應用多目標基因演算法改善離散餘弦結合奇異值分解之數位浮水印技術
70
0
0
全文
(2) 應用多目標基因演算法改善離散餘弦結合奇異值分解 之數位浮水印技術 指導教授:賴智錦 博士 國立高雄大學電機工程學系. 研究生:王韋舜 國立高雄大學電機工程學系碩士班. 1 摘要. 伴隨著個人電腦與網際網路的普及,以及數位化的趨勢,如何保護數位多媒 體的智慧財產權是一個重要的問題。數位浮水印技術提供了一個有效的解決方法 以保護數位多媒體的著作權。本論文提出一個結合離散餘弦轉換與奇異值分解之 浮水印技術,並且透過多目標基因演算法對數位浮水印技術進行最佳化。使用者 可以從多目標基因演算法產生的解集合中挑選理想的最佳解,如此可滿足需求不 同的使用者;另外,相較於單目標基因演算法,多目標基因演算法所求得的解集 合穩定性更高。實驗結果證實,我們的方法所產生的浮水印不僅具有高抗攻擊 性,亦具有良好的影像品質,並且較單目標最佳化式浮水印演算法穩定性更高、 應用度更廣。. 關鍵字:數位浮水印、多目標基因演算法、離散餘弦轉換、奇異值分解. i.
(3) Improved DCT-SVD-based Watermarking Through Multi-objective Genetic Algorithm Advisor: Dr. Chih-Chin Lai Department of Electrical Engineering National University of Kaohsiung. Student: Wei-Shun Wang Department of Electrical Engineering National University of Kaohsiung. 2 ABSTRACT. With the trend of digitalization, the popularization of personal computer, and Internet, an important issue should be considered that is how to protect the multimedia files from illegal use. Digital watermarking is an effective solution for protecting the copyright of multimedia files. In this paper, we proposed a DCT-SVD-based watermarking algorithm, and we optimized the algorithm through a multi-objective genetic algorithm (MOGA). The user can choose one optimal solution from the solution set according to the demand of user. Furthermore, the solutions obtained from MOGA are more stable than those from a single-objective genetic algorithm (SGA). Experimental results show that the proposed approach has batter robustness as well as better image quality, and the proposed approach is more stable than SGA.. Keywords: Digital watermarking, Multi-objective genetic algorithm, Discrete cosine transform, Singular value decomposition. ii.
(4) 3 誌謝 本論文能夠順利的完成,首先最要感謝的是我的指導教授賴智錦老師,在撰 寫碩士論文的這段期間,賴老師不厭其煩地給予我論文寫作上的指導,也很有耐 心地包容我的缺失。另外,感謝口試委員吳志宏老師以及李嘉紘老師所提供的寶 貴意見,使得本論文得以更加的完善。 在這兩年的研究所生活中,我學的到不僅僅是學術上的知識,也讓我學會了 許多待人處事之道。感謝賴智錦老師在這兩年中,一直很有耐心且細心的給予教 導,從老師對我與實驗室的關心和付出上,讓我覺得實驗室的成員就如同老師的 小孩一樣,除了研究與課業上的關心之外,老師也非常關心我們的生活狀況,都 會適時的給予支持與鼓勵,如今我既將畢業了,心中充滿著無限的感激。感謝吳 志宏老師,不僅讓我學到做研究的態度,也讓我學會許多研究之外的事。接下來 要感謝的是與我共度兩年研究生涯的奇峰,一起討論課業、分享知識,一起架設 雲端伺服器、一起為會議論文奮戰、一起建立 ViC 實驗室、一起吃飯、玩樂,有 好多好多難忘且快樂的時光,你是我在研究上共同奮鬥的重要夥伴,也是我在生 活中共患難的朋友。感謝老葉學長、彥合學長、河馬學長、銘宏學長和佳霖學長, 在我碩一的時候,你們都相當慷慨地與我分享你們的寶貴經驗,有你們的帶領, 讓我很快的就能夠適應研究生的生活。感謝宜陞和俐雯,我們一起修課、討論作 業,在課業上或是生活上也都會互相扶持、幫忙。感謝小葉、信慈和懿萱,在我 碩二的時候,實驗室因為有你們的支援,我才能夠專心的致力於研究上。感謝小 林、ViC 實驗室、ICA 實驗室以及陪我度過研究生活的各位,這一路上有你們的 陪伴,讓我的研究生活增添了許多色彩。 最後,感謝我最敬愛的父母。在我的求學過程中,不管是在精神上還是實質 上,有您們的支持與包容,使得我能夠無後顧之憂的專心於學習上,謝謝您們 24 年來不辭辛勞地栽培,希望我能成為您們的驕傲。 iii.
(5) 4 目錄 摘要................................................................................................................................. i ABSTRACT ...................................................................................................................ii 誌謝...............................................................................................................................iii 目錄............................................................................................................................... iv 圖目錄........................................................................................................................... vi 表目錄..........................................................................................................................vii 第一章 導論.................................................................................................................. 1 第二章 背景回顧.......................................................................................................... 4 2.1 離散餘弦轉換................................................................................................. 4 2.2 奇異值分解..................................................................................................... 8 2.3 單目標基因演算法....................................................................................... 10 2.3.1 染色體編碼........................................................................................ 11 2.3.2 選擇機制............................................................................................ 11 2.3.3 交配與突變........................................................................................ 13 2.3.4 終止條件............................................................................................ 15 2.4 多目標最佳化演算法................................................................................... 15 2.4.1 多目標最佳化問題............................................................................ 15 2.4.2 多目標最佳化概念............................................................................ 16 2.5 非支配排序基因演算法................................................................................ 18 2.5.1 快速非支配排序法............................................................................ 19 2.5.2 擁擠距離............................................................................................ 20 2.5.3 擁擠競爭選擇法................................................................................ 21 第三章 多目標數位浮水印系統................................................................................ 23 3.1 浮水印嵌入程序........................................................................................... 23 3.2 浮水印擷取程序........................................................................................... 25 3.3 多目標基因演算法配置............................................................................... 26 3.3.1 染色體編碼方式................................................................................ 27 3.3.2 適應函數............................................................................................ 27 3.3.3 交配與突變........................................................................................ 29 第四章 實驗結果........................................................................................................ 31 4.1 實驗環境....................................................................................................... 31 4.2 多目標與單目標的實驗數據....................................................................... 34 4.2.1 本論文所提出的方法(多目標)之實驗數據 ..................................... 34 4.2.2 單目標基因演算法之實驗數據........................................................ 41 iv.
(6) 4.2.3 多目標與單目標的實驗結果比較.................................................... 47 4.3 其他多目標基因演算法之實驗結果........................................................... 47 第五章 結論................................................................................................................ 57 參考文獻...................................................................................................................... 59. v.
(7) 5 圖目錄 圖 2.1:灰階影像之DCT轉換示意圖...................................................................... 5 圖 2.2:Zig-zag掃描法 ............................................................................................. 5 圖 2.3:DCT之DC、AC18、AC63 之頻域段示意圖 ............................................ 6 圖 2.4:DCT高、中、低頻域區分.......................................................................... 6 圖 2.5:影像經不同壓縮比的JPEG壓縮後,所產生的失真差異 ........................ 7 圖 2.6:JPEG壓縮所造成的區塊效應 .................................................................... 7 圖 2.7:基因演算法的簡易流程圖........................................................................ 11 圖 2.8:依據染色體被挑選的機率所繪製的圓餅圖............................................ 12 圖 2.9:二元編碼單點交配.................................................................................... 13 圖 2.10:二元編碼雙點交配.................................................................................. 14 圖 2.11:二元編碼均勻交配 .................................................................................. 14 圖 2.12:二元編碼突變.......................................................................................... 14 圖 2.13:決策空間與目標空間之對應圖[49] ....................................................... 16 圖 2.14:多目標問題中的五個解.......................................................................... 17 圖 2.15:非之配解集合所構成的非支配前緣示意圖.......................................... 18 圖 2.16:NSGA-II之簡易流程圖[49] .................................................................... 19 圖 2.17:擁擠競爭選擇法-狀況(a) ........................................................................ 22 圖 2.18:擁擠競爭選擇法-狀況(b)........................................................................ 22 圖 3.1:將 64×256 矩陣重新塑形為 128×128 矩陣 ............................................. 24 圖 4.1:實驗測試影像............................................................................................ 31 圖 4.2:四種不同演化代數的所得到的實驗結果................................................ 34 圖 4.3:以表 4.1 之三個解進行浮水印嵌入所得到的影像................................. 36 圖 4.4:SOGA_1、2、3 三個解進行浮水印嵌入所得到的影像 ........................ 43 圖 4.5:NSGA-II與SGA的最佳解之比較 ............................................................. 47 圖 4.6:M&S[37]提出的方法,實驗中取三次實驗的柏拉圖最佳解 ................ 49 圖 4.7:隨機挑選三解之嵌入浮水印後之影像,(a)為解一,(b)為解二,(c) 為解三.............................................................................................................. 51. vi.
