們會得到另一組的 Uncertainty Score, 我們紀錄並標註為 USdata with empty column。我們將會重複這個步驟共 m 次(因為總共. 20.
(29) 有 m 個特徵值)。我們將 A1 恢復原狀,並把 A2 用遺失值取代,記錄另一組 Uncertainty Score,重複此步驟直到我們有 m 組新的 Uncertainty Score。 X1 I1. X2. X3. ………. Result. Xm. (假設有 K 種結果). US1. NA. US2. I2. Original Data. NA I3. US3. I4. NA. US4. …... NA. …. In. NA. 立. 政 治 大. USn. 圖 3.3 特徵值 X1 遺失時的 Uncertainty Score. ‧ 國. 學. 進行完上面的步驟,我們總共會有一組原始的 Uncertainty Score USoriginal data,. ‧. 以及 m 組的 USdata with empty column (第 1~m 組的 US 分別代表的 1~m 個特徵值遺失. y. Nat. 的時候 Uncertainty Score 的值)。我們將 m 組新的 US 和原始的 US 相減並且取絕. io. sit. 對值,得到 m 組「差距」,也就是我們定義的重要性「大小」。. n. al. er. 差距等於│Uncertainty score original data-Uncertainty score data with empty column│,若. i n U. v. 是此相差的絕對值總和越大,就代表特徵值遺失的時候對於整個模型的. Ch. engchi. Uncertainty Score 影響越大,因此我們將其值越大的特徵值視為比較重要的特徵 值,應該給予較高順位的填值順序。. 21.
(30) 3.2.2 程式撰寫 U Sampling framework Given: 𝐹 − set of total complete data points 𝐼 − set of incomplete data points G − set of complete data points, F − I 𝑈 − set of uncertainty score calculating data points 𝐷 − set of difference in uncertainty score between F and U 𝑅 − rank of D in an decreasing order 𝑁 − number of total columns in F 𝑇 − set of training points, G ∪ I 𝐿 − leaning algorithm. 立. 政 治 大. 1. 𝑅𝑒𝑝𝑒𝑎𝑡 𝑁 𝑡𝑖𝑚𝑒𝑠 𝑡ℎ𝑖𝑠 𝑠𝑡𝑒𝑝. ‧ 國. 學. 𝐺𝑒𝑛𝑒𝑟𝑎𝑡𝑒 𝑈 𝑓𝑟𝑜𝑚 𝐹, 𝑒𝑎𝑐ℎ 𝑡𝑖𝑚𝑒 𝑤𝑖𝑡ℎ 𝑜𝑛𝑒 𝑒𝑚𝑝𝑡𝑦 𝑐𝑜𝑙𝑢𝑚𝑛 2. 𝐶𝑎𝑙𝑐𝑢𝑙𝑎𝑡𝑒 𝑡ℎ𝑒 𝑢𝑛𝑐𝑒𝑟𝑡𝑎𝑖𝑛𝑡𝑦 𝑠𝑐𝑜𝑟𝑒 𝑓𝑜𝑟 𝐹 𝑎𝑛𝑑 𝑈, 𝑎𝑛𝑑 𝑡ℎ𝑒𝑖𝑟 𝑑𝑖𝑓𝑓𝑒𝑟𝑒𝑛𝑐𝑒𝑠. ‧. 3. Record the differences in D, and rank them in R. y. sit. 5. ∀𝑥𝑖𝑗 ∈ 𝐼,. Nat. 4. 𝐺𝑒𝑛𝑒𝑟𝑎𝑡𝑒 𝑎 𝑐𝑙𝑎𝑠𝑠𝑖𝑓𝑖𝑒𝑟, 𝐶 = 𝐿(𝑇). n. al. i n U. 7. 𝑅𝑒𝑚𝑜𝑣𝑒 𝑑𝑎𝑡𝑎 𝑝𝑜𝑖𝑛𝑡 𝑖𝑛 𝑓𝑟𝑜𝑚 𝐼 𝑎𝑛𝑑 𝑎𝑑𝑑 𝑡𝑜 𝐺. Ch. engchi. 8. 𝑈𝑝𝑑𝑎𝑡𝑒 𝑡𝑟𝑎𝑖𝑛𝑖𝑛𝑔 𝑠𝑒𝑡, 𝑇 = 𝐺 ∪ 𝐼 9. 𝑅𝑒𝑡𝑢𝑟𝑛 𝐿(𝑇). er. io. 6. 𝐴𝑐𝑞𝑢𝑖𝑟𝑒 𝑣𝑎𝑙𝑢𝑒 𝑓𝑜𝑟 𝑡ℎ𝑒 𝑚𝑖𝑠𝑠𝑖𝑛𝑔 𝑑𝑎𝑡𝑎 𝑝𝑜𝑖𝑛𝑡 𝑥𝑖𝑗 𝑎𝑐𝑐𝑜𝑟𝑑𝑖𝑛𝑔 𝑡𝑜 𝑅. v. 圖 3.4 U Sampling 程式架構. 程式說明:將一個完整的資料集合的特徵值(共有 N 個)輪流以遺失值取代並 且測量它們對 Uncertainty Score 的影響,依照絕對值大小總和順序排序。之後以 此順序進行填值,並且記錄準確度。. 3.2.3 假設與限制 本研究主要是對特徵值重要性排序,也就是填值順序的不同對於分類準確度 的影響,所以並沒有比較不同的填值方法。再者,我們在填值的時候填的是實際 22.
