國立臺中教育大學數學教育學系碩士班碩士論文
指導教授:林原宏 博士
國小高年級學生在相關性問題之
解題規則階層結構與分群探討
研 究 生 : 陳 惠 萍 撰
中 華 民 國 九 十 六 年 六 月
摘要
本研究針對國小高年級學生在相關 (correlation) 問題的解題規則表現進行探 究,首先分析受試者在通過率的表現,以及不同年級與性別之受試者進行解題的 各類規則使用差異。其次呈現個別受試者的解題規則階層結構圖,以及受試者與 專家之解題規則階層圖之相似情形。此外研究中並依據受試者在各題的通過率進 行分群,以了解受試者在相關問題的解題規則反應類型。 本研究樣本以台中市小學部份高年級學童,共計 431 名有效樣本。且研究基 於文獻上解決相關問題的四個解題規則,分析受試者在相關性測驗的解題規則表 現。研究結果分述如下: 一、在相關測驗之三種題型中,全體的受試者皆在「次要面向不同問題」表現最 佳,「相等衝突問題」次之,「首位面向衝突問題」最差;且就測驗的通過率 而言,六年級高於五年級、男生高於女生。 二、不同年級在相關性測驗的解題規則表現達顯著差異,且六年級優於五年級; 而不同年級在各規則之表現皆達顯著差異,五年級學童之解題規則以規則 一、規則二為主,但六年級學童則以規則三和規則四的應用為主。但不同性 別的受試者在相關性測驗的解題規則表現未達顯著差異,且年級與性別在相 關性測驗的表現,其交互作用不顯著。 三、不同年級的受試者其解題規則結構圖與專家的解題規則結構圖之相似度表 現達顯著差異,且六年級的解題規則結構圖與專家較為相似,顯示六年級的 認知結構較五年級完備,其認知層次亦較高。但不同性別的受試者的結構圖 相似度表現則未達顯著差異,且年級與性別在結構圖相似度之表現,其交互 作用亦不顯著。 四、不同總分的受試者之解題規則階層各具特色,而相同總分但反應組型不同的 受試者,其解題規則階層亦具差異,所蘊含的認知結構亦不同,顯示總分無 法確實代表受試者的認知結構,應進一步參考其解題規則階層圖以了解受試 者之認知情形。 五、潛在類別分析顯示分為四群最佳,第 I 群的學生所使用的規則為規則一、規 則二與規則三的混用,顯示規則的使用並非單一性,也可能同時選用多種規 則。而第 II、第 III、第 IV 群的受試者主要的解題規則依序為規則四、規則 一及規則四。年級在分群表現達顯著差異且五年級的分群以第 I 群及第 III 群為主,六年級則以第 I 群、第 II 群為主。但性別在分群表現未達顯著差異。 關鍵字:次序理論、相關、規則評量方法、認知診斷The ordering hierarchies and the cluster on the performance of
correlation problem-solving for pupils
Abstract
The purpose of this study is to investigate the performance on correlation problems for pupils. The study shows the correct ratio of each item, and comparisions on rule graphs between grade and gender. The individualized hierarchical structures for rules based on ordering theory are discussed. Besides, the researcher classifify the examinee with latent class analysis according to the rule usage of examinee.
In this study, there are 431 objects of fifth and sixth graders from Tai-chung city of Taiwan. The results are as follows.
1. For the correct ratio of all items in three kinds of problems, the highest is in subordinate problems, the second is in conflict-equal problems, and the lowest is in conflict-dominant problems.
2. As to the rules usage on all items, there is significant difference between grade. Moreover, the performance of 6th graders is better than that of 5th graders. The pupils of 6th graders use rule3 and rule4 the most. On the contrary, the pupils of 5th graders used the rule1 and the rule2 the most. But there is no significant difference between gender for the rule usage. In the same way, there is also no significant difference between the interaction of grade and gender.
3. About hierarchical structures on rule usage, the similarity index between different graders is different. It shows that hierarchical structures of sixth garders are more similar to expert than that of fifth graders. However, the similarity index does not vary with gender. Besides, the interaction of gender and grade on similarity index is not significantly different.
4. The hierarchical structures on rule usage vary with subjects of different total score and response patterns. Therefore, total score can not explain the knowledge structure.
5. There are four latent classes with respect to laent class analysis. Cluster I consist of mixture the rule 1, rule 2, and rule 3. Cluster II, III, IV represent rule 4, rule 1, and rule 4. There is significant difference on the frequencies of clusters for varied graders. Most fifth graders belong to cluster I and III, while most sixth graders belong to cluster I and cluster II.
目錄
第一章 緒論
...1 第一節 研究動機...1 第二節 研究目的...3 第三節 名詞定義...5 第四節 研究假定與限制...5第二章 文獻探討
...7 第一節 相關性概念...7 第二節 規則評量方法...14 第三節 精緻試題的有向圖分析方法...26 第四節 潛在類別分析...28 第五節 次序理論...32第三章 研究方法
...35 第一節 研究架構...35 第二節 研究對象...36 第三節 研究工具...37 第四節 資料蒐集與處理...43 第五節 資料分析...44第四章 結果與討論
...50 第一節 相關性測驗之通過率...50 第二節 不同年級與性別之解題規則表現差異...53 第三節 不同年級與性別解題規則結構圖之差異...54 第四節 個人解題規則階層結構圖之比較分析...55第五節 潛在類別之分析...61
第五章 結論與建議
...68 第一節 結論...68 第二節 建議...70參考文獻