(8) 6 表目錄 表 2.1:DCT各頻域段與浮水印不可視性和強韌性的特性關係.......................... 8 表 2.2:非支配前緣層級 1 各解的目標函數值、擁擠距離及排序.................... 21 表 4.1:本論文所提出的方法之實驗數據............................................................ 35 表 4.2:Ours _1、2、3 之浮水印強韌度測試 ...................................................... 36 表 4.3:以不同分布索引進行實驗之結果............................................................ 40 表 4.4:SOGA重複進行 10 次測試之實驗數據 ................................................... 41 表 4.5:SOGA之 3 次實驗的數據 ......................................................................... 42 表 4.6:SGA_1、2、3 之浮水印強韌度測試....................................................... 43 表 4.7:M&S[37]的方法之解一的數據 ................................................................ 49 表 4.8:M&S[37]的方法之解二的數據 ................................................................ 50 表 4.9:M&S[37]的方法之解三的數據 ................................................................ 51 表 4.10:三張嵌入浮水印的影像分別受各種攻擊後,擷取出來的浮水印及其 品質.................................................................................................................. 52 表 4.11:本論文與M&S[37]之數據比較 .............................................................. 55 表 4.12:三組實驗之平均執行時間比較表.......................................................... 56. vii.
(9) 1 第一章 導論 近幾年來,隨著科技的發達,電腦與網際網路的技術越趨成熟,很多東西都 隨之數位化,並以電腦進行管理。網際網路的技術使這些數位化後的檔案,可以 很快的流傳於全世界,也因為這個方便性,促使這些檔案可能會遭到一些不肖人 士非法竄改盜用。所以,如何保護數位檔案的著作權,儼然已成為一個重要的議 題。有學者提出了數位浮水印(digital watermarking)的技術,此技術可以有效的解 決這個問題。 一個簡單的數位浮水印技術,以影像為例,必須包含一張藏匿影像(cover image)以及一個浮水印(watermark),浮水印是一個具象徵性的資訊;數位浮水印 技術的架構有兩個主要的程序: 1. 嵌入程序:將浮水印嵌入至數位檔案中。 2. 擷取程序:從數位檔案中擷取先前嵌入的浮水印。 數位浮水印的目的是將可以代表原作者的一些資訊或是圖樣,這些具象徵性的資 訊稱之為浮水印,透過嵌入程序將浮水印嵌入到數位檔案。被嵌入的浮水印必須 能夠抵抗有意或無意的竄改,這些竄改的動作我們稱之為「攻擊」。受攻擊後的 數位檔案,必須能夠經由擷取程序,將先前嵌入的浮水印擷取出來,以證明該數 位檔案的擁有者。數位浮水印技術有兩個重要的特性必須考慮: 1. 不可視性(imperceptibility):ㄧ個被嵌入浮水印的數位檔案,在視覺或聽覺 上,要盡可能的保有原本的品質。 2. 強韌性(robustness):當數位檔案受到一些攻擊後,還是能夠從中擷取出浮 水印,且是個可以辨識的浮水印。 數位浮水印的技術,其嵌入方法從嵌入區域的觀點來看,大致可分為兩種: 一種是空間域(spatial domain)[1-5],另一種是轉換域(transformation domain)。空 間域的數位浮水印技術是透過修改影像的顏色,進而將浮水印嵌入。空間域的嵌 1.
(10) 入法最早是在 1994 年,由 Schyndel 等人[1]所提出的數位浮水印技術,使用 least significant bit (LSB)演算法修改像素顏色值的最不重要的位元,進行浮水印嵌入 動作。該法優點是作法簡單,而且嵌入浮水印後的影像品質仍能保有一定的水 準,即不可視性很高;但是浮水印的強韌性卻非常的弱,無法抵抗攻擊。在轉換 域 的 嵌 入 方 法 中 , 比 較 常 見 的 有 離 散 餘 弦 轉 換 (discrete cosine transform, DCT)[6-10]、離散傅立葉轉換(discrete Fourier transform, DFT)[11]、離散小波轉換 (discrete wavelet transform, DWT)[12-13] 、 與 奇 異 值 分 解 (singular value decomposition, SVD)[14-22]。DCT、DFT 或 DWT 都是頻率域的轉換,主要是將 影像的顏色透過轉換公式,從空間域轉換為頻率域,接著透過修改轉換後得到的 頻率值進行嵌入的動作,再透過反轉換公式,將修改過後的頻域值轉換回空間域 的顏色值。SVD 嵌入法是透過矩陣分解公式,將藏匿影像分解成為三個二維矩 陣,分別是 U 矩陣、S 矩陣以及 V 矩陣,接著透過修改這三個矩陣進行浮水印嵌 入的動作。近幾年來,有許多學者提出結合兩種轉換法的嵌入方法,因為每一種 轉換域都有各自的優缺點,結合的目的就是為了能夠截長補短;其中,DCT 結 合 SVD 的文獻有[23-25],DWT 結合 SVD 的文獻有[26-28]。轉換域的嵌入方法 其優點為浮水印的強韌性夠強,比較能抵抗攻擊,但其不可視性就比空間域差。 所以,如何在不可視性與強韌性之間取捨,是一個重要的難題所在。 近幾年已有許多學者運用人工智慧來解決不可視性與強韌性取捨的問題,這 問題可視為一種最佳化的問題。在人工智慧領域中,使用較為廣泛的求取最佳解 的演算法有基因演算法(genetic algorithm, GA)[29-33]、粒子群最佳化演算法 (particle swarm optimization, PSO)[34-36]。在 2001 年,Wang 等人[30]提出使用基 因演算法求解 LSB 嵌入法的最佳化。於 2004 年,Shieh 等人[31]則是使用基因演 算法尋求 DCT 嵌入法的嵌入位置。由於數位浮水印必須注重不可視性與強韌 性,故浮水印的最佳化問題可視為一個多目標最佳化問題。但早期所提出的方法 都是使用單目標最佳化演算法,單目標最佳化演算法有一個致命的缺點在於:當 面對多目標問題時,必須將多目標以權重的分配合併成為單一適應函數;如此, 2.
(11) 最佳化的結果很容易受到權重的不同而產生大幅度的變動。所以有學者提出使用 多目標最佳化演算法解決數位浮水印最佳化的問題[37-42],其中比較廣為使用的 多目標最佳化演算法是非支配排序基因演算法(non-dominated sorting genetic algorithm-II, NSGA-II)[43]。故本論文提出結合 DCT、SVD 兩種轉換域的數位浮 水印嵌入技術,並利用 NSGA-II 來解決數位浮水印的最佳化問題。 本論文由五個章節所構成,第一章介紹研究背景、研究動機與目的。第二章 介紹本論文使用到的轉換技術與多目標基因演算法。第三章詳細說明本論文所提 出的方法。第四章為實驗數據。第五章將總結本論文,以及討論未來可以改進或 研究的方向。. 3.
(12) 2 第二章 背景回顧 本論文所提出的多目標數位浮水印系統中所使用到技術有離散餘弦轉換、奇 異值分解、與非支配排序基因演算法-II,在本章將逐項介紹。. 2.1 離散餘弦轉換 訊號處理和影像處理常常使用離散餘弦轉換將訊號或影像(靜態圖片和動態 影片)從空間域轉換到頻率域,轉換後的資料可以再進一步的運用,例如:進行 資料的壓縮。在影像處理領域上,已經有數個資料壓縮的演算法都是基於二維離 散餘弦轉換衍生而來的,例如:JPEG 和 MPEG,前者用於靜態影像的壓縮,後 者用於動態影像音訊的壓縮,兩者都是現今多媒體壓縮的標準。 在影像進行離散餘弦轉換前,會先進行直流準位位移(DC level shifting),其 目的是方便後續的處理。直流準位位移是將影像中每一個像素(pixel)減去一個數 值,該數值的大小是根據像素的位元深度 p(bit depth)來決定,其值為 2 p −1 。以灰 階影像為例,其位元深度 p 為 8,影像的每個像素數值介於 0~255 之間,故影像 進行直流準位位移時,每個像素值將減去 128。 影像經過直流準位位移處理後,再進行離散餘弦轉換。離散餘弦轉換及離散 餘弦反轉換的公式分別如(2-1)式及(2-2)式所示: N −1 N −1 (2 x + 1)iπ (2 y + 1) jπ DCT (i, j ) = C (i ) × C ( j ) × ∑∑ I ( x, y ) × cos cos 2N 2N x =0 y =0 N −1 N −1 (2 x + 1)iπ (2 y + 1) jπ cos I ( x, y ) = ∑∑ C (i ) × C ( j ) × DCT (i, j ) × cos 2N 2N i =0 j =0. 其中 C (i ), C ( j ) = . 1 N 2 N. for i, j = 0 for i, j = 1, 2, …, N-1. 其中 I ( x, y ) 為某影像 I 的第 x 列,第 y 行的像素灰階值。. 4. (2-1) (2-2).