(31) 的數值,也就是說本研究用的資料必須是原先完整,但經過我們抽樣之後用不同 比例的遺失值取代之。 另外,由於本研究並沒有考慮到不同特徵值間的成本差異,因此的資料並沒 有提供每項特徵值的成本,且現有文獻對於特徵值的取得成本的模擬與分析也沒 有一致的看法,因此,本研究將假設資料的所有取得成本一樣。 本方法還有一個應用上的限制,由於計算 Uncertainty Score 需要一定數量的 完整資料,所以本方法不能使用在完全沒有歷史紀錄的資料庫。. 第三節 U Sampling 評估. 政 治 大 本研究除單純了解使用 U Sampling 方式建立的模型的分類能力外,我們也 立. 以相同的資料測試 Random Sampling 和 Error Sampling 兩種方式的表現,並分. ‧ 國. 學. 析不同型態的資料中各個模型的適用程度與準確度差異,以下將針對模型評估的. sit er. io. 1. 排序的穩定程度. y. Nat. 3.3.1 評估指標. ‧. 各項標準與重點詳細的介紹,. al. n. v i n Ch 在本研究中每次將一整個欄位資料的 e n g50%替換成遺失值,測量每個欄位的特 chi U 徵值重要順序,但如果用其他遺失比例來替換成遺失值,排序或許會有些更 動,所以必須確定整體排名的趨勢不能變動太大,因此我們將會使用不同的 遺失值比例去檢視排名的穩定性。 2. 準確率( Accuracy) 當訓練資料(training data)每填入一個遺失值後,使用測試資料(test data)檢驗 模型分類的準確程度。使用平均準確率進行比較。 3. 平均錯誤減少率(Average Error Reduction Rate) 23.
(32) 過去相關文獻多以「準確率(accuracy rate)」衡量預測模型的分類表現好壞, 即當訓練集合(training data)每填入一定數量的遺失值後,使用測試集合(test data) 測量預測模型分類的準確度,繼而從中判斷表現好壞。 在比較不同方式的填值方式時,我們參考 (Saar-Tsechansky et al., 2009)提出 的「平均錯誤減少率(average percentage error reduction)」評估。假設現在有 A、 B 兩種方法去填值,分別可產生 RA、RB 的準確率,則 B 方法以 A 方法為基準的 錯誤減少率等於(RB-RA)/(1-RA)。除此之外,同時我們也使用配對樣本 T 檢定, 分析每個選值動作時使用 A 方式和 B 方式所建立的模型的錯誤率是否有顯著差 異(p<0.05)。第四章的研究結果將附上每組資料使用不同方式建立的學習曲線圖 與平均失誤差減少率。. 立. 政 治 大. ‧ 國. 學. 3.3.2 檢驗方式. ‧. 1.. 不同遺失比例檢驗排序穩定度. sit. y. Nat. io. er. 在 U-Sampling 當中我們分別以 0.1、0.3、0.5 的遺失比例去測量 Uncertainty Score 的變化大小排序,觀察在不同的遺失比例是否會對排序造成顯著的影. al. n. 響。. 2.. Ch. engchi. i n U. v. 10 折交叉驗證 (10-fold cross validation) 訓練資料建立的模型若是自己測試本身的準確率,將會產生過度配適(over. fitting)的問題,為了避免這的問題,我們使用 K 折交叉驗證。K 折交叉驗證是先 將數據分割成 K 個子樣本,一個單獨的子樣本保留為驗證模型表現的數據(測驗 集合 test data),其他 K-1 個樣本用來訓練模型的建立(training data),並且交叉重 複驗證 K 次。每個子樣本都會有一次機會當成測試資料,最後平均 K 次結果為 我們的判定準確程度的指標。 (Kohavi, 1995)提到 10 折交叉驗證是最好的預測. 24.
