國立臺灣大學電機資訊學院資訊工程學系 碩士論文
Department of Computer Science and Information Engineering College of Electrical Engineering and Computer Science
National Taiwan University Master Thesis
運用單語相關語料庫於跨領域機器翻譯調適問題之研 究:一種混合式機器翻譯策略
Uses of Monolingual In-Domain Corpora for
Cross-Domain MT Adaptation: A Hybrid MT Approach
謝安昌 Hsieh, An-Chang
指導教授:陳信希 博士 Advisor: Chen, Hsin-Hsi, Ph.D.
中華民國 102 年 7 月
July, 2013
i
摘要
本論文探討跨領域機器翻譯的問題,統計式翻譯近年來已逐漸成為機器翻譯 的 主 流 , 然 而 以 一 般 領 域(general domain) 統 計 式 翻 譯 模 型 翻 譯 特 殊 領 域 (domain-specific)語句會遇到許多問題,例如歧異性、排序錯誤以及未知詞問題(out of vocabulary)。由於特殊領域雙語語料庫並不一定存在,在先前的實驗中,我們加 入雙語字典及規則式翻譯來輔助統計式翻譯,並取得了不錯的效果。在此論文中,
我們更進一步使用領域相關單語語料庫來改進統計式翻譯模型。我們使用多種方 法利用單語語料庫,包括從譯後編輯(post-editing)取得新翻譯規則(pattern)、以非監 督及半監督式學習訓練出領域相關統計式翻譯模型,並探討不同模型組合對翻譯 效果的影響。
實驗顯示從譯後編輯取出的規則確實能提升翻譯品質;從單語語料庫作非監督 及半監督式學習訓練出的模型也皆有顯著進步;以譯後編輯搭配半監督式學所得到 的模型則有最佳效果。
關鍵字:統計式機器翻譯、領域調適、單語語料庫、半監督式學習、譯後編輯
ii
Abstract
This thesis deals with the problems encountered in the cross-domain machine translation. Statistical machine translation has been the mainstream approach in the machine translation field, however, there are many problems when using general domain statistical machine translation model to translate the domain-specific sentences.
For instance, word sense ambiguity errors, ordering errors, and out of vocabulary errors.
Since the domain-specific parallel corpus alignment may not be available, there are some experiments which added the domain-specific bilingual dictionary and translations rule to support the statistical machine translation system, and they had some good results in those methods . In this thesis, we use those models and further extend their methods by using in-domain monolingual corpus to improve the statistical machine translation system. We make use of the monolingual corpus by multiple approaches, including mining new translation patterns from post-editing log, training the in-domain statistical machine translation models by unsupervised and semi-supervised learning, and studying the performance for different approaches combinations.
The results of experiments show that the new translation rules mining from post-editing log can significantly improve the translation quality. The model trained from semi-supervised learning also has positive effect on performance, and the combination of new translation rules and semi-supervised method has the best result.
Keywords: Statistical Machine Translation, Domain Adaptation, Monolingual
Corpus, Semi-Supervised Learning, Post-editing
iii
誌謝
首先感謝陳老師這兩年的指導,能夠進到自己有興趣的 lab 實在很幸運。也感 謝界人學長為lab 的付出,感謝瀚萱學長平時的討論和閒聊,感謝基鑫學長和我討 論人生,也感謝一起修課的佳純,因為大家的幫忙我才能順利完成論文。最後也 感謝niconico 的 inorry,謝謝妳超有活力的生放送伴我度過寫論文的日子。
iv
目錄
摘要………...……… i
Abstract.………....ii
誌謝………..………iii
目錄………..iv
圖目錄………..vi
表目錄……….vii
第一章 緒論……….1
1.1 研究動機………1
1.2 研究方法………2
1.3 實驗資料………4
1.4 論文架構………6
第二章 相關研究與文獻……….7
2.1 基於片語的統計式機器翻譯………7
2.2 跨領域統計式機器翻譯………7
2.3 簡化翻譯還原架構………10
2.3.1 重要雙語句型的取得………...12
2.3.2 簡化翻譯還原架構………...15
第三章 運用領域相關單語語料庫改進簡化翻譯還原架構……….18
3.1 使用譯後編輯記錄產生翻譯規則………..………18
3.1.1 產生譯後編輯記錄……….…….18
3.1.2 運用譯後編輯記錄產生翻譯規則………...23
3.2 非監督與半監督式學習之應用………..………25
3.2.1 以非監督式學習訓練模型………..26
v
3.2.2 以半監督式學習訓練模型………...28
3.3 運用領域相關單語語料庫於簡化翻譯還原架構……….…….30
第四章 實驗設計與結果分析………...33
4.1 實驗資料介紹………..33
4.2 實驗設計………..34
4.3 實驗結果分析………..39
4.3.1 評估方法………...39
4.3.2 結果分析………...39
第五章 結論與未來研究方向………...49
5.1 結論………..49
5.2 未來研究方向………..49
參考文獻……….51
vi
圖目錄
圖1. Chen 等人(2012)提出的病歷機器翻譯架構………...………3
圖2. Schwenk 提出的微監督訓練架構……….………..……….9
圖3. Chen 等人(2012)提出的簡化翻譯還原架構……….…………11
圖4. 簡化翻譯還原的例子(Chen 等人, 2012)………..………16
圖5. 產生譯後編輯的過程………19
圖6. 病歷翻譯譯後編輯系統………21
圖7. 產生虛擬平行雙語語料庫的基本想法……….………...26
圖8. 加入新翻譯規則以產生虛擬平行雙語語料庫的流程………27
圖9. 以半監督式學習產生虛擬平行雙語語料庫的流程………28
圖10. 翻譯流程………..31
圖11. 產生各模型的統計式翻譯系統和翻譯規則流程………..32
vii
表目錄
表1. 一般領域 PBM 翻譯發生的錯誤………2
表2. 一個病例範例(Chen 等人, 2012)………….………...5
表3. 病歷中常用的句型例子………12
表4. 病歷句型及其中文翻譯例子(Chen 等人, 2011)………….……….…13
表5. 類型翻譯規則例子………14
表6. 詞彙翻譯規則例子………15
表7. 初步翻譯及其譯後編輯的例子………20
表8. 譯後編輯系統的編輯紀錄………22
表9. 從譯後編輯紀錄取得的類型翻譯規則例子………24
表10. 譯後編輯修正及取出的詞彙翻譯規則例子………..25
表11. 簡化翻譯還原架構翻譯中的錯誤統計………..29
表12. 含有英文的句子的例子………..29
表13. 整句都為中文的例子………..30
表14. 模型列表………..37
表15. 模型列表………..38
表16. 各模型的實驗結果………..40
表17. 各模型 BLEU 分數差距的 t-test 結果………42
表18. M11~M17 的翻譯錯誤例子……….43
表19. 各模型的錯誤統計………..43
表20. 錯誤片語翻譯的例子………..44
表21. M16 和 M17 的翻譯候選數量……….45
viii
表22. M3 和 M13 的錯誤統計………45 表23. 歧義性錯誤的例子………..46 表24. 順序錯誤的例子………..46
1
第一章 緒論
1.1 研究動機
近十年來由於網路的發達,取得大量語料庫變得越來越容易,使得統計式機 器 翻 譯(statistical machine translation)逐漸成為機器翻譯的主流。Koehn 等人 (2003,2004)提出了基於片語的統計式機器翻譯模型(Phrase-Based Model, 以下簡稱 PBM),而許多研究皆顯示,PBM 的效果較基於詞(Word-Based Model)的統計式機 器翻譯模型為佳(Koehn 等人, 2003; Marcu and Wong, 2002),使得 PBM 成為統計式 機器翻譯的主流之一。
要訓練出一個PBM,首先須具備平行語料庫對照(parallel corpus alignment),