...72附錄一:相關性測驗
...78附錄二:規則計分之 SAS 程式碼
...84附錄三:解題規則結構圖相似度分析之 SAS 程式碼
...86表目錄
表 2-1 球之大小與滾得遠近之關聯表...9 表 2-2 常用的相關統計法...12 表 2-3 曲線相關與多變項資料相關之介紹...14 表 2-4 Awang 之相關性概念的四種解題規則...24 表 2-5 試題反應與規則之對應關係表...27 表 2-6 規則使用次數列聯表...33 表 3-1 研究樣本區域、班級與人數分配表...36 表 3-2 測驗試題之特質與對相關性解題策略各規則之意涵表...38 表 3-3 題目組成與各規則下的作答反應...40 表 3-4 各題選項與整道試題的反應解釋力...41 表 3-5 各題選項與整道試題的反應區別力...42 表 3-6 編號 355 受試者與專家的規則次序關係矩陣之比較...47 表 4-1 全體、五六年級與男女生在相關性測驗之各題通過率...50 表 4-2 全體、五六年級與男女生在各類型問題之平均通過率...51 表 4-3 二因子多變量變異數分析表...53 表 4-4 不同年級的單因子變異數比較 ...53 表 4-5 不同年級與性別之平均相似性係數...54 表 4-6 相似性係數之二因子變異數分析摘要表...54 表 4-7 不同潛在類別的組數下的 AIC、BIC 及 CAIA 值...61 表 4-8 規則使用次數列聯表...62 表 4-9 潛在類別分析下,四群樣本在各題的得分機率...62 表 4-10 潛在類別分析之四群情形與各規則之作答情形表...63 表 4-11 各分群與四種規則作答的符合比例情形...63 表 4-12 不同性別與年級的受試者分群人數分配分布...66 表 4-13 不同年級受試者的分群人數分配分布...67 表 4-14 不同性別受試者的分群人數分配分布...67圖目錄
圖 2-1 Awang 之相關性概念解題規則一模式...22 圖 2-2 Awang 之相關性概念解題規則二模式...22 圖 2-3 Awang 之相關性概念解題規則三模式...23 圖 2-4 Awang 之相關性概念解題規則四模式...23 圖 2-5 反應與規則對應圖...27 圖 3-1 本研究架構圖...35 圖 3-2 自編測驗之第一題...38 圖 3-3 專家的解題規則結構圖...46 圖 3-4 編號 355 受試者之解題規則結構圖...49 圖 4-1 全體在各問題類型的通過率...51 圖 4-2 五、六年級在各問題類型的通過率...52 圖 4-3 男女生在各問題類型的通過率...52 圖 4-4 不同總分的三位受試者的解題規則階層圖...56 圖 4-5 解題規則階層圖(高分組)...57 圖 4-6 解題規則階層圖(中分組)...58 圖 4-7 解題規則階層圖(低分組)...60 圖 4-8 第 I 群受試者在四種規則作答的符合比例...64 圖 4-9 第 II 群受試者在四種規則作答的符合比例...64 圖 4-10 第 III 群受試者在四種規則作答的符合比例...65 圖 4-11 第 IV 群受試者在四種規則作答的符合比例...65第一章 緒論
本研究旨在結合規則評量方法、次序理論與潛在類別分析方法(Latent Class Analysis,簡稱 LCA),分析國小五、六年級學童在相關問題的解題規則表現。本 章就研究動機、研究目的、名詞定義與研究限制等四節進行闡述。第一節 研究動機
解決問題的能力在九年一貫數學課程中,是頗受重視的要點(教育部,2003), 其在數學領域備受強調與重視。而解決問題的過程中,學生的解題規則(或稱策 略)往往扮演著重要的關鍵角色,不僅是教師們在教學上時常深究的問題,對學 生的數學學習發展更深具意義,故而在教育界頗受關注,亦是研究者關切而欲深 入了解之問題。 林原宏、游森期 (2006) 指出解題者面對問題時,常因既有的經驗或知識架 構影響其解題的規則,然而有正確的解題規則,亦有不正確的解題規則,採用正 確規則會有對的答案,但不正確的規則其答案可能錯,亦可能對,甚至同一位解 題者,亦可能交替地使用不同的規則來解題,故而答案的正確與否無法代表受試 者的認知,進一步分析解題者的解題規則,以判斷解題者的知識結構甚為重要。 解題過程中解題規則使用的先備條件關係亦具意義。例如,一位解題者先考 慮使用規則 A 來解題,若不使用規則 A,則使用規則 B,則稱解題過程中,規則 A 為規則 B 的先備規則,而這種規則間的先備關係,恰可透過次序理論之應用來 呈現解題規則的階層性,不僅可呈現出受試者的認知型態,使我們更清楚解題者 的知識結構,對於教師的教學更具輔助、參考之功用。反觀國內外針對數學領域 之解題策略的研究,已有不少的實驗與研究(吳德邦、馬秀蘭、朱芳謀和簡秀儀, 1997;洪繼賢、劉祥通,2004;馬秀蘭,2005;Jansen, & van der Maas, 2002;Richards, & Siegler, 1981;Siegler & Chen, 2002;Saake, Sattler, & Conrad, 2005),卻鮮少將次序理論應用於解題規則。故而本研究將次序理論應用於相關性問題之解題規則 階層,應有其意義及價值。
此外,在學生的學習過程中,教學者往往希望藉由「評量」來了解學習者的 學習成果,診斷學習者是否已達教學目標。然而余民寧、陳嘉成 (1998) 指出以 往的評量,常著重在學習者的最後所呈現的「總結性評量」,卻忽略了知識建構 過程的「形成性評量」,或者忽略了Bart, Post, Behr, & Lesh (1994) 所提及半密集項 目 (semi-dense item) 的功用,而這樣的結果,往往讓「半成就」的學生誤以為學 習沒有進步,甚至因而影響其學習意願,而此結果與評量之原始目的,卻造成相 反效果,得不償失。 因而在設計評量系統時,應更著重從學生的評量呈現出目標的階層性,了解 距離目標尚須努力的方向與要項,檢視過去的測驗往往以「試題」做為測驗最基 本的分析單位,所呈現的是全對或全錯的樣貌,忽略學習者有「部分」了解的可 能,為此我們更應注重測驗過程中的各各環節,以各概念或解題規則作為施測的 單位,而非僅以整個概念或試題為分析單位,方能更深入了解學習者的學習情 形。如此不僅可以得知學生在某些概念的錯誤,更能藉由分析其解題規則的使 用,以得知其錯誤的原因,並進而指導改進,所以此種評量方更具意義。此亦是 本研究強調以「解題規則」作為測驗的分析單位的因素之ㄧ。 針對數學概念之解題規則的研究,國內外以往不乏有以晤談、實作方式進行 質性的研究(林香、張英傑,2004;許美華、游家政,2001;蕭毓秀、鍾靜,2002; Inhelder & Piaget, 1999),亦有部分量化的研究(林原宏,2006;林原宏、游森期, 2006;羅友任,2003; Boom, Hoijtink, & Kunnen, 2001;Raijmakers, Jansen, & van der Maas, 2004;Siegler & Svetina, 2006),而余民寧、陳嘉成 (1998) 指出為使認 知診斷的評量技術更為精確,必須兼顧「質化」與「量化」的評量歷程,其中, 質化的評量歷程有賴研究者的專業知識與經驗,使測驗更具效度;量化的程序則 可簡化錯誤解題之解讀,可作為質性分析的先遣作業,協助教學者在短時間內, 獲取學生整體的學習訊息,以便於測驗後的診斷分析或補救教學之安排。本研究
採用量化分析,希望協助教學者分析學生整體的學習訊息,以作為後續研究及分 析之參考。 舉凡各領域的相關研究與生活上的問題皆與相關性思考有關,譬如:擁有什 麼樣的基因容易引發什麼樣的疾病(詹芳瑜,2005)、什麼樣的人格特質其學習 成就較高(張志榮,2005)、以及什麼樣的學經背景其對工作壓力的承受情形較 佳(葉錦光,2006),這些都是與相關性有關的問題與研究;而生活上的種種語 言、文化、表達也皆與相關性有關,語言能力愈好,其學習能力愈佳、態度愈積 極的人就愈容易成功等。然而針對相關性問題之認知層面的探究卻少有耳聞,尤 其針對學齡兒童的相關性問題研究更為少見,故認為應有進一步研究之必要。 除生活之應用外,相關性 (correlation) 概念所涵蓋之範圍亦相當廣泛, Inhelder & Piaget (1999) 指出相關性問題的概念涉及分類、比例、機率和邏輯命 題等概念,而 Siegler (1976, 1982) 的研究更發現相關性概念之概念不易透過直接 教學提升概念的進展,故而在教學或研究上相關性概念亦是值得挑戰之問題。 而目前在國民小學的教材中,相關性概念未能呈現全貌,僅以其有關的概念 呈現,諸如:速率、比例、比率及機率課程(教育部,2003),亦可見相關性認 知概念研究之缺乏,且與相關概念有關的課程多呈現於高年級,故而研究者將以 國小高年級學童作為研究對象,期能對此主題的研究與分析,關注這樣的數學概 念,也希冀後續之研究者能以此參考,針對學童相關性概念更進一步之探究。以 提出更佳的方式讓學習者對這些概念融會貫通,以達更有效率的學習。