(33) 模型準確率方法之一,因此本研究將會使用 10 折交叉驗證法驗證模型的預測能 力。 在第一個實驗中,我們對一個檔案進行 4 次的 10 折交叉驗證,訓練資料的 遺失比例分別為 0.1、0.3、0.5。紀錄在不同遺失比例下,訓練資料在依照不同方 法填補遺失值時,其預測準確率的變化。 在第二次實驗中,我們把每個檔案的測試資料的 70%用遺失值取代,並且記 錄其在不同的填值方法下,其預測準確率的變化。. 3.3.3 和 Random Sampling、Error Sampling 的比較. 政 治 大 我們將所提出的 U-Sampling 方式與 Random Sampling 和 (Melville et al., 立. 2004)等學者發表的 Error Sampling 兩種方式進行比較。和 Random Sampling 比較. ‧ 國. 學. 是想要觀察 U-Sampling 和不花任何額外成本的 Random Sampling 方式比較,觀. ‧. 察其進步的幅度。. y. n. al 3.3.4 不同資料型態比較. er. io. sit. 方法更有進步。. Nat. 與 Error Sampling 比較的目的在於我們提出的方法是否會比當前流行的改善. 1.. Ch. 訓練資料的遺失比例不同. engchi. i n U. v. 決策樹預測模型在不同的遺失比例下會有不同的表現,其填值的方法也可能 因此表現優劣不一,所以我們在實驗中用不同的遺失比例(10%、30%、50%)去 檢視不同的方法及其相對應的準確率表現。. 25.
(34) 第四章 研究結果 第一節 實驗數據 本研究使用 UCI Machine Learning 資料庫的 8 組資料進行分析,以下我們將 先簡單介紹研究資料,再進行上一章所提到的各項實驗,進而評估、分析各填值 順序模型的分類效果。. 4.1.1 研究資料介紹 1. 資料簡介. 立. Breast tissue. 3. Glass. ‧. 病患的胸部組織經過的不同檢驗後,即得知胸部罹患的. Nat. 疾病,如癌症、纖維腫瘤等。. y. 2. 根據不同的耳部聽立診斷判定耳疾的種類。. sit. Audiology. 此數據是從犯罪學衍生而來的研究,用來判定犯罪現場. io. er. 1. 說明. ‧ 國. 資料名稱. 表 4.1 研究資料基本介紹. 學. No.. 政 治 大. 遺留的玻璃碎片所屬性質與類別。. n. al. Ch. i n U. v. 根據樹葉不同的特徵進而分類該樹葉是屬於何種樹科 4. Leaf. 5. Lungcancer. 的葉子。. engchi. 根據不同的檢驗結果判定患者所罹患的肺癌類別。 該資料是從受試者進行生醫聲音檢驗(biomedical voice. 6. Parkinsons. measurements),從不同的聲音檢測了解哪些人罹患帕金 森氏疾病。 此資料為 Pima 印地安婦女罹患糖尿病的判定報告,其. 7. Pima Indians. 中由各種不同的指標檢驗出病患所罹患糖尿病的嚴重. Diabetes 性。. 8. Zoo. 根據動物的特徵辨別為何種動物。 26.
(35) 2. 資料型態 表 4.2 實驗數據的資料型態. 資料名稱. 資料類別. 資料筆數. 屬性筆數. 結果種類. 1. Audiology. 數值、類別. 123. 68. 21. 2. Breast tissue. 數值. 106. 9. 6. 3. Glass. 數值. 214. 9. 7. 4. Leaf. 數值、類別. 340. 15. 30. 5. Lungcancer. 類別. 32. 56. 3. 6. Parkinsons. 數值. 22. 2. 7. Pima. 2. 8. Zoo. 立 類別. 8 17. 7. ‧. 各組資料的結果分布狀況. 20 0. y. sit er. al. n. 40. io. 60. 101. Nat. 80. 治195 政 數值 768 大. 學. 100. ‧ 國. No.. Ch. engchi. i n U. v. 圖 4.1 實驗資料的結果分布. 我們所選取的資料樣本大小有異,不論是資料數目、屬性數目的範圍涵蓋很 廣,此外,由上表也可以看到我們所實驗的 8 組資料中,有 5 資料的結果分布較 不平均(分別為 Audiology、Glass、Parkinsons、Pima、Zoo),而其他 3 的分類結 果則較平均分配。 27.