再以此訓練出片語表 (phrase table)。然而,使用一般領域平行語料庫對照訓練出 的PBM 來翻譯特殊領域的語句會發生許多問題,如未知詞問題、歧義性問題、排 序錯誤等。以下以一般領域的英翻中PBM 翻譯病歷的英文句子說明:
英文 After admission , lactulose was applied for hepatic encephalopathy . 翻譯 入學 後 , lactulose 人 申請 hepatic 病 。
在上面的例子,“入學” 和 “申請” 屬於歧義性錯誤(正確翻譯分別為 “入院” 和
“用於”),而未被翻譯的字 “lactulose” 和 “hepatic” 則為未知詞錯誤 ,其他的類 似例子如表1。從表 1 可發現,未知詞問題會造成原文無法翻譯,歧義性問題會造 成明顯的翻譯錯誤,而排序錯誤會產生錯誤的文法及語意。
2
表 1. 一般領域 PBM 翻譯發生的錯誤
英文 The BMA report on 2002/12/21 revealed remission . 翻譯 在 BMA 報告 2002/12/21 顯示 減免 。
英文 Under stable condition , he was discharged on 2002/10/30 . 翻譯 在 穩定 的 條件 , 他 被 釋放 在 2002/10/30 。 英文 We rechecked the CBC/DC and blood culture was done . 翻譯 我們 在 rechecked CBC/DC 和 血液 文化 所 做 的 。
以PBM 來翻譯特殊領域的語句,最好的方法是使用特殊領域的平行語料庫當 作訓練資料,但並非每個領域都有足夠的平行語料庫,資料稀少常造成跨領域翻 譯的障礙。對某些特定領域,例如醫院的病歷資料,甚至只能取得病歷單語語料 庫(英語)及醫學名詞詞典,使得機器翻譯任務更加困難。
在此論文中,為了解決跨領域翻譯資料不足的問題,我們提出了許多機器翻 譯模型,並使用不同的方法來利用領域相關單語語料庫,以增進跨領域機器翻譯 的效能。
1.2 研究方法
近年來跨領域機器翻譯的問題逐漸被注意到,也帶起了許多相關研究。許多 研究嘗試在網路搜集領域相關的語料庫,或是以資訊檢索(information retrieval)的 方法找出翻譯模型(translation model)或語言模型(language model)中領域相關的部 分,將其應用於統計式翻譯系統(相關研究將於第二章做更詳細的說明) 。但在某 些極端情況下,例如台灣的醫院病歷一律使用英文書寫,因而極度缺乏中文的病
3
歷語料。此外由於病歷的隱私性,網路上亦難以取得此類資料,使得機器翻譯在 翻譯醫院病歷上具有相當的挑戰性。由於中文資料嚴重缺乏,一般領域的統計式 機器翻譯並不適用,勢必得加入其他方法來提升翻譯效果。在此情況下,Chen 等 人(2012)對病歷的機器翻譯做了相關研究,並提出了一系列的架構來實現病歷的機 器翻譯,如圖1。
圖 1. Chen 等人(2012)提出的病歷機器翻譯架構
此架構包括抽取常用病歷句型(pattern)以及簡化翻譯還原的方法(於 2.3 節中詳述),
此架構可以大幅提升病歷翻譯的BLEU (Bilingual Evaluation Understudy)(Papineni 等人,2002) 分數。
簡化翻譯還原架構的精神在於,由於特殊領域的句子往往含有特殊領域的詞 彙及寫作風格,為了使一般領域的統計式機器翻譯系統能夠容易翻譯這領域句子,
4
因此需在翻譯前先以固定規則將句子簡化,簡化過的句子再交由一般領域的統計 式機器翻譯系統翻譯,之後再將簡化的部分還原。然而,簡化翻譯還原只能簡化 特定的句型,而無法應用到所有特殊領域句子。若是能改善統計式機器翻譯系統 本身,使其更適用於特殊領域,則翻譯效果或能有所提升。有鑑於此,本論文以 醫院病歷為例,嘗試使用譯後編輯(post-editing)的資料,以及領域相關的單語語料 庫來改善統計式翻譯系統。我們從譯後編輯資料中取出易翻錯的部分,並製作成 翻譯規則,以避免系統再翻錯,並嘗試使用譯後編輯的中文作為統計式翻譯系統 語言模型(language model)的訓練資料。對於領域相關的單語語料庫,我們則使用 非監督及半監督式學習來產生中文翻譯,以製作出虛擬領域相關平行語料庫 (pseudo in-domain parallel corpus),並以虛擬領域相關平行語料庫作為統計式翻譯 系統的訓練資料,進而產生領域相關的統計式翻譯系統 。 除此之外,我們也以 此方式重複訓練統計式翻譯系統,以期能得到更好的效能。實驗結果顯示,將此 改進過的統計式翻譯系統結合簡化翻譯還原架構,能得到更好的BLEU 分數。
1.3 實驗資料介紹
本論文使用的實驗語料庫是由台大醫院提供的病歷語料庫,總共 60448 個病 歷,包含 620 萬句的英文。一個病歷可分為三部分:主訴、簡史、治療過程。一個 病歷的範例如表2。
5
表 2. 一個病例範例(Chen 等人, 2012)
6
1.4 論文架構
本論文第一章敘述了論文研究動機,並簡述研究方法和實驗資料。第二章描 述統計式翻譯的相關研究,例如跨領域機器翻譯、非監督式學習的應用以及簡化 翻譯還原的研究。第三章敘述如何以領域相關單語語料庫改善簡化翻譯還原架構,
並提出數種方法,包括改進統計式翻譯系統和改進翻譯規則,以及他們的併用。
第四章則是各種模型的實驗結果及討論。第五章為結論及未來研究方向,將說明 未來可以再做的研究及改進。
7
第二章 相關研究與文獻
2.1 基於片語的統計式機器翻譯
統計式翻譯最早是由 Brown 等人(1993)提出了通道訊號模型(noisy-channel model)及基於詞的(word-based)IBM 模型(IBM model-1,2,3,4,5),開啟了統計式機器 翻譯的研究潮流,其後 Koehn 等人(2003)提出了 PBM。在統計式翻譯中,其目標 就是找出來源句子s 的翻譯 t,並滿足最大的事後機率:
argmax ( | ) = argmax ( | ) ∙ ( ) (1) 在公式(1)的右半部式子可分為兩個統計模型,分別為翻譯模型(translation model) p(s|t)和語言模型(language model) p(t)。p(s|t)就是目標語言句子 t 翻譯成來源語言句 子s 的機率,而 p(t)就是目標語言句子 t 出現的機率。語言模型只和目標語言有關,
而翻譯模型則和來源語言及目標語言有關。這個式子的涵義在於,在翻譯時會同 時考量來源句子s 是否常翻譯成目標語言句子 t,以及目標語言句子 t 在目標語言 中是否為正確的用法(是否常用),此二者相乘的機率越高,則代表 t 為 s 的翻譯的 可能性越大。其中 p(t)可經由大量的目標語言語料庫來訓練,而 p(s|t)可經由大量 的平行雙語語料庫(parallel bilingual corpus)來訓練。
除了訓練資料外,統計式翻譯還會使用調式資料(tuning data)來最佳化翻譯模 型、語言模型以及順序模型(reordering model)的權重:
= argmax ∏ (s | ) ( − − 1) ∏| | ( | … ) (2) 最基本的用法便是用 Och(2003)提出的最少錯誤訓練法(minimum error training)來 最佳化公式(2)的三個 λ,d 為順序模型(reordering model)
2.2 跨領域統計式機器翻譯
雖然近年統計式翻譯已成為機器翻譯的主流,然而和其它自然語言處理 (natural language processing)任務一樣,統計式翻譯系統在處理跨領域的翻譯時也會
8
發生問題。原因在於統計式翻譯都是以雙語語料庫及語言模型的訓練資料來估計 機率值,當擬翻譯的資料和訓練資料來自同一領域時,統計式翻譯能有不錯的效 果,反之則翻譯品質會嚴重下降。因此,如何將一個領域的知識轉移應用到另外 一個領域,便成為一個很重要的研究。
Eck 等人(2004)以跨語言資訊檢索方法(cross-language information retrieval techniques)從網路取得領域相關的目標語言文件,將這些文件和原本的語言模型結 合。
Hildebrand 等人(2005)從使用資訊檢索的方法從訓練語料庫(training corpus)中 取出和測試資料相關的句子,並將這些句子加入翻譯模型和語言模型的訓練資 料。
Foster 和 Kuhn 等人(2007)使用混和模型(mixture model)的方法,在這個方法中 訓練資料依據不同內容被分為多個子集,每個子集分別訓練出一個翻譯模型,再 給予每個模型不同的權重(weight),最後再將所有子模型用於基於片語的統計式翻 譯。此種混合模型的方式的好處是,只需要修改少數模型的參數就能達成跨領域 應用。但此種方式就無法選擇修改個別片語的機率。
另一種方式是屬於翻譯模型自我改良(self-enhancing)的研究,此種方法首先是 由Ueffing(2006)所提出。其想法是先翻譯測試資料,並以信心分數(confidence score) 挑選出較佳的翻譯,將這些翻譯訓練成一個片語表,在下一輪翻譯時加入此片語 表並重複此過程直到 BLEU 分數不再增加。此種方法通常需要大量的測試資料以 產生大量的翻譯。Ueffing(2007)並在之後的研究將其更進一歨改良。
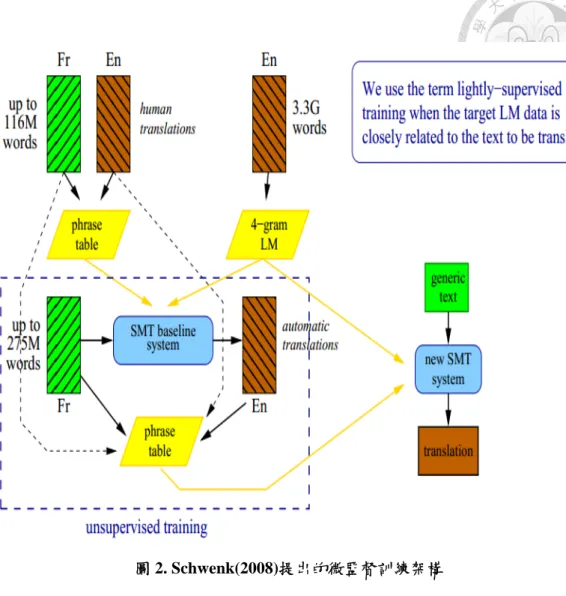
另一個較為相似的方式則是由 Schwenk(2008)所提出,稱之為微監督訓練 (lightly-supervised training)。在這個方法中,統計式翻譯系統被用來翻譯大量的來 源語言單語語料庫(source language monolingual corpus),經過挑選後將其當作翻譯 模型的訓練資料,而語言模型則不更動,如圖2。在其實驗中發現此方法確實能提 高BLEU 分數。
9
圖 2. Schwenk(2008)提出的微監督訓練架構
根據上述研究,跨領域的統計式翻譯研究主要可分為兩個支線:
(1) 其中一個支線只使用已有的訓練資料,並以混合模型優化參數的方式來達成跨 領域應用(Foster 和 Kuhn,2007; Civera 和 Juan,2007)。
(2) 另一個支線則使用半監督或類似非監督學習的方式產生雙語語料庫,並使用這 個語料庫當作訓練資料(Ueffing 等人,2007; Bertoldi 和 Federico,2009; Schwenk 和Senellart,2009)。
10
2.3 簡化翻譯還原架構
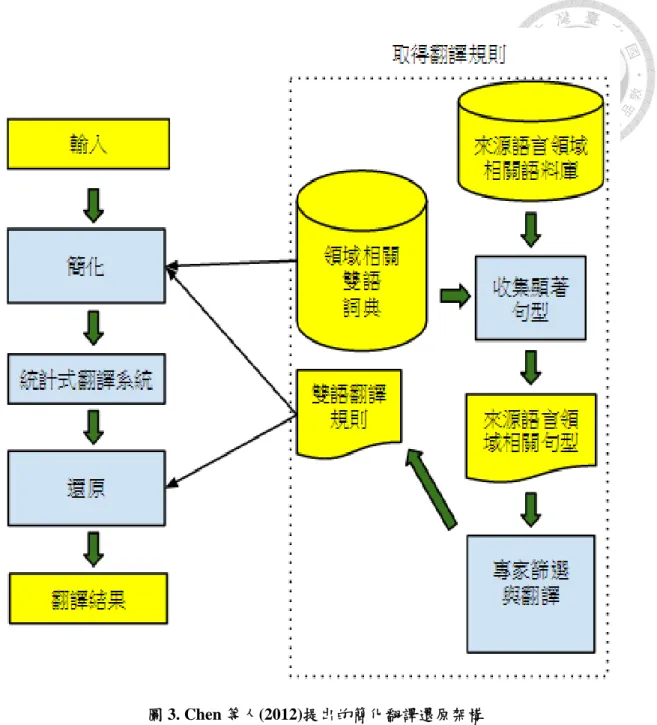
對於特定領域,例如醫院病歷,由於雙語語料不足,以一般用途的統計式機 器翻譯應用於該領域會造成翻譯品質下降。因此,Chen 等人(2012)以醫院病歷為 例,提出了在特定領域雙語語料不足的情況下,一個可用於跨領域的簡化翻譯還 原架構。此架構流程如圖3。
