國立交通大學
工業工程與管理學系
博 士 論 文
中文字、詞在文章閱讀理解的背景下的認
知處理歷程
The Processing of Chinese Characters
and Words in Text Comprehension
研究生:黃永昌
指導教授:洪瑞雲 博士
中文字、詞在文章閱讀理解的背景下的認知處理歷程
The Processing of Chinese Characters and Words in Text Comprehension
研究生:黃永昌 Student: Yung-Chang Huang
指導教授:洪瑞雲博士 Advisor: Dr. Ruey-Yun Horng
國立交通大學
工業工程與管理學系
博士論文
A Thesis
Submitted to Department of Industrial Engineering and Management
College of Management
National Chiao Tung University
In Partial Fulfillment of the Requirements
For the Degree of
Doctor of Philosophy
in
Industrial Engineering
July 2008
Hsinchu, Taiwan, Republic of China
The Processing of Chinese Characters and Words in Text
Comprehension
Student: Yung-Chang Huang Advisor: Dr. Ruey-Yun Horng Department of Industrial and Engineering Management
National Chiao Tung University
ABSTRACT
Researchers met one problem while applying Latent Semantic Analysis (LSA) to Chinese: what should be input, single Chinese character or multi-characters words? In the present study, Kintsch’s text comprehension paradigm (1985, 1988), Construction-Integration Model, was applied to test the hypothesis that Chinese readers process character by character under Chinese text reading comprehension. In Experiment 1, four different prime-target relationships (single character, two-character words, context, and control) and three different stimulus onset asynchrony (SOA) (200, 500, & 1000ms) were manipulated between the prime and the target character. The participants were asked to do lexical decision task under reading comprehension task. Results of Experiment 1 indicated irrelevant meanings of Chinese characters and context meaning were parallel activated at 500ms SOA under reading comprehension task and this effect decayed at 1000ms, but irrelevant meanings of two-character words were inhibited under
reading across all three SOA’s. This result indicated Chinese character is more like English word under reading. In Experiment 2, four different prime-target relationships (the first character, the second character, whole word, and control) and three different stimulus onset asynchrony (SOA) (200, 500, & 1000ms) were manipulated between the prime and the target character. The
participants make lexical decision task. The results of Experiment 2 indicated all meanings of single character in words were parallel activated while reading two-character words.
Keywords: Latent Semantic Analysis; LSA; Chinese text comprehension; lexical decision task, contextual effect; Chinese character; Chinese words; priming effect
中文字、詞在文章閱讀理解的背景下的認知處理歷程
研究生:黃永昌 指導教授:洪瑞雲博士
國立交通大學工業工程與管理學系博士班
摘要
應用潛藏語意分析(Latent Semantic Analysis, LSA)到中文文章理解時,遭遇到的一 個困難是在字的輸入部分,究竟是要用個別的單字或是由單字組成的詞。在本研究中由文 章理解的建構-整合理論的觀點假設中文閱讀理解時以單字作為處理單位即可。在研究中 以比較中文雙字詞在有足夠的文章背景下即在薄弱的文章背景下,其詞義及其構成單字的 字義是否平行激發,以驗證此假設。實驗一以一次一個字的方式呈現中文文章,並檢驗雙 字詞之單字字義、詞義激發與文章背景訊息對字彙判斷作業的促發效果,結果發現當 SOA 為 500ms 時,與文章背景訊息無關的單字字義以及文章的背景訊息都會被激發,SOA 為 1000ms 時此激發產生的促發效果消失。另一方面,與文章背景無關的雙字詞詞義在 SOA 為 200、500、1000ms 時都產生負向的促發效果。此結果顯示中文的雙字詞中的單字字義 是被獨立且平行激發的,與建構-整合模型的假設相符,但雙字詞則不符合。實驗二是雙 字詞為背景來與比較雙字詞中構成單字的字義與雙字詞的詞義被激發的時間歷程,結果發 現雙字詞中個別組合單字在 SOA 為 200ms 時,其與雙字詞詞義無關的字義會與雙字詞詞 義皆被平行激發,且雙字詞中第二字的字義與雙字詞詞義的激發則皆會持續至 SOA 為 1000ms 時。綜合兩個實驗結果,我們推論在中文的理解歷程中,中文的認知處理單位可 以是單字。 關鍵字:潛藏語意分析、中文閱讀理解、字彙判斷、中文字詞、背景效果、促發作用
誌謝
本論文的完成,必須感謝洪瑞雲老師十年來,在我面臨人生徬徨境遇之際, 給予我無數的支持與指導。而方聖平老師對我的研究方向與論文內容的批評與指 正,同樣是我能夠完成論文的一大動力。同時也感謝劉美君老師的關懷與鼓勵, 還有柯華葳老師與李玉琇老師不辭路途辛勞擔任口試委員,在此一併致謝。 感謝王耀德老師的鼓勵以及推介實驗參與者,特別是庭瑜學長的熱心幫 助,以及林舒予老師、楊文瑞老師和幾位學弟妹的相助,家寧、柏輝、思諺、翌 盈、世寶、哲銘,和庭瑜學長的三位學生:正偉、昱良、淵鑫,沒有你們,實驗 不可能完成,也不會有這篇論文。同時也感謝明新科技大學工業工程與管理學系 的慨然相助。 接著要感謝的是父母及家人,特別是幫我寫出實驗程式的大哥。最後,我 要感謝的是少娟,沒有妳,我就不可能完成這篇論文,妳是我最後的支持力量, 願與妳分享所有的一切。目錄