第二節 研究目的
本研究所編製的一份相關性測驗,用以評量國小高年級學童的解題規則類型 之表現,從認知研究之相關文獻可知年級與性別等因素可能影響認知(高耀琮, 2002),但有關相關性測驗之認知研究並不多見,故而在本研究中探討受試者在 相關性測驗中的表現是否會因年級與性別等因素而有所差異。 隨著兒童學習經驗差異性的不同,其認知結構亦有所不同,可藉由兒童的解題規則次序性了解其認知結構之差異,故而有關解題規則之次序性分析研究甚為 重要,然而以此作為認知結構探討的文獻尚不多見,而 Bart & Krus (1973) 所提 出的次序理論 (ordering theory) 可用以分析學童的解題規則階層結構,故而在本 研究中,將應用次序理論分析受試者在相關性概念之解題規則階層,以作為診斷 受試者在相關性概念的認知結構之參考。
規則評量方法可將受試者的解題規則予以一般化,而 Jansen & Van der Mass
(1997) 所提出的潛在類別分析方法(簡稱 LCA)則可根據受試者的解題規則而分
群,且同一族群之受試者具有相同特質,故而在本研究中將應用潛在類別分析方 法進行分群以了解各群的解題規則特色,並比較各群在使用規則的類別是否因年 級與性別的不同而有所差異。
許多專家與生手的研究中(林清山,1991;Larkin, Mcdermont, & Simon, 1980; Michelene, Feltovich, & Glaser, 1981; Shavelson, 1972, 1974)可以發現專家與生手在 解題規則方面亦有所差異,故而在本研究中專家與生手的解題規則次序結構圖之 比較分析亦是值得探究之處。再者,以往認知結構的比較多以視覺化呈現,而本 研究欲將認知結構之比較予以量化方式呈現。 綜合上述,本研究之主要目的分述如下: 一、了解受試者在相關性測驗之表現情形。 二、了解不同年級與性別之學生在相關性測驗各規則表現之差異情形。 三、了解不同年級與性別之學生其解題規則結構圖之差異情形。 四、了解總分或反應組型不同的個別學生,在相關性問題的解題規則次序階層圖 之異同。 五、根據學生在相關性測驗的得分將學生分群,以了解各群學生在解題規則的特 徵,並分析年級與性別的因子下,其分群解題規則的人數分布的差異性。
第三節 名詞定義
本節將就研究中所涉及之相關名詞進行定義與說明如下:一、解題規則
人們在解決問題時會使用一套思考或策略,而當一群人使用相同的思考方法 則為解題規則或解題策略。二、相關性測驗
本研究之相關性測驗僅限於「正相關性」的概念,測驗均以三個選項的選擇 題呈現,且透過受試者在三個選項的反應以量化的分析方式解釋其四種解題規則 的使用情形,從而了解受試者的解題規則表現、解題規則的使用次序階層以及其 認知結構。第四節 研究假定與限制
本節將說明本研究之假定與限制,分述如下:一、研究假定
有關本研究所涉及之方法或理論,有其基本假定,分述如下: (一)規則評量方法的基本假設 (Siegler, 1981; 1982) :1. 人們依照假設的規則 來解題;2. 所表現的模式可透露假設的本質,意即可從人們解題的試題反 應之組型,呈現出其所使用的規則;3. 將概念發展視為一種解題中可逐次 增加的有用規則,意即規則是具有層次性的,且可使解題有效進行,在本 研究中皆符合其假設。 (二)潛在類別分析(簡稱 LCA)的基本假設:潛在類別分析的潛在變數及所觀 察的變數必須為類別變數,而非連續變數。 (三)各解題規則或試題可經由計分及圖示化呈現元素的階層次序性。二、研究限制
本研究之主要限制分述如下: (一)限於經費與人力,本研究之對象僅限於台灣台中市之部分小學高年級學 生,未能擴及各縣市樣本,樣本數不足,故而研究結果無法進行推論。 (二)本研究以規則評量方法作為研究基礎,但有關相關概念的解題規則受限於 研究環境,無充足的時間與人力,無法針對所有的解題規則進行探究,故 在所研究的相關概念解題規則,僅限於具代表性、符合一般性的四種解題 規則,並探討受試者選擇四種規則的表現情形。 (三)本研究的相關性測驗因考量國小高年級學童在課程上對相關性概念的接觸 較少,以及解決相關性問題之經驗缺乏,故而將相關性測驗侷限於「正相 關」問題,簡化測驗之複雜度。第二章 文獻探討
第一節 相關性概念
相關性 (correlation) 是指兩個隨機變量次序之間對應關係,當其中一個變量 趨向增加或減少時,另一個隨之改變,則稱兩者為正相關 (positive correlation) 的,反之,則稱為負相關 (negative correlation) 或逆相關 (inverse correlation) (Borowski & Borwein, 2004) 。而本節將針對與相關性概念分成三部份介紹,以期 對相關性概念有更深入的了解,一、關係與分類;二、相關性基模的發展;三、 統計上的相關係數與應用。
一、關係與分類
在相關性的認知發展中,必須依賴分類概念的成熟。J. Piaget 曾指出當兒童 思維可以脫離具體事物進行時,其首要成果便是使物體間的「關係」和「分類」 從他們具體或直覺的束縛中解放出來(李其維,1995)。其中,兒童在分類 (classes) 與關係 (relations) 概念理解之關聯更是 J. Piaget 的一個創見,認為兒童一開始會 將分類與關係的概念分開,但最後會統整成合成一體的理解(林美珍,1996)。 而J. Piaget 曾將人類的認知發展分為感覺動作期、前運思期、具體運思期、形式 運思期,各時期在分類與關係之理解亦有所不同,研究者將其整理如下: (一)感覺動作期:物體間的關係就像分類方式一樣,且是經由感覺動作而發展。 例如:「愈用力做什麼事,其結果愈大」。 (二)前運思期:前運思期之早期漸漸發展分類,後期已能產生一致的分類,但 在推理上無法解決階層集合的包含關係;而在序列問題 (seriation problem) 上,也因傾向於專注某一向度而有些困難。 (三)具體運思期:此時期的兒童將分類和關係概念視為單一的整體系統,而在 多元分類問題 (multiple classification) 中是兩種向度的交錯考量,如形 狀、顏色兩種向度,此階段的孩子大多能同時考量兩種向度。(四)形式運思期:形式運思的推理活動讓青少年對關係中的關係,以及分類中 的分類問題進一步的思考,讓青少年在邏輯可能的情境中去解釋觀察的結 果,如化學液體的組合的推理活動。
二、相關性基模的發展
J. Piaget 認為相關性的觀念衍生於概率觀念和一種與比例結構相似的結構之 綜合。其中,相關性亦是J. Piaget 總結出八種形成結構化的運算格式之ㄧ,另有: 組合、比例、兩個參照的協調、機械平衡、機率、乘積補償、超出直接經驗證明 的守恆形式,如:慣性定律、動量守恆(李其維,1995)。 此外,相關性的表徵在最簡單的形式中,是與機率基模有關之形式運思基 模,藉由原本的機率基模來架構出相關性之基模 (Inhelder & Piaget, 1999) ;為使 相關性的認知基模有更詳細的了解,在此將同時說明機率基模與相關性基模的發 展過程。(一)機率基模的發展過程
機率基模的發展大致可分為以下階段,各階段說明要點如下:
1.階段一:非守恆亦非分配定律 (neither Conservation nor Law of Distribution) 前運思期階段的樣本對「機會」的意思尚不了解,也無法知道「相關」的 特質。在面對變動時,認為任何事都可能是造成變動的原因,有時甚至以一個任 意的次序關係來解釋,而造成這種想法的限制可能是缺乏保留概念所造成,無法 將因素固定以進行分析。
2.階段二:擴散可能性反應及判斷分布區域 (Diffuse Probilistic Responses then Determination of a Zone of Distribution)
七到八歲的樣本會開始思考變動的原因,到了九歲則想要找出有系統的變動 因素,甚至畫定變動的區域範圍,例如考慮重量及體積之變動因素。但該階段因 未能有系統地獨立變數,故對機率及限定變數區域的想法仍無法發現其潛在的相 關性架構。同時該樣本將變動視為多種因素造成而無法將個別面向獨立出來,受 限於僅能透過具體操作來描述定律實驗而無法區分變數,故無法下結論。
3.階段三:解釋分布及判斷機率變動的定律 (Explanation of the Distribution and Determination of the Law which Underlies the Chance Fluctuations)