其運作方式如下:
(1)給定一個英文句子,首先利用雙語詞典及雙語翻譯規則(Bilingual Patterns)辨識 句子中的領域相關部分(in-domain pattern)。
(2) 將 此 領 域 相 關 部 分 作 簡 化 (Simplification): 以 領 域 相 關 雙 語 詞 典 (Bilingual In-Domain Dictionary)及雙語翻譯規則來做簡化,替換掉艱澀的領域相關部分。
(3)以領域外的 PBM 統計式翻譯系統翻譯經過(2)簡化的句子。
(4)以領域相關雙語詞典及雙語翻譯規則翻譯艱澀的領域相關部分。
(5)將(4)中翻譯完的領域相關部分和簡化的部分作交換(Restoration),而產生最終的 翻譯結果。
由於本論文會使用到簡化翻譯還原架構做為基本的模型,因此接下來會先概 略介紹此架構。簡化翻譯還原的實作需要兩個部分: 取得雙語翻譯規則和簡化翻譯 還原方法。在2.3.1 節中我們將介紹如何取得重要的雙語翻譯規則,2.3.2 節則介紹 了簡化翻譯還原的方法。
11
圖 3. Chen 等人(2012)提出的簡化翻譯還原架構
12
2.3.1 雙語翻譯規則的取得
在醫院病歷中,許多特定句型常會重複使用,例如(Chen等人, 2011)
“Port-A implantation was performed on 2009/10/9”
含有一個常用的醫學句型,此句型為
SURGERY was performed on DATE
其他例子如表3。
表3. 病歷中常用的句型例子
paracentesis was performed on 2010-01-08 repositioning was performed on 2008/04/03 incision and drainage was performed on 2010-01-15
tracheostomy was performed on 2010/1/11
它表示某個手術在某個時間執行,SURGERY代表手術名稱,DATE代表時間。一般領 域的統計式機器翻譯系統無法辨認出此類常用句型,並且常在翻譯此類句型時出 錯。其中一個原因是,此類特殊領域句型及片語很少出現在ㄧ般領域的語料庫,
另一個原因是由於該特殊領域目標語言語料庫(target language corpus)難以取得,資 料稀少使得一般領域統計式翻譯系統難以翻譯此類句子。若是能辨識此類重要句 型,並以人工的方式翻譯而得到句型翻譯,如表4,便可將其應用在特殊領域的機 器翻譯。
雙語翻譯規則的取得可分為兩階段任務:(1)取得常用句型,和(2)人工翻譯句 型。取得常用句型後,再請領域專家翻譯這些句型,便能得到雙語翻譯規則,接 下來將概述如何取得常用句型。
13
表4. 病歷句型及其中文翻譯例子(Chen等人, 2011)
Chen等人(2011)提出了五階段的方式以找出常用句型,敘述如下:
(a) 醫學名詞辨識(Medical Entity Classification)
以醫學辭典辨識出醫學名詞,包括手術、疾病、藥物等,將他們轉為對應的 醫學類別,並形成新的語料庫。
(b) 抽取常用句型(Frequent Pattern Extraction)
以N-gram從新語料庫中找出常用句型。(c) 找出符合文法的句型(Linguistic Pattern Extraction)
對每個句型,隨機選取含有此句型的若干句子,若這個句型在這些句子中至 少形成一個子樹,則保留此句型。
(d) 找出覆蓋句型(Pattern Coverage Finding)
若某個較短的句型被某個較長的句型覆蓋,則移除較短的句型。
(e) 句型分群(Pattern Clustering)
將剩下的句型分群,並從每群中找出有代表性的句型。
類型翻譯規則的一些例子如表5:
14
表5. 類型翻譯規則例子
英文 中文翻譯
there was no significant $診斷 並 無 明顯 $診斷
was implanted on $時間 smoothly 在 $時間 順利 植入
was admitted for $檢驗 follow-up 為了 $檢驗 追蹤 而 住院
distal $部位 and $部位 $醫學詞 遠端 $部位1 及 $部位2 $醫學詞
received $診斷 $手術 on $時間 接受 了 $診斷 $手術 於 $時間
$藥物 was given for $醫學詞 使用 $藥物 用於 治療 $醫學詞
$診斷 with $醫學詞 was impressed 被 診斷為 $診斷 合併 $醫學詞
with $部位 and $部位 $診斷 併有 $部位1 與 $部位2 之 $診斷
$醫學詞 and $診斷 was suspected 懷疑 有 $醫學詞 及 $診斷
treatment with $藥物 and $藥物 $藥物1 和 $藥物2 的 治療
had the history of $診斷 有 $診斷 的 過去 病史
詞彙翻譯規則的一些例子如表6:
15
表6. 詞彙翻譯規則例子
英文 中文翻譯
sudden onset of consciousness change 突然 發作 的 意識 變化
then received regular follow up 然後 接受 定期 追蹤
got admitted for further management 住院 接受 進一步 處置
no definite abnormal tracer uptake 沒有 明確 的 異常 示 踪 劑 攝取
revealed high grade urothelial carcinoma 顯示 高 惡性度 尿道 上皮癌
had fair activity and appetite 活動 和 食慾 尚可
no specific discomfort was noted 沒有 注意到 特異 的 不適
with initial loss of consciousness 最初 有 意識 喪失
no evidence of local recurrence 沒有 證據 顯示 局部 復發
was discharged with oral medication 攜帶 口服 藥物 出院
did not improve after medication 用藥 後 沒有 改善
2.3.2 簡化翻譯還原架構
Chen等人(2012)提出的簡化翻譯還原架構是以下列四步驟組成:
1. 從輸入的句子S辨識領域相關的片段 , , … , 。 2. 簡化S中的 , , … , ,得到一個新的來源句子S’。
3. 將來源句子S’以統計式翻譯系統翻譯成目標句子T’。
16
4. 還原S’-T’中的雙語片段 − , − , … − ,得到最後的翻譯。
一個簡化翻譯還原的例子如圖4:
圖4. 簡化翻譯還原的例子 (Chen等人, 2012)
關於如何簡化領域相關的片段,則是使用以下規則:
(a) 名詞片語(Noun Phrase)
保留NP片段中的表頭部分,去除其修飾語。若表頭名詞是特殊領域的名詞,
則更進一步使用特定的簡化規則做簡化。
(b) 動詞片語 (Verb Phrase)
VP V + NP: 保留動詞部分不變,並以簡化規則(a)來簡化NP,例如我們會 將"had underlying diseases of ventricular tachycardia and dyslipidemia" 簡化成 "had diseases"。
17
VP V + PP: 保留動詞部分不變,且若PP是修飾語,則移除PP。例如我們 會將"he was discharged on the morning of 6/30" 簡化成 "he was discharged"。
(c) 介系詞片語(Prepositional Phrase)
PP P + NP: 保留P並以(a)簡化NP,例如我們會將"with underlying diseases of ventricular tachycardia and dyslipidemia" 簡化成"with diseases"。
(d) 子句 (Clause)
以上述的規則遞迴地簡化一個子句的子樹。
18
第三章 運用單語相關語料庫改進 簡化翻譯還原架構
在這一章節我們將會說明我們所提出的方法,包括詳述如何利用單語相關語 料庫改善簡化翻譯還原架構。在3.1 節將介紹如何產生譯後編輯,以及如何利用譯 後編輯的紀錄來產生新的翻譯規則。在3.2 節將介紹如何以非監督式及半監督式學 習的方式產生虛擬領域相關雙語語料庫(pseudo in-domain bilingual corpus)。3.3 節 則介紹如何運用譯後編輯資料和虛擬領域相關雙語語料庫於簡化翻譯還原架構,
並提出我們的模型。
3.1 使用譯後編輯記錄產生翻譯規則
3.1.1 產生譯後編輯記錄
如同在第一章所提到的,由於台灣醫院病歷皆是以英文書寫,加上病歷的隱
私性,使得中文病歷資料嚴重不足且難以取得。缺乏中文語料不只會造成統計式 翻譯無法運作,甚至連規則式的機器翻譯都無法實作,因此產生初步的中文病歷 語料是首要任務。由於我們已從台大醫院取得相當數量的英文病歷語料,因此可 以人工翻譯來產生平行病歷語料。然而,若要以人工做大量翻譯,其花費的時間 和金錢都必相對增加,為了減少金錢的花費及減少人工翻譯的時間,在Chen 等人 (2012)的研究中,他們從病歷語料中挑選少量的句子,先經過機器翻譯後再以人工 翻譯,以產生譯後編輯翻譯。在他們的研究中,經譯後編輯的翻譯只被拿來做為19
正確翻譯以測試翻譯效果,而在此論文中,我們則更進一步利用此譯後編輯的詳 細資訊來取得新的翻譯規則。接下來我們將介紹如何做譯後編輯,以及取得新翻 譯規則。
產生譯後編輯的過程如圖5:
圖 5. 產生譯後編輯的過程
首先從病歷語料庫中選取1004 句病歷句子,再使用 2.3 節所提到的簡化翻譯還原 架構翻譯這1004 句,而產生初步翻譯。由於初步翻譯是機器翻譯產生的翻譯,結 果未必正確,因此需再以人工修正成正確翻譯,也就是以人工對初步翻譯做譯後 編輯。一些初步翻譯及其譯後編輯的例子如表7。
在做譯後編輯時,使用的是特殊的譯後編輯網頁介面。編輯時,系統提供編 輯者四種操作:
(1) 修改:修改初步翻譯的詞(word)修正為正確的翻譯。
(2) 移動:將初步翻譯的詞在句子中移動到不同的位置,以修正翻譯順序錯 以簡化翻譯還原架構
翻譯
得到初步翻譯
以人工對初步翻譯 作譯後編輯
20
誤。
(3) 刪除:將初步翻譯中不必要的詞刪除。
(4) 對應:編輯者可將譯後編輯中的詞和英文句子的片語標記為翻譯關係,可多 個譯後編輯的詞對應到一個英文片語。
其中(4)是為了產生英文片語和譯後編輯詞的對應關係,以進一歩使用此資訊改善 翻譯結果。
表 7. 初步翻譯及其譯後編輯的例子
英文 X-ray on 2009/06/26 showed no bony lesions .