英文摘要……… i 中文摘要……… ii 誌謝……… iii 目錄……… iv 表目錄……… v 圖目錄……… vi 第一章、導論……… 1 第二章、文獻探討……… 11 第三章、研究方法……… 48 第四章、結果……… 62 第五章、結論與討論……… 88 參考文獻……… 100 附錄一……… 109 附錄二……… 112 附錄三……… 113表目錄
表 3-1 實驗一目標字之字頻平均數與中位數表……… 51 表 3-2 實驗二的促發與目標刺激……… 59 表 3-3 實驗二目標字之字頻平均數與中位數表……… 59 表 4-1 閱讀理解正確率……… 63 表 4-2 閱讀理解正確率變異數分析表……… 63 表 4-3 實驗一 字彙判斷作業正確反應之反應時間(ms)……… 66 表 4-4 實驗一 字彙判斷作業正確反應變異數分析表……… 66 表 4-5 實驗一 字彙判斷作業正確率(%) ……… 67 表 4-6 實驗一 字彙判斷作業正確率變異數分析表……… 68 表 4-7 實驗一 字彙判斷作業正確反應之反應時間(ms)……… 70 表 4-8 實驗一 字彙判斷作業正確反應變異數分析表……… 71 表 4-9 實驗一 字彙判斷作業正確率(%) ……… 73 表 4-10 實驗一 字彙判斷作業正確率變異數分析表……… 74 表 4-11 實驗二 字彙判斷作業正確反應之反應時間(ms)……… 78 表 4-12 實驗二 字彙判斷作業正確反應變異數分析表……… 79 表 4-13 實驗二 字彙判斷作業正確率(%) ……… 80 表 4-14 實驗二 字彙判斷作業正確率變異數分析表……… 81 表 4-15 實驗二 字彙判斷作業正確反應之反應時間(ms)……… 83 表 4-16 實驗二 字彙判斷作業正確反應變異數分析表……… 83 表 4-17 實驗二 字彙判斷作業正確率(%) ……… 85 表 4-18 實驗二 字彙判斷作業正確率變異數分析表……… 85圖目錄
圖 3-1 實驗一的實驗進行程序……… 56 圖 3-2 實驗二的實驗進行程序……… 61 圖 4-1 實驗一 字彙判斷反應時間 ……… 65 圖 4-2 實驗一 字彙判斷正確率 ……… 67 圖 4-3 實驗一 字彙判斷反應時間 ……… 70 圖 4-4 實驗一 字彙判斷正確率 ……… 73 圖 4-5 實驗二 字彙判斷反應時間 ……… 78 圖 4-6 實驗二 字彙判斷正確率 ……… 80 圖 4-7 實驗二 字彙判斷反應時間 ……… 82 圖 4-8 實驗二 字彙判斷正確率 ……… 84第一章 導論
一、研究背景與動機
由於電腦科技的進步,許多研究者試圖以電腦資訊技術來貯存、抽取並運 用人類的文字紀錄。例如,Landauer,Foltz,與 Laham(1998)依據 Landauer & Dumais(1997)的長期記憶語意知識模式發展出的潛藏語義分析系統(latent semantic analysis, LSA)利用字在文件出現中的同時出現(co-occurrence) 的頻率關聯性建立一個頻率矩陣(frequency matrix),在利用字與字的情境間 關連性適當地縮減矩陣形成的向量空間,以此來表徵出一個字的字義或一篇文章 的大意或抽象概念。由於 LSA 是以英文為基礎發展的,將之應用在類似的拼音文 字時並無特殊的問題。然而 LSA 應用在中文的文章理解時,就產生了一個令人困 擾的問題:中文應該以哪一個文字階層作為頻率矩陣中的單位?主要的問題來源 是因為在英文或類似的拼音文字裡,字(word)具有明確的視覺外觀可以作為斷 字(parsing)的方式,但是在中文裡卻非如此。 藉由對文字發展與結構的分析,可以進一步地說明中文裡單位定義的困難 所在。語言的構成或分析單位由最小至最大依序為音素(phoneme)、音節
(syllable)、詞素(morpheme)、字(word)、片語(phrase)、與句子(sentence), 其中前二類單位(音素與音節)是以語音為基礎(sound-based)的單位,而其 他的則是以意義為基礎(meaning-based)的單位。目前仍在使用中的文字便可
依其構字規則與語言表徵的方式可分為三大類系統:意符文字(logography)、
音節文字(syllable)、拼音文字(alphabet)(Taylor, 1981)。
語言的書寫系統若一個字是直接指涉到一個事物(意義)的單位時,稱為 意符文字(如,山、魚)(Gelb, 1963)或表意文字(ideography)(Diringer, 1968)。
目前唯一留存並在使用中的意符文字是漢字,或稱中文字。而文字系統中以一個 符號來代表語言中的一個發音音節的文字系統稱為音節文字,現存具有最長遠歷 史的音節文字則是日文中的兩種假名(kana):片假名(katakana)與平假名 (hiragana)。文字系統中以符號來表達語言中的最小單位「音素」的文字系統 稱為拼音文字(如,A,/ei/)。由於英文是目前世界上最多人使用的語文系統, 也因為英文在拼音文字裡,相對上具有較高度的形-音不一致性 (grapheme-phoneme noncorrespondence),例如同一字母在不同的拼字狀況下 所表徵的音素不同,或是不同字母表徵的是同一音素,英文便成了目前被研究最 多的語言。目前文字的閱讀理解歷程的研究多數是以英文為研究的對象(Taylor, 1981),這也使英文成為拼音文字的代表。 由上述三大文字系統的描述中可以發現,拼音文字、音節文字與意符文字 所表徵的語言單位由小至大依序為音素、音節、詞素。因此,拼音文字與意符文 字可說位於文字發展光譜的兩個極端,以下將以這兩種文字系統的代表文字:英 文與中文來比較其間的差異。 英文的組成階層由下至上依序為字母(letter)→字(word)→片語(phrase) →句子(sentence)→文章(discourse, text)。英文中的字是由一個或一個以 上的字母所組成,字母的組合表徵的是不同的讀音。在文章中,英文的字與字之 間會有固定的空間來顯示字的邊界範圍(boundary),單字或句子均固定的由左 至右來書寫。 然而中文的文字系統的組成階層和結構與英文不同。中文的組成結構是: 部件(radical)→字元(character)→詞(word)→片語→句子→文章(Taylor, 1981)。部件是由不同形式的筆畫(stroke)所組成的,每一個字元是由一個或 以上的部件構成,形成在一個約略相對固定大小的空間中,而一個或以上的字元
可以組合成詞,中文可以自左而右或自右而左或由上而下的方式書寫。因此字元 是中文的主要知覺單位,具有視覺邊界範圍;而每一個字元都表徵了中文裡最小 的意義單位,即詞素;每一個中文字元的讀音也只有一個音節。 但是許多的學者均認為,中文的閱讀單位並非是字元,而是由字元所組成 的詞(如 Chen,1992)。中文中的詞是由一個以上的字元所組成的意義單位,其 意義和其構成的個別字元可能有關也可能無關。將多字詞做為中文的閱讀單位, 是符合大多數中文的使用者的習慣與直覺的,但這是表示中文閱讀者在閱讀中文 時是以詞還是以字元為認知處理對象,則是一個未被解答的疑問。由英文的研究 成果開始,我們以 Rayner 與 Pollatsek(1989)的研究文字辨識(word recognition)時的六個核心問題,與文字辨識研究的一般性結論出發,來探討 這個問題的解答。 Rayner 與 Pollatsek(1989)提出,文字辨識研究的六大核心問題為:第 一,字的辨識是否需要學習?第二,字的辨識是否是自動化的(automatic)? 第三,辨識文字的歷程是否須先觸接讀音,再由讀音觸接字義?第四,在一個字 中的每一字母的處理歷程是序列式的(serial)還是整體的(whole)?第五, 熟練的閱讀者是以拼音規則(rule of spelling)還是藉由建立特定的形-音關 係來學習一個字的讀音的?第六,文章背景是否會影響一個字的辨識?其中第 二、第四與第六的問題核心均指向一個字的辨認時的基本假設,亦即:若字是一 個文字系統中不可分割的意義單位時,其認知處理的歷程應該具有高度的自動 化;一個字中的字母應該是整體被處理的;一個字在文章中是獨立被處理而與背 景無關的。若這三項條件皆成立,則我們便可以推論一個文字系統中的「字」 (word)是文章閱讀理解時的處理單位。對應到中文閱讀理解的歷程,此三條件 表示,若詞是中文處理的對象,則詞的辨識歷程應該是自動化的;詞中的字元應 該是整體被處理的;一個詞在文章中是獨立處理而與背景無關的。若單字是中文