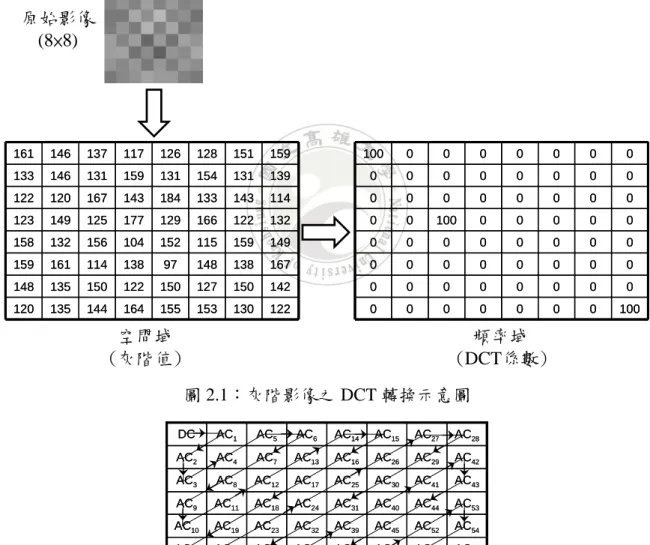
(13) 一個影像經過離散餘弦轉換後,會得到該影像各個頻域段的DCT係數,而該 影像就是由這些頻域段所組合而成的。以一個 8×8 的灰階影像(如圖 2.1,以下稱 為I圖)為例子,I圖經離散餘弦轉換後,可得到 64 個頻域段的DCT係數,這些頻 域段的係數以Zig-zag的掃描方式(如圖 2.2),依序將這些頻域段稱為DC、AC 1 、 AC 2 、…、AC 62 、AC 63 ,故I圖主要是由DC、AC 18 和AC 63 所組合而成,分別將 這三個頻域段作反離散餘弦轉換的運算,既可得到這三個頻域段其空間域的示意 圖(如圖 2.3,以下分別稱為B圖、C圖、D圖),而I圖即為B、C、D圖所組成。. 原始影像 (8×8). 161. 146. 137. 117. 126. 128. 151. 159. 100. 0. 0. 0. 0. 0. 0. 0. 133. 146. 131. 159. 131. 154. 131. 139. 0. 0. 0. 0. 0. 0. 0. 0. 122. 120. 167. 143. 184. 133. 143. 114. 0. 0. 0. 0. 0. 0. 0. 0. 123. 149. 125. 177. 129. 166. 122. 132. 0. 0. 100. 0. 0. 0. 0. 0. 158. 132. 156. 104. 152. 115. 159. 149. 0. 0. 0. 0. 0. 0. 0. 0. 159. 161. 114. 138. 97. 148. 138. 167. 0. 0. 0. 0. 0. 0. 0. 0. 148. 135. 150. 122. 150. 127. 150. 142. 0. 0. 0. 0. 0. 0. 0. 0. 120. 135. 144. 164. 155. 153. 130. 122. 0. 0. 0. 0. 0. 0. 0. 100. 空間域 (灰階值). 頻率域 (DCT係數) 圖 2.1:灰階影像之 DCT 轉換示意圖. DC. AC1. AC5. AC6. AC14. AC15. AC27. AC28. AC2. AC4. AC7. AC13. AC16. AC26. AC29. AC42. AC3. AC8. AC12. AC17. AC25. AC30. AC41. AC43. AC9. AC11. AC18. AC24. AC31. AC40. AC44. AC53. AC10. AC19. AC23. AC32. AC39. AC45. AC52. AC54. AC20. AC22. AC33. AC38. AC46. AC51. AC55. AC60. AC21. AC34. AC37. AC47. AC50. AC56. AC59. AC61. AC35. AC36. AC48. AC49. AC57. AC58. AC62. AC63. 圖 2.2:Zig-zag 掃描法. 5.
(14) DC. AC18. AC63. 圖 2.3:DCT 之 DC、AC18、AC63 之頻域段示意圖 一個 8×8 的灰階影像經離散餘弦轉換運算後,得到的 64 個 DCT 係數可以粗 略的將它們區分為低頻係數、中頻係數以及高頻係數(如圖 2.4)。. 圖 2.4:DCT 高、中、低頻域區分 人眼對於非平滑區塊的變化(灰階值變異度較高的區塊)的敏感度較小,亦即若改 變高頻 DCT 係數的值時,人眼比較不易觀察出其空間域的變化;反之,人眼對 於平滑區塊的變化相對的敏銳,故若改變低頻 DCT 係數時,其空間域的變化較 易被人眼察覺。許多以 DCT 為基礎的影像壓縮技術,就是利用人眼對於非平滑 區塊的敏感度較小的關係,將區塊中的高頻資訊予以捨棄,進而達到資料壓縮的 目的,並仍保有一定的影像品質。以 JPEG 壓縮為例子,圖 2.5 中分別為未經壓 縮的影像以及分別經過不同壓縮品質壓縮過後的影像,由於在影像中的邊緣、毛 髮等非平滑區塊其中、高頻係數的能量相對的高,所以當壓縮品質越來越低的時 候,在量化 DCT 係數時會捨棄掉大量的中高頻資訊,故在這些非平滑區塊會產 生嚴重的失真。當壓縮品質越來越低時,在量化的過程中不僅中、高頻的資訊會 6.
(15) 被捨棄掉,甚至連部分低頻的資訊也會被捨棄。由量化 DCT 係數而造成區塊邊 界的失真稱之為區塊效應,圖 2.6 為原始影像經過壓縮品質 10%的 JPEG 壓縮後 的影像,可清楚地看見所謂的區塊效應。. (a) 未經壓縮. (b) 壓縮品質 90%. (c) 壓縮品質 80% (d) 壓縮品質 50% 圖 2.5:影像經不同壓縮比的 JPEG 壓縮後,所產生的失真差異. 圖 2.6:JPEG 壓縮所造成的區塊效應 在 1997 年 Cox 等人[6]是第一個提出結合離散餘弦轉換的數位浮水印演算 法,他們的方法是將一張 M × M 的遮蔽影像(cover image)進行 M × M 的離散餘弦. 7.
(16) 轉換後,接著將長度為 l 的浮水印藏在 DCT 係數值最大的前 l 個係數位置上。除 了 DC 值不考慮之外,藏匿的位置主要是考慮到,這些數值較大的 DCT 係數代 表著整張影像的重要資訊。所以,在影像經過一些影像處理或是影像壓縮的動作 之後,這些 DCT 係數比較不易被捨棄掉,其實驗結果也證明了他們提出的方法 具有不錯的強韌性。 繼 Cox 等人提出的方法後,陸續有人提出了結合區塊式離散餘弦轉換 (block-based DCT)的數位浮水印演算法。1999 年 Hsu 和 Wu[7]提出的方法中,其 嵌入步驟是先對遮蔽影像進行切割,每一個切割區塊的大小為 8×8。接著對每個 區塊分別進行離散餘弦轉換,再分別對每個區塊進行 Zig-zag 掃描排序,接著根 據 JPEG 量化表(JPEG quantization table)在每個區塊中挑選出 16 個相對應的中頻 DCT 係數,並將它們排列成一個 4×4 的二維矩陣,再逐步對每個區塊進行浮水 印的嵌入動作。實驗結果證明了他們所提出的方法對於 JPEG 壓縮攻擊有著良好 的強韌性,但無法有效抵抗影像旋轉(image rotation)和影像重新取樣(image resample)的攻擊。在他們的論文中提到,人眼對於低頻的變化較高頻的變化來的 敏感;但高頻的資訊比低頻的資訊更容易於量化過程中被捨棄[7]。所以將浮水 印嵌在中頻區段,是為了取得這兩者之間的平衡。DCT 頻域段與浮水印的不可 視性和強韌性之間的關係可以表 2.1 描述之。 表 2.1:DCT 各頻域段與浮水印不可視性和強韌性的特性關係 頻域段. 低頻. 中頻. 高頻. 不可視性. 差. 中等. 優. 強韌性. 優. 中等. 差. 2.2 奇異值分解 在線性代數中,依據使用目的的不同,矩陣的分解可以分為奇異值分解法 (singular value decomposition, SVD)、三角分解法(triangular factorization)、及 QR. 8.