初步翻譯 骨 2009/06/26 的 X 射線 顯示 沒有 病變 。
譯後編輯 2009/06/26 的 X 光 顯示 沒有 骨頭的 病變 。
英文 Bone scan was arranged on 07/23 , and it showed uptake over left distal tibia .
初步翻譯 安排 了 骨掃描 在 07/23 , 它 表明 在 離開 吸收 distal 脛骨。
譯後編輯 在 07/23 安排 了 骨掃描 , 顯示 左側 遠端 脛骨 有 攝入 。
英文 After discharge , one episode of fever was noticed and then fever was subsided gradually under oral antibiotic treatment .
初步翻譯 出院 後 , 然後 發熱 一 次 發熱 被 發現 是 逐漸 緩和 下 口服 抗生素 治療 。
譯後編輯 出院 後 , 一 次 發熱 被 發現 然後 發熱 逐漸 緩和 因 口服 抗 生素 治療 。
英文 Bilateral leg weakness as well as polyuria were noticed during 2008/10 , and he received whole brain radiotherapy during 2008/11/14 ~ 28 .
初步翻譯 腿 以及 雙邊 弱點 尿 被 發現 在 2008/10 , 他 收到 的 整 個 腦 放療 在 2008/11/14 ~ 28 。
譯後編輯 雙 腿 無力 以及 多尿症 被 發現 於 2008/10 , 他 在 2008/11/14
~ 28 接受 全 腦 放射線治療 。
21
編輯者開始編輯後,系統會記錄下列資訊:
(1) 初步翻譯中每個詞對應到英文句子中哪個片語,若無對應片語則對應到 NULL。
(2) 譯後編輯句子中每個詞對應到英文句子中哪個片語(word alignment),若無對應 片語則對應到NULL。
其中(1)的對應資訊是由 Moses(Koehn 等人, 2007)所提供,(2)則是編輯者在修改翻 譯時所標註。該網頁系統(Chen 等人, 2012)的介面如圖 6。有了(1)和(2)的資訊,便 可用於3.1.2 節產生翻譯規則。(2)的例子如表 8。
圖 6. 病歷翻譯譯後編輯系統
22
表 8. 譯後編輯系統的編輯紀錄
23
3.1.2 運用譯後編輯記錄產生翻譯規則
此節將說明如何使用 3.1.1 節所取得的片語對應資訊,來得到新的翻譯規則。
從譯後編輯記錄(表)中我們可以得知每個英文片語的譯後編輯中文翻譯,因此可以 找出容易被翻錯的部分,並將之修正。在此我們抽取出兩種新的翻譯規則,類型 翻譯規則(class pattern)和詞彙翻譯規則(lexical pattern):
1.類型翻譯規則:
在2.3.1 節中,我們提到 Chen 等人(2012)用頻率及文法合理性來取出重要的病 歷英文句型,再交由專家翻譯而得到重要雙語翻譯規則。然而由於專家的人數有 限,代價很高,無法翻譯所有的句型,在步驟(5)只翻譯每群中出現頻率最高的句 型。因此仍有許多句型尚未被翻譯,而這些句型都是經過文法合理性驗證的。
我們將用來做譯後編輯的1004 句英文句子集合稱作 A,經過步驟(4)處理後的 句型集合稱為 B,經過步驟(5)處理後的句型集合稱為 C。抽取新類型翻譯規則的 方法如下:
對B 中的每一個句型,若符合下述條件(1)、(2),則抽取此句型和其譯後編輯 的翻譯做為可能的類型翻譯規則。
(1) 此句型有出現在 A 中。
(2) 此句型沒有出現在 C 中。
經過上述過程後,由於未必每個翻譯規則都適合作為類型翻譯規則,因此我們接 著以人工檢視抽取出的翻譯規則,只挑選出較適合的規則。
一些取出的類型翻譯規則如表9。
24
表 9. 從譯後編輯紀錄取得的類型翻譯規則例子 英文 received oral $藥物
中文 接受 口服 $藥物
英文 $藥物 was used empirically
中文 $藥物 依據經驗 使用
英文 $檢驗 revealed $診斷 with $診斷 中文 $檢驗 顯示 $診斷 1 合併 $診斷 2 英文 multiple $部位 $診斷
中文 多發性 $部位 $診斷
英文 left distal $部位 mass 中文 左側 遠端 $部位 腫塊 英文 empirical $藥物 was prescribed 中文 經驗 $藥物 被 開立 英文 follow-up $檢驗 on $時間 中文 後續 $檢驗 於 時間 英文 after $藥物 and $藥物 use 中文 經過 $藥物 1 和 $藥物 2 的 治療
2.詞彙翻譯規則:
在譯後編輯的紀錄中,每句英文都被分成許多片語,每個片語都有其對應的 譯後編輯中文翻譯,其中片語是由統計式翻譯系統決定。我們希望找出容易被簡 化翻譯還原系統翻錯的片語,並利用譯後編輯記錄將其翻譯修正。因此,對 1004 句英文句子,我們檢視每個英文片語,若該片語曾被修正成同樣的中文兩次以上,
25
則取此英文片語和該中文翻譯做為詞彙翻譯規則,一些修正及取得的詞彙翻譯規 則例子如表10。
表 10. 譯後編輯修正及取出的詞彙翻譯規則例子
英文片語 簡化翻譯還原系統 譯後編輯中文翻譯
was intubated 是 intubated 被 插管 low grade fever 低 期別 的 發熱 低 度 發燒 fever with night sweating 發熱 合併 盜汗 發燒 合併 盜汗 initial presentation 起始 表現 起初 徵兆 lower leg weakness and
numbness
小腿 的 弱點 及 麻木 小腿 的 無力 及 麻 木
3.2 非監督與半監督式學習之應用
在 Chen 等人(2012)的研究中,雖然簡化翻譯還原架構可以大幅提升翻譯效果,
但簡化翻譯還原需依靠既定的翻譯規則(pattern)和簡化規則,若英文句子中有翻譯 規則沒有涵蓋到的部分,則無法使用此架構。若要得到更好的翻譯,一種最根本 的方法仍是提升統計式翻譯的翻譯品質,但由於領域相關的雙語語料不足,使得 這個方法有其難度。為了解決領域相關雙語語料不足的問題,在這一小節我們提 出以非監督與半監督式學習的方式,產生虛擬的領域相關雙語語料庫,並以這個 語料庫當作訓練資料,以產生領域相關的統計式翻譯系統,並以此新的統計式翻 譯系統取代原本簡化翻譯還原架構中的統計式翻譯。
26
3.2.1 以非監督式學習訓練模型
接下來我們首先介紹如何產生虛擬平行雙語語料庫。產生虛擬平行雙語語料 庫的初步想法如圖7:
圖 7. 產生虛擬平行雙語語料庫的基本想法
首先我們以簡化翻譯還原系統翻譯1.3 節介紹的醫院英文病歷語料庫,接著 再將翻譯產生的中文句子和英文病歷語料庫做成平行語料庫,此平行語料庫便是
醫院英文病歷語料庫
以基本的翻譯規則和字典來簡化病 歷句子
以統計式翻譯系統翻譯
醫院英文病歷語料庫+初步中文翻譯
= 虛擬平行雙語語料庫 將被簡化的部分還原
初步中文翻譯
27
虛擬平行雙語語料庫。但是由實驗中(將於第四章詳述)發現,簡化翻譯還原系統加 入3.1 節介紹的新翻譯規則後可有效提升 BLEU 分數,因此我們決定在產生虛擬雙 語語料庫時加入3.1 節的新翻譯規則,以提高虛擬平行雙語語料庫的中文翻譯正確 性,這就是我們之後用非監督式學習來產生虛擬平行雙語語料庫的方式。
流程如圖8:
圖 8. 加入新翻譯規則以產生虛擬平行雙語語料庫的流程 以基本的翻譯規則+新翻譯規則和
字典來簡化病歷句子
以統計式翻譯系統翻譯 醫院英文病歷語料庫