(36) 我們所選取的資料涵蓋的範圍很廣,主要可以區分成下列幾個不同點。 1. 特徵值的多寡不同,從 8~68 個特徵值 2. 結果的分布不同,有些檔案的分類種類很少,結果集中;但有些檔案的 結果分布很多樣,結果並沒有這麼集中。 3. 資料比數的差異,從 32 筆資料到 768 筆資料。 由不同的資料型態會有不同的結果,如此可以比對我們的方法是否會特別適合或 是不是何某一種資料型態。. 第二節 實驗結果. 政 治 大. 4.2.1 十折交叉驗證-training data 含有遺失值. 立. 在這個部分將會先呈現 Random Sampling,Error Sampling,以及 U-Sampling. ‧ 國. 學. 在 8 組測試資料中的準確率,並分別用圖表說明。. ‧. 在這個部分中,我們把 8 組測試資料分別做 10 折交叉驗證。每一個檔案會. y. Nat. 經過四個的 10 折交叉驗證(訓練資料分別有 10%、30%、50%的遺失比例)。在每. io. sit. 次交叉驗證中,每筆資料會被分為 10 等份,其中 9 份會被拿來當訓練資料並且. n. al. er. 有比例會被遺失值所取代,剩下的一份被拿來當測試資料並且不會有任何遺失值。. i n U. v. 訓練資料會被用來建置決策樹,再用完整的測試資料去測量其預測的準確度,在. Ch. engchi. 每一次測量完之後,我們將會用不同的方式(Random Sampling、Error Sampling、 U-Sampling)用正確的資料去填補一個遺失值,如此過程重複直到所有遺失值都 被填滿為止。 結束後我們會得到 training data 中完整資料的數目和測試資料的準確率的對 照,以此為依據作圖觀察準確率的走勢及計算整體的平均準確率。. 28.
(37) 表 4.3 遺失值從 10%到填滿的平均準確率. NA=10%. R. E. U. audiology. 0.610847. 0.615421. 0.6293. breasttissue. 0.649512. 0.635. 0.65622. 0.6848. 0.6799. 0.7041. 0.609578. 0.602161. 0.62069. lungcancer. 0.4514. 0.4458. 0.4728. parkinsons. 0.8593. 0.8537. 0.8466. pima. 0.7419. 0.7398. 0.76. 0.900069. 0.896759. 0.91476. glass leaf. zoo. 政 治 大. 表 4.4 遺失值從 30%到填滿的平均準確率. 立. R. E. U. 0.57154. 0.59962. breasttissue. 0.65221. 0.65742. 0.65299. glass. 0.6828. 0.6909. 0.6902. leaf. 0.59301. 0.60378. 0.62324. lungcancer. 0.32498. 0.40908. 0.45626. 0.8405. 0.8504. 0.8271. 0.741. 0.733. 0.89409. 0.90480. pima. io. al. n. zoo. Ch. engchi. y. 0.742. er. Nat. parkinsons. ‧. ‧ 國. 0.55668. 學. audiology. sit. NA%=30%. 0.90679. i n U. v. 表 4.5 遺失值從 50%到填滿的平均準確率. NA%=50% R. E. U. audiology. 0.570204. 0.605241 0.636973. breasttissue. 0.650222. 0.631946. 0.67436. glass. 0.62583. 0.63026. 0.63458. leaf. 0.548643. 0.553333. 0.55696. lungcancer. 0.261955. 0.423206 0.415456. parkinsons. 0.8399. 0.8497. 0.8390. pima. 0.7391. 0.729. 0.732. zoo. 0.846685. 29. 0.865368 0.870943.
(38) 表 4.6 研究資料 10 折交互驗證的結果. Data. NA_Rate E. Audiology. Breasttissue. Glass. Leaf. 30%. 3.35%. 9.69%. 50%. 8.15%. 15.53%. 10%. -4.14%. 1.91%. 30%. 1.50%. 0.22%. 50%. 2.85%. -3.77%. 10%. -1.54%. 6.14%. 30%. -1.19%. -1.09%. 50%. 1.19%. 2.34%. 10%. -1.90%. 2.85%. 10%. -1.03%. 3.89%. 30%. 12.46%. 19.45%. 50%. 21.85%. 20.80%. 10%. -3.31%. 14.70%. 30%. 10.12%. 11.99%. 50%. 12.19%. 15.82%. 10%. -3.96%. -9.01%. 30%. 6.18%. -8.42%. 50%. 6.14%. 10%. -0.831%. 30. y. -0.59%. v i6.18% n U. i e30% n g c h -3% 50%. sit. ‧ 國. n. Ch. ‧. Nat. Parkinsons. io. 4.74%. 學. Zoo. Pima. 1.18%. 政30% 治2.65% 大 7.43% 50% 1.04% 1.84%. Lungcancer. al. 10%. er. 立. U. -3.5%. 0.4% -1%.
(39) Audiology-training data missing 0.72. 準確率. 0.67 0.62 R 0.57. E U. 0.52 0.47 3700. 4700. 5700. 6700. 7700. 8700. training data 取得樣本數. 政 治 大. 圖 4.2 Audiology 10 折交互驗證時的學習曲線. 立. ‧ 國. 學. Breasttissue-training data missing. 0.75. al. n 0.5 400. y. sit. io. 0.55. R E U. er. 準確率. 0.6. Nat. 0.65. ‧. 0.7. Ch. 500. e600 n g c h700i. iv n U 800. training data 取得樣本數. 圖 4.3 Breast tissue 10 折交互驗證時的學習曲線. 31. 900.