(17) 分解法(QR factorization)等三種。在前人的文獻中,奇異值分解法較被廣為使用, 且有效地應用於數位浮水印上[14-22]。奇異值分解,是一種正交矩陣分解法,主 要的目的是用來解決最小平方誤差(least-square)的問題[46],另外 SVD 也應用於 資料壓縮[47]、消除雜訊[48]。 奇異值分解基本上是一種基底變換的演算法。此法可將一個 n × n 的矩陣A分 解 成 兩 個 正 交 矩 陣 (orthogonal matrix) U、V , 以 及 一 個 對 角 矩 陣 (diagonal matrix)S,其中 U、S、V矩陣大小皆為 n × n 。奇異值分解的公式如(2-3)式所示。 σ 1 σ2 [v1 , v2 ,, vn ]T A = U ⋅ S ⋅ V T = [u1 , u2 ,, un ] σ n−1 σ n . (2-3). 其中 ui 和 vi 分別為 U 和 V 的行向量(column vector),S矩陣為一個對角矩陣,位於 對 角 線 上 的 數 值 σi 稱 為 奇 異 值 , σi 會 滿 足 下 列 條 件 :. σ 1 ≥ σ 2 ≥ ≥ σ r = σ r +1 = = σ n = 0 ,其中 r為 A矩陣的秩(rank)。就影像的觀點 而言, U、V 矩陣代表著影像的幾何特性,而 S矩陣代表著影像的亮度資訊。 近幾年來有學者提出以 SVD 為基礎的數位浮水印技術。在 2001 年 Gorodetski 等人[22]提出結合 SVD 的數位浮水印技術,他們提出的方法是將一張彩色影像 (RGB color)分別對 Red、Green、Blue 矩陣切割成多個大小為 k × k 且不重疊的區 塊,接著分別對每個區塊進行奇異值分解。最後根據每個區塊中最大的奇異值. σ 1 (奇數或偶數)以及要嵌入的二元資料(1 或 0),進而修改 σ 1 的值進行藏匿的行 為。 在 2002 年Chandra提出[15]了兩種結合SVD的數位浮水印嵌入方法,一種是 全域式SVD,另一種是區塊式SVD。在全域式SVD中,是將大小為 n × n 的原始 影像 X和大小為 m × m 浮水印 W進行全域式奇異值分解(假設 n ≥ m ),可以得到 X 與 W的對角矩陣,分別以 S X = [σ X 1 ,σ X 2 ,,σ Xn ] 與 SW = [σ W 1 ,σ W 2 ,,σ Wm ]表示,以 9.
(18) 及兩組正交矩陣 U X 、 VX 和 UW 、 VW ,接著根據(2-4)式對 S X 進行修改,. σ Yi = σ Xi + α i ⋅ σ Wi. (2-4). 其中 i = 1, 2, , m ,經修改過後的 S X 以 SY 表示之,接著將運算後得到的 SY 與. U X 、 VX 進行反奇異值分解運算,得到藏匿浮水印之後的影像 Y。 第二種方法是以區塊式SVD為考慮重點。先將大小為 n × n 的原始影像 X切割 成大小為 k × k 且不重疊區塊 X B ,接著對每個區塊進行奇異值分解的運算,會得 到每個區塊的對角矩陣 S B = [σ 1B , σ 2B , , σ kB ] ,浮水印 W在嵌入之前先進行打亂 的動作,打亂後的浮水印以 W ′ 表示之,接著根據(2-5)式對每個區塊中的最大. σ 1′ B = σ 1B + α ⋅ W B. (2-5). 的奇異值 σ 1B 進行修改,接著再以修改過後的 S B 矩陣進行反奇異值分解運算,得 到藏匿後的影像 Y。. 2.3 單目標基因演算法 在 1975 年 John H. Holland 受達爾文的進化論「物競天擇,適者生存」所啟 發,提出了基因演算法(genetic algorithm)[29],是一種用於求取最佳化解答的搜 尋演算法。其仿效大自然中物種的演化方式進行尋優,透過選擇(selection)、交 配(crossover)、與突變(mutation)等三個演化機制進行演化,隨著世代的演進,最 後會決定出一個最好的解答。 基 因 演 算 法 的 基 本 流 程 如 圖 2.7 所 示 。 一 開 始 會 隨 機 產 生 一 個 族 群 (population),族群中有數條染色體(chromosome),每一條染色體代表著一個問題 的「可能解答」, 染 色體是 由一串基因(gene)所組成 。透過適應函數(fitness function),可計算每條染色體的適應值(fitness value),適應值代表著每條染色體 在所處的環境(要解決的問題)中,它們各自適應程度的好壞,適應程度不好的染 10.
(19) 色體在後續的演化過程中,有比較大的機率會被淘汰掉;相對的,適應程度較好 的染色體,其優良的基因有比較大的機率會遺傳至下一個世代。利用選擇運算元 從族群中挑選一定數量的染色體至交配池(mating pool)中,交配池中的染色體經 過交配和突變的運算產生子代(offspring)染色體。持續計算各染色體的適應值、 配合選擇、交配和突變等運算,直到停止條件達成,最後會決定出一條適應值最 好的染色體,即所謂的最佳解。. 開始. 隨機產 生族群. 計算適 應程度. 終止條件達成. 否. 挑選. 交配與 突變. 是 結束. 圖 2.7:基因演算法的簡易流程圖 以下我們將逐步介紹染色體的編碼,選擇、交配與突變等機制,以及終止條件的 訂定。. 2.3.1 染色體編碼 根據要解決的問題的不同,染色體的編碼方式可分為下列四種: 1. 二元編碼(binary-coded):染色體中所有的基因皆由 0 或 1 所組成。 2. 實數編碼(real-coded):染色體中所有的基因可為整數或是實數。 3. 排列編碼(permutation-coded):染色體中所有的基因為一組有序列關係的數字 所構成。 4. 樹狀編碼(tree-coded):染色體是由一個樹狀結構所組成。. 2.3.2 選擇機制 在進行交配與突變之前,必須從現有的族群中挑選出要進行演化的染色體。 11.
(20) 這些被挑選出來的染色體會被複製到交配池中成為父代染色體,適應值越高的染 色體,被挑選到的機率越高。挑選的機制有很多種,比較常見的方法是輪盤選擇 法(roulette wheel selection)與競爭選擇法(tournament selection)。 (a) 輪盤選擇法: 依據族群中每條染色體適應值的優劣來決定其被挑選到的機率大小。假 設族群大小為n,且C i 染色體的適應值為f(C i ),則可由(2-6)式計算出每條染 色體被挑選到的機率P(C i )。 P (C i ) =. f (C i ). (2-6). n. ∑ f (C ) i =1. i. 舉例說明,假設族群大小為 5,染色體編號分別為C 1 、C 2 、C 3 、C 4 、 C 5,其適應值依序為 9、7、4、12、21,假設適應值越高越好,接著可由(2-6) 式算得C 1 被挑選到的機率為 P(C1 ) =. 9 9 = ≅ 17%,同理可得 9 + 7 + 4 + 12 + 21 53. C 2 、C 3 、C 4 、C 5 被挑選到的機率分別為 13%、8%、23%、39%。由上述所 算得的機率,可繪製出一個像輪盤的圓餅圖(如圖 2.8 所示)。再根據每條染 色體被挑選到的機率,隨機從中挑選出要被複製到交配池中的染色體。. 圖 2.8:依據染色體被挑選的機率所繪製的圓餅圖 (b) 競爭選擇法: 隨機從族群中選出 k 條染色體,其中 k ≥ 2 。在從這 k 條染色體中,將. 12.
(21) 適應值最好的染色體複製到交配池中。. 2.3.3 交配與突變 基因演算法經由父代的交配與突變產生新的子代,其中交配是透過兩條父代 染色體交換彼此的基因內容產生兩條新的子代染色體;突變則是藉由突變一條父 代染色體的某些基因,產生一條新的子代染色體。 常見的交配機制有下列三種: (a) 單點交配法(one-point crossover) 隨機選取一個交配點,以這個交配點為中心將兩條父代染色體的基因分 割成兩部份。將兩條父代染色體被切開的基因進行互換後,產生兩條新的子 代染色體(如圖 2.9 所示)。 交配點 Parent 1: 互換 Parent 2: 進行交配 Child 1: Child 2:. 圖 2.9:二元編碼單點交配 (b) 雙點交配法(two-point crossover) 隨機選取兩個交配點,接著將位於兩交配點中的父代染色體基因進行互 換,進而產生兩條新的子代染色體。. 13.
(22) 交配點. 交配點 Parent 1:. 互換 Parent 2: 進行交配 Child 1: Child 2:. 圖 2.10:二元編碼雙點交配 (c) 均勻交配法(uniform crossover) 以隨機的方式產生一組由 0 與 1 組成的遮罩(mask),並且其長度與染色 體長度相同。根據遮罩上的內容決定兩條父代染色體相對應的基因是否要進 行交換。如果遮罩內容是 1,則進行交換;否則不進行交換。 Parent 1: Parent 2: Mask:. 0. 1. 1. 0. 1. 0. 1. 1. 進行交配 Child 1: Child 2:. 圖 2.11:二元編碼均勻交配 突變程序會依突變機率決定該基因是否要進行突變,以二元編碼為例,其突 變方法是字元反轉,也就是從 1 變 0,或從 0 變 1。 Parent : 0. 1. 1. 0. 1. 0. 1. 1. 1. 1. 進行突變 Child : 0. 1. 0. 0. 1. 0. 圖 2.12:二元編碼突變. 14.