醫院英文病歷語料庫+初步中文翻譯
= 虛擬平行雙語語料庫 將被簡化的部分還原
初步中文翻譯
28
3.2.2 以半監督式學習訓練模型
在圖 8 的流程中,我們將全部的中文翻譯都視為正確的翻譯,並製作成平行 雙語語料庫,此種將全部翻譯皆視為正確,不經挑選的方式可看做一種非監督式 的學習。除了以非監督式學習的方式產生虛擬平行雙語語料庫,我們也提出了半 監督式學習的方式,如圖9:
圖 9. 以半監督式學習產生虛擬平行雙語語料庫的流程 醫院英文病歷語料庫
以基本的翻譯規則+新翻譯規則和 字典來簡化病歷句子
以統計式翻譯系統翻譯
挑選過的中文翻譯+對應的醫院英文病歷句子
= 虛擬平行雙語語料庫 挑選較佳的初步中文翻譯
將被簡化的部分還原
初步中文翻譯
29
在經過簡化翻譯還原架構翻譯後,我們不接受全部的初步中文翻譯,只選出經過 挑選的初步中文翻譯和其對應的英文句子做為虛擬平行雙語語料庫。我們挑選的 標準是:只挑選整句皆為中文的句子。其原因是,由於簡化翻譯還原架構產生的翻 譯中仍有一些問題,包括未知詞問題、拼錯字而未翻譯的英文、未斷詞的英文,
其統計資料如表11,例如平均 100 句中有 38 句有未知詞問題。
表 11. 簡化翻譯還原架構翻譯中的錯誤統計
錯誤類型 發生百分比
未知詞 38%
拼錯字 8%
未斷詞 4%
一些含有英文的中文翻譯如表12:
表 12. 含有英文的句子的例子
這 是 introverted 12y3m/o 女 病人 的 性質 。
在 印象 經常 膀胱腫瘤 、 pt2n0m0 或 ct3an0m0 , 她 收到 的 人 工 血管 implatation 94-11-21 。
thepain 是 dullness 在 字符 和 局部 anterior 左手 胸部 。
出生 : 歷史 g2p2 : 39+wks 、 GA 、 BBW 、 NSD : 3570gm PROM ( - ) ,
小伙子 , pobas 和 LCX RCA 進行 順利 。
我們發現摻有英文的句子通常是較差的翻譯,原因是由於無法辨識的英文詞而造
30
成翻譯規則無法套用,簡化翻譯還原架構也會無法使用。而整句皆為中文的句子 通常是較佳的翻譯,一些全句皆為中文的句子如表 13。因此我們嘗試移除含有英 文的中文翻譯,只選擇全句皆為中文的句子當做虛擬平行語料庫的訓練資料。
表 13. 整句都為中文的例子
然後 她 來到 我們 的 門診 作 進一步 評估 。
左乳房 和 腋窩淋巴結 的 細針穿刺 完成 及 細胞學 的 淋巴結 是 腺癌 。 但 她 沒有 經驗 咳嗽 、 發燒 或 呼吸急促 。
近年 來 , 她 住院 幾 次 主要 是 由於 腹脹 及 呼吸困難 。 由於 溫度 機構 穩定 , 我們 制止 恆溫箱 使用 自 2/17 。
3.3 運用領域相關單語語料庫於簡化翻譯還原架構
在 3.1 節中我們提到運用譯後編輯的紀錄來產生新的翻譯規則,而在 3.2 節中 則說明了如何運用非監督及半監督式學習來產生虛擬平行雙語訓練資料。在這小 節中我們將說明如何把新的翻譯規則和虛擬平行雙語訓練資料以不同方式結合,
並產生不同的模型來改進簡化翻譯還原架構。
圖10 描述了我們的模型流程。我們提出了多種不同的模型,而各模型的主要 差別就在於圖中的翻譯規則和統計式翻譯系統。我們使用不同的翻譯規則和統計 式翻譯系統來組成不同的模型。接下來我們將以圖說明翻譯規則以及統計式翻譯 系統的產生方式,並於第四章詳述各個模型的內容。
31
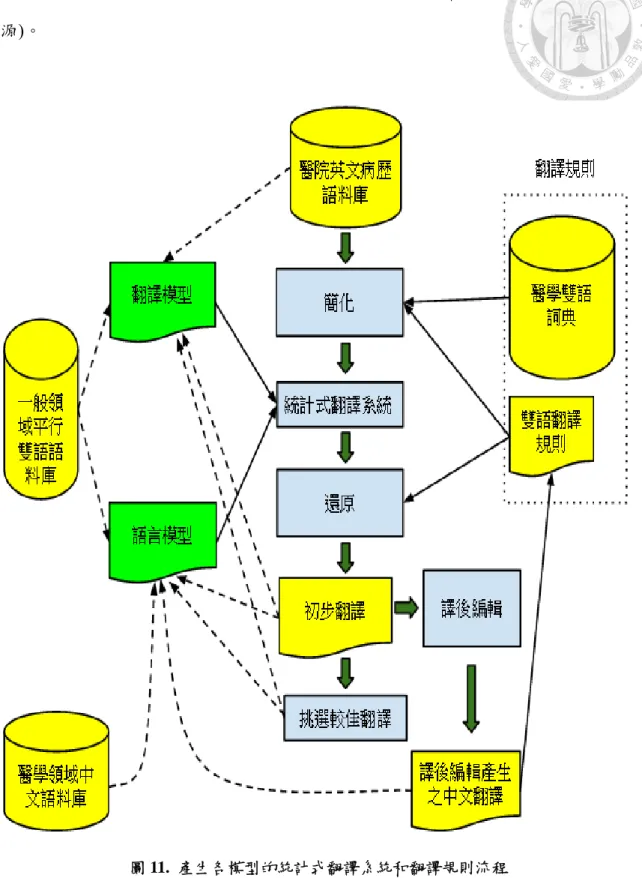
圖 10. 翻譯流程
產生各模型的統計式翻譯系統和翻譯規則流程如圖 11。圖中首先將醫院的英 文病歷交給簡化翻譯還原架構來翻譯,也就是先以基本的醫學詞典和雙語翻譯規 則作簡化,再將簡化後的句子以統計式翻譯系統翻譯,接著把被簡化的部分還原,
還原後的結果就是初步翻譯。接著初步翻譯的用途主要分為兩個路徑: (1)挑選一部 份(1004 句)初步翻譯做譯後編輯(Chen 等人, 2012),並從譯後編輯的結果抽取新的 翻譯規則加入雙語翻譯規則中,另外譯後編輯也可作為新的語言模型的訓練資料,
以產生新的統計式翻譯系統。(2)大量的初步翻譯可直接做為翻譯模型和語言模型 的訓練資料,以產生新的統計式翻譯系統,亦可先經過挑選,並只將較佳的翻譯 做為新統計式翻譯系統的訓練資料。另外在實驗中,我們亦嘗試從網路收集醫學
以翻譯規則和字典來簡化病歷句子
以統計式翻譯系統翻譯
中文翻譯結果 將被簡化的部分還原
英文病歷句子
32
領域的中文語料,並將其做為新統計式翻譯系統的訓練資料(將於第四章詳述來 源)。
圖 11. 產生各模型的統計式翻譯系統和翻譯規則流程
33
第四章 實驗設計與結果分析
本章將說明我們實驗設計,以及實驗結果與進一步分析討論。4.1 節詳述了實 驗會用到的資料。4.2 節則詳述了各模型的內容,包括各模型的配置和配置的原因。
4.3 節則對實驗結果做了一些分析。
4.1 實驗資料介紹
本實驗用到的語料庫將介紹如下。我們使用以下語料庫來訓練2.3節提到的簡 化翻譯還原架構的基本統計式翻譯系統:
香港中英平行語料庫(Hong Kong parallel text) (LDC2004T08),
UN中英平行語料庫(LDC2004E12)。
此兩個語料庫用來訓練基本統計式翻譯系統的翻譯模型,其內容包含法律、新聞 領域,共有6.8M句。基本統計式翻譯系統的語言模型則是以上述語料庫的中文部 分及中央社語料庫(Central News Agency part of the Tagged Chinese Gigaword) (LDC2007T03) 來訓練三元(trigram)語言模型。語言模型所用的語料庫共有18.8M 句。
除了用上述一般領域的語料庫來訓練統計式翻譯系統,我們還使用了一些醫 學領域的資料以建立簡化翻譯還原架構,敘述如下: 我們從台大醫院病歷中取出 60,448份英文病歷資料(共1.8M句),以取出n元翻譯規則(n-gram patterns),並以一 體化醫學語言系統(Metathesaurus of the Unified Medical Language System (UMLS)) 來提供醫學類別查詢。在簡化翻譯還原架構中,最後共得到了981條翻譯規則,這 些規則就是簡化翻譯還原架構的基本翻譯規則。
在以非監督/半監督式學習產生虛擬雙語語料庫的步驟中,我們從台大醫院病 歷中挑選了(隨機選取)2.1M及1.1M句英文病歷,並以M11模型(將於4.2節中敘述)
34
翻譯它們,以產生病歷的虛擬雙語語料庫,此處分成2.1M及1.1M是為了測試虛擬 雙語語料庫的大小對訓練效果是否有影響。
除此之外,我們亦使用在3.2 節中提到的選取較佳翻譯的方法,來挑出較佳 的翻譯。以此方式共從2.1M 的虛擬雙語語料庫中挑出了 0.95M 句。
另外,我們利用從病歷資料中取出的1,004 句英文病歷,以 3.1 節中敘述的譯 後翻譯方式取得了 422 句翻譯規則,其中類別規則共有 246 句,詞彙規則有 176 句。抽取類別規則時有人工介入,類別規則在未經人工檢視前有 259 句,經過人 工檢視後,才從中篩選出適合的246 句規則。
我們亦將這 1,004 句病歷分為 804 及 200 句兩部分,其中的 804 句用來訓練 M2(將於 4.2 節中提及)模型的語言模型,而 200 句則是當做模型的調適資料(將於 4.2 節中提及)。
為了測試相關領域的語料庫是否有用,我們也嘗試從網路取得醫療領域的語 料,當做統計式翻譯系統的語言模型訓練資料。由於病歷資料在網路上難以取得,