此階段的學童開始考慮隨機變數,並能獨立出隨機變數的定律,且獨立的過 程需靠相關性基模協助完成。學童透過將變數區分成所有可能的組合而找出定 律,但在有系統地分析變動結果仍有困難。而此階段的學童因以往有比例運思基 模衍生至公式化的概念,故而能漸進式的發展到相關性的運思基模。 舉一例子說明獨立出定律的過程,並以表2-1 輔助說明(資料採自 Inhelder & Piaget, 1999)。我們假設樣本想證明最小的球可以滾最遠時,令p為假設球比標 準球來的小的命題,而p則為比標準球來的大的命題; 為比標準球滾的遠的事 實, q q則為比標準球滾的近的事實。觀察變動並指導樣本對四種可能的組合做出 總結:(p.q)∨(p.q)∨(p.q)∨(p.q)=(p∗q),其中(p∗q)表示完整的證實。 表2-1 球之大小與滾得遠近之關聯表(資料採自Inhelder & J. Piaget, 1999)
小 (p) 大 (p) 遠 (q) a= p q. c= p q. 近 (q) b= p q. d = p q. 由表2-1 中可知四種可能的組合,計算後可簡化成相關性的形式,我們稱為 「關聯係數」,樣本會對照四種可能性,不計算表中的數量也不做數量的定量化, 而是使用大於、小於來加強定量的關係,包括對表中 和 及b和 兩組數量的比 較,其中 和 代表確定,而b和 代表不確定,因此他們的推論可能呈現為: 或( ) ;但無法有系統化的分析與統整。 a d c a d c (a d+ ) (> b c+ ) a d+ < (b c+ ) (二)相關性基模伴隨機率基模發展的過程 潛在的相關性基模在機率基模的階段三呈現,首先對樣本區分成兩類,一種 為能在兩種變數之假設關係下確定的情形 (a、 ) ,一種則為無法確定的情形 (b、c ) ,今將問題簡化成以下類型: d a=藍眼金髮( .p q);b=藍眼褐髮( . )p q ;
c=褐眼金髮( . )p q ;d =褐眼褐髮( . )p q 此實驗情境提供我們從邏輯命題觀點來看,並與計算問題及歸納法相對照,p 代表藍眼,q代表金髮,有利於相關性的確定狀況會與等價的( . ) ( . )p q ∨ p q 相對應, 而不確定的狀況則會與互逆的( . ) ( . )p q ∨ p q 相對應,呈現出相關性。 相關性基模發展的重要過程乃伴隨機率基模,將機率基模之階段三細分為階 段三之A 及階段三之 B,而兩者皆為階段三的子階段,分述如下: 1.階段三之 A: 此階段初期對類別與連結的架構有些困難,僅考慮到 而未考慮 ,且認為 的關聯是b而非 ,因而在了解對角線的比較前,須先進行垂直(指眼睛)或水 平(指頭髮)比較的過程。一旦克服類別關聯錯誤之困難後,相關性就不再是 與 基本比例的簡單機率,而可有更近一層的認知。 a d a d (a d+ ) (a b c d+ + + ) ) 然而,因為( )和( 基本比例的簡單機率可透過一系列的卡片推 論而來,故而在階段三之A 不須出現假設演繹推理仍可正確解題。簡言之,階段 三之 A 的認知特色是早期會認為( ) a d+ a b c d+ + + a d+ 及(b c)+ 是各自獨立的情形,但未想到 及 兩狀況相關的可能性,而較成熟時則會考慮 (a d+ ) (b c+ ) (a d+ )或 與整 體,但仍不考慮 及 關係。 (b c+ ) ) (a d+ ) (b c+ 2.階段三之 B: 相 關 性 的 定 性 形 式 在 階 段 三 之 B 不 再 被 重 視 , 反 而 會 根 據 基 模 ) . ( ) . ( ) . ( ) . (pq ∨ pq ∨ pq ∨ pq 來區分四種可能性,並知道(p.q)=R(p.q)表示兩者等價, 且 知 道(p=q)=(p.q)∨(p.q) , 可 知 兩 者 皆 是 確 定 的 ; 同 理(p.q)=R(p.q) , 及 ) . ( ) . ( ) (p=q = pq ∨ pq 。因此在三之 B 階段的樣本是根據對角線及 之和與 之和的數字關係來推理,可自發性的考慮到確定情形及不確定情形的關 聯,並連結到可能狀況之總和,即是會採用邏輯命題結果的階段。 ) (a+d ) (b+c 而有關相關性的公式,其基本的形式如關聯係數 ( ) - ( ( ) ( a d b c R a d b c ) ) + + = + + + ,代表兩 特性的相關程度,該公式中有三個結論:
(1)若E
[
(p.q)∨(p.q)] [
=E (p.q)∨(p.q)]
則兩特性為零相關; (2)若E[
(p.q)∨(p.q)] [
> E (p.q)∨(p.q)]
則兩特性為正相關; (3)若E[
(p.q)∨(p.q)] [
<E (p.q)∨(p.q)]
則兩特性為負相關; 其中E 為證實被考慮的命題之總和。 相關性之關聯係數R 以比例形式呈現,與 J. Piaget 認為速度是距離和時間二 者相關的認知結構相似(王文科,1994),其距離和時間的關係恰可以比例形式 來呈現。由此可見相關性概念的發展過程之繁複與環環相扣,所含面相的深與 廣,更讓我們深知相關性概念學習的過程中之重要性。 綜合以上可知相關性的認知發展與必須在分類概念成熟下而發展,且相關性 的基模發展是伴隨機率基模發展而來,同時命題邏輯組合系統亦是形成相關性之 認知架構的重要支柱,以下簡化說明如下: 1.基本機率概念引導: 兩事實間是否有關係,是包含有機遇的干擾,可猜測相應的頻率數,首先對 物件區分成兩類,一種為能在兩種變數之假設關係下考慮確定的情形 (a、d ) , 一種則為無法考慮確定情形 (b、 ) ,今將問題簡化成以下類型: =藍眼金髮 ; =藍眼褐髮 c a ( . )p q b ( . )p q ;c=褐眼金髮( . )p q ;d=褐眼褐髮( . )p q 。 此實驗情境提供我們從邏輯命題觀點來看,與計算問題及歸納法相對,p代 表藍眼,q代表金髮,有利於相關性的狀況會與等價的( . ) ( . )p q ∨ p q 相對應,而不 確定的狀況則會與互逆的( . ) ( . )p q ∨ p q 相對應,把肯定情況的數目( . ) ( . )p q ∨ p q 與不 肯定情況的數目( . ) ( . )p q ∨ p q 進行比較即可得知。並可透過此實驗情境說明相關性 基模建立的程序,如下: (1) 僅考慮 而未考慮d,且認為 的關聯是b而非 ,因而在了解對角線的比較 前,須先進行垂直(指眼睛)或水平(指頭髮)比較的過程。 a a d (2) 認為(a d+ )及( )是各自獨立的情形。 ) b c+ (3) 考慮(a d+ )或(b c+ 與整體的關係而不考慮(a d+ )及(b c)+ 關係。(4) 根據基模(p.q)∨(p.q)∨(p.q)∨(p.q)來區分四種可能性,並知道(p.q)=R(p.q)與 ) . ( ) . (pq =R pq 皆為等價的關係,根據對角線及(a+d)之和與 之和的數字 關係來推理,並連結到可能狀況之總和,此為相關性基模的成熟模式。 ) (b+c 2.相關性與邏輯命題推理分類的關係: 尋求相關時,要求有一組合系統,不僅要求主體對四種可能的情形加以分 類 , 並 能 夠 將 確 定 情 形 及 不 確 定 情 形 的 組 合 加 以 分 離 , 如 將( . ) ( . )p q ∨ p q 和 ( . ) ( . )p q ∨ p q 相對照,故而相關性的發展格式亦依賴於命題組合系統。 3.相關性引入公式化的比例架構: ( ) - ( ( ) ( a d b c R a d b c + + = + + + ) ),代表兩特性的相關程度。
三、統計上的相關係數與應用
統計上的相關是許多研究常會應用的統計方法,而研究上所謂的相關是指兩 變項 (X、Y) 之間相互發生的關聯程度。透過雙變項資料 (bivariate data) 的分 析,常可研究兩變項間的相關問題,且通常可繪製資料散佈圖,或計算相關係數 等方式來呈現。以下參考林清山 (1992) 介紹較常用的相關統計法,並就其適用 變數、計算公式與顯著性之考驗來做說明,整理如表2-2。 表2-2 常用的相關統計法 名稱 適用資料變數與計算公式 顯著性考驗 皮爾遜積差相關 (Pearson product-moment correlation) 適用於兩個變項都是等距或比率 變項的資料,是一種最重要且最常 用的統計方法。公式: 1 Z Zx y xy =∑