(23) 2.3.4 終止條件 終止基因演算法的情況有下列三種: 1. 當迭代次數已達到指定的次數。 2. 當有染色體的適應值達到所要求的值。 3. 多次的迭代過程中,未能得到適應值更好的染色體。. 2.4 多目標最佳化演算法 現實生活中很多設計或決策的問題需考慮多個以上的需求,像是數位浮水印 必須考慮的需求就有不可見性與強韌性,而單目標基因演算法無法完全兼顧到各 個需求的多樣性。. 2.4.1 多目標最佳化問題 一個多目標最佳化問題(multi-objective optimization problem, MOOP),即是將 數個目標函數(objective function)最大化或最小化。可以下式來概述一個多目標最 佳化問題[49]: Min/Max subject to. f m (x ), g v (x ) ≥ 0, hw (x ) = 0,. v = 1,2, , V. xi( L ) ≤ xi ≤ xi(U ) ,. i = 1,2, , n. m = 1,2, , M w = 1,2, , W. (2-7). 其中 x 為一決策變數向量: x = ( x1 , x 2 , , x n ) ,向量中的每個元素稱之為決策變 T. 數(decision variable),每個決策變數皆有自己的上界(upper bound) xi(U ) 和下界 (lower bound) xi( L ),由 xi(U ) 和 xi( L ) 界定的空間稱之為決策空間(decision space)。g v (x ) 和 hw (x ) 為限制函數(constraint function),用來界定決策變數的可行解區域。若有 一解 x (1) 滿足上下界限,且滿足限制函數,則解 x (1) 稱為可行解(feasible solution); 15.
(24) 否則稱之為不可行解(infeasible solution)。 f m (x ) 為目標函數,M 個目標函數構成 一 個 多 維 的 空 間 , 將 之 稱 為 目 標 空 間 (objective space) , 目 標 空 間 的 點 以 z = ( f1 (x), f 2 (x), , f M (x) ) 表示之。決策空間中的每一個解 x,在目標空間中會 T. 存在一點 z 與其相對應。圖 2.13 為決策空間與目標空間的對應示意圖。 x3. 目標空間. 決策空間 f2. z. x1 x. f1. x2. 圖 2.13:決策空間與目標空間之對應圖[49]. 2.4.2 多目標最佳化概念 Deb[49]訂定了一個理想的多目標最佳化程序。透過多目標最佳化演算法求 取一組具多樣性的最佳解集合,使用者再依各自的需求從解集合中挑選一個最佳 解。 許多多目標最佳化演算法中,都運用「支配」(domination)這個概念評估解 答的好或壞。假設在一最佳化問題中,有 M 個目標函數,若解 i 在某特定目標函 數中優於解 j,則以 i j 表示之;反之,以 i j 表示之。支配的定義如下: 若一解 x (1) 支配另一解 x ( 2 ) ,則必須滿足下列兩個條件: 1. 解 x (1) 在所有的目標函數中都不比解 x ( 2 ) 差。. ( ). ( ). f j x (1) / f j x (2 ) ,對所有 j = 1,2, , M 2. 解 x (1) 至少在一個目標函數中優於解 x ( 2 ) 。. ( ). ( ). f j x (1) f j x (2 ) 至少有一個 j ∈ {1,2, , M } 16.
(25) 當兩解無法滿足支配條件時,我們稱之為非支配解(non-dominated solution)。假 設有一多目標最佳化問題,其目標函數有兩個,且在目標空間中有五個不同的 解,如圖 2.14 所示。以解 2 和解 3 為例,解 2 在所有的目標函數中皆優於解 3, 滿足上述的支配條件,故解 2 支配解 3;以解 2 和解 5 為例,解 2 的f 1 目標函數 優於解 5,且解 5 的f 2 目標函數不比解 5 差,因此滿足支配條件,故解 2 支配解 5。. f2(minimize). f1(minimize) 圖 2.14:多目標問題中的五個解. 支配的概念可以應用於比較解答之間的好壞,所以很多運用支配概念的多目 標最佳化演算法,其目的就是要找出非支配解。由非支配解所組成的解集合 (non-dominated set)在視覺上會構成一個非支配前緣(non-dominated front),非支配 前緣有層級(rank)之分。層級 1(rank 1 )上的非支配解優於層級 2(rank 2 )上的非支配 解,層級 2(rank 2 )上的非支配解優於層級 3(rank 3 )上的非支配解,以此類推;層 級 1 的非支配解集合又稱為柏拉圖最佳集合(pareto-optimal set),柏拉圖最佳集合 中的解又稱為柏拉圖最佳解(pareto-optimal solution)。以圖 2.15 為例,六個解經 過非支配排序後,可得到三個非支配前緣,其中解 2、4、5、7 所構成的是非支 配前緣層級 1,解 1、3 所構成的是非支配前緣層級 2,解 6 所構成的是非支配前 緣層級 3。. 17.
(26) f2(minimize). f1(minimize) 圖 2.15:非之配解集合所構成的非支配前緣示意圖. 2.5 非支配排序基因演算法 非支配排序基因演算法(non-dominated sorting genetic algorithm-II, NSGA-II) [43]是由 Deb 所提出的一種多目標基因演算法,其主要的演化過程與單目標基因 演算法一樣,通過挑選、交配、突變等三個主要機制產生子代。接著將父代與子 代合併成一個大族群,再透過快速非支配排序法(fast non-dominated sort)和擁擠 距離法(crowding distance)決定下一個世代的父代族群,其簡易的流程如圖 2.16 所示。 NSGA-II 有三個主要的優點: 1. 使用精英(elitist)策略,確保族群的優越性。 2. 使用擁擠距離法,確保族群的多樣性(diversity)。 3. 使用快速的非支配排序法,減少運算複雜度。. 18.
(27) Non-dominated sort. Crowding distance sorting. rank1 rank2. Parentt. Parentt+1. rank3. Offspringt Rejected Totalt 圖 2.16:NSGA-II 之簡易流程圖[49]. 2.5.1 快速非支配排序法 在 NSGA-II 中,使用快速非支配排序法將一組解排序後,可得到解與解之 間的支配關係,進而用來評估各個解的適應程度。快速非支配排序演算法如下: fast non-dominated sort: For each p ∈ P Sp = Ø np = 0 for each q ∈ P if (p q) then S p = S p ∪{q} else if (q p) then np = np + 1 if n p =0 then p rank = 1 F 1 = F 1 ∪{p} i=1 while F i ≠Ø Q=Ø for each p ∈ F i for each q ∈ S p nq = nq + 1 if n q = 0 then q rank = i + 1. If p dominates q Add to the set of solutions dominated by p Increment the domination counter of p p belongs to the first front. Initialize the front counter Used to store the members of the next front. q belongs to the next front. 19.
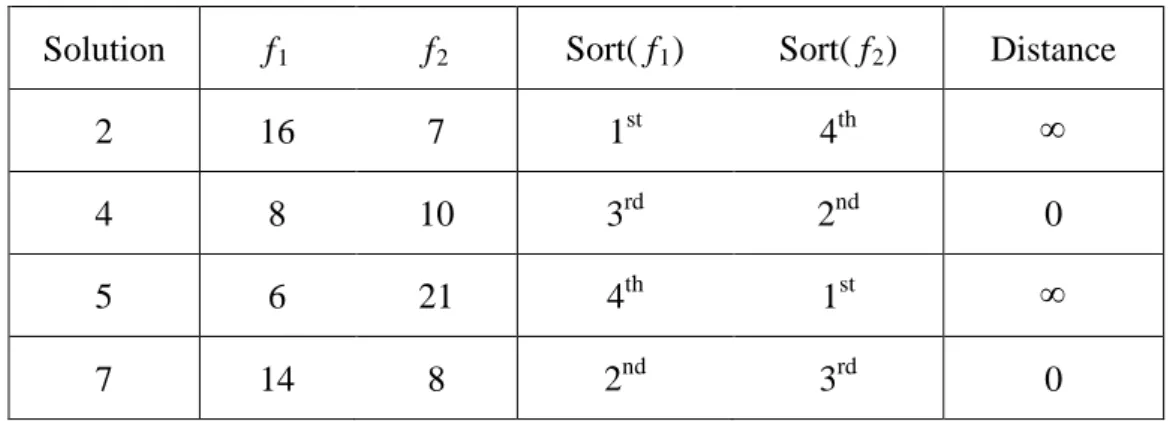
(28) Q=Q∪{q} i=i+1 Fi = Q 其中P表示族群,S p 表示被解 p所支配的解集合,n p 表示可以支配解 p的解答的個 數,F i 表示非支配前緣rank i 的解集合,p rank 表示解 p所處的非支配前緣層級數。. 2.5.2 擁擠距離 當一組解經過非支配排序後,可對各個非支配前緣上的每個解,分別算出它 們各自的擁擠距離,這個數值代表該解在該非支配前緣中多樣性的程度。該數值 越大,代表該解的多樣性越高,即該解在所處的非支配前緣中的離散性越高,比 較具有代表性;反之,多樣性越低。故為了維持族群多樣性,擁擠距離較大者會 被優先保留,距離較小的會被淘汰。以下為擁擠距離的計算過程: 1. 假設非支配前緣 F上的解集合個數以 l表示 l = F 。F中每個解的擁擠距 離 d i 先設為 0。 2. 分別對每個目標函數 f m ( m = 1,2, , M ),將解以遞減順序進行排序,以 I m 表示之。 3. 令 d I m = d I m = ∞ ,對其他所有解 j ( j = 2, , l − 1 )以(2-8)式算出擁擠距離 1. l. (I m ). dIm = dIm j. j. (I m ). f j +1 − f m j −1 + m max f m + f mmin. (2-8). ( I mj ). 其中 I mj 代表在第 m 個目標函數中,其目標函數值位於第 j 順位的解。 f m. 代表. 在第 m 個目標函數中,其目標函數值位於第 j 順位的解的目標函數值。 f mmax 和 f mmin 分別為第 m 個目標函數的最大值和最小值。 以圖 2.15 中的非支配前緣層級 1 舉例說明,假設層級 1 中的每個解的目標 函數值以及大小順序,如表 2.2 所示。並將目標函數值最大與最小的解的擁擠距 20.