處理的對象,則單字的辨識歷程應該是自動化的;單字中的部件應該是整體被處 理的;一個單字在文章中是獨立處理而與背景無關的。本研究的目的即在區分在 文章中獨立被處理的是單字還是詞。 以英文為對象的研究大致上已獲取四個一般性的結論:1.文字辨識是相當 自動化的;2.文字辨識不只是將字母轉換成字音,然後再將字音換為字義的歷 程,也有由字形直接獲取字義的歷程;3.字中的字母並非序列式地被處理的,而 是整體被處理的;4.字在文章中與單獨存在時期被處理的歷程是差不多的 (Rayner & Pollatsek,1989)。這四個一般性的結論回答了上述的三個條件, 亦即,自動化、整體處理、與獨立處理而與背景無關。由於這三個條件的成立, 可以合理地推論英文中的字,不但是在視覺上具有邊界分為而被區隔成為個別的 單位,在閱讀者的認知歷程中,每一個字是獨立且適合的意義分析單位。 然而以中文為對象的研究,並沒有能夠得到一致性的結論。例如鄭昭明 (1981)的中文詞優效果的實驗。觀察到中文的雙字詞也有 Cattell(1886)所 觀察到的字優效果,鄭昭明稱之為中文的詞優效果。然而他的研究中卻也發現出 一個與英文不同的特殊現象,亦即「詞優效果」只在低頻中文詞上觀察得到,但 在高頻詞上則無,這和認知自動化歷程的預測是不相符的。而 Zhang & Peng (1992)的研究結論則顯示出,一個雙字詞中構成單字字頻,會影響整個雙字詞 的辨識速度,顯示了雙字詞中的單字似乎不是整體被處理的。而包括 Taft,Huang 與 Zhu(1994)以及 Mattingly 與 Xu(1994)的實驗也重複驗證了這個單字字頻 在雙字詞中的效果。至於吳瑞屯,周泰立與劉英茂(1994),以及 Liu 與 Peng(1997) 的實驗則比較支持多字詞的整體處理現象。綜觀這些實驗的程序與材料,可以發 現以中文的單字或雙字詞為材料的研究經常有高度的材料依賴與作業依賴性,任 一研究即使以相同的變項設計,只要改變實驗材料或是參與者作業,如唸字作業 與字彙判斷作業,就很可能得到不一樣的結果。
另一類的研究則是從文章閱讀而來的,這些研究主要是討論中文的「斷詞」 問題。劉英茂,葉重新,王蓮慧,與張迎桂(1974)的實驗顯示,如將中文句子 中的單字進一步做詞與詞的空間分隔,並無閱讀幫助,反而可能產生干擾。陳烜 之(1987)與胡志偉(1989)進行類似的研究,但卻形成不一樣的結果。他們都 要求參與者辨認出文章中的特定單字,陳烜之(1987)發現在文章閱讀中偵測特 定單字,當單字位於合法詞中時比位於非詞中時容易辨識,他認為這是單字在文 章閱讀中的詞優效果。而胡志偉(1989)卻觀察到閱讀文章時,當單字位於合法 詞中時會比位於非法詞中難辨認,與陳烜之(1987)的結果剛好不相符。他認為 這是中文的詞劣效果。顯然胡志偉的研究比較符合多字詞整體處理歷程的預測, 因為當多字詞是被整體處理時,就不容易辨別出詞中的構成單位。但是他們的實 驗材料設計並未考慮到文章中單字字義與雙字詞詞義和文章意義的關聯性,無法 排除文章所造成的背景效果的混淆。 Hoosain(1992)要求參與者作詞的區隔(斷詞),結果發現每一個參與者 所做出的斷詞與其他人有相當大的差異,這個實驗指出一個現象,當我們將(多 字)詞視為中文的處理單位時,每一個人的心理詞彙可能會非常的不同。這裡的 「不同」指的不只是相同的詞對不同人而言有不同的含意,更指出每一個人所認 為的「詞」都是不一樣的。彭瑞元與陳振宇(2004)試著以類似 Hoosain 的方式 讓參與者對文章材料進行斷詞,來解釋為什麼會有斷詞不一致的現象。他們認為 由於中文在使用習慣上是多音節的,中文使用者並不習慣說單音節的詞彙,因此 會有避免單字詞單獨出現,而有在單字詞,如「美」,前後加上其他的字或詞的 傾向,如「美麗」或「好美」。 楊立行與陳學志(1995)則認為中文的斷詞歷程類似英文的剖句歷程 (parsing process),但並不完全相同。主要的差異是由於中文閱讀者不知道文
章中可能出現的詞會是什麼,因此必須藉著閱讀上下文才能判斷。然而楊立行與 陳學志的研究中發現的中文「斷詞歷程」本身,便已成為多字詞是中文閱讀時認 知處理單位的反證:亦即,閱讀中文文章時,文章中的詞是藉由背景訊息來確定 的,而非獨立於背景之外的存在。此與:「英文單字在文章中或單獨存在時其認 知處理歷程是相同的」的現象並不相同。 從過去關於中文閱讀單位的實證研究中可以發現幾個重點,一是多數學者 均以中文多字詞是否整體被處理來作為多字詞存在的證據,然而這些相關的研究 並未達到一致的結論;二是許多學者研究重點在印證中文多字詞的「心理真實性」 的存在,他們的研究也以證明「心理真實性」存在為主,然而多字詞「心理真實 性」的存在與否並不表示多字詞就是中文閱讀時的基本資訊處理單位;三是從文 章閱讀的相關研究可以發現,多數的學者均認同中文的詞在文章中需要文章的背 景訊息來確定的。由 Rayner 等人所提出的文字辨識核心問題來判斷,可以發現 目前以多字詞為中文閱讀單位的假設所進行研究並不能清楚地回答這三個問 題:多字詞的認知處理是否是自動化的?多字詞是否是整體被處理的?以及單獨 存在的多字詞與在文章中的多字詞的基本認知處理歷程是否是相同的? 本研究以 Kintsch(1988,1998)的文章理解的建構-整合理論為基礎,並 延用他的實驗典範以探討中文文章閱讀時的「斷詞歷程」的問題,希望藉此為 LSA 的系統究竟比較適合用單字為輸入單位或多字詞為輸入單位,尋找一合乎 事實的理論依據。在建構-整合理論中,文章的閱讀理解是藉由建構歷程來激發 出在長期記憶中我們所閱讀到的每一個英文字的所有意義,這字義激發歷程是 一個由下而上(bottom-up)的、意識無法選擇與控制的歷程。在字被閱讀後極端 短的時間內產生,Kintsch 個人的研究中發現,在 400ms 以下,一個字的相關 意義將會被平行激發。經由建構歷程我們會得到一個字的所有字義,但是這些 字義和文章中其他字義所激發出來的字義可能並不相容,因此會有另一個整合
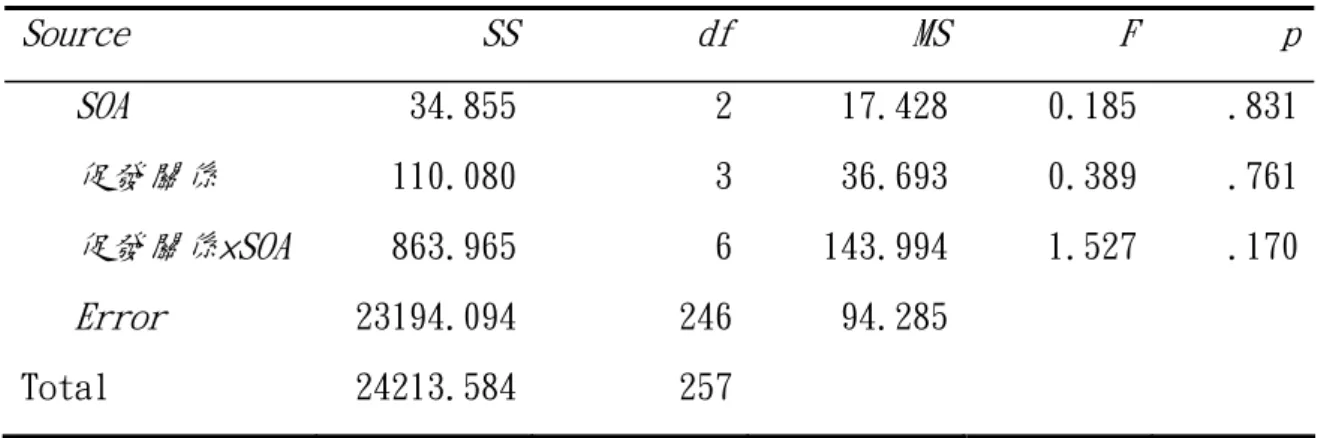
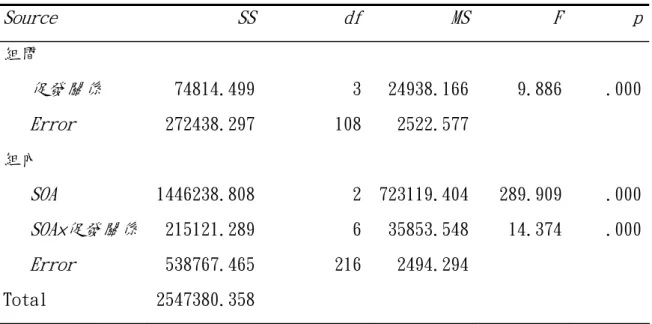
歷程以保留文章理解所需要的字義而排除不需要的字義,這是一個由上而下的 (top-down),可以受意識控制的歷程。中文的「斷詞歷程」,就楊立行與陳學 志的定義來看,比較像是整合歷程的一部份:閱讀者選擇並確定中文詞的邊界 範圍。然而,若採取多字詞是中文閱讀的基本單位此一假設,其所牽涉的卻是 詞義建構的歷程:激發出每一個詞的意義的過程。本研究所欲探討的是中文文 章閱讀的建構歷程,文章中雙字詞的詞義與其構成單字的字義的自動激發歷 程。研究中將比較雙字詞在文章背景中的詞義及構成單字促發效果(實驗一), 以及在文章背景薄弱的雙字詞中詞義及構成單字的字義促發效果(實驗二)。若 中文雙字詞在閱讀時是整體被處理的,則我們預期不論在有無文章背景中,詞 義的多重意義將會被同步激發,對與其意義相似的目標字的判斷產生正向促發 效果。相對的,若中文詞在閱讀時是其構成單字是個別被處理的,則我們預期 不論在有無文章背景中,字義的多重意義將會被同步激發,對與其意義相似的 目標字的判斷產生正向促發效果。 我們將以 Kintsch(1988,1998)的建構-整合模型為基礎,設計二個實驗 來進行中文閱讀時的分析單位研究。 二、研究問題與假設 依據 Kintsch 的建構-整合理論,本研究假設中文閱讀時的處理單位是單 字,以兩個實驗來檢驗這個假設,藉兩個實驗的結果以回答下列問題: 實驗一 問題 1:在有文章背景時,句子中的雙字詞的詞義及其構成單字的字義是否會被 平行激發? 假設 1:單字的字義與雙字詞的詞義都會被平行激發。 問題 2:在中文文章閱讀時,句子中的雙字詞的詞義、單字的字義的激發時間歷 程是否不同?