因此我們從華藝數位的中文期刊(Chinese Electronic Periodical Services)中抓回醫學 領域論文的中文摘要,包括各種醫學領域,並去除較不相關的科別,例如獸醫、
牙醫、中醫等領域的文章,剩下取得30,000 句醫學領域的句子。
為了測試各模型的效能,我們從醫院病歷中另隨機取出了1000 句英文病歷並 以人工翻譯,做為我們的測試資料和正確答案。
4.2 實驗設計
在本小節將描述我們提出多種模型,包括如何修改簡化翻譯還原架構中的翻 譯規則和統計式翻譯系統。
我們使用 Moses 來實作基於片語的統計式翻譯系統。要訓練一個統計式翻譯
35
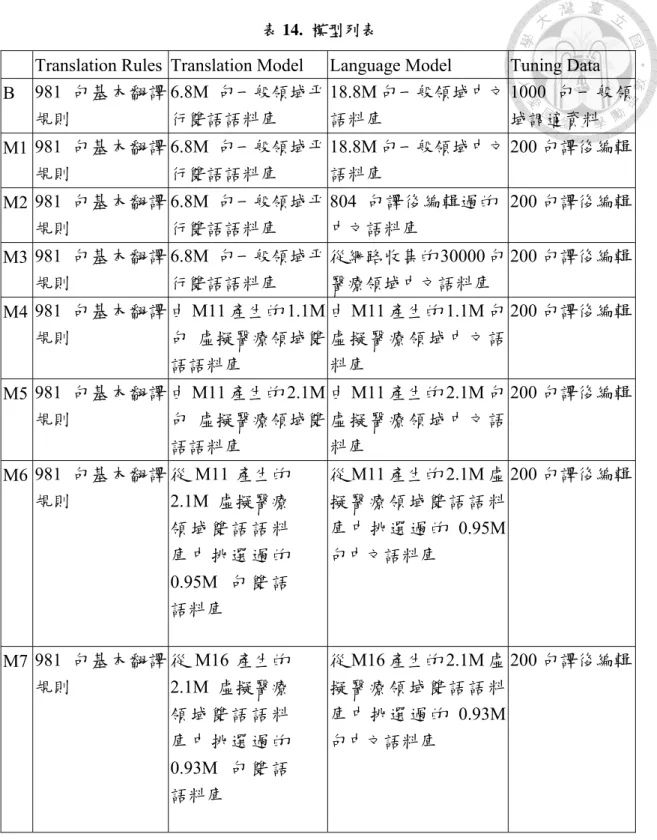
系統,必須有三種資料: 翻譯模型訓練資料、語言模型訓練資料、調適資料。分別 用來訓練翻譯模型、語言模型集最佳化各模型的權重。表14、15 詳述了各模型的 配置資料。
在表 14 中,所有模型都使用相同的翻譯規則來做簡化翻譯還原,而表 15 的 模型則全部加上從譯後編輯得到的新翻譯規則。接下來將逐一介紹表中的各模型:
1. B: B 為基本模型,其統計式翻譯系統是由以一般領域的語料庫做為訓練及調 適資料,翻譯規則也是由Chen 等人(2012)抽取出的 981 句翻譯規則組成。此 模型就是Chen 等人(2012)在其研究中提出的架構。
2. M1: M1 的統計式翻譯訓練資料和 B 相同,但調式資料則換成 200 句譯後翻譯,
翻譯規則和B 相同。
3. M2: 在 M2 中,我們嘗試將 1,004 句譯後翻譯中的 804 句做為統計式翻譯系統 的語言模型訓練資料。
4. M3: 在實驗中,我們使用 4.1 節提到的 30,000 句醫學領域文章,將其做為語 言模型的訓練資料。M3 便使用了此資料做為統計式翻譯的語言模型訓練資 料。
5.
M4: 在 M4 中,我們參照圖 8 的流程,使用模型 M1 翻譯了 1.1M 句英文病歷,並將翻譯的中文和英文原文做為平行雙語語料庫來訓練統計式翻譯系統,並 以此統計式翻譯系統當做M4 的統計式翻譯系統(圖 8)。
6.
M5: M5 和 M4 同樣都使用 M1 產生的虛擬平行雙語語料庫當做統計式翻譯的 訓練資料,不同的是,在M5 比 M4 多了 1M 句,我們希望觀察較多的虛擬雙 語語料是否能提升翻譯效果。7.
M6: 我們從 M1 翻譯的 2.1M 句虛擬平行雙語語料庫中,以 3.2.2 節提到的方 法,挑出了0.95M 句較佳的翻譯,並以這 0.95M 句做為 M6 的翻譯模型和語 言模型訓練資料,以期得到更好的翻譯結果。8. M7: 由於在 B,M1~M6 的實驗結果中(將在 4.3 節中提到),M16 的效果是最好
36
的,因此我們使用M16 再翻譯同樣的 2.1M 句英文病歷,並使用 3.2.2 節的方 法從2.1M 句中選擇較佳的 0.93M 句,將這 0.93M 句做為 M7 的統計式翻譯的 訓練資料。
9.
表15 的 M11~M17 和表 14 的 M1~M7 的差別在於,M11~M17 加上了從譯後 編輯取出的422 句新翻譯規則,作為固定的翻譯規則。37
表 14. 模型列表
Translation Rules Translation Model Language Model Tuning Data B 981 句基本翻譯
規則
6.8M 句一般領域平 行雙語語料庫
18.8M 句一般領域中文 語料庫
1000 句一般領 域調適資料 M1 981 句基本翻譯
規則
6.8M 句一般領域平 行雙語語料庫
18.8M 句一般領域中文 語料庫
200 句譯後編輯
M2 981 句基本翻譯 規則
6.8M 句一般領域平 行雙語語料庫
804 句譯後編輯過的 中文語料庫
200 句譯後編輯
M3 981 句基本翻譯 規則
6.8M 句一般領域平 行雙語語料庫
從網路收集的30000 句 醫療領域中文語料庫
200 句譯後編輯
M4 981 句基本翻譯 規則
由M11 產生的 1.1M 句 虛擬醫療領域雙 語語料庫
由M11 產生的 1.1M 句 虛 擬 醫 療 領 域 中 文 語 料庫
200 句譯後編輯
M5 981 句基本翻譯 規則
由M11 產生的 2.1M 句 虛擬醫療領域雙 語語料庫
由M11 產生的 2.1M 句 虛 擬 醫 療 領 域 中 文 語 料庫
200 句譯後編輯
M6 981 句基本翻譯 規則
從 M11 產生的 2.1M 虛擬醫療 領 域 雙 語 語 料 庫 中 挑 選 過 的 0.95M 句 雙 語 語料庫
從M11 產生的 2.1M 虛 擬 醫 療 領 域 雙 語 語 料 庫 中 挑 選 過 的 0.95M 句中文語料庫
200 句譯後編輯
M7 981 句基本翻譯 規則
從 M16 產生的 2.1M 虛擬醫療 領 域 雙 語 語 料 庫 中 挑 選 過 的 0.93M 句 雙 語 語料庫
從M16 產生的 2.1M 虛 擬 醫 療 領 域 雙 語 語 料 庫 中 挑 選 過 的 0.93M 句中文語料庫
200 句譯後編輯
38
表 15. 模型列表 M11 981 句基本翻譯規
則 +
來 自 譯 後 編 輯 的 422 句新翻譯規則
6.8M 句一般領域 平行雙語語料庫
18.8M 句一般領域中 文語料庫
200 句譯後編輯
M12 981 句基本翻譯規 則 +
來 自 譯 後 編 輯 的 422 句新翻譯規則
6.8M 句一般領域 平行雙語語料庫
804 句譯後編輯過的中 文
200 句譯後編輯
M13 981 句基本翻譯規 則 +
來 自 譯 後 編 輯 的 422 句新翻譯規則
6.8M 句一般領域 平行雙語語料庫
從 網 路 收 集 的 30000 句醫療領域中文語料 庫
200 句譯後編輯
M14 981 句基本翻譯規 則 +
來 自 譯 後 編 輯 的 422 句新翻譯規則
由 M11 產 生 的 1.1M 句 虛擬醫療 領域雙語語料庫
由M11 產生的 1.1M 句 虛擬醫療領域中文語 料庫
200 句譯後編輯
M15 981 句基本翻譯規 則 +
來 自 譯 後 編 輯 的 422 句新翻譯規則
由 M11 產 生 的 2.1M 句 虛擬醫療 領域雙語語料庫
由M11 產生的 2.1M 句 虛擬醫療領域中文語 料庫
200 句譯後編輯
M16 981 句基本翻譯規 則 +
來 自 譯 後 編 輯 的 422 句新翻譯規則
從 M11 產 生 的 2.1M 虛擬醫療領 域 雙 語 語 料 庫 中 挑 選 過 的 0.95M 句雙語語料庫
從M11 產生的 2.1M 虛 擬醫療領域雙語語料 庫中挑選過的 0.95M 句中文語料庫
200 句譯後編輯 語料庫
M17 981 句基本翻譯規 則 +
來 自 譯 後 編 輯 的 422 句新翻譯規則
從 M16 產 生 的 2.1M 虛擬醫療領 域 雙 語 語 料 庫 中 挑 選 過 的 0.93M 句雙語語料庫
從M16 產生的 2.1M 虛 擬醫療領域雙語語料 庫中挑選過的 0.93M 句中文語料庫
200 句譯後編輯
39
4.3 實驗結果與分析
4.3.1 評估方法
我們使用BLEU 做為評估的標準,BLEU 是一種用 N-gram 來評估機器翻譯效能的 方法,其公式如下:
=
∑∑ (( ))(3)
分母是一個句子能分割出的N-gram 數目,分子是分割的 N-gram 可以在答案找到 的數目, 就是N-gram 的準確率。除此之外,BLEU 還設有懲罰因子,若翻譯結 果太短則會扣分(在公式(3)中若翻譯結果太長,則分母會變大,也會被扣分),其懲 罰因子BP 如下:
BP = 1 >
≤
(4) c 為翻譯結果的長度,r 為正確答案的長度,完整的 BLEU 公式為:BLEU = BP∙ exp (∑ )