(29) 離設為 ∞ ,其餘設為 0。 表 2.2:非支配前緣層級 1 各解的目標函數值、擁擠距離及排序 Solution. f1. f2. Sort( f 1 ). Sort( f 2 ). Distance. 2. 16. 7. 1st. 4th. ∞. 4. 8. 10. 3rd. 2nd. 0. 5. 6. 21. 4th. 1st. ∞. 7. 14. 8. 2nd. 3rd. 0. 接著用(2-8)式計算解 4、7 的擁擠距離。 Solution 4: d solution _ 4 = 0 +. f1( solution _ 7 ) − f1( solution _ 5) 14 − 6 =0+ = 0.4 max min f1 − f1 20 − 0. d solution _ 4 = 0.4 +. f 2( solution _ 5) − f 2( solution _ 7 ) 21 − 8 = 0.4 + = 0.92 max min f2 − f2 25 − 0. Solution 7: d solution _ 7 = 0 +. f1( solution _ 2 ) − f1( solution _ 4 ) 16 − 8 =0+ = 0.4 max min f1 − f1 20 − 0. d solution _ 7 = 0.4 +. f 2( solution _ 4 ) − f 2( solution _ 2 ) 10 − 7 = 0.4 + = 0.52 max min f2 − f2 25 − 0. 由計算結果得知,解 4 的擁擠距離大於解 7。因此,若要在rank 1 中淘汰掉一個解, 則因為解 2、4、5 都比解 7 的擁擠距離大,亦即解 2、4、5 比較具有代表性,所 以會選擇淘汰解 7。. 2.5.3 擁擠競爭選擇法 NSGA-II 的 挑 選 機 制 為 擁 擠 競 爭 選 擇 法 (crowded tournament selection operator),相較於一般的競爭選擇法,擁擠競爭選擇法加入了支配與擁擠距離的 概念,主要的目的是要挑選出具多樣性且適應程度較優的染色體。在多目標基因 演算法中,族群經過非支配排序和擁擠距離排序後,可得知每條染色體的非支配. 21.
(30) 層級 ri 和區間擁擠距離 d i (local crowding distance),接著利用擁擠比較運算子 < c (crowded comparison operator)來評估染色體之間的適應程度好壞。在擁擠競爭 選擇法中, ri 和 d i 這兩個特徵會被用來評估染色體的適應程度。擁擠競爭選擇法 的定義如下: 假設C i 與C j 的非支配層級與區間擁擠距離分別為 ri 、 r j 和 d i 、 d j 。 (a) 當 ri < r j 時,則C i 的適應程度優於C j 。 (b) 若 ri = r j ,且當 d i > d j 時,則C i 的適應程度優於C j 。 圖 2.17 和圖 2.18 分別說明了狀況(a)與狀況(b)。在圖 2.17 中,由於C 2 所屬層級為 1,C 5 所屬層級為 2,故可得知C 2 的適應程度優於C 5,所以將C 2 複製到交配池中。 在圖 2.18 中,由於C 2 和C 3 所屬層級皆為 1,所以必須根據擁擠程度來決定合適 度較好的染色體,擁擠距離越大表示該染色體在所屬層級中,所代表的象徵性越 大,所以要把擁擠距離較大的染色體C 3 複製到交配池中。 r. d. C1. 1. ∞. C2. 1. 0.23. C3. 1. 0.51. C4. 1. ∞. C5. 2. ∞. 隨機挑選2 條染色體. C2. 1. 0.23. C5. 2. ∞. 將合適度較 好的複製到 交配池. mating pool C2. 圖 2.17:擁擠競爭選擇法-狀況(a) r. d. C1. 1. ∞. C2. 1. 0.23. C3. 1. 0.51. C4. 1. ∞. C5. 2. ∞. 隨機挑選2 條染色體. C2. 1. 0.23. C3. 1. 0.51. 將合適度較 好的複製到 交配池. 圖 2.18:擁擠競爭選擇法-狀況(b). 22. mating pool C3.
(31) 3 第三章 多目標數位浮水印系統 本章將逐步介紹本論文所提出的多目標數位浮水印系統之嵌入及擷取浮水 印的詳細程序,以及描述本系統中多目標演算法的染色體的編碼、適應函數的定 義、挑選機制、以及染色體交配和突變的方法。. 3.1 浮水印嵌入程序 以 X 表示原始影像,其大小為 M × M ,W 表示原始浮水印,其大小為 M M × 。浮水印的嵌入步驟如下: 2 2 步驟一:將原始影像 X 切割成大小相同且不重疊的區塊,每個區塊大小為 32×32, X =. M / 32 M / 32. X m =1. (3-1). ( m,n ). n =1. 步驟二:對每個區塊進行二維離散餘弦轉換,. X (DCT m ,n ) = DCT ( X ( m ,n ) ),且. X (DCT m,n ) =. {X. 1024. ZDCT ( m,n ). (3-2). (i )},其中 1 ≤ m ≤ M. 32. i =1. ,1 ≤ n ≤. M 32. (3-3). 每個 32×32 區塊中,總共有 1024 個 DCT 係數,其中一維矩陣 X (ZDCT m , n ) (i ) 是以 zigzag 的掃描方式,依序將係數表示為 DC、AC1、AC2、…、AC1023。 M M 步驟三:從每個區塊中取出 256 個 DCT 係數(AC3 到 AC258),故總共有 × 32 32 . 個 1×256 的一維矩陣,接著將它們合併並重新塑形成為一個. M M × 的二維 2 2. 矩陣,以 Y 表示之。圖 3.1 為重新塑形之示意圖( M = 256 )。 Y=. {X. M / 32 M / 32 258 m =1. n =1. ZDCT ( m,n ). (i )}. (3-4). i =3. 23.
(32) AC(1,1). …. AC(1, 128). AC(1, 129). …. AC(1, 256). AC(2,1). …. AC(2,128). AC(2,129). …. AC(2, 256). …. …. …. …. …. …. AC(63,1). …. AC(63,128). AC(63,129). …. AC(63, 256). AC(64,1). …. AC(64,128). AC(64,129). …. AC(64, 256). Reshape. AC(1,1). …. AC(1, 128). AC(2,1). …. AC(2,128). …. …. …. AC(63,1). …. AC(63,128). AC(64,1). …. AC(64,128). AC(1, 129). …. AC(1, 256). AC(2,129). …. AC(2, 256). …. …. …. AC(63,129). …. AC(63, 256). AC(64,129). …. AC(64, 256). 圖 3.1:將 64×256 矩陣重新塑形為 128×128 矩陣 步驟四:對 Y 進行奇異值分解 Y = U Y ⋅ SY ⋅ VYT. (3-5). 步驟五:對原始浮水印進行二維離散餘弦轉換, W DCT = DCT(W ). (3-6). 步驟六:對 W DCT 進行奇異值分解 W DCT = U W ⋅ SW ⋅ VWT. (3-7). 步驟七:將 SW 乘以調整參數 α ,並與 S Y 相加,嵌入完之後的結果以 SY′ 表示之, SY′ = SY + α ⋅ SW. (3-8). 24.