假設 2:單字的字義激發歷程會在較短的時間內出現,雙字詞的詞義激發出現的 時間會比單字字義激發晚。 實驗二 問題 3:閱讀一個中文雙字詞時,雙字詞中組成單字的字義是否會被平行激發? 假設 3:雙字詞中的組成單字字義會被平行激發。 問題 4:雙字詞的詞義及構成單字的語意訊息激發的時間是否不同? 假設 4:單字的字義激發歷程會在較短的時間內出現,雙字詞的詞義激發出現的 時間會比單字字義激發晚。 藉由實驗一和實驗二的結果的比較,我們將進一步探討中文雙字詞在有無 文章背景時的詞義激發歷程是否相似,以回答 Rayner 的第六個問題(單字或雙 字詞在文章背景下與單獨存在的認知歷程相同)。 三、研究變項的定義 實驗一 實驗一將以雙重作業的模式進行,參與者需要同時閱讀理解文章並完成嵌 入於文章中的字彙判斷作業。實驗將操弄嵌入的字彙判斷作業之目標字與促發刺 激,以及目標字呈現的時間歷程兩個自變項。並以字彙判斷作業的反應時間與正 確率為依變項。 1.自變項 自變項有二,定義如下: 促發刺激與字彙判斷作業目標字間的關係,分為四種水準: 1) 單字促發組:目標單字與文章中不定的句子之末字間有意義關連,目標 字與句末雙字詞和文章意義皆無語意關連。 2) 雙字詞促發組:目標單字與文章中不定的句子之末雙字詞間有意義關
連,目標字與句末雙字詞中的單字和文章意義皆無語意關連。 3) 文章促發組:目標單字與文章的意義有意義關連,目標字與句末雙字詞 中的單字和句末雙字詞無語意關連。 4) 控制組:目標單字句末單字、句末雙字詞,以及文章意義均無語意關連。 刺激開始異步,SOA,代表刺激接觸記憶後的處理時間。定義為句末字呈現 至目標單字呈現的時間差,共有三個: 1. 短 SOA:200ms。句末字出現後至目標單字出現的時距為 200ms。 2. 中 SOA:500ms。句末字出現後至目標單字出現的時距為 500ms。 3. 長 SOA:1000ms。句末字出現後至目標單字出現的時距為 1000ms。 2.依變項:由真假字字彙判斷作業中衡量目標字判斷所需的時間,目標字有一半 為真字一半為假字,以真字的正確反應項目估計。 反應時間:目標字出現至參與者做真假字反應的平均反應時間(毫秒,ms)。 正確率:參與者的字彙判斷作業的平均正確率(百分比)。 閱讀理解正確率:參與者閱讀文章後進行的閱讀測驗正確率。 實驗二 以字彙判斷作業方式進行,實驗以前向促發方式呈現促發刺激與目標刺激。 1.自變項 自變項有二,定義如下: 促發雙字詞與目標單字間的關係,共有四種: 1) 第一單字促發組:目標單字與促發雙字詞的第一個單字有語義關連,但 目標字與第二字及促發雙字詞間皆無語義關連。如目標單字「生」與促 發詞「活頁」。
2) 第二單字促發組:目標單字與促發雙字詞的第二個單字有語義關連,但 目標字與第一字及促發雙字詞間皆無語義關連。如目標單字「生」與促 發詞「逃命」。 3) 整詞促發組:目標單字與促發雙字詞有語義關連,但目標字與詞中任一 單字間皆無語義關連。如目標單字「生」與促發詞「分娩」。 4) 控制組:目標字與促發雙字詞及詞中的單字均無語意關連。如目標單字 「生」與促發詞「快速」。 刺激開始異步,SOA,代表刺激接觸記憶後的處理時間。定義為促發雙字詞 呈現至目標單字呈現的時間差,共有三個: 1. 短 SOA:200ms。句末字出現後至目標單字出現的時距為 200ms。 2. 中 SOA:500ms。句末字出現後至目標單字出現的時距為 500ms。 3. 長 SOA:1000ms。句末字出現後至目標單字出現的時距為 1000ms。 2.依變項:由真假字字彙判斷作業中衡量目標字判斷所需的時間,目標字有一半 為真字一半為假字,以真字的正確反應項目估計。 反應時間:目標字出現至參與者做真假字反應的平均反應時間(毫秒,ms)。 正確率:參與者的字彙判斷作業的平均正確率(百分比)。
第二章 文獻回顧
潛藏語意分析與語意分析的單位
潛藏語意分析(Latent Semantic Analysis, LSA)是由 Landauer, Foltz, Laham(1998)所提出的一個長期語意記憶(long-term semantic memory)提取 的演算模式。LSA 假設一個字的字義是由此字出現的背景與在此相同背景中同時 出現的其他字義所共同決定的,在它的演算法中利用文章與文章中字彙出現的頻 率及字彙之間的頻率關連性來表徵出文章的意義概念。其基本的方式是對一篇文 件(text)建立一個頻率矩陣(frequency matrix),將此文件的特定段落、句 子等設為矩陣列(背景),而每一個矩陣列中出現的每一個字彙設為矩陣行,矩 陣中的數值則為該詞在矩陣列中(段落或句子等)所出現的次數頻率。針對一篇 文件所形成的頻率矩陣,可以視為一個 m 行(背景)乘以 n 列(字)的 n 維度向 量空間。而這個以頻率矩陣建立的向量空間,可以表徵出該文件的概念意義。但 只要是足夠篇幅的文件,其維度(n)會非常大,Landauer 等人(1998)發展出 以奇異值分解方式(singular value decomposition)來縮減此向量空間的大小。 亦即利用各字彙間的相關來降低向量空間的維度,並且同時可以表達出各個字彙 間的關係。Landauer 與 Dumais(1997)以英文百科全書為輸入文件資料,在利 用百科全書形成的向量空間作答 TOFEL 的同義詞測驗時,發現當空間維度縮減為 300 個,其作答結果與非英語系國家應試者的結果最為相近。維度多於 300 或少 於 300,其表現都不如維度為 300 時。因此藉由維度的縮減,更能夠顯示出文件 的潛藏概念意義。 LSA 能夠應用在許多方面,如教育方面,可以用來評估學生的學習成果 (Rehder, Schneider, Wolfe, Laham, Landauer, & Kintsch, W. 1998);研究 人類的知識學習與問題解決能力(Landauer & Dumais, 1997);增進學生閱讀與
寫作能力(Kintsch, Steinhart, Stahl, 2000)等。在心理學方面,LSA 可以作 為一個學習、閱讀理解、問題解決等認知歷程的模擬工具(Kintsch, Patel, Ericsson, 1999; Kintsch, 2000)。資訊科技方面,可以用來做資訊檢索、文件 索引與摘要、不同語言系統間的翻譯等(Deerwester, Dumais, Furnas, & Landauer, 1990)。 LSA 演算模式的出現對文章理解的認知研究提供了一個建構人類長期記憶 中字義提取的利器。LSA 是以英文為基礎建立的文章概念意義整合與提取的技 術,中文使用 LSA 也被應用在中文的文章理解系統,主要應用在資訊檢索、文件 索引與摘要等用途(葉鎮源, 2002; 吳佳昇, 2004),以及教育用途(陳意芬, 2002)等。然而中文與英文有相當大的差異,但是這些研究幾乎沒有探討語言文 字系統的差異與 LSA 的使用與應用間的問題。事實上不只是 LSA,其他的相關資 訊提取技術,幾乎都是以英文或者其他拼音語言為基礎發展的,但是中文與英文 這兩個文字系統有相當大的差異,應用 LSA 或者其他相關的技術於中文系統,要 解決的第一個問題就是中文文章的 m × n 矩陣中的字的單位究竟是單字詞或多 字詞的問題。 一篇文章的理解牽涉到對文章中字義的認識與解讀。Kintsch(1988, 1998) 以建構-整合模型的理論來說明閱讀理解的兩個基本歷程,一是文中單字字義的 平行激發,稱為字義的建構(construction)歷程,當我們閱讀文章時,文章中 每一個字的字義會先被激發出記憶中所有相關的字義,然而字的各種字義在文章 中可能相互抵觸,因此會有一個文意的整合歷程(integration),透過一個限制 滿足(constraint-satisfaction)的機制來抑制與文章內容或主題不符的字義, 僅保留與文章背景相一致的字義,以進一步整合出整個句子的大意。也就是說, 由建構-整合模型來看,閱讀者在看到文章中的每一個字時,字的各種字義都會 被激發,然後才以文章的背景訊息去除不必要的並留下文章所要的訊息,再整合