− N γ t檢定 φ相關係數 (phi-coefficient) 兩個變項均為二分的名義變項。 公式: y x y x y x xy q q p p p p p − = φ 卡方檢定表2-2 常用的相關統計法(續) 名稱 適用資料變數與計算公式 顯著性考驗 列聯相關係數 (Contingency- coefficient) 兩個變項不只分為兩個類別時的 名義變項。公式: 2 2 x N x C + = 卡方檢定 點二系列相關 (point-biserial correlation) 一個變項為二分名義變項,而另一 變項為等距或比率變項。 公式: pq S X X t q p − = s γ t檢定 z檢定 二系列相關 (biserial correlation) 兩個均為常態的連續變項,但其一 變項乃因人為因素或其他理由而 二分。 公式: y p S X X t t p − ⋅ = bi γ 斯皮爾曼等級相關 (Spearman rank-order correlation) 兩 個 變 項 都 是 次 序 變 項 的 資 料 時,通常,使用在計算兩組等級之 間一致的程度。 公式: ) 1 ( 6 -1 2 2 s =
∑
− N N d γ t檢定 肯德爾等級相關係數: τ 係數 (kendall's tau coefficient) 計算兩個次序變項的相關,適用情 況同斯皮爾曼等級相關。公式: 1) ( 2 1 + = N N S τ z檢定 肯德爾和諧係數 (Kendall's coefficient of concordance) 兩個次序變項的相關通常用以計 算兩組以上等級之間一致的程度。 公式: ) ( 12 1 k2 N3 N S W − = 卡方檢定除了以上介紹常用的相關統計法之外,另有適用於曲線相關時的相關比 , 以及適用於多變項資料的相關,包括淨相關、複相關等,茲分別說明如表2-3。 2 η 表2-3 曲線相關與多變項資料相關之介紹 名稱 適用資料變數與計算公式 顯著性考驗 相關比 (η, correlation ratio) 適用於曲線相關的情形,亦即隨著 X 變項 的增加,Y 變項最初可能先增加,而增加到 某一程度後,可能反而減少。公式: t b SS SS = 2 η F 檢定 淨相關 (partial correlations) 適用於多變項資料的相關,係指除去其它變 項的影響後,兩變項之間相關的程度。公 式: ) 1 )( 1 ( 2 23 2 13 23 13 12 3 12 r r r r r r − − − = ⋅ t 檢定 複相關 (muitiple correlation) 係指變項X1與變項X1 ) 的相關,亦即根據多 個 變 項 ( ) 所 預 測 的 分 數 ( k X X X1, 2,..., 1 X) ) 與實際分數 (X1) 之間的相關。 公式: 2 23 23 12 13 13 23 13 12 12 3 12 1 ) ( ) ( R r r r r r r r r r − − + − = ⋅ F 檢定
第二節 規則評量方法
一、規則評量方法之內涵
(一)規則評量方法之意義 規則評量方法是將解題者在解題過程中用以解決問題的一系列替代性規則 予以一般化的評量方法 (Siegler, 1981),以解題者在解題過程中的反應得知其所 使用的規則,並以規則作為評量之單位分析、了解解題者之思考方式或層次。 (二)規則評量方法之基本想法1984) 。在Siegler (1982) 的研究中,規則評量方法的基本想法認為人們的知識對 學習能力有重要影響,而透過評量人們已知知識來提升其學習能力便是規則評量 方法之目的。所以,規則評量方法是透過對解題者進行解題規則的評量,以評量 出解題者的知識進而檢驗出知識與學習不同的基本發展,並可針對學習者所不會 的或所需要的先備知識進行輔導,如此更可避免重複教授學習者已會的知識而造 成浪費。 (三)規則評量方法教育上的意義 Siegler (1982) 將規則評量方法應用於認知發展時著重於三個面向:孩子的已 知知識、孩子學習的能力以及刺激孩子的編碼。並對二議題感到興趣,其一是不 同的起點知識對學習的影響,亦即具有不同起始知識的學生,可否預測使用什麼 樣的引導方法可使學生獲得最有效的學習,其二是不同發展下其學習能力的差異 如何。而這些不僅是關心教育發展的人士們所關心並在意的,亦可見規則評量方 法在教育上的意義。
有關規則評量方法的研究中 (Bart & Orton, 1991; Siegler, 1976, 1981, 1982) ,Siegler (1982) 應用規則評量方法來研究孩子在13種問題的推理,包括: 槓桿、投影、填滿、機率、數的保留、液體質量保留、固體質量保留、數數、河 內塔問題、道德推理問題、時間、速度、及距離問題,且因採用規則評量方法, 而產生對教育有重要影響的八個結論,而這些結論可讓我們更深入思考教育的意 義與方法,說明如下: 1. 透過研究發現,以往我們認定是孩子們的基礎知識,仍有部分可能有誤,例如: 結果發現規則評量方法所認定的規則與J. Piaget的保留概念所使用的方法並 不相符,有些甚至更為複雜。 2. 使用規則評量方法著重在不同任務間的推理過程之穩定性程度之比較。 3. 有許多的研究發現孩子們的推理,以一個月的間隔時間下,其所測得的結果有 75%的人會使用相同的方式作答,意即較不受時間性的影響,可推知孩子的推 理有其規則使用的穩定性。
4. 正確評量學生的已知知識將能提供學生有效的指導方式。 5. 特殊的知識並非影響學習能力的唯一因素,年齡亦是影響其發展或規則選擇的 因素之ㄧ。 6. 編碼與學習能力的關係中,有限的編碼會使學習能力亦受到限制,多一些編碼 的方式可幫助學生擴展其學習能力。 7. 直接的引導往往無法使學生真正的懂得使用編碼,應多著重改善學生編碼的因 素,例如:給予學生感覺到被贊同的經驗、分析態度等的鼓勵。 8. 使用規則評量方法的經驗可獲得一系列的知識,且在過程中可鼓勵孩子們展現 出其分析的態度,並感受到被贊同的經驗。
此外,Bart & Orton (1991) 則將規則評量方法應用在研究 28 位小學老師於 32 小時的數學在職工作坊中,試圖採用直接引導的方式改變教師在了解這些概念的 層次,結果發現:比例概念層次有顯著提升,而機率及相關性概念之層次則無顯 著改變,但在機率概念的表現仍屬三者中最高的思考層次,由此可見直接引導在 改進相關性概念的發展上甚為薄弱。 (四)規則評量方法的研究假設與限制 儘管規則評量方法在教育上有其基本的研究方向與目的,但在方法的使用上 卻有基本假設與限制 (Siegler, 1982) :1. 人們依照所假設的規則來解題;2. 可 從解題者在試題的反應組型看出其所使用的規則;3. 概念發展可透過逐次增加的 有用規則來呈現,意即解題的規則是具有層次性的且可使解題有效進行。 而在本研究中,為求使知識評量技術能更可信且有其應用性,我們不再著重 錯誤的推理或深入分析學生的推理過程,而使用規則評量方法來整合受試者解題 過程中其所使用的規則。在此,為使研究過程具有標準化的診斷過程,也為避免 因回饋增長了孩子的知識或能力而影響研究,強調孩子的評量過程中能夠獨立完 成,不再如J. Piaget的任務實驗給予回應,而以紙筆測驗的項目取代,每一問題 提供3個選項,並忽略受試者口語化的判斷,定義出四個規則作為受試者解題之 模式,且每種規則皆會和一特定的反應組型相對應。
(五)規則評量方法的作法 而Siegler (1976, 1981) 應用規則評量方法在槓桿問題,設計出簡化的樣貌以 作為標準化的診斷過程,且與Inhelder及Piaget不同,對此任務以大量的項目取代 而不再給予受試者回饋或指導也忽略受試者口語化的判斷,並定義出四個規則作 為受試者解題之模式:規則一僅注意重量之單一向度;規則二僅注意距離之單一 向度;規則三同時注意重量與距離,但當一邊的重量較重而另一邊的距離較遠, 則會產生困惑,而隨機作答;規則四則是正確規則,將重量與距離相乘後進行比 較。此外,Siegler (1981) 發展出6種問題類型以與4個規則相配,以測驗其正確性, 每種規則皆會和一特定的反應組型相對應,且由Siegler (1981) 的分析得知樣本會 因問題類型之不同,而選擇較簡單之規則來解題,而其問題分析之特徵則以大家 所熟知的決策樹 (decision tree) 來呈現。 (六)規則評量方法的所受到的爭議與後續補救 儘管規則評量方法在認知發展及簡化任務等兩方面在教育上具有相當顯著 的貢獻,但仍受到許多爭議 (Boom et al, 2001) ,分述如下: 1. 所訂下的解題規則決策樹屬於人工加工品,故而假設樣本會透過限定的規則來 解題恐怕會忽視受試者解題規則的多樣性。 (Wilkening & Anderson, 1982) 。 2. Normandeau, Larivee, Roulin, & Longeot (1989) 的研究認為Siegler在槓桿問題