(33) 其中 α = diagonal α 1 , α 2 , , α M 2 . M M , α 為一 × 之對角矩陣。 2 2 . 步驟八:將 SY′ 與 U Y 、 VYT 做反 SVD 運算,其結果以 Y ′ 表示之, Y ′ = U Y ⋅ S Y′ ⋅ VYT. (3-9). 步驟九:將Y ′ 中的係數取代 X DCT 中相對應區塊的 DCT 係數,取代完之後的結果 以 X ′ DCT 表示之。 步驟十:對 X ′ DCT 進行反離散餘弦轉換,轉換完後的結果以 X ′ 表示之,. (. X W = I DCT X ′ DCT. ). (3-10). X W 即為嵌入浮水印後的影像。. 3.2 浮水印擷取程序 在擷取浮水印時,會參考到原始的 SY ,故在嵌入浮水印的程序中,必須將 SY 的值記錄下來,將其當作擷取程序中的金鑰。假設 X W* 為一張嵌有浮水印且受攻 擊過後的影像,浮水印擷取程序的詳細步驟如下: 步驟一:將影像 X W* 切割成大小相同且不重疊的區塊,每個區塊大小為 32×32, X = * W. M / 32 M / 32. X m =1. * ( m ,n ). (3-11). n =1. 步驟二:對每個區塊進行二維離散餘弦轉換,. (. ). * X (*mDCT ,n ) = DCT X ( m ,n ) ,且. 1024. {. }. (3-12). *ZDCT X (*mDCT ,n ) = X ( m ,n ) (i ) ,其中 1 ≤ m ≤ i =1. M M , 1≤ n ≤ 32 32. 25. (3-13).
(34) 每個 32×32 區塊中,總共有 1024 個 DCT 係數,其中一維矩陣 X (*mZDCT ,n ) (i ) 是以 zigzag 的掃描方式,依序將係數表示為 DC、AC1、AC2、…、AC1023。 M M 步驟三:從每個區塊中取出 256 個 DCT 係數(AC3 到 AC258),故總共有 × 32 32 . 個 1×256 的一維矩陣,接著將它們合併並重新塑形成為一個. M M × 的二維 2 2. 矩陣,以 Y * 表示之, Y* =. {X. M / 32 M / 32 258 m =1. n =1. *ZDCT ( m ,n ). (i )}. (3-14). i =3. 步驟四:對 Y * 進行奇異值分解 Y * = U Y* ⋅ SY* ⋅ VY*T. (3-15). 步驟五:將 SY* 與金鑰 SY 及調整參數 α 進行運算後得到 SW*. (. SW* = α −1 ⋅ SY* − SY. ). (3-16). 步驟六:將 SW* 與 U W 、 VW 進行反 SVD 運算,其結果以 W * DCT 表示之, W * DCT = U W ⋅ SW* ⋅ VWT. (3-17). 步驟七:對 W * DCT 進行反離散餘弦轉換,其結果以 W * 表示之,. (. W * = IDCT W * DCT. ). (3-18). W * 即為擷取出來的浮水印影像。. 3.3 多目標基因演算法配置 本論文提出使用 NSGA-II 來解決多目標最佳化的問題,下面將對 NSGA-II 中所使用的染色體編碼方式、適應函數、挑選、交配與突變的機制作介紹。. 26.
(35) NSGA-II 是用來解決多目標最佳化的問題,在進行迭代演算的過程中,每個 解都有各自的適應值,接著以這些適應值當作參考,來決定解之間的支配、非支 配關係,然後再進行演化的動作,演化的過程包括選擇、交配、突變等步驟。. 3.3.1 染色體編碼方式 在嵌入浮水印的程序中,使用到的調整參數 α (scaling factor),要如何訂定其 數值是一個相當複雜問題。這個調整參數將會隨著不同的藏匿影像而不同,進而 直接影響到數位浮水印的不可見性以及強韌性;可想而知,若以人工的方法訂定 其數值的話,會是一項相當困難的工作。所以,如何訂定合適的調整參數成了我 們要解決的問題。故本論文提出以多目標基因演算法來決定調整參數的數值,透 過 NSGA-II 的運算,最後會決定出一組最適解集合,再由這些解集合中挑選出 使用者本身偏好的解來當作嵌入浮水印的調整參數 α 。 調整參數 α 是一個大小為. M M × 的對角矩陣(diagonal matrix),矩陣對角線 2 2. 上的數可以是一個正整數或是正浮點數,共有 定義為一個大小為 1 ×. M 個數值。故染色體編碼方式可 2. M M 的一維矩陣,其資料型態為實數型態,染色體上的 個 2 2. 基因對應到調整參數 α 對角線上的. M 個數值。 2. 3.3.2 適應函數 由於數位浮水印主要注重的是影像的不可見性以及浮水印的強韌性,故可以 將前述兩項需求定義為兩個獨立的適應函數F 1 和F 2,分別對應不可見性以及強韌 性。F 1 代表嵌入浮水印之影像的不可見性,計算嵌入浮水印後的影像與藏匿影像 的平均平方誤差(mean square error, MSE);當MSE數值越小,代表兩張影像的差 異度越小,即不可見性越高。F 1 適應函數定義如(3-19)式: F1 = MSE ( X , X ′). (3-19) 27.
(36) MSE 計算公式如(3-20)式:. MSE ( X,X ′) =. 1 MN. M. N. ∑∑ ( X (i, j ) − X ′(i, j )). 2. (3-20). i =1 j =1. 其中X為藏匿影像, X ′ 為嵌入浮水印後的影像。故,目的要將F 1 最小化。 F 2 代表嵌入浮水印之影像受到攻擊後取出的浮水印品質,也就是浮水印方法 的強韌性。我們使用Wang和Bovik[50]所提出的影像品質指標來評估,以下稱此 方法計算得的值為Q值,其公式如(3-21)式:. Q(x, y ) =. 4σ xy x y. (3-21). (σ x2 + σ y2 )[( x ) 2 + ( y ) 2 ]. 假設 x = {xi | i = 1,2, , N } , y = { y i | i = 1,2, , N } 其中 x=. 1 N. N. ∑ xi , y = i =1. 1 N. N. ∑y i =1. i. σ x2 =. 1 N 1 N 2 2 , ( ) x x − σ = ( yi − y ) 2 ∑ ∑ i y N − 1 i =1 N − 1 i =1. σ xy =. 1 N ∑ ( xi − x )( yi − y ) N − 1 i =1. 此影像品質評估指標結合了三種影像評估因子:相關度損失(loss of correlation)、 明亮度失真(luminance distortion)、對比度失真(contrast distortion)。Q值會介於-1 到 1 之間,當Q值越大,表示兩張影像差異度越小;反之,Q值越小,表示兩張 影像差異度越大。所以,Q值越高,代表浮水印抗攻擊能力越強,即強韌性高; 反之亦然。F 2 適應函數定義如(3-22)式: F2 =. 1 n ∑ Q(W ,Wi′) n i =1. (3-22). 其中,W代表原始浮水印,Wi′ 代表經第i種攻擊後取出來的浮水印,總共有n種攻 擊。故,目的要將F 2 最大化。 28.
(37) 3.3.3 交配與突變 雖然實數可使用二元編碼來實現,但是當使用者需要更高的精準度時,染色 體的長度會隨之變大,這樣會導致計算複雜度的增加。因此陸續有學者提出適用 於實數編碼的交配與突變方法。 本論文 NSGA-II 中使用的交配方法為模擬二元交配法(simulated binary crossover, SBX)[44],突變方法為多項式突變法(polynomial mutation)[45]。以下將 依序描述模擬二元交配法與多項式突變法如何產生新的子代。 模擬二元交配法是一種模擬二元字串之單點交配的實數編碼交配法,由兩條 父代染色體進行下式運算後產生兩條子代染色體,. [. ]. (3-23). [. ]. (3-24). Child1,i =. 1 (1 + β qi )Parent1,i + (1 − β qi )Parent 2,i 2. Child 2,i =. 1 (1 − β qi )Parent1,i + (1 + β qi )Parent 2,i 2. 其中, Child k ,i 表示第 k 條新子代的第 i 個決策變數, Parent k ,i 表示第 k 條父代的 第 i 個決策變數, β qi 是隨機數中的一個樣本,其機率密度如(3-25)式所示, 0.5(η c + 1)β i ηc , if β i ≤ 1 1 P(β i ) = 0.5(η c + 1) ηc + 2 , otherwise βi . βi =. Child 2,i − Child1,i. (3-25). (3-26). Parent 2,i − Parent 1,i. β qi 可由(3-27)式算得, 1 η ( ) 2 u c i +1 , 1 if u i ≤ 0.5 β qi = ηc +1 1 , otherwise 2(1 − u i ) . (3-27). 其中 u i 為一隨機數 u i ∈ [0,1) , η c 為分布索引(distribution index)。隨著分布索引值 29.
(38) 的不同,其演化搜尋能力也會跟著不同。η c 為一非負實數,由使用者自訂,若 η c 的值越大,則交配後會有比較高的機率產生出與父代相近的新子代;若 η c 的值越 小,則產生與父代差異較大的新子代的機率會相對的高。 多項式突變法為一條父代染色體經由下式運算後產生一條子代染色體, Child i = Parent i + (Upperi − Loweri ) × δ i. (3-28). 其中Child i 表示子代的第i個決策變數,Parent i 表示父代的第i個決策變數,Upper i 和Lower i 分別表示第i個決策變數的上限值與下限值, δ i 的定義如下: (2ri )1 / (η m +1) − 1,. δi = . 1 − [2(1 − ri )]. 1 / (η m +1). if ri < 0.5 , if ri ≥ 0.5. (3-29). 其中 ri 為一隨機數 ri ∈ [0,1], η m 為分布索引(distribution index),與模擬二元交配 法中的η n 一樣都是用來決定搜尋能力的強弱, η m 為一非負實數,由使用者自訂 其值。. 30.