於整個的文章理解之中。亦即,閱讀理解時,單字(word)是認知處理單位。我 們在閱讀時,首先建構出閱讀到的每一個字的每一個字義,然後依據文章的背景 訊息,選擇需要的字義,再整合成為更大閱讀單位(句子、段落或文章)的意義。 當我們用建構-整合模型來看 LSA,可以發現 LSA 是以每一個字作為其建立 頻率矩陣的基礎,這個基礎可以視為建構歷程的表徵,亦即閱讀理解的第一個歷 程是從每一個字「建構」其字彙的基本意義開始的。而矩陣的建立與奇異值縮減 為較小維度空間向量的過程,可以視為整合歷程的表徵,意即我們在建構了每一 個字彙的意義後,會依據其背景訊息來選擇出需要的字彙意義,並將這些被選擇 而留下來的意義整合出句子、段落乃至一篇文章的意義。而任何時候,當我們看 到一段文句時,此句子的整體大意是由這些字在 LSA 縮小後的 300~400 的意義 的維度(出現背景)的距離所計算出來的。因此,LSA 不是一個武斷的、沒有理 論基礎的訊息提取方法,它的語意提取歷程非常近似人類的閱讀理解認知歷程。 但是建構-整合模型及 LSA 是以英文的研究建立的,中文的文字系統與英文 乃至其他所有的拼音文字系統有相當大的差異,LSA 與建構-整合模型一樣都是 以單字(word)作為其基礎的處理單位,那麼當我們要研究中文的閱讀歷程,或 者是運用 LSA 或類似的語意提取方法時,中文系統的處理單位是什麼呢? Nei 與 Ren(1999)曾經比較中文的多字詞與雙字詞在語意提取上的實際效 果,Nei 與 Ren 認為目前有兩種主要的中文詞分割(word segmentation)方式: 一個是利用字典或辭典,也就是以辭典中所定義出來的詞彙來分割;另一個則是 以統計方式,亦即相同字串同時出現的次數來定義多字詞並做多字詞在文章中的 分割,他們設定了幾種分割法,一是二字分割,一是最長分割,最長分割意指盡 可能取到最長的,重複出現的字串來當作多字詞。他們比較了數個不同的詞彙分 割結果,結果發現以最長字分割法的結果比雙字詞分割所進行的訊息提取回憶率
要稍好,並且如果能綜合二者進行訊息提取,會比任兩者的結果都好一點,但 Nei 等人並未進行統計顯著性的比較,無法看出「稍好」的顯著性,因其用不同 字串分割法建立的 LSA 向量空間得到的回憶率結果都在 0.4-0.5 之間。因此 Nei 等人的結論是:任何一種分割方式都能得到差不多的結果,但是如果綜合使用, 可能會有更好的效果。陳意芬(2003)即以 Nei 等人的結果,在她的研究中使用 最長分割法來做字詞切割。Wu, Yang, 與 Soo(1998)則直接使用中文單字作為 LSA 的輸入單位,他們用網路蒐集的 1190 篇涵蓋不同主題的文章來進行 LSA,結 果發現以單字為單位作的訊息提取作語意訊息的回憶率,比起用多字詞做的結果 是差不多的。 不過如果比較這些用中文為材料所做的 LSA 語意提取研究,就可以發現這 些研究的結果比起 Landauer 等人(1997)的研究,其效果差很多,例如葉(2004) 的研究,用 100 篇週刊中的政治類文章建立 LSA 的摘要實驗,其 LSA 的回憶能力 只有大約 52%及 45.6%,葉認為斷詞的好壞會影響摘要的正確性。而許皓閔 (2004)的實驗則使用單字為 LSA 的輸入單位,以國中三年的國語文課本、半個 月的新聞語料庫,以及古文觀止的文言文建立 LSA 演算模型,並以 LSA 回答閱讀 測驗,其結果也只有約 40%的正確率。 從這幾個研究可以發現,如果我們在使用 LSA 或相關的訊息提取技術於中 文上時,由於中文字、詞的界線具有模糊地帶,斷字的邏輯與方法是一個爭議的 來源,也可能影響系統使用的效率與正確性。目前的相關中文字詞的電腦斷字技 術很難完全的自動化,如何解決這個問題,除了自動化的技術途徑外,另外則是 由人的認知歷程來探討中文閱讀歷程中訊息處理的方式究竟如何。或許可以從中 尋找一個既合乎心理真實性且又有一邏輯法則可循的文章閱讀的斷字方法。 中文的文章閱讀過程中的物理刺激是一個個書寫的字,然而許多研究者不
使用單字做為中文閱讀處理的原因是認為中文文章閱讀時的處理單位是詞(單字 詞、雙字詞、乃至多字詞),而非單字(Nei & Ren, 1999)。因此使用中文詞來 作為閱讀時的資訊處理單位才是符合閱讀歷程的訊息提取方式。但是在建立一個 如 LSA 這樣的中文長期記憶的語意提取演算模式時,遭遇的困難是中文截至目前 為止還很難建立起一個毫無爭議的斷詞方式,本研究的目的因此想探討在中文的 文章理解過程中,雙字詞的詞義激發過程。 以下我們將從中文與英文的文字系統差異、英文的相關認知研究乃至中文 的認知研究來探討中文文章閱讀時字詞的語意處理的問題。 文字系統的發展與特徵 語言的分析單位由最小至最大依序為音素(phoneme)、音節(syllable)、 詞素(morpheme)、字(word)、片語(phrase)、與句子(sentence),其中前二 類單位(音素與音節)是以語音為基礎(sound-based)的單位,而其他的則是 以意義為基礎(meaning-based)的單位。文字作為紀錄語言的符號,其所表徵 的即同時包含一事物或文件的語言(語音)與經驗上的意義(語意)兩個層面。 人類在五千多年前,就開始發展可書寫的符號來做為語言或重要事件的紀錄。經 過歷史的演變,目前仍在使用中的文字依其構字規則與語言表徵的方式可分為三 大類系統:意符文字(logography)、音節文字(syllable)、拼音文字(alphabet) (Taylor, 1981)。
語言的書寫系統若一個字是直接指涉到一個事物(意義)的單位時,稱為 意符文字(Gelb, 1963)或表意文字(ideography)(Diringer, 1968)。意符文
字是人類歷史上最早出現的文字。根據 Gelb(1963),中文是目前所有文字系統
中最具有意符特性的。文字系統中以一個符號來代表語言中的一個發音音節的文 字系統稱為音節文字,音節文字比意符文字更適合表現語言中的語音特徵(Gelb,
1963)。現存具有最長遠歷史的音節文字則是日文中的兩種假名(kana):片假名 (katakana)與平假名(hiragana)。由於日文本身具有音節文字特性(日語的 基本發音只有 50 種音節)、且夾雜漢字(kanji)與假名共同使用、加上使用日 文的廣大人數、以及日本在國際上的地位,日文也吸引了相當多學者的研究,成 為音節文字的代表(Taylor, 1981)。 文字系統中以符號來表徵語言中的最小單位「音素」的文字系統稱為拼音 文字。一種語言中的音素都不太多,通常在 12 到 70 個之間,因此只要使用少數 的符號就足以表徵一個語言系統中的所有發音(Taylor, 1981),這也是拼音文 字的最大特色:以最少的符號就可以排列組合出非常多的字彙組合。希臘字母 (Greek)可說是最早的拼音文字,時至今日,拼音文字已成為目前最廣泛使用 的書寫系統。由於英文是目前世界上最多人使用的語文系統,也因為英文在拼音 文字裡,相對上具有較高度的形-音不一致性(grapheme-phoneme noncorrespondence),例如同一字母在不同的拼字狀況下所表徵的音素不同,或 是不同字母表徵的是同一音素,英文便成了目前被研究最多的語言。事實上,目 前文字的閱讀理解歷程的研究多數是以英文為研究的對象(Taylor, 1981),這 也使英文成為拼音文字的代表。 由上述三大文字系統的描述中可以發現,依文字所表徵的語言單位的大小 依序為拼音文字、音節文字與意符文字。因此,拼音文字與意符文字可說位於文 字發展光譜的兩個極端,接著將進一步以這兩種文字系統的代表文字:英文與中 文來比較其間的差異。 英文的閱讀研究 英文的組成階層由下至上依序為字母(letter)→字(word)→片語(phrase) →句子(sentence)→文章(discourse, text)。字母所表徵的是音素,如 A
表徵/e/,B 表徵/b/。英文以 26 個字母來表徵約 40 個左右的音素,這表示有時 是需要使用一個以上的字母來表徵一個音素(Taylor, 1981)。英文中的字是由 一個或一個以上的字母所組成,每一個字具有一個或一個以上的音節,每一個字 具有一個或以上的詞素。數個字可以組合成片語或簡單的句子,數個句子可以組 合成一篇文章段落。在文章中,英文的字與字之間會有固定的空間來顯示字的邊 界範圍(boundary),單字或句子均固定的由左至右來書寫。 從 Miller(2002)的觀點,音素、字與句子都可以是語言分析的單位,那 麼在研究英文的閱讀歷程時,應該選擇上述字母至文章的那一個階層來做為閱讀 的處理單位?由於在英文文章中視覺上具有可識別的邊界範圍的是字(word), 且句子是由一個以上的單字構成,因此可以由單字辨識(word recognition)的 研究來探討單字是否為英文的閱讀認知單位。 Rayner 等人(1989)舉出了研究單字辨識時的六個核心問題:第一,單字 的辨識是否需要學習?第二,單字的辨識與其他的閱讀歷程是否是自動化的 (automatic)?第三,辨識單字的歷程是否須先觸接讀音,再由讀音觸接字義? 第四,在一個字中的每一字母的處理歷程是序列式的(serial)還是整體的 (whole)?第五,熟練的閱讀者是以拼音規則(rule of spelling)還是藉由 建立特定的形-音關係來學習一個字的讀音的?第六,文章背景是否會影響一個 單字的辨識?其中,第二、第四與第六的問題核心均指向一個字的辨認時的基本 假設,亦即:若單字(word)是一個文字系統中不可分割的處理單位時,其認知 處理的歷程應該具有高度的自動化;一個字中的字母應該是整體被處理的;一個 字在文章中是獨立被處理而與背景無關的。若這三項條件皆成立,則我們便可以 推論一個文字系統中的單字(word)是文章閱讀理解時的資訊處理單位。 Posner 與 Snyder(1975)指出三個認知自動化的判斷標準:第一,個體對