中所訂定之規則三(規則三是指:同時注意重量與距離,但當一邊的重量較重 而另一邊的距離較遠,則會產生困惑,而隨機作答)並非同一性質,而是使用 整合的規則,但此整合規則並未被列為解題規則之ㄧ,且可能另有規則未被發 現,例如加法或比例規則(稱之為QP規則),也有些規則是透過猜測或抵銷的 想法,未能與先前所訂的規則相符合。 3. 有關Siegler在槓桿問題中所訂定之規則三的反應機率,較可能是因受試者無法 了解呈現的方式而使試題的反應機率為1/3,在這樣的情形下可能有較高的誤差 變項。 4. 樣本在進行的過程中,可能會對一些規則進行有系統的轉換,而使其反應看起
來像是使用較高層次的組織反應,卻非真正會使用高層次的規則之情形產生。 可能會有將某些作法歸類到規則三的情形,而無法看出其解題規則。
5. Jansen & Van der Mass (1997) 指出與規則相符的統計方法尚未被驗證,因此透 過實際操作是無法明確地區分出各類規則的,意即對規則並未獲得明確之評量 標準。
6. Thomas & Lohaus (1993) 指出爭議中較大的問題:什麼樣的實證規則可以確定 或反駁規則的存在。規則被視為獨特的策略,而學生所採用的規則可能有很多 種,無法將規則全部列出。 而丁振豐、林清山 (1993) 亦指出所研究之規則三的錯誤類型也與Siegler不 同。此亦表示受試者未必使用單一性的規則,有時甚是同時採用兩種不同的規 則,整合兩種規則的特性。針對上述問題,在有限的時間與人力限制下,確實無 法呈現出所有可能的解題規則,且就簡化與教育應用的意義看來,過多而繁雜的 解題規則恐失去分析價值,故而呈現具代表性的解題規則才具實際意義,而此亦 是重要的研究方向。再者,Jansen & Van der Mass (1997) 提出解決規則評量方法規 則單一性質之缺失的方法—潛在類別分析方法 (LCA) ,用以區分受試者反應組 型的類別,可透過受試者對所隸屬類別的相符程度,推知受試者使用各規則的情 形,解決受試者使用單一解題規則的不合理情形。此外,Boom et al. (2001) 為求 補救規則評量方法的缺失,亦將LCA應用在Siegler的槓桿問題中,透過所蒐集的 反應機率進行實證性的類別分析,而所涉及的反應策略能以一致的觀點合理地進 行解釋、闡明。 而將LCA應用於規則評量方法的實際試驗中,Boom et al. (2001) 有以下發 現:1. 使用LCA假設學生可被分為有限個類別下,由槓桿任務所獲得的反應組型 與潛在反應類別有所差異,其中,一類未必只有一種規則;然而LCA亦無法呈現 所有項目反應的全貌。2. 發展與年齡的在各類別的趨勢關係不同。3. 發展過程 中是階段性不連續的成長,並非依循著規則的層次性而使用,意即其發展亦可能 是跳躍式地進行著。
綜合以上可知,透過潛在類別分析,了解不同類型的受試者使用規則的情形, 使規則評量方法的意義更為明確,雖然仍未能呈現所有規則之樣貌,但卻能呈現 出各類學生在各項規則的表現,以了解受試這在此概念的發展情形,這樣的發現 確實是很大的突破,使規則評量方法更添實際應用的意義。
二、解題規則的選擇與發現
應用規則評量方法有其基本限制:解題者依照假設的規則來解題。故而有關 所測驗的概念必須有其解題規則作為根本,因而在此簡述有關解題規則的選擇與 發現過程。 (一) 解題規則與認知發展相關 解題規則是指人們進行解決問題時,會使用一套思考或策略,而當一群人使 用相同的思考方法或策略,則稱為解題規則。再者,解題的過程會使用其特有的 解題規則,或稱之為策略,甚至解題規則往往與認知發展有關,而在此方面已有 許多研究與發現,諸如:Siegler (1981) 指出 J. Piaget 在液體量保留問題在概念內 發展研究談到,第一階段的孩子無法同時對液量的高度及寬度進行判斷,僅能考 慮高度;而在第二階段的孩子則會留意第二個相關面向—寬度;但在第三階段的 孩子能不顧所造成的數量及本質改變,很快的描述液體的量是守恆的。可知不同 階段的孩子其面對問題時,所考量的面向不同,其所能採用的解題方式也有所異。 (二)解題規則發現的研究方法 在研究學童解題規則中,以往多以晤談方式進行,但所耗時間甚多,且所考 量的因素時而無法達到理想,而伴隨著資訊時代的來臨,已將電腦運用在學童的 解題規則之發現,例如:Shrager & Siegler (1998) 運用電腦模擬來整合學齡前兒 童在加法策略的選擇,而在學童加法策略本來就至少有八種解題策略的平行資 料,透過電腦模擬及了解孩童的能力下,可以簡單的找出孩童可能的解題策略並 發現新的策略,對於解題規則的發現確實是一大突破。有關解題規則之研究,尚有Tatsuoka & Baillie (1982) 、Tatsuoka (1983) 、 Tatsuoka (1986) 、Tatsuoka & Tatsuoka (1987) 所提出的「規則空間」測量模式,
可用以診斷、解釋及偵測學習者在問題解決時,若使用了錯誤規則,會以致產生 系統性的認知失誤,而出現特異的反應組型。但余民寧、陳嘉成 (1998) 指出此 模式之數理統計知識較為艱深,難為教師所接受。 而日本學者佐藤隆博 (Takahiro Sato) 則將學生在試題的作答反應於進行圖 形化分析,命名為S-P 表的分析技術,藉由學生在測驗的作答,以指標數據診斷 其反應組型異常與否(余民寧、陳嘉成,1998)。此方法是用於班級為單位的少 數人資料,並用以分析形成性評量,且分析結果可診斷學生表現、試題品質及教 學成果,可提供給教學者改進教學、命題並輔助學生之參考。余民寧(1997)甚至 為便利教學者之使用而將S-P 表分析軟體發展為中文化之研究與出版。 (三)解題規則模式與問題類型設計發現 規則評量方法的應用除解題規則的發現研究外,問題的設計也相當重要,須 能從受試者的試題反應來解釋其規則的使用,其中Siegler (1981) 便依據 J. Piaget 式的規則模式,針對平衡問題設計出以下六種不同的問題模式,分述如下: 1.相等問題 (Equal problems) :首位與次要面向皆相同。 2.首位面向不同問題 (Dominant problems) :首位面向不同,但次要面向相同。 3.次要面向不同問題 (Subordinate problems) :次要面向不同,但首位面向相同。 4.首位面向衝突問題 (Conflict-dominant problems) :首位面向與次要面向皆不 同,但首位面向影響較大。 5.次要面向衝突問題 (Conflict-subordinate problems) :首位面向與次要面向皆不 同,次要面向影響較大。 6.相等衝突問題 (Conflict-equal problems) :首位與次要面向皆不同,但兩面向的 影響互相抵消。 在該研究中,以5、9、13、17 歲等不同的年齡層學生為對象進行實驗施測, 且發現規則模式在120 位孩子中有 107 位(占 88%)能正確地將其表現呈現出來, 其中五歲的孩子有80%作到,而 17 歲的孩子有 100%作到。且不同年齡層的學童, 在不同的問題模式表現也有所差異,大致如下:
(1)首位面向衝突問題的表現,五歲孩子答對率為 89%,而十七歲的孩子答對 率為51%,可知在這些問題的表現,十七歲表現的比五歲孩子差。 (2)而在次要面向不同的問題表現五歲孩子答對率為 9%,而九歲的孩子答對率 為78%,而十七歲的孩子答對率為 95%,在此類型問題從五到十七歲,其發 展漸增。 (3)相等及首位面向不同問題兩種問題表現,有持續性的正確,從 88%~100%。 (4)次要面向衝突(次要面向影響較大)問題及相等衝突(首位面向與次要面 向的影響相抵消)問題的表現,分別是7%~40%及 11%~50%。 因此,透過學童在各種問題的反應可分析其解題規則,進而了解受試者在該 概念的發展情形。而本研究編製的測驗問題亦包含其中的三類問題:次要面向不 同的問題、相等衝突問題以及首位面向衝突問題等。
三、相關性概念的解題規則
有關相關性概念的解題規則,Awang (1984) 比照 Siegler (1981) 機率概念的 解題規則訂出相關性概念的四種解題規則;而本研究相關性測驗改編自 Awang (1984) 的測驗,但限定於「正相關性」概念,故四種解題規則中的規則四與 Awang (1984) 所訂定的規則有所不同,並未取差與整體的絕對值來判斷相關性之高低,而直接判斷差值與整體之關係。今以Awang (1984) 當時命名為魚的問題(The Fish
Problems)為例來說明四種解題規則,如下: 題目:每一問題中將有左、右兩圖片,且兩圖片中皆有四種魚,有些魚是大 的,有些魚是小的,有些魚是黑的,有些魚是白的。你認為哪一張圖片中魚的大 小和顏色有較高的相關性?請注意存在較大的相關性是指大多數的大魚是黑 的,以及大多數的小魚是白的;或者大多數的大魚是白的,及大多數的小魚是黑 的。 有關相關性的四個解題規則分別以圖 2-1、2-2、2-3、2-4 呈現,而圖中代號 的意義說明如下:
LC表示左圖的小且白及大且黑的魚之總數; LD表示左圖的大且白及小且黑的魚之總數; RC表示右圖的小且白及大且黑的魚之總數; RD表示右圖的大且白及小且黑的魚之總數。 規則一: 圖 2-1 Awang 之相關性概念解題規則一模式 規則二: 相等 選擇C值較大的一邊 LC=RC? 是 否 LC=RC? 是 否 LD=RD? 是 否 相等 選擇C值較大的一邊 選擇D 值較小的一邊 圖 2-2 Awang 之相關性概念解題規則二模式
規則三: LC=RC? 是 LC=RC? 否 LD=RD? LD=RD? 是 否 是 否 相等 圖2-3 Awang 之相關性概念解題規則三模式 規則四: 圖2-4 Awang 之相關性概念解題規則四模式 LC-LD=RC-RD? 是 否 相等 選擇D值 較小的一邊 選擇C值 較大的一邊 LC=RC? 是 否 LD=RD? 是 選擇max(LC-LD,RC-RD) 否 相等 選擇D值 較小的一邊 LD=RD? 是 否 選擇C值 較大的一邊 是 否 ? RD) (RC RD) -(RC LD) (LC LD) -(LC + = + 相等 選擇max( RD) (RC RD) -(RC , LD) (LC LD) -(LC + + )
有關Awang (1984) 之相關性概念的四種解題規則,以表 2-4 說明做法: 表2-4 Awang 之相關性概念的四種解題規則 規則 解題規則之做法 一 直接比較圖片中黑且大、白且小的魚之數量和,數量多者相關 大。 二 先比較圖片中黑且大、白且小的魚之數量和,若相同,則比較 黑且小、白且大之魚數量,量大者相關較小。 三 先將各圖中黑且大及白且小的魚數量和,與黑且小及白與大的 魚數量和之差值算出後比較,差值大者相關較大。 四 先將各圖中黑且大及白且小的魚數量和,與黑且小及白與大的 魚數量和之差值算出,並將各差值除以各圖中之魚總數,最後 再取絕對值,比值大者相關較大。 註:本研究因題目限定於正相關的思考,故規則四未取差值與總數比值的絕 對值,而是直接比較差值與總數之比值。 由表2-4 可以發現相關性概念的解題規則中,規則一是最低階的策略,規則 二、三次之,直到規則四才是正確的解題規則,顯示四種解題規則具有層次性。 而各規則中,規則一僅考慮到問題中的首要變數,規則二、規則三雖已考慮到次 要變數,但未能正確解題,而規則四的作法,同時考慮問題中的首要變數及次要 變數,且能有系統的正確解題。
四、規則評量方法與其他認知發展應用策略之比較
Siegler (1981) 將規則評量方法與其他被應用在認知發展的策略進行比較,以 清楚呈現特質,了解規則評量方法之優勢及限制。(一)與Levine’s blank-trials produre之比較
Levine, 1966) ,簡稱L法,L的方法與規則評量方法有兩基本假設是相似的:1. 人 們依照假設的規則來解題;2. 所表現的模式可透露假設的本質,而此兩種方法在 他們五歲孩子所用的系統化策略之基本發現也是一致的。而最大的不同在於:L 並不將其分析延伸到區別學習,且未發展出分類問題一般性的模式,而此乃是規 則評量方法的重要目的。 (二)與生產系統方法 (production-system approach) 之比較
規則評量方法也與Klahr & Wallace (1973) 所使用的生產系統方法相關,而兩 種情境配對型態是生產系統方法的基本單位,也是規則評量模式的基礎。再者, 規則評量方法與生產系統方法可用以區別網絡方法並具體呈現在電腦模擬程 式,如EPAM (Feigenbaum, 1961),其中,生產系統方法在任務表現的短期記憶與 容量是較為專業的,而規則評量模式則較容易測量但卻較缺乏品質,各有其優缺。 (三)與多重特點-多重方法技術 (multitrait-multimethod matrix) 比較 規則評量模式比過去所使用的多重特點-多重方法技術更為創新,且規則評量 模式著重在未經熟表現的層次,更詳盡描述人們在特定任務下更為細膩的層次。 (四)與J. Piaget 式之比較 規則評量方法與J. Piaget 式的研究方法皆認為可透過獲取有用的解題規則來 呈現概念上的發展,然而對於兒童表現的推論以及呈現孩子的知識模式卻不相 同,其中規則評量方法是使用受試者非口語模式的正確資料,但J. Piaget 則是使 用受試者的口語及錯誤類型反應來推論探究。 綜合以上可發現,規則評量方法是以情境配對型態為基礎,亦可區別網絡方 法,但在任務表現的短期記憶,規則模式則較缺乏品質,卻較易於測試;此外乃 針對未精熟表現的層次,進行非口語化的分析探究並詳盡描述特定任務的層次。 而本研究亦以規則評量方法之特點,針對受試者未精熟的表現層次,進行非口語 化的分析探究,以了解受試者的概念認知發展情形。
第三節 精緻試題的有向圖分析方法
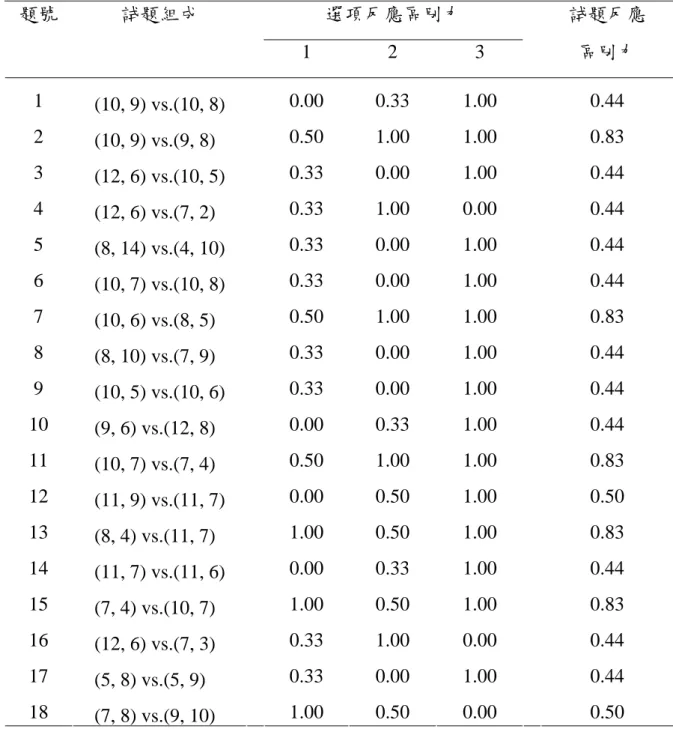
林原宏 (2006) 指出在解題規則測驗中,試題可否有效「區別」及「解釋」 規則,對於分析規則的次序性具有相當大的影響力,若試題無法區別或解釋解題 之規則,則試題即無法提供規則次序性之相關訊息,該規則之次序性也將不具意 義。 又一般而言,認知規則是透過一系列對問題反應的認知操作,且以正確反應 為基礎,然而,受試者也可能使用不正確的認知規則,卻產生正確的答案,故而 分析規則比分析反應更有助認知了解。而若一個項目可完全的解釋學生解題時之 反應所犯的錯誤,Bart et al. (1994) 稱之為半密集項目 (semi-dense item) ,而從 認知的診斷觀點而言,半密集項目是個理想的項目,儘管該反應非正確的答案, 卻可從中知道其錯誤規則的原因,另外,為分析檢視半密集項目的特性,必須檢 驗反應與項目的關係,以及所使用的認知規則對反應項目的解釋程度。其中半密 集項目的特性有五,包括:反應解釋力、反應區別力、規則區別力、規則系統的 徹底使用、半密集;而與本研究相關的為反應解釋力及反應區別力。而為求能檢視解題規則測驗之試題品質,Bart & Williams-Morris (1990) 提出 精緻試題的有向圖分析 (refined item digraph analysis, 簡稱 RIDA) 方法,以反應 解釋力 (response interpretability) 及反應區別力 (response discrimination) ,作為 衡量試題之認知診斷力的兩大指標。以下說明試題反應解釋力與試題反應區別 力,並列表2-5 及圖 2-5 輔助說明。
一、試題反應解釋力
Bart et al. (1994) 認為反應解釋力是用以衡量反應能被規則所解釋的程度,且 每一個對項目的反應至少可被一個認知規則所解釋,該項目方具有反應解釋力。 又林原宏 (2006) 認為反應解釋力公式可令為 I int I i i∑
=1 ,其中I是反應的數目,當反於0 時,則 為0。所以,表 2-5 中該題的反應解釋力為 。而反 應解釋力的值域介於[0,1 ]之間,其值愈高,表示該題的反應愈能被規則所解釋。 i int (0+1+1)/3=2/3
二、試題反應區別力
Bart et al. (1994) 認為反應區別力是用以衡量反應能被規則所區別的程度,且 每一個對項目的反應只可被一個認知規則所解釋,該項目方具有反應區別力,意 即若反應項目與認知規則間存在有函數關係,則該項目反應具有反應區別力。又 林原宏 (2006) 認為反應區別力公式可令為 I dis I i i∑
= ⎟⎟⎠ ⎞ ⎜⎜ ⎝ ⎛ 1 1 ,其中I 是反應的數目,而 是反應i的列總和;如果 i dis disi =0 ,則令 i dis 1 為0。所以,表 2-5 中該題的反應 區別力為(0+1/3+1)/3=4/9。反應區別力的值域亦介於[0,1 ]之間,其值愈高,表 示該題的反應愈能被不同規則所區別出來。 表2-5 試題反應與規則之對應關係表 規 則 反應 一 二 三 四 1 0 0 0 0 2 0 1 1 1 3 1 0 反應1 反應2 反應3 (10, 9) vs. (10, 8) 規則二 規則三 規則四 規則一 0 0 圖2-5 反應與規則對應圖第四節 潛在類別分析
一、潛在類別分析之意義