(5) 為權重。在我們的實驗中,N 設為 4, = 1/ 。4.3.2 結果分析
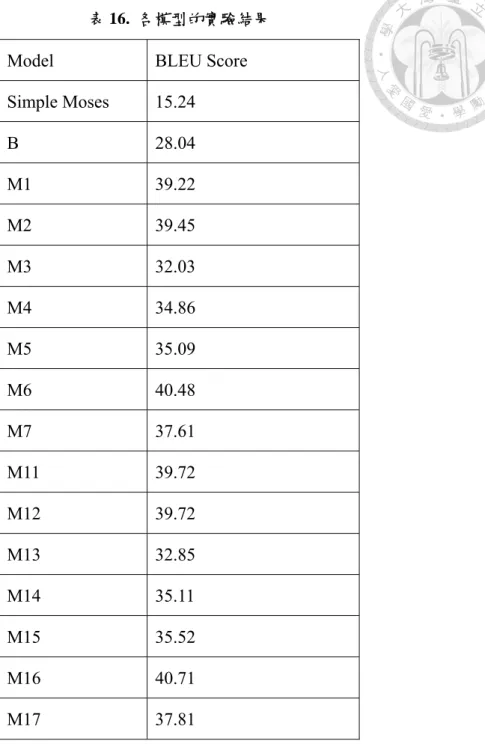
表14、15 的模型的實驗結果如表 16。
40
表 16. 各模型的實驗結果
Model BLEU Score Simple Moses 15.24
B 28.04 M1 39.22 M2 39.45 M3 32.03 M4 34.86 M5 35.09 M6 40.48 M7 37.61 M11 39.72 M12 39.72 M13 32.85 M14 35.11 M15 35.52 M16 40.71 M17 37.81
Simple Moses 代表沒有使用簡化翻譯還原,而只使用 Moses 來翻譯(Moses 的 翻譯模型、語言模型、調適資料都和B 相同),做為比較,顯示若只單純使用一般 領域的統計式翻譯系統可得到的效能。由表16 中可發現,加上簡化翻譯還原架構 (B)後 BLEU 會從 15.24 提升到 28.05,可看出簡化翻譯還原的效果。再觀察其他模 型,也可發現所有模型的BLEU 分數都較 B 高出許多,而表現最好的則是 M16。
41
以下討論將著重於探討各模型結果的差異。
B 和 M1 的差異只在於 Moses 的調適資料,換了調適資料後 BLEU 便從 28.05 升到39.22,因此使用 200 句譯後編輯當做調適資料可以明顯的提升 BLEU 分數。
而M1 在加入新翻譯規則後(變成 M11)BLEU 分數也有提升。M2 和 M1 的差別在 於M2 使用譯後編輯當做語言模型的訓練資料,相較於 M1 使用 18.8M 句一般領域 的語料庫來訓練語言模型,M2 只用了 804 句領域相關的語料庫便可達到和 M1 接 近的BLEU 分數,可見領域相關的資料對統計式翻譯的重要性。有鑑於領域相關 語料的影響,我們從網路取得30,000 句醫學領域的句子,並以此來訓練 Moses 的 語言模型,產生的模型就是M3。但 M3 的分數卻和 M1 有明顯落差,由於此 30,000 句醫學領域的語料皆是從醫學論文摘要取得,仍不是真正的病歷語料,可推測病 歷資料和一般醫學領域的資料仍是相當不同,因此BLEU 分數無法提升。
比較 M11~M13,可看出 M11 和 M12 的分數較高,因此我們便以 M11 翻譯大 量的英文病歷,以產生虛擬平行雙語語料庫。M4 就是以此 1.1M 句的虛擬平行雙 語語料庫來訓練Moses,但是從 BLEU 分數可發現 M4 沒有比 M1 的效果好。為了 討探虛擬雙語語料庫的大小對翻譯效能是否有影響,我們仍用 M11 多翻譯了 100 萬句的英文病歷,以2.1M 句的虛擬語料庫來訓練 Moses,形成了 M5。M5 的 BLEU 分數也較M1 低,稍高於 M4,但以 t-test 測試後結果並不顯著(p>0.05)。由於以非 監督學習的方式產生的統計式翻譯效果較M1 差,因此在 M6 中我們採用半監督式 學習,選取較佳翻譯的做法,產生了0.95M 句虛擬雙語語料庫,並以此訓練 Moses。
經過此步驟,M6 的 BLEU 分數便高於 M1。由於此方法可提升 BLEU 分數(從 M5 的 35.09 升到 40.48),因此我們以同樣的半監督式訓練來產生 M7,也就是以 M6 翻譯 2.1M 句病歷,在從中挑選出全句為中文的句子,共挑出 0.93M 句,再以此 0.93M 句訓練 Moses。但經測試,M7 的 BLEU 分數並未高於 M6,反而較低,我 們將在下面探討變低的原因。
M1~M7 在加上 422 條新翻譯規則後,BLEU 分數皆有提升,t-test 的結果如
42
表17。其中的 M13 是從 M3 加入新翻譯規則後的模型,其 BLEU 分數較 M3 有顯 著提升,由於M3 的模型中沒有用到新翻譯規則,因此可證明從譯後翻譯取出的新 規則確實能提升翻譯效果。另外M15 和 M14 的差距仍不顯著(p>0.05)。而 M16 的 BLEU 分數和 M11、M12 的差距以 t-test 測試後結果為顯著(p<0.05),證明以半監 督式學習方式產生的虛擬平行雙語語料庫確實能增強簡化翻譯還原架構。
表 17. 各模型 BLEU 分數差距的 t-test 結果
Model 比較 Significance?(p<0.05)
M2 vs M12 No, p = 0.42162
M3 vs M13 Yes
M4 vs M14 No, p = 0.26473 M5 vs M15 No, p = 0.05803
M6 vs M15 No, p = 0.16620
M7 vs M17 No, p = 0.13263
M16 vs M12 Yes M16 vs M11 Yes
我們以人工對B、M11~M17 的翻譯結果做了分析,我們將出現的錯誤分為順 序錯誤、歧義性錯誤。順序錯誤是指明顯不合中文文法的錯誤,歧義性錯誤是指 詞被翻為不適用的翻譯。未此兩種錯誤的例子如表18。
43
表 18. M11~M17 的翻譯錯誤例子
錯誤種類 例子
順序錯誤 原文 No discomfort after chemotherapy . 翻譯 沒有 不舒服 後 化療 。
歧義性錯誤 原文 After admission , lactulose was applied for hepatic encephalopathy .
翻譯 入院 後 , 乳果糖 是 申請 肝性腦病 。
統計的結果如表19,其中的 n%表示平均每 100 句中有 n 句有此錯誤。
表 19. 各模型的錯誤統計
Model B M11 M12 M13 M14 M15 M16 M17
Ordering
error 23% 15% 15% 17% 16% 15% 14% 15%
Word sense ambiguity
45% 24% 23% 39% 28% 29% 23% 28%
BLEU 28.02 39.72 39.72 32.85 35.11 35.52 40.71 37.81
由表20 可發現,B 以外的其他模型的順序錯誤差距都不大,可推論出 200 句的譯 後編輯調適資料能使詞的排序做得更好。除了B 之外,M13 的歧義性錯誤較其他 的模型多,可得知為語言模型的影響,由於M12 的語言模型雖然只有 804 句,因 此可進一歩推論是因為M13 語言模型的領域不同所造成,而非語言模型訓練資料
44
太少的關係。我們曾嘗試把虛擬雙語語料庫擴大,並產生了M15,希望 M15 能有 個好的表現,但M14 和 M15 的各項錯誤卻沒有明顯的差別。接著可看到 M16 的 歧義性錯誤又比M15 少,可見選擇較正確的訓練資料可有效幫助解決歧義性問題。
由於M17 的歧義性錯誤比 M16 多,BLEU 分數也比 M16 低,因此以同樣的方式 選擇較佳的翻譯可能無法一直帶來更好的翻譯結果,我們接下來將探討 M17 和 M16 翻譯結果的差異。
經過檢視翻譯結果,我們發現M17 會學習到一些錯誤的片語翻譯,並提高這 些錯誤翻譯在片語表中的機率。例如表20 中的例子:
表 20. 錯誤片語翻譯的例子
例子1 原文 He has complained of sore throat and odynophagia since 1/2 . M16 翻譯 他 抱怨 喉嚨痛 和 吞嚥 自 1/2 。
M17 翻譯 他 還 控訴 喉嚨痛 和 傳統 吞嚥 自 1/2 。
例子2 原文 After discussion with him , he did not want to receive the enterosc opy temporarily .