認知歷程是無意識的;第二,該認知的歷程是無法被當事人的意識控制的;第三, 該認知的處理歷程不會消耗認知的資源。若一個字的辨識符合這三個標準,則字 的認知可以被認為是自動化的歷程。
Meyer 與 Schvaneveldt(1971)的促發實驗(priming experiment)即提 供一個字的辨識歷程是無意識的證據。Meyer 等人(1971)的實驗發現,當目標 字為「CAT」而促發字為「DOG」或「FAN」時,即使促發字的呈現時間只有 20
毫秒(ms),高度意義關連的促發字「DOG」仍會對目標字「CAT」產生促發效果。
20ms 的呈現時間很顯然是在閾限下(subliminal)的狀態,且多數的參與者均
表示沒有看到促發字(Rayner 等, 1989),因此,我們可以說這是一種無意識的
促發效果(unconscious priming)。許多實驗均類似結果(例如 Balota, 1983, Carr, McCauley, Sperber, & Parmelle, 1982 等),由此推論,文字辨識的歷 程,至少在熟悉字的範圍內,是在人的意識之外的。 文字辨識能否以意識控制的證據來自於 Stroop(1935)所發現的 Stroop 效果,在他的實驗中,當參與者唸一紅色的字「GREEN」時,其反應速度會比唸 綠色的「GREEN」慢,而當刺激字為無關顏色的字「ANT」時,不論刺激字以什麼 顏色呈現,都不會影響唸字的速度。Stroop 效果顯示,不論我們是否意圖以較 快的速度來辨識一個字,與此字相互關聯的知覺訊息,如字的顏色,會影響閱讀 者的認知歷程,顯示字義的提取速度與色彩知覺的偵測速度同樣快速,且很難區 隔,這顯示字義的辨識歷程很難受閱讀者的意識控制,也符合了第二個標準:字 的辨識歷程是不在意識控制範圍內的。 較不一致的問題則是第三個標準,亦即文字辨識的處理歷程是否消耗認知 資源。Stroop 效果大體上支持了文字辨識難以受意識控制的假設,但同時也成 為自動化第三標準的反證:念紅色的「GREEN」時速度較慢,表示文字字義的辨
識歷程中,區隔字義與字的知覺屬性如色彩,是需要消耗認知資源的。不過其他 的證據仍顯示,即使文字辨識需要消耗認知資源,所消耗的也相當小。例如, Rayner 等(1981)以眼動追蹤方式進行閱讀研究,他們發現,閱讀者在讀一篇 英文文章時,每一個字的凝視(fixation)時間非常短,Rayner 等以遮蔽符號 遮蔽閱讀者所讀的文字,使閱讀者閱讀每一個字的時間不超過 50 毫秒(ms),此 時閱讀者的讀字速度與正常狀態下相比,僅減緩約 15%。因此,即使文字辨識需 要某些認知資源,字的辨識仍可視為是一個相對上相當自動化的認知歷程。由文 字辨識是無意識的、難以受意識控制的、消耗的認知資源非常少的三個條件來判 斷,在閱讀中以字為意義的分析單位是可以成立的。那麼,比字更小的單位:字 母(letter)是否也可以作為字義的分析單位?這便牽涉到上述 Rayner 等所提 出的第四個問題:字中的字母是如何被處理的? 100 多年前,Cattell(1886)就發現,參與者看到英文字或字母時,他們 分辨字比字母更容易,也就是字比字母更容易辨識。Reicher(1969)以更為嚴 謹的方式重做了 Cattell 的實驗,他呈現三種不同的刺激給參與者:字,(如
「word」)、字母,(如「d」)、非字(nonword),(如「owrd」),並在呈現刺激後
以圖形遮蔽覆蓋,然後要求參與者判斷最後一個字母是否為「d」。結果當參與者
所讀到的是「word」時,辨認出「d」存在的正確率顯著比較高。這就是所謂的 字優效果(word superiority effect):一個字的辨識比字母更為容易。
McClleland 與 Rumelhart(1981)則以交互激發模型(interactive activation model)在電腦上模擬字優效果。交互激發模型假設,人在辨識一個 文字時,字中的字母是同時且整體被處理的。當閱讀者看到「word」時,四個字 母「W」、「O」、「R」、「K」會同時被處理,經由特徵偵測後而激發視覺特徵相關聯 的字母訊息,如,「W」可能激發「W」與「V」;「O」可能激發「O」與「C」;「R」 可能激發「R」與「P」;「K」可能激發「K」與「V」;然後這些被激發的字母可能
在激發數的字,如:「FORK」、「WORD」、「WORK」等。然而只有「WORK」能符合這 四個字母同時激發出來的訊息,因此其被激發的程度最高,因而成為被辨識出來 的字。 字優效果與交互激發模型對文字辨識的模式,可以告訴我們,在字的辨識 中字母是同時被處理的,也就是字的辨識歷程是整體的(holistic),難以再被 分割,因此在閱讀的認知歷程中以字為資訊處理單位是合理的。然而,在閱讀文 章時,句子中每一個單字究竟是獨立地被處理,還是被文章背景所影響而改變了 資訊處理的單位,如跨單字的界線,而以詞為資訊處理的單位?如果一個字的處 理界線會因文章背景因素而變更,那麼將字作為一個文章閱讀時的資訊單位就可 能是一個不恰當的方式。這牽涉到 Rayner 等提出的第六個問題:文章背景是否 影響字的辨識?也就是一個字在單獨存在時和在它與其他字組合成句子或文章 時的認知處理的歷程是否會不同。 Kintsch(1988)的建構-整合模型正好可以回答這第六個問題:他和它的同 伴所做的研究指出人類認知理解的兩個基本認知歷程,第一,由單字字義建構 (construction)歷程平行激發一個字的各種意義。亦即,當我們閱讀文章時, 文章中每一個字的字義會先被激發出記憶中所有相關的字義。然而句子中各字的 各種字義在文章中字義可能相互抵觸,因此會有一個文意的整合歷程 (integration),以抑制與文章內容或主題不符的字義。也就是說,由建構-整 合模型來看,閱讀者在看到文章中的每一個字時,字的各種字義都會被激發,然 後才以文章的背景訊息去除不必要的並留下文章所要的訊息,再整合於整個的文 章理解之中。亦即,建構-整合模型架設閱讀理解時,字資訊處理單位。
Kintsch 依據 Van Dijk & Kintsch(1985),Kintsch 與 Mross(1985)以及 Till, Mross, 與 Kintsch(1988)的關於文字辨識與背景效果的研究,於 1988
提出他的文章理解的建構-整合模型。在建構-整合模型中,閱讀理解有兩個認知 歷程,一是建構歷程,當閱讀到一個字的時候,這個字的各種字義會被平行的激 發,這些被激發的字義需要依賴背景訊息保留符合文章意義的字義,這是閱讀理 解的整合歷程。他們使用快速連續視覺呈現(rapid serial visual presentation, RSVP)的實驗方式呈現文章,以探討在文章的背景中字的各種字義被平行激發的 歷程。在該研究的實驗二中,參與者以一次一個字的方式閱讀文章,並且同步進 行文章中所嵌入的字彙判斷作業。實驗所操弄的是目標字與前一個字(可視為促 發字)所形成的促發-目標關係,以及目標字與整篇文章的關係。文章分為兩組: 同形異義組(homograph)與腳本組(scriptal),同形異義組的目標字有三類: 第一類是關聯/主題關係,即目標字字義是符合文章的主題,同時也與前一個呈 現的促發字有語意關聯,如「iron」與「steel」;第二類是關聯/非主題,即目 標字字義不符合文章的主題,但與前一個呈現的促發字有語意關聯,如「iron」 與「clothes」;第三類是控制字,即目標字字義與文章主題或促發字皆無關聯。 其中,「iron」的兩個字義「鐵」與「熨斗」的連結強度是相當的。腳本組的目 標字也是三類:第一類是非關聯/主題關係,即目標字字義是符合文章的主題, 但與前一個呈現的促發字沒有語意關聯,如「plane」與「gate」;第二類是關聯 /混和,即目標字字義可以符合文章的主題,也可能不符合,但與前一個呈現的 促發字有語意關聯,如「plane」與「fly」;第三類則同樣是控制字。其中「plane」 的兩個語意關聯,「大門」與「飛」是不相等的。 實驗中的文章每個字呈現 150 毫秒,字與字的間隔為 40 毫秒,亦即促發字 與目標字間的呈現時間差距為 190 毫秒,每一個字都呈現在 CRT 螢幕的相同位置 上。目標字並非屬於文章中的字,當呈現至目標字時,目標字的前後各同時顯示 四個星號「****」。當參與者看到前後有四個星號的目標字時,就必須進行真假 字的字彙判斷作業。實驗的結果發現,不論目標字與文章主題有無的關係,只要 與促發字有語意關聯,就產生 86 毫秒至 106 毫秒的顯著促發效果。接下來,
Kintsch 等延遲目標字的呈現,在目標字與促發字間插入兩個干擾字,此時目標 字與促發字的呈現時間差距為 570 毫秒,以相同的材料進行實驗後,結果發現並 無顯著的促發效果出現。此結果顯示在極短(190ms)的時間內,文中一個字的 多種字義會被激發,但與文章無關的字義到 570ms 時即已被抑制,而僅餘與文章 相關的字義了。
Till, Mross, 與 Kintsch(1988)的研究更進一步的確定這個現象。他們 設計了含有約二至四個句子的 28 對短文,並以每一篇短文中無特定位置句子的