(40) 準確率. Glass-training data missing 0.68 0.66 0.64 0.62 0.6 0.58 0.56 0.54 0.52 0.5. R E U. 800. 1000. 1200. 1400. 1600. 1800. training data 取得樣本數. 政 治 大. 圖 4.4 Glass 10 折交互驗證時的學習曲線. 立. ‧ 國. 學. 0.45. y. sit. al. n. 0.5. er. 0.55. io. 準確率. 0.6. ‧. 0.65. Nat. 0.7. Leaf-training data missing. 0.4. Ch. engchi U. v ni. R E U. 0.35 0.3 2000. 2500. 3000. 3500. 4000. 4500. training data取得樣本數. 圖 4.5 Leaf 10 折交互驗證時的學習曲線. 32. 5000.
(41) Lungcancer-training data missing 0.7 0.6. 0.4. R. 0.3. E. 0.2. U. 0.1 0 800. 900. 1000. 1100. 1200. 1300. 1400. 1500. 1600. 1700. training data取得樣本數. 政 治 大. 圖 4.6 Lung cancer 10 折交互驗證時的學習曲線. 立. ‧ 國. 學. Parkinsons-training data missing. ‧. 0.89 0.88 0.87 0.86 0.85 0.84 0.83 0.82 0.81 0.8 0.79 1900. n. al. R. er. io. sit. y. Nat. 準確率. 準確率. 0.5. Ch. 2400. engchi 2900. i n U. 3400. v. 3900. training data取得樣本數. 圖 4.7 Parkinsons 10 折交互驗證時的學習曲線. 33. E U. 4400.
(42) Pima-training data missing 0.76 0.75 準確率. 0.74 0.73. R. 0.72. E U. 0.71 0.7 2400. 2900. 3400. 3900. 4400. 4900. 5400. 5900. training data 取得樣本數. 政 治 大. 圖 4.8 Pima 10 折交互驗證時的學習曲線. 立. ‧ 國. 學. Zoo-training data missing. 0.95. ‧. al. n. 0.7 720. y. io. 0.75. R. sit. 0.8. E. er. 0.85. Nat. 準確率. 0.9. Ch. 920. e n g1120c h i. i n U. U. v. 1320. 1520. training data 取得樣本數. 圖 4.9 Zoo 10 折交互驗證時的學習曲線. 準確率和錯誤減少率本身是相互對應的,準確率越高錯誤減少率越少,從上 面對 8 個不同檔案的實驗數據我們可以觀察到下列幾個現象。 1. 在全部的 18 次實驗中,U-Sampling 在 14 次的實驗中(77%)的平均準確率 都是在三者當中最高的。. 34.
(43) 2. 在遺失比例為 10%的時候,因為遺失的資料太少,所以平均錯誤減少率 上 Error Sampling 和 U-Sampling 都沒有比 Random Sampling 好多少,其中 Error Sampling 甚至表現不如 Random Sampling。推測是因為在遺失比例小的時候,遺 失值的問題並不會對整個決策樹模型造成很大的改變,因此 Error Sampling 和 U-Sampling 並沒有辦法大幅改善決策樹的準確率。 表 4.7 不同遺失比例的錯誤減少率. 遺失比例 E. U. 10%. -1.94%. 3.93%. 30%. 5.21%. 8.52%. 50%. 7.48%. 8.19%. 政 治 大. 立 不同遺失比例的錯誤減少率. ‧ 國. 學. 10.00%. 8.00%. 4.00%. -4.00%. 0%. y. sit. 10%. al. 20%. 30%. 40%. n. -2.00%. io. 0.00%. E. Ch. e遺失值比例 ngchi. 50%. er. 2.00%. Nat. 錯誤減少率. ‧. 6.00%. i n U. v. U. 60%. 圖 4.9 不同遺失比例的錯誤減少率. 4.2.2 十折交叉驗證-test data 含有遺失值 在 4.2.1 中,我們進行的十折交叉驗證,是在測量當訓練資料含有不同比例 的遺失值時,其建立的決策樹的準確率。但是在 4.2.2 的實驗當中,訓練資料是 完整而沒有遺失的,但測試資料則有 70%的遺失值。前者(4.2.1)是用在「建立模 型」時,U-Sampling 的排序是否會比較快達到比較高的準確率,後者(4.2.2)則是 35.