(一)潛在類別分析之緣起 潛在類別分析(簡稱 LCA)是一種潛在特質分析的模式,最先由 Lazarsfeld (1950) 提出,其後有一系列的母數估計研究報告,直到 Goodman (1974a; 1974b) 發展了最大概似法後,一般研究者皆採用此法來進行母數估計,LCA 的應用才開 始擴展(引自吳毓瑩、林原宏,1996)。 (二)潛在類別分析在教學上的意義 而潛在類別分析主要作用在於分群,在教學上提供了兩大用途,其一是將同 質的學生分成同組,可以針對共同的迷思概念或特色進行教學,以提升學習效 率;其二則可將同質的學生打散分組,讓各組的異質性較高,以配合討論活動或 合作學習活動,達到不同認知結構的轉變與同化。 (三)潛在類別分析的研究假設與限制Jansen & Van der Mass (1997) 強調潛在類別分析方法的潛在變數及所觀察的 變數必須為類別變數,而非一般潛在變數所要求的連續變數,更能符合實際研究 之需求。而潛在類別分析模式中的類別有些可以成為階層關係,有些則依題目特 性而平行共存,未必具有階層性。且分析模式是以試題的答對機率之觀點來看受 試者的潛在特質,並以受試者在各試題的答對機率並不受其他試題的作答所影響 的局部獨立性作為假設基礎。 而先前已提過規則評量方法缺失可透過潛在類別方法加以修正,並有Boom et al. (2001) 將LCA應用在Siegler (1981) 的槓桿問題,以求修正Siegler提出的規 則評量方法之缺失,而本研究亦然。並透過潛在類別分析,更深入地呈現各類學 生在各種解題規則的表現,除作為分群教學外,亦可做為補救教學之用。
二、潛在類別分析之方法
在本研究中,將應用潛在類別分析於學童在相關性測驗的解題規則,透過潛 在類別分析了解學童在解題規則的分群情形,並彌補規則評量方法之缺失與限 制。 潛在類別分析的過程必須估計參數,包含各類別組佔全體樣本的比例,以及 每一題在各類別組內的答對機率值,又稱通過率。而參數估計完成後,便依各潛 在類別在題目上的答對率及解題規則做各類別認知結構之描述。根據受試者的反 應組型,計算受試者的事後機率並將其歸類,從而看出受試者之反應特性以得知 其認知結構,並做為教育上之診斷與學習分組之用。 以下說明潛在類別分析所使用之符號,解釋如下:(引自吳毓瑩、林原宏, 1996)。 (一)受試者之有效人數共N人,以 為受試者代號,則i i=1,2,...,N。 (二)分析的題數共計K題,以 為各題之代號,k k =1,2,...,K。 (三)受 試 者 對 各 試 題 的 反 應 組 型 , 以 x 表 示 ; 記 分 方 式 為 二 分 法 (dichotomous) ,答對為 1,答錯為 0,受試者 對題目k的反應以 表示, 而對全部題目的反應向量則為 。 i xik i x (四)根據研究所得之反應資料,可將受試者分為C個類別,以 表示各個類別, 。 c ,...,C , c=12 (五)試題k在類別 的條件下,其條件機率 (condictional probability) ,或稱通 過率為 。 c kc θ (六)類別c人數佔全體受試人數比例為αc。 今利用以上符號,並舉本研究來說明各符號之使用,本研究之測驗題目共計 18題, ,反應組型共計 種,並假設第i位受試者的反應型態 為 ,代表各題的對錯情形,其中對第二題的反應值為 。又假設第二題對第一類別而言相當容易,則θ 會接近1,反之則接近0。 再者,若第一類別人數佔全體人數之30%,則 18 = K 218 =262144 i x ,1,0,1) ,1,0,1,0,1 ,1,0,0,1,1 (1,0,0,0,0 0 2 = i x 21 3 0. α = ,且由於α 為潛在類別之比例,故而α1 +α2 +...+αc =1。而潛在類別分析所要估計參數,即為類別比例α 及c 試題條件機率θkc。 另外,局部獨立性是潛在類別分析的重要概念,但一般測驗的題目間彼此必 有相依之關聯,諸如內部一致性,然而,如果我們將共同特質的變異量部分去除, 則可發現題目本身扣除共同的特性後,題目的反應即可互相獨立,在潛在類別分 析中,因共同變異的部份為潛在類別所佔,故而 題目答對機率所反應的即是潛 在類別中的條件機率。(吳毓瑩、林原宏,1996)。 kc θ 接著,我們將採用潛在類別分析之估計方法中,常用的最大可能估計法 (Maximum Likelihood Estimation,簡稱MLE),估計類別比例 及試題條件機率 等參數值,並以EM(Expectation and Maximization)估計法來輔助,介紹如下:
c α kc θ (一)最大可能估計法 先令 fi(Xi c)表示受試者的反應向量 在類別c中對於各試題反應之條件機 率函數,則: i X
∏
= = K k ) -x ( kc x kc i i(X c) θ ki( -θ ) ki f 1 1 1 此反應向量在全部組別中的機率則為上式的條件機率與各類別的比重乘積和:∏
∑
= = ∗ = K k ) -x ( kc x kc C c c i i(X ) α θ ki( -θ ) ki f 1 1 1 1 任一組反應向量Xi,屬於特定潛在類別的事後機率為: ) f(X ) -θ ( θ α ) X f(c i K k ) -x ( kc x kc c i ki ki∏
= ∗ = 1 1 1 令最大概似函數為:∏
∑
∏
= = = ∗ = K k ) -x ( kc x kc C c c N i ) ) -θ ( θ α ( L ki ki 1 1 1 1 1 取 之後為: ln∑ ∑ ∏
∑
= = = − = ⎥⎦ ⎤ ⎢ ⎣ ⎡ − = = N i C c K k x kc x lc c N i i i k i k( θ ) θ α ) f(X L 1 1 1 1 1 1 ln ln ln針對各參數進行偏微分,可得各參數估計值。
∑
= ∧ ⋅ = N i i c f (c X ) N α 1 1 ˆ (1)∑
= ∧ ∧ ⋅ × = N i i i c kc x f (c X ) α N θ 1 1 ˆ (2)此外,由貝氏事後機率(Bayes’ posteriori probability)可知
) f(X ) c f(X α ) X (c f i i c i ∗ = ∧ (3) 由以上 (1)、(2)、(3) 式的關係,我們可以進行EM估計法(Expectation and Maximization)的估計,此估計法之概念由Dempster, Laird, & Rubin (1977) 而來, 但應用於LCA的參數估計上,Clogg (1977) 所設計之軟體則有很大貢獻。 (二)EM估計法 此 估 計 法 之 步 驟 有 二 , 為 估 計 步 驟 (Expectation ) 及 最 佳 化 步 驟 (Maximization),呈現如下:(引自吳毓瑩、林原宏,1996) 1. 將 (3) 式中的α 及c θ 給定初始值(initial value),並得到事後機率kc f(cXi)。 2. 在最佳化步驟中,將 f(cXi )代入 (1) 、 (2) 式的右端,並在左端中得到新的αc 及θ 。 kc 3. 將所得的兩個值代入 (3) 式,再進入估計步驟,以獲得新的事後機率,取代原 本設定之初始值。 4. 將新的事後機率估計值代入 (1) 、 (2) 式的右端,回到步驟2的最佳化步驟, 如此重複步驟2、3、4,不斷的重複和迭代 (iteration) ,進行估計與最佳化之 工作,直到估計達到收斂 (convergence) 。 EM估計法利用方程式間不斷地迭代,計算不繁雜卻冗長,今則可藉電腦強 大的計算能力,使該估計程序在短時間內完成。
第五節 次序理論
一、次序理論之意義
(一)次序理論的緣起
次序理論之基礎起源於 Guttman 之 Scalogram 分析及線性量尺技術 (linear
scaling technique) (Jansson, 1986) ,不同的是 Guttman 之 Scalogram 分析僅侷限於 線性的階層關係(例如:A→B→C→D),亦即每一項目或任務只出現在某一階 層,且每一項目都必是另一項目的必要條件 (Bart & Airasian, 1974) ;而次序理 論則延伸為非線性之測量技術,且所能呈現的階層關係能提供較多的訊息,不僅 限於試題之難易關係 (Bart, Frey, and Baxter, 1979) ,使其應用更為廣泛。 (二)次序理論的目的
次序理論常用以決定試題間之次序關係 (Bart & Krus, 1973) ,且次序理論之 試驗具有兩個一般性的目的 (Airasian & Bart, 1973) :1. 測試兩個項目間的假設 性的次序,以確定其階層關係;2. 將未具備假設性次序的項目進行一般化的次 序,以判斷該些項目是否具有階層關係。 (三)次序理論的記分方式 以往次序理論僅限於二元計分,但經林原宏、Bart、黃國榮,已擴展到可以 廣義多元計分的模式。(林原宏、Bart、黃國榮,2006;林原宏,2007)。 (四)建立次序關係的步驟 次序理論大致可分成四個步驟以檢驗出項目間是否具有次序性 (Airasian & Bart, 1973) : 1. 以口頭和圖表描繪出假定性的次序。 2. 具體說明合理的 (confirmatory) 反應模式和不合理 (disconfirmatory) 的反應 模式。 3. 選擇容忍標準和適當的試題資料。 4. 執行容忍標準,判斷是否具有次序性關係。