句末字作為促發字,設計五種促發-目標字關係:非字(nonword)、與背景訊息
相符的同義字、與背景訊息不符的同義字、與文章主題推論相符字、無關係的控 制字。並且設計 6 個不同的促發字與目標字呈現時間間隔,也就是刺激開始異步 (stimulus onset asynchrony, SOA):200ms、300ms、400ms、500ms、1000ms 與 1500ms。實驗發現,在 SOA 極短時(350ms 以內),不論目標字與背景訊息的 關係為何,只要與促發字間有語意關聯就有促發效果。然而當 SOA 增加時(1000ms 以上),只有與背景訊息相符的目標字有促發效果。Till 等認為,這些實驗的結 果支持了激發-選擇-精緻化模型(activation-selection-elaboration model),亦即人的閱讀歷程,是先激發每一個讀到單字的所有關聯字義,然後從 中選擇一個符合文章所需要的字義,再將整篇文章的意義建立起來的認知歷程。 從上述的文獻我們知道:英文字在文章閱讀過程中是以自動化的方式處理 的;字的認知處理歷程是整體的,且字在單獨存在或在文章中的處理歷程是一樣 的,因此在拼音文字的代表語文:英文中,字(word)是文章閱讀時的資訊處理 單位。 那麼,做為與拼音文字差異最大的中文,其閱讀時的處理單位是什麼?中 文的組成階層、視覺特徵與文章背景訊息的角色和英文有非常大的差異。在研究
中文的文字辨識或閱讀歷程時,有需要先確認出中文的處理單位。確認之後,我 們便得以適當地運用 LSA 等技術來處理中文文章。 中文文字構成的特徵與閱讀時的字義提取歷程 中文的文字系統的組成階層和結構與英文不同。一般認為,中文的組成結 構是:部件(radical)→字元(character)→詞(word)→片語→句子→文章 (Taylor,1981)。部件是由不同形式的筆畫(stroke)所組成的,每一個字元 是由一個或以上的部件構成,形成在一個約略相對固定大小的空間中,因此中文 被稱為是一種方塊字(Miller, 2002)。例如:字元「組」,是由「糸」與「且」 兩個部件所組成的,但「且」本身也是一個可以單獨形成的字元。每一個字元有 其個別的字義,而一個或以上的字元可以組合成詞,如「組織」、「分組」等,並 由詞組合成片語,如「分組討論」等,再組合成句子,如「我們上課必須要進行 分組討論」。 相較於英文的字(word),在中文會是什麼?我們先要解決的問題是,字究 竟是什麼?Sapir 指出「…第一個衝動是將字定義為一個概念的符號…這種定義 是行不通的。」(P.59)(Miller,2002)。行不通的理由很簡單:「概念」比字更 難定義,一個字可以對應到一個意義或一個概念,但一個概念很難用一個字來說 明。。因此 Sapir 的結論為:「字只是一個形式」。Miller(2002)以此為出發點 探討了兩個定義,第一個定義是:「字是兩個空間之間所印的任何字母序列,在 這些字母之間沒有空間相隔。」此定義即以視覺上的邊界範圍作為字的定義。如 果我們以這個定義來看,那麼英文中的字母或字母串(字首或字尾)可以類比為 中文的部件,在中文中具有邊界範圍的是字元,根據此定義字元在中文中的階層 就等於英文中的字(word)。Taylor(1981)指出,中文有三個特徵,第一個特 徵是中文是一個字元—一個詞素—一個音節:字元是中文的最小知覺單位,具有 視覺邊界範圍;而每一個字元都表徵了中文中最小的意義單位,即詞素;每一個
中文的讀音也只有一個音節。亦即,每一個中文字元都是一種形式,可以對應到
一個意義,也就是每一個字都具有自由形式(free form),每一個字元也都可以
是一個詞,並且獨自使用。
Miller 的這個定義的最大問題在於符合造字規則的假字(pseudo word), 以及不符合造字規則的非字(nonword)也都具有邊界範圍,但它們不是真正的 「字」。因此 Miller 提出第二個定義:「字是一個最基本的自由形式」。所謂「自 由形式」指,一、語言的「形式」為語言的任何有意義的單位,意義最小單位是 詞素,也就是無法再分割的最小意義單位;二、自由的形式是不需要依附在其他 形式上而可以自由存在的,例如英文過去式的「-d」,必須要附加的動詞上才有 意義,因此它只是一個結合詞素(bound morpheme);三、最小的自由形式是可
以單獨存在做為句子的,如「How are you today?」這個問句的回答,可以只是 「Fine」。
Miller 以「carpus」(腕骨)為例,「carpus」可以再分割成「carp」(鯉魚) 和「 us」(我們的受詞),或是「car」(汽車)和「pus」(膿)。然而這兩種分割 都不能夠組合出「腕骨」的意義。而「carpus」同時也可以做為回答「手腕上的 骨頭叫做什麼?」此一問句的答案。因此,無庸置疑地,「carpus」是最小的自 由形式。然而在中文系統中,「腕骨」是可以分割成「腕」與「骨」二者組合成 「手腕部位的骨頭」。由此推論,「腕骨」一詞在中文中並不是最小的自由形式。 以此定義來看,中文的詞並不具有不可再分割的特質,字元才有,因此以字元來 對應英文的 word 似乎比較符合字的定義。 Miller 也對由自由型式來作為文字單位的定義提出一些疑問,例如,有些 具有自由形式的 word,並無法成為一個句子,例如「the」。而複合詞(compound word)也是此定義無法處理的,例如,「Boston-to-Chicago」,包含了一個以上
的詞素,但被視為一個字,因為它不能被拆解開來使用。另外中文中的「的」就
面臨了類似「the」的窘境。針對哪一個階層才適合作為中文的分析單位,「複合
詞」是一個最重要的問題。複合詞在英文或其他拼音文字定義為:一,複合詞可 以像動詞一般地衍伸,例如,「horse」(馬)與「whip」(鞭打)所組合的「horsewhip」
(以馬鞭鞭打)可以衍伸成為「horsewhipped」;二,複合詞的組合方式通常為
一個片語/子句的相反單字順序,例如,
「horsewhip」的構成元件是一個名詞-動詞(N-V),其字義是從「whip a horse」的動詞-名詞(V-N)組合而來的;三, 複合詞是不能分開而在其間插入其他單字的,例如我們不能寫成
「horse-badly-whipped」(兇狠地鞭打馬)。第四,因為複合詞可以如一般動詞 使用,我們可以容許在句子裡放入贅字,例如,「He horsewhipped the beast」, 然而我們不能寫成「He whipped the horse the beast」(Bates, Chen, Li, Opie, & Tzeng,1993)。
很明顯地,以上的四個複合詞的標準並不適用於中文,Bates, Chen, Li, Opie, & Tzeng(1993)分析中文的複合詞的定義時指出,中文的複合詞與片語 結構狀態(phrase structure condition, PSC)之間的差異可以用以下三個標 準來區隔:第一,有限的分割性(limited separability),雖然中文的複合詞 (也就是多字詞,如「觀光」、「觀光區」、「觀光勝地」)都可以再分隔成更小的 詞素,但是不能結合成片語;第二,邊界性(boundedness),當複合詞中的字元 互相成為結合詞素時(例如「unhappy」是由「un」與「happy」結合成的複合字), 它們是詞而非片語,因此仍然保有英文中 word 的邊界範圍,但是中文的複合詞 與其他字元或其他詞間並無視覺上的邊界範圍,此邊界範圍依然僅存於字元之 間;第三,符合語言使用習慣(idiomaticity),一個複合詞的個別詞素在習慣 上不會拆開來使用。例如,中文的「蚯蚓」,「蚯」與「蚓」幾乎不可能有分開來 使用的機會。
Chen(1992)整理出幾個中文的特徵,他認為中文的 word,是由一個或以 一個上的字元所形成的。也就是中文中充滿了複合詞:例如「自由」、「故事」等 等。可能絕大多數中文使用者也都同意,中文中的意義單位是字元所組合的複合 詞。中文其他兩個特徵也可以來釐清中文單字與多字詞的關係。首先是關於中文 的組成結構:部件,中文是由部件所組合的,而且具有一定的組合規則。在英文 中,比英文的字更小的單位是字母,而比中文的字元更小的單位則是部件,如 「氵」,是「漢」的部件。過去的語言學家曾經認為,中文的筆畫是獨斷的、沒 有規則的,學習中文就像在記憶數千個電話號碼一樣(Halle, 1969),然而事實 上並非如此。早在二千年前的漢代,即已明確地指出中文的六大組字規則:象形 (pictograph)、會意(compound ideograph)、指示(simple ideograph)、轉 注(analogous)、假借(phonetic loan)與形聲(semantic-phonetic compound)。 從六書規則可以看出,中文每一字元(單字)的組字單位並非筆畫,而是部件。 在現代常用中文中,最多的是形聲字,其佔中文字數量約 80%(Li, 1977)。所 謂的形聲字意指,一個字內至少具有兩個以上的部件,其中一個部件含有與該字 讀音相關的訊息,稱為音旁,如「清」中的「青」;另一個部件則含有與該字意 義相關的訊息,稱為部首,如「清」中的「氵」。利用部首與音旁的組合,中文 可以創造出幾乎無限的組合。 其次,Chen(1992)指出中文另一個特徵,中文並無詞性變化或各種衍伸 的符號,例如,在英文中動詞有時態的變化「is」、「was」、「been」,而中文都只