(44) 在「取得新資料」時,U-Sampling 所提供的順序是否能讓我們用比較少的資料 達到比較高的準確率。 表 4.8. test data 有遺失值的平均準確率. R. U. Audiology. 0.524709. 0.62763. breasttissue. 0.53875. 0.612969. glass. 0.548069 0.599325. leaf. 0.402176. 0.51803. parkinsons. 0.807592 0.828095. pima. 0.723808 0.740037. zoo. 0.721327 0.888938. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 36. i n U. v.
(45) Audiology-test data missing 0.7 0.65. 準確率. 0.6 0.55 0.5. R. 0.45. U. 0.4 0.35 0.3 200. 300. 400. 500. 600. 700. 800. 900. test data總數. 政 治 大. 圖 4.10 Audiology-10 折交叉驗證的學習曲線(測試資料有遺失值). 立. ‧ 國. 學. ‧ y. sit. n. al. er. io. 0.75 0.7 0.65 0.6 0.55 0.5 0.45 0.4 0.35 0.3. Nat. 準確率. Breasttissue-test data missing. 20. 40. Ch. n U engchi 60 80. U. iv. 100. test data 取得樣本數. 圖 4.11 breasttissue-10 折交叉驗證的學習曲線(測試資料有遺失值). 37. R.
(46) Glass-test data missing 0.75 0.7. 準確率. 0.65 0.6 0.55. R. 0.5. U. 0.45 0.4 50. 100. 150. 200. test data 取得樣本數. 政 治 大. 圖 4.12 Glass-10 折交叉驗證的學習曲線(測試資料有遺失值). 立. ‧ 國. al. n. 0.2. sit. io. 0.3. er. 0.4. y. Nat. 準確率. 0.5. ‧. 0.6. 0.1 150. 學. 0.7. Leaf-test data missing. 250. Ch. e n350g c h i. i n U. 450. v. 550. test data 取得樣本數. 圖 4.13 Leaf-10 折交叉驗證的學習曲線(測試資料有遺失值). 38. R U.
(47) Parkinsons-test data missing 0.85 0.84. 準確率. 0.83 0.82 0.81. R. 0.8. U. 0.79 0.78 0.77 0. 100. 200. 300. 400. 500. test data 取得樣本數. 政 治 大. 圖 4.14 Parkinsons-10 折交叉驗證的學習曲線(測試資料有遺失值). 立. ‧ 國. io. 0.71. al. 0.69 0.68 100. 200. Ch 300. n U engchi 400 500 600. 700. test data 取得樣本數. 圖 4.15 Pima -10 折交叉驗證的學習曲線(測試資料有遺失值). 39. R U. iv. n. 0.7. sit. 0.72. er. 0.73. y. Nat. 準確率. 0.74. ‧. 0.75. 學. 0.76. Pima-test data missing.
(48) Zoo-test data missing 1 0.9 準確率. 0.8 0.7. R. 0.6. U. 0.5 0.4 45. 65. 85. 105. 125. 145. 165. 185. test data 取得樣本數. 政 治 大. 圖 4.16 Zoo-10 折交叉驗證的學習曲線(測試資料有遺失值). 立. 從這小節的實驗當中我們可以歸納出以下重點。. ‧ 國. 學. 1. 7 個檔案中的 U-Sampling 表現明顯比 Random 好,而且進步的幅度比前一. ‧. 小節(訓練資料有遺失還大)。所以不論是用來建構較好的預測模型,或是用來做 為未來特徵值取得順序的參考,U-Sampling 的順序都可以對預測的準確率有所. er. io. sit. y. Nat. 提升。. 2. Parkinsons 是 U-Sampling 在 4.2.2 實驗中表現最差的資料,但是由圖形可. al. n. v i n 得知在 4.2.3 的實驗其表現仍然比 C hRandom SamplingU好。所以即使是 U-Sampling engchi 的填值順序在建立模型時沒有明顯的幫助,在預測未來資料時,依照這個順序取 得特徵值依然會提高準確率。. 4.2.4 不同資料型態 1.. 不同遺失比例. 比較不同資料遺失比例時 Error Sampling 和 U Sampling 的表現(以平均錯誤 改善率衡量)我們觀察到下列現象。. 40.