M16 翻譯 與 他 討論 後 , 他 不 想 接受 的 腸鏡檢查 暫時 的 。 M17 翻譯 與 他 討論 後 , 他 不 想 領取 在 腸鏡檢查 暫停 。
在例子1 中,M17 錯誤的將 ”and" 翻譯成 ”和 傳統”,在例子 2 中則錯將 “receive”
翻譯為 “領取”。藉由觀察 M16 和 M17 的片語表,我們發現在 M16 的片語表中“和 傳統” 翻成 “and” 的機率是 0,而 M17 的片語表中的機率則大於 0 ; 在 M16 的片 語表中”接受”翻成”receive”的機率是 0.0677263,在 M17 中則是 0.0450522(“接受”
是病歷中”receive”最常用的翻譯,在 1000 句測試資料中”receive”的正確翻譯全部 都是”接受”),較 M16 為低。更進一步觀察片語表的內容,我們發現在 M16 的片 語表中”receive”和 “and”在 M17 的翻譯選項數量比 M16 要少,如表 21。
45
表 21. M16 和 M17 的翻譯候選數量
詞 M16 的片語表中的翻譯選項 M17 的片語表中的翻譯選項
receive 13 7
and 414 217
因此,可推測使用3.2.2 節的選擇方式會使翻譯的選項越來越少。由於翻譯成正確 翻譯的機率變低,又因為使用只選取中文的方式,使得片語表的翻譯選項變少,
原本期望選項變少能使翻譯成正確翻譯的機率增加,但從片語表可看到翻譯成正 確翻譯的機率反而變低,因此可推論使用3.2.2 節的半監督式方法在一開始有較佳 的效果,但是第二輪後會使接下來的模型學習到上一輪模型的錯誤翻譯,使得效 果反而變差。Ueffing 等人(2007)在其自我改良的研究中,也是在第二輪訓練後沒 有得到比第一輪更好的效果,但在其研究中沒有對結果做更進一步的分析。
由於 M3 和 M13 的差異只在於有無使用譯後編輯的新翻譯規則,因此我們將 M3 及 M13 的結果做了一些比較,以驗證譯後編輯新翻譯規則的效果。M3 和 M13 的錯誤統計如表 22。從表中可看出,新翻譯規則主要能減少歧義性錯誤,M3 和 M13 的 BLEU 分數也有顯著差異(P<0.05),證明從譯後編輯取得的新翻譯規則確實 有用。表23 為歧義性錯誤的例子,表 24 為順序錯誤的例子。
表 22. M3 和 M13 的錯誤統計
Model M3 M13 Ordering
error 18% 17%
Word sense
ambiguity 43% 39%
BLEU 32.03 32.85
46
表 23. 歧義性錯誤的例子 例句
原文 He received blood transfusion and then was discharged M3 翻譯 他 收到 輸血 然後 出院
M13 翻譯 他 接受 輸血 然後 出院
原文 5th course of Taxol 253mg ( 175mg/BSA ) + Cisplatin 108mg M3 翻譯 第五 過程 紫杉醇 253mg ( 175mg/bsa ) + 順鉑 108mg M13 翻譯 第五 療程 紫杉醇 253mg ( 175mg/bsa ) + 順鉑 108mg
表 24. 順序錯誤的例子 例句
原文 And then Biopsy was done .
M3 翻譯 然後 活檢 是 .
M13 翻譯 然後 做了 活檢 .
原文 Stenting was done from distal IVC through left common iliac vein to external iliac vein .
M3 翻譯 支架置入術 是 做 從 distal 下腔靜脈 通過 從 左髂總靜脈 到 髂 外靜脈 .
M13 翻譯 完成 支架置入術 從 distal 下腔靜脈 通過 從 左髂總靜脈 到 髂 外靜脈 .
由於M16 在實驗中有最好的效果,因此我們對 M16 額外做了一些觀察。我們 將M6 和 M16 做了一些比較,以觀察加入譯後編輯的新翻譯規則後,對翻譯結果
47
有什麼影響。我們觀察到新翻譯規則可以改善一些錯誤,並將錯誤分為歧義性錯 誤和順序錯誤,其改善的例子如下:
1. 歧義性錯誤:
原文 Enhancement of right side pleural , and mild pericardial effusion was noted .
M6 翻譯 增強 方面 的 權利 胸腔 、 和 發現 有 輕微 的 心包積液 。 M16 翻譯 增強 的 右 胸腔 、 輕微 心包積液 被 注意到 。
2. 順序錯誤
原文
Thoracentesis was done on Feb 14 due to dyspnea with 1000ml
exudative pleural effusionM6 翻譯 穿刺 是 在 二月 十四日 因 呼吸困難 的 因素 與 1000ml 滲出 性 胸腔積液 。
M16 翻譯 做了 穿刺 在 二月 十四日 因 呼吸困難 的 因素 與 1000ml 滲 出性 胸腔積液 。
原文
Stenting was done from distal IVC through left common iliac vein to
external iliac vein .M6 翻譯 支架置入術 是 從 遠端 下腔靜脈 通過 從 左髂總靜脈 到 髂外 靜脈 。
M16 翻譯 完成 支架置入術 從 遠端 下腔靜脈 通過 從 左髂總靜脈 到 髂 外靜脈 。
雖然加入譯後翻譯的新規則能改善部分結果,但仍然有需要改進的地方,如 表20 顯示,在 M16 的翻譯中仍有 14%的句子有順序錯誤,23%的句子有歧義性錯
48
誤。我們對這些部分做了一些分析,並檢視這些錯誤為何沒有被虛擬雙語語料庫 及新翻譯規則改善。
(1)歧義性錯誤
原文: After tracheostomy , he was transferred to our ward for post operation care . M16 翻譯: 氣管切開術 後 , 他 被 轉送到 我們 病房 為 員額 關懷 行動 。
“post operation care” 應翻為術後照護,此為歧義性錯誤。由於 422 條新翻譯規則 是取自1,004 句譯後翻譯,而此 1,004 句無法涵蓋所有病歷內容,因此仍會有許多 歧義性錯誤沒有被修正。
(2)順序錯誤
原文: Antibiotics were discontinued after 8 days of treatment . M16 翻譯: 抗生素 中斷 後 8 天 的 治療 。
正確翻譯為”8 天 的 治療 後 抗生素 中斷 。”,這是一個順序錯誤,由於 422 條 新翻譯規則中只有2~5-gram,因此超過 5-gram 的順序錯誤便無法被更正。在 M16 的14%的順序錯誤中,有 9%屬於此種超過 5-gram 導致的錯誤,剩下的 5%則屬於 小於5-gram 的錯誤。可見未來若想更進一步改善順序錯誤,應該從改善長距離的 順序錯誤著手。
從上述觀察可看出,歧義性錯誤仍是跨領域翻譯最大的問題,而若要進一歩 有效的解決順序錯誤,未來可先由處理長距離(超過 5-gram)順序錯誤著手。
49
第五章 結論與未來研究方向
5.1 結論
本論文提出多種模型來處理跨領域翻譯問題,包括加入從譯後編輯資料取得 的新翻譯規則、從網路取得相關領域訓練語料庫、使用虛擬雙語語料庫做非監督/
半監督式學習來訓連統計式翻譯系統、以不同大小的虛擬雙語語料庫當做訓練資 料等。模型中表現最佳的是加入從譯後編輯取得的翻譯規則,並以挑選過的虛擬 雙語語料庫訓練統計式翻譯的M16,其 BLEU 分數為 40.71,和原本的簡化翻譯還 原系統(28.03)以及使用譯後編輯調適資料的 M11 (39.72)的 BLEU 分數相比,其差 距皆為顯著(p<0.05)。
經過分析翻譯結果,我們發現使用挑選過的虛擬雙語語料庫能夠有效的降低 歧義性錯誤,而加入從譯後編輯取出的翻譯規則亦能改善歧義性錯誤,此二種方 法使用前和使用後的BLEU 分數差異皆為顯著(M16 和 M15 比,M13 和 M3 比),
證明了這兩種方法的效果。
5.2 未來研究方向
本論文中提出了加入新翻譯規則和虛擬雙語語料庫以改進簡化翻譯還原架構 的方法,但仍有一些方向可供未來繼續研究。在從譯後編輯取出新翻譯規則時,
我們只抽取2~5-gram 長度的翻譯規則,如此一來就無法取得超過 5-gram 的翻譯規 則。另外從表22 中也可發現,我們從譯後編輯取出的新規則對改善順序的幫助不
50
大(錯誤率只從 18%降為 17%),未來若想有效的改善順序錯誤,或許需要從譯後編 輯資料中抽取其他的有用的資訊來幫助改善翻譯,包括抽取更長(超過 5-gram)的翻 譯規則,或是專門抽取調整翻譯順序的規則。我們在論文中嘗試使用虛擬雙語語 料庫改善翻譯結果,但最佳的模型仍有 23%的翻譯會有歧義性錯誤,若想持續改 進簡化翻譯還原架構,或許可加入其他的方法來改善歧義性問題,例如使用資訊 索(information retrieval)的方法來選取領域相關的訓練資料,或是以其他的方法來 挑選翻譯,以產生較佳的虛擬雙語語料庫。另外關於調適資料,在實驗中我們使 用了200 句的譯後編輯資料做為調適資料,其餘部分做為 M2 的語言模型訓練資料,
在實驗結果中M2 沒有比 M1 好,但我們沒有再繼續探究如何分配調適資料和語言 模型訓練資料的比例,更適當的分配比例或許可得到更佳的效果,這也可做為未 來的研究內容。