有「是」。英文名詞中有單複數的「-s」,而中文中完全沒有。英文的動詞、名詞、
形容詞可以從特定字尾判別,如「-ive」、「-able」、「-ability」、「-ivity」等,
但中文的動詞與名詞是完全相同的。例如,「我在此聲明」中的「聲明」是動詞,
然而「他給我一份聲明」的「聲明」則是名詞,沒有辦法從文字結構上判別其間 的差異。因此,Chen 指出:背景訊息在中文的閱讀與理解中扮演決定性的角色。 正因中文的時態、單複數等等文法訊息完全沒有辦法從組字結構中看出,所以在
閱讀時,中文的讀者需要比英文或拼音文字的讀者更依賴文章背景訊息來釐清其 模糊性。 然而,除了 Bates 等人的分析外,我們必須注意的是,第一,英文的複合 詞是在同一個邊界範圍之內的,然而就中文的多字詞而言,多字詞與多字詞之間 並無邊界範圍,中文系統的邊界範圍仍僅存於字元與字元之間;其次,如同「腕 骨」的例子,中文的複合詞(多字詞)絕大多數具有兩個特徵:一,它們是可以 拆解成為更小的意義單位,例如「故事」,是由「故」,過去的;與「事」,事件, 由這兩個字與其代表字義所構成的。以同樣方式,我們可以組合出「故人」(過 去認識的人)、「趣事」(有趣的事件)等複合詞。二,中文裡許多雙字詞都是由 兩個類似意義的字元所組合的,例如「快速」、「緩慢」、「豐滿」等,「快」與「速」 字元組合成「快速」一詞後詞義與字義其實是相同的,只是重複加強而已。 Bates 等人也指出,中文裡的 V-N(動詞-名詞)組合同時帶有片語與詞的 特性,例如「我要讀書」,是「I want to read book」,此時的「讀書」可說是 一個多字詞,但也可以是一個片語。在中文使用慣例上,動詞很少單獨使用或作 為結尾,如,「我要讀」、「我吃」。在文章中,要把受詞明確表達出來,如「我要 讀書」、「我吃飯」。因此,要判斷中文裡的複合詞究竟是詞還是片語是一件非常 困難的任務。 從上述的討論中可以發現,將中文中的多字詞視為文章閱讀時的資訊處理 單位並將它與英文的 word 視為同一階層可能必須考慮的是前述的三個重點:自 動化、整體性與獨立性。相反的,如將字元視為與英文的 word 同一階層,比較 能夠符合。 我們可以從另一個觀點來討論中文的字元與複合詞的何者適用於閱讀時資
訊處理單位的問題。Taylor(1981)與 Chen(1992)均指出,由於中文是一種 表意的文字,不同的字形就是代表不同的字義,因此中文的數量與字形極其龐 大。以 18 世紀的康熙字典為例,其中就收錄約有四萬五千個中文。當然,日常 使用的中文不可能這麼多。劉英茂,莊仲仁與王守珍(1975)曾整理出 4532 個 不同的常用中文,與 40032 個常用詞。事實上,依據一般人的了解,中文由單字 詞組成的多字詞可以是無限多的,例如「馬車」(以馬拉的車)、「火車」(以燃燒 作為動力的車)、「電車」(以電為動力的車)、「風車」(以風力所推動裝置)、「水 車」(以水力推動的裝置)……,幾乎可無止境創造出新詞,40032 個常用詞也 無法涵蓋一般人所認為的「詞」的數量。中文的使用者若需要學習與記憶這麼多 「單獨存在」的詞,將是一件無限困難的工作。但經驗告訴我們,即使是第一次 碰到的新詞,我們對它的理解也不是那麼困難。 字彙處接歷程:由字形至字義的認知歷程 由字的閱讀去提取字義的研究稱為字彙觸接(lexical access)的研究。 所謂的字彙觸接,指當閱讀者讀到一個字時,以其所接受到的視覺訊息「觸接」 到個人認知系統中紀錄關於該字的相關知識(字音或字義等)的心理辭典(mental lexicon)的歷程,字彙觸接的研究可以探討字彙知識在人的記憶系統中的儲存 與運作的歷程。閱讀時字彙觸接的認知歷程,就視覺訊息而言,指當閱讀者讀到 一個字時,以其所接受到的視覺訊息「觸接」到認知系統中紀錄關於該字的相關 知識(字音或字義等)的歷程。在字彙觸接的過程中,文字字形訊息與字義觸接 的可能路徑模型有二:單路徑模型(single route model)與雙路徑模型(dual
route model)。在單路徑模型中,字彙觸接是由字形訊息直接觸接到字義訊息;
而在雙路徑模型中,這一個過程有兩個可能的途徑:一為從字形到字義的直接路 徑;另一為從字形到字音再到字義的間接路徑,亦即需要藉由語音訊息作為中介 訊息才能觸接字義。後者又稱為觸接前語音轉錄(prelexical phonological recoding)或是形-音轉換規則(grapheme-to-phoneme conversion, GPC)
(Coltheart, 1978)。以英文為實驗材料的研究,大多發現英文字義的獲得有一 個形音對應規則存在(grapheme-phoneme correspondence rule)。亦即字彙觸 接的歷程需要語音作為中介的途徑(Coltheart, Besner, Jonasson, & Davelaar, 1979;Fleming, 1993;Lesch & Pollatsek, 1993;Perfetti & Bell, 1991; Perfetti, Bell, & Delaney, 1988; Van Orden, 1987;Van Orden, Johnston, & Hale, 1988)。 Taft(1991)整理出四個字彙觸接的主要模型:搜尋(search)模型、字 彙集(logogen)模型、交互激發(interactive-activation)模型與驗證 (verification)模型。在搜尋模型中,當文字的知覺(聽覺或視覺)訊息輸入 時,會依據知覺特徵形成一個字彙庫(bin),例如,所有以「s」開頭的字,接 著閱讀者會將知覺訊息所得到的字母串與字彙庫中所儲存的字做比對,當找到相 符的字之後,便會從儲存字彙知識的認知系統,稱之為主檔案(master file) 中,獲取該字的字義。通常而言,由於學習的效果,越常使用的字在字彙庫中的 排序就越前面。因此,搜尋模型可以明確地說明高字頻的字辨識速度較快的字頻 效果。(Murray 與 Forster,2004)。 字彙集模型中(Morton,1969,1970)則加入了激發的概念。在此模型中, 字彙觸接的歷程為,當閱讀到一個字時,每一字會在認知系統中形成一個視覺輸 入的字彙集(input logogen)。字彙集是一種收集機制,在此機制中依據字彙的 語意與語法以及知覺特徵來形成一個字彙訊息的候選組(set of candidates), 其中含有字彙相關的語義訊息。當閱讀的知覺訊息越來越清楚時,字彙集裡所存 特定訊息的激發程度會越來越高,一旦激發程度超過一個預設的閾限時,該特定 訊息就會被激發出來,也就是觸接到了字義。在字彙集模型中,以認知系統的概 念來替代搜尋模型中的主檔案。這個認知系統會視輸入語義與文法特徵而改變激 發的程度。
交互激發模型,是以 McClelland 與 Rumelhart(1981, 1982)等人的訊息 認知處理觀點為主,此模型可說是更為精細的字彙集模型。交互激發模型更進一 步地指出,當一個字的特徵經由視覺閱讀輸入後,會從字彙知識的記憶系統中激 發該字中所有字母的相關訊息,然後進一步激發相關的文字訊息,並且依據相關 的語義和語法訊息來決定該輸入字彙的字義。交互激發不只促進與刺激字相關的 訊息,亦能夠抑制與刺激字無關或造成妨礙的訊息,因此能夠較為清楚地解釋促 發(priming)實驗的各種促進與抑制的效果。進一步地說,交互激發觸接字義 的過程就是候選組合經由促進與抑制字義的平行激發的機制以挑選的字義訊息。 Becker(1976)的驗證模型也是 logogen 模型的一種修訂,驗證模型認為 在 logogen 模型中所形成的候選組合,會序列式地依據輸入刺激的表徵來做驗 證,以決定正確的字彙訊息究竟是什麼。 中文的字彙觸接研究 根據四個主要的字彙觸接模型來推測中文字的觸接歷程時,以搜尋模型來 看,當閱讀中文時的意義處理單位可以是多字詞時,就需要假設人的記憶系統中 會有一個多字詞的字彙庫與主檔案,人們並不需要去進行任何額外的認知處理來 獲取多字詞的詞義,當閱讀到一個多字詞時,只要在主檔案中就可以找到相對應 的字義。如「腕骨」、「腕」、「骨」三者,各有其獨立的心理詞彙。所謂「手腕部 位的骨頭」詞義的解釋,只存在於該詞彙的解釋,而不存在於個體的認知系統之 中。 以字彙集模型、交互激發模型與驗證模型來看,三者的字彙觸接歷程具有 一個相同的特性,它們均假設觸接一個字的字義(或多字詞的詞義),我們必須 依賴各種相關的訊息,包括語法、語意以及知覺特徵,而知覺與記憶體中的訊息