(49) (1) 遺失比例太小時,效果不明顯。推測其原因是遺失比例小時,很多模型 都已經可以建立高準確率的決策樹,因此在多填值並不會對於結果的準確率達到 太大的影響。因此不論是 Error Sampling 還是 U-Sampling,其相對於 Random Sampling 的表現在遺失比例僅有 10%的時表現均普通,Error Sampling 甚至還有 不如 Random Sampling 的表現。 (2) 遺失比例越大,U-Sampling 的效果越明顯。推測其原因應該是 U-Sampling 是利用過去完整的資料並且以部分比例用遺失值取代成得出的填值 順序,其效果並不會因為遺失比例的大小而受到影響,但若是 Error Sampling 則 會受到遺失比例很大的影響,因為 Error 本身的判斷必須依據當時所建立的決策. 政 治 大. 樹,當遺失比例高時決策樹可能不太具有參考性,因此 Error Sampling 的表現有. 立. 所起伏。. 遺失比例 E. U. 10%. -1.94%. 3.93%. 30%. 5.21%. 8.52%. 50%. 7.48%. 8.19%. n. er. io. sit. y. ‧. Nat. al. 學. ‧ 國. 表 4.9 比較三種方式在不同資料遺失比例下的表現. Ch. engchi. 41. i n U. v.
(50) 第五章 結論與建議 第一節 結論 預測模型中的訓練資料若有遺失值,則會影響模型的預測能力,因此如何處 理遺失值就變成一個重要的問題。本研究的範疇是在「用特定的成本」去真實取 得遺失的資料,我們提出了新的填補順序 U-Sampling,以用更有效率的方式填 補遺失值。 有別於過去的研究中 row-based 的方法,是以「受試者的重要性」來排列填. 政 治 大 重要性」來排列填補順序,其目的是判斷每一種不同特徵值的重要順序。 立. 補順序,本研究提出的 U-Sampling 是一個 column-based 的方法,以「特徵值的. ‧ 國. 學. 在過去的文獻中 Uncertainty Score 的「高低」 被用來判斷一個受試者是否 容易被歸到錯的類別,其值越低則越容易被分類錯誤。但在本研究中進一步把受. ‧. 試者的每一個特徵值分開,輪流把每一個特徵值用遺失值取代,並且計算其對整. Nat. er. io. sit. y. 個模型 Uncertainty Score「變化量」,「變化量」越大則被列為較重要的特徵值。 我們對 8 組不同的資料集合各自進行三次的遺失值填補實驗,每次的遺失比. n. al. Ch. 例不同,主要的結果列在下面各項中. engchi. i n U. v. 1. 在總共 22 個情境下 U-Sampling 在 70%以上的實驗表現都好於 Random Sampling 以及 Error Sampling,因此平均上情況使用 U-Sampling 會節省成本。. 2.對於某些資料,取得更多的特徵值並不會增加決策樹對結果預測的準確率, 在此種情況下額外在花成本取得遺失值便沒有太大的意義。因此在使用 U-Sampling 之前應判斷該資料是否需要做遺失值的處理。. 42.
(51) 3. 在遺失比例小的時候(10%),平均準確率的進步幅度較小,我們推測原因 是資料在遺失比例低的時候,填補遺失值並不會對其模型造成太大的影響。不過 隨著遺失比例增加(30%~50%),準確率的進步幅度也隨之增加。 4. 我們也模擬了「未來資料」填值順序的實驗,在遺失比例 70%的前提下, 依照 U-Sampling 的填值順序來填補資料,其準確率會比 Random Sampling 為高, 因此不論是用於建立決策樹模型或是未來希望被正確分類的資料,U-Sampling 都提供了一個節省成本的選值順序。. 第二節 研究限制及建議 5.2.1 研究限制. 立. 政 治 大. 1. 在本研究中我們並沒有關於資料的成本資訊。因此我們假設每個資料的. ‧ 國. 學. 取得成本相同,純粹使用特徵值的重要性去排序。. ‧. 2. 受限於實驗時間以及程式運作速度,我們並沒有應用到非常大的資料集. sit er. io. 5.2.2 未來建議. y. Nat. 合。. al. n. v i n 1. 加入成本的資訊,配合C U-Sampling 所提供的重要性,將可以做加權計算, hengchi U 再去判斷哪一個資訊是最重要的。 2. 除了 column-based 的方法外,也可以把 Error Sampling 的概念納入其中, 先選到重要的「特徵值」之後再選重要的「受試者」。 3. 改善程式的速度,可以把 U-Sampling 實驗在更大的資料集合上。. 43.
(52) 參考文獻 1.. Allison, P. D. (2001). Missing data. Thousand Oaks, CA: Sage.. 2.. Alpaydın, E. (2010). Introduction to machine learning. London, England: The MIT Press.. 3.. Bennett, D. A. (2001). How can I deal with missing data in my study? Australian and New Zealand Journal of Public Health, 25(5), 464–469.. 4.. Giks, Walter R ; Richardson, Sylvia; Spiegelhalter, David J. (1996). Introducing Markov chain Monte Carlo. In Markov chain Monte Carlo in practice (pp. 1-19). London: Chapman & hall/CRC.. 立. 政 治 大. Graham, J. W. (2003). Adding missing-data-relevant variables to FIML basedstructural equation models. Structural Equation Modeling, pp. 10, 80– 100.. 6.. Jackson, J. (2002). Overview, data mining: a conceptual. Communications of the Association for Information Systems.. 7.. Kohavi, R. (1995). A study of Cross-Validation and Bootstrap for Accuracy Estimation and Model Selection. IJCAI, (Vol.14, No.2, pp. 1137-1145).. ‧. ‧ 國. 學. 5.. er. io. sit. y. Nat. al. n. v i n Levin, N., & Zahav, J.C (2001, h e Spring). i U modeling using n g c hPredictive. 8.. segmentation. Journal of Interactive Marketing, 15(2), 2-22. 9.. Melville, P., Saar-Tsechansky, M., Provost, F., & Mooney, R. (2004). Active Feature-Value Acquisition for Classifier Induction. Proceedings of the 4th IEEE International Conference on Data Mining, (pp. 483-486). Brighton, UK.. 10. Pallant, J. (2007). SPSS survival manual (3rd ed.). New York, NY: Open University Press. 11. Pedro J. Garcı´a-Laencina Æ Jose´-Luis Sancho-Go´mez Æ , A. R.-V. (2010). Pattern classification with missing data: a review. Neural Comput & Applic. 44.
(53) 12. Peng, C. Y. J., Harwell, M., Liou, S.M., & Ehman, L.H. (2006). Advances in missing data methods and implications for educational research. In Real data analysis, 31-78. North Carolina,US : Information Age Publishing. 13. Quinlan, J. R. (1989). Unknown attribute values in induction., In ML (pp. 164-168). 14. Rubin, D. B. (1987). Multiple imputation for non-response in surveys. New York: John Wiley & Sons. 15. Saar-Tsechansky, M., Melville, P., & Provost, F. (2009, 4). Active Feature-Value Acqusition. Management Science, 55(4), 664-684.. 學. ‧ 國. 16.. 政 治 大 Schafer, J. L. (1999). Multiple imputation: a primer. Statiscal methods in 立 medical research, 8(1), 3-15.. 17. Schlomer, G. L., Bauman, S., & Card, N. A. (2010). Best Practices for. ‧. Missing Data Management in Counseling Psychology. Journal of Counseling Psychology, 57(1), 1-10.. sit. y. Nat. al. er. io. 18. Simon, H. A., & Lea, G. (1974). Problem solving and rule induction: A. v. n. unified view. Knowledge and cognition. Oxford, England: Lawrence Erlbaum.. Ch. engchi. i n U. 19. Simon, H., & Lea, G. (1974). Problem solving and rule induction: A unified view. 20. Turney, P. (2000). Types of Cost in Inductive Concept Learning. Proceedings of the Cost-Sensitive Learning Workshop at the 17th ICML-2000 Conference. Stanford, CA.. 45.
(54) 21. Vinod, N. C., & Punithavalli, D. M. (2011). Classification of Incomplete Data Handling Techniques-An Overview. International Journal on Computer Science and Engineering, 3(1), 340-344.. 22. Zheng, Z., & Padmanabhan, B. (2002). On Active Learning for Data Acquisition. Proceedings of IEEE International Condference on Data Mining, (pp. 562-569).. 網路資料. 政 治 大. UCI machine Learning Repository. (n.d.). Retrieved from http://archive.ics.uci.edu/ml/. 立. 學 ‧. ‧ 國 io. sit. y. Nat. n. al. er. 1.. Ch. engchi. 46. i n U. v.
(55)
數據
Outline
相關文件
一、研究動機 二、資料來源 三、模型建立 四、模擬預測 五、研究結果
第三節 研究方法 第四節 研究範圍 第五節 電影院簡介 第二章 文獻探討 第一節 電影片映演業 第二節 服務品質 第三節 服務行銷組合 第四節 顧客滿意度 第五節 顧客忠誠度
根據研究背景與動機的說明,本研究主要是探討 Facebook
由於 DEMATEL 可以讓我們很有效的找出各準則構面之因果關係,因此國內外 有許多學者皆運用了 DEMATEL
表 2.1 停車場經營管理模型之之實證應用相關文獻整理 學者 內容 研究方法 結論
股市預測在人工智慧領域是一個重要的議題。我們的研究使用混合式的 AI 以預測 S&P 500 芭拉價值指標和 S&P 500 芭拉成長股之間的價值溢價;S&P 600 小
中華大學應用數學研究所 研 究 生:黃仁性 敬啟 指導教授:楊錦章 教授 中華民國九十六年..
歷史文獻回顧法又稱史學方法、史學研究法、歷史法或歷史研究法。歷史文獻回顧 法的英文名稱除了 Historical Method 之外,亦有 Historical Research、Historical Study