(39) 4 第四章 實驗結果 本章將對本論文提出的數位浮水印技術進行效能測試。另外,我們將實作單 目標基因演算法及 Monemizadeh 和 Seyedin[37]所提出的方法,進行實驗數據的 比較與分析。. 4.1 實驗環境 本實驗環境為一台四核心的電腦,CPU 型號為 Intel® Core™ i7-920 @ 2.67GHz,記憶體大小為 4GB,作業系統為 Windows 7 Professional,程式開發軟 體為 MATLAB R2008a。 本實驗使用 Lena 當作藏匿影像,為一 256×256 的灰階影像(如圖 4.1 (a)所 示),測試的浮水印使用 Boat,為一 128×128 的灰階影像(如圖 4.1 (b)所示)。. (a) 原始影像. (b) 浮水印 圖 4.1:實驗測試影像. 為了證明浮水印的強韌性,本論文引用一些比較常見的影像處理,以及 Shelby 所提出的 Checkmark[51]中的部份影像處理,本論文使用的影像攻擊類型 如下: 31.
(40) 1. 幾何攻擊: 外圍裁切(border cropping):從影像周圍裁減掉四分之一總面積的大小,並將 裁掉的區域以白色取代之。 橫向裁切(transverse cropping):以縱向為基準,將影像橫向切割成八等分, 每一等分的影像大小為 32×256,接著將第二、四、六、八等分的橫幅 影像,以黑色取代之。 旋轉(rotation):將影像旋轉-20 度。 重調尺寸(resizing):將影像從 256×256 縮成 128×128,再將其放大為 256×256。 2. 雜訊攻擊: 高斯白雜訊(Gaussian white noise):其平均數(mean)為 0,變異數(variance)為 0.003。 胡椒鹽雜訊(salt & pepper noise):其雜訊密度(noise density)為 0.02。 3. 去雜訊攻擊: 低通濾波(low pass filtering):採用 3×3 的遮罩,如(4-1)式所示。. 1 2 1 1 2 4 2 16 1 2 1 . (4-1). 均值濾波(mean filtering):採用 3×3 的遮罩,如(4-2)式所示。. 1 1 1 1 1 1 1 9 1 1 1. (4-2). 銳利化(sharpening):採用 3×3 的遮罩,如(4-3)式所示。. − 1 − 4 − 1 1 − 4 26 − 4 6 − 1 − 4 − 1 . (4-3). 4. 壓縮攻擊: JPEG 壓縮:quality factor 為 10%。 32.
(41) 5. 其它影像處理攻擊: 直方圖等化(histogram equalization)。 像素值減少 20(contrast -20):將原始影像上每個像素的值減去 20。 6. Checkmark[51]: 高斯濾波(Gaussian filter):採用 5×5 的遮罩。 中值濾波(median filter):採用 3×3 的遮罩。 修整平均濾波器(trimmed mean filter):採用 7×7 的遮罩。 抖色處理(dithering):透過演算法以區塊的方式,逐步產生出一張與原始影 像色調很相近的二值影像,其主要是利用空間解析度換取強度解析度, 以達到此效果。 翻轉(flip):將影像左右翻轉。 二值化處理(thresholding):將影像二值化,變成黑白影像。. 33.
(42) 4.2 多目標與單目標的實驗數據 4.2.1 本論文所提出的方法(多目標)之實驗數據 本實驗之實驗參數設置如下: 族群大小:32 演化代數:400 代、600 代、800 代、1000 代 交配機制:模擬二元交配法, η c = 20 ,交配機率 Pc = 0.9 突變機制:多項式突變法, η m = 20 ,突變機率 Pc = 0.1 基因數值界限:下界為 10 −6 、上界為 1 n. 適應函數 F1 = MSE ( X , X ′) 、 F2 = ∑ Q(W , Wi′) ,其中 n 為攻擊類型總數,實驗中 i =1. 3. 3. 2. 2. Q Value. Q Value. 所使用的攻擊類型為 JPEG 壓縮、中值濾波以及重調尺寸,故 n = 3 。. 1. 0. 0. 20. 60. 40. 80. 1. 0. 100. 0. 20. MSE. 2. 2. Q Value. Q Value. 3. 1. 20. 40. 60. 80. 100. (b) 第二組實驗:600 代. 3. 0. 60. MSE. (a) 第一組實驗:400 代. 0. 40. 80. 1. 0. 100. MSE. 0. 20. 40. 60. 80. MSE. (c) 第三組實驗:800 代 (d) 第四組實驗:1000 代 圖 4.2:四種不同演化代數的所得到的實驗結果 34. 100.
(43) 我們針對四種不同的演化代數進行實驗,每一種演化代數重複進行 10 次實驗, 故總共進行了 40 次的實驗。圖 4.2 為四組實驗分別重複進行 10 次實驗所得到的 最佳解集合。我們可從圖 4.2 得知,隨著演化代數的提高,每次實驗所得到的最 佳解集合的變異程度會隨之降低。第四組實驗中,10 次實驗所得到的解集合其 差異度很小;也就是說,隨著演化代數的增加,所得到的最佳解集合不僅更穩定, 也更優越。從第四實驗組中,隨機挑選一次實驗,並從最佳解集合中隨機挑選三 個解進行攻擊測試。實驗數據如表 4.1 所示: 表 4.1:本論文所提出的方法之實驗數據 PSNR Non-attack JPEG 高斯白雜訊 胡椒鹽雜訊 低通濾波 中值濾波 均值濾波 高斯濾波 修整平均濾波 銳利化 直方圖等化 重調尺寸 外圍裁切 橫向裁切 旋轉 Contrast -20 抖色處理 翻轉 二值化處理. Ours _1. Ours _2. Ours _3. 34.58 0.9998 0.9949 0.9456 0.8574 0.9704 0.9807 0.9598 0.9536 0.3406 0.5562 0.9032 0.9909 0.7855 0.8309 0.8619 0.9959 0.5750 0.9982 0.8739. 39.28 0.9974 0.9936 0.9129 0.7983 0.9182 0.9645 0.9057 0.9259 0.0216 0.5227 0.9481 0.9820 0.7271 0.9490 0.8055 0.9963 0.5459 0.9508 0.9446. 42.01 0.9878 0.9731 0.9211 0.2743 0.3397 0.9543 0.0164 0.8368 0.4223 0.3980 0.8943 0.9450 0.6387 0.8958 0.7090 0.9868 0.6498 0.9367 0.8925. 35.
(44) 圖 4.3 為表 4.1 的三個解之嵌入浮水印後的影像及其品質。. (a) PSNR = 34.58 dB (b) PSNR = 39.28 dB (c) PSNR = 42.01 dB 圖 4.3:以表 4.1 之三個解進行浮水印嵌入所得到的影像 表 4.2 為圖 4.3 之三張影像經各種攻擊後擷取出來的浮水印及其品質。 表 4.2:Ours _1、2、3 之浮水印強韌度測試 Ours_1. Ours _2. Ours _3. Q = 0.9998. Q = 0.9974. Q = 0.9878. Q = 0.9949. Q = 0.9936. Q = 0.9731. Q = 0.9456. Q = 0.9129. Q = 0.9211. Non-attack. JPEG. 高斯白 雜訊. 36.
(45) 胡椒鹽 雜訊. Q = 0.8574. Q = 0.7983. Q = 0.2743. Q = 0.9704. Q = 0.9182. Q = 0.3397. Q = 0.9807. Q = 0.9645. Q = 0.9543. Q = 0.9598. Q = 0.9057. Q = 0.0164. Q = 0.9536. Q = 0.9259. Q = 0.8368. Q = 0.3406. Q = 0.0216. Q = 0.4223. 低通濾波. 中值濾波. 均值濾波. 高斯濾波. 修整平均 濾波. 37.
(46) 銳利化. Q = 0.5562. Q = 0.5227. Q = 0.3980. Q = 0.9032. Q = 0.9481. Q = 0.8943. Q = 0.9909. Q = 0.9820. Q = 0.9450. Q = 0.7855. Q = 0.7271. Q = 0.6387. Q = 0.8309. Q = 0.9490. Q = 0.8958. Q = 0.8619. Q = 0.8055. Q = 0.7090. 直方圖 等化. 重調尺寸. 外圍裁切. 橫向裁切. 旋轉. 38.
(47) Contrast -20. Q = 0.9959. Q = 0.9963. Q = 0.9868. Q = 0.5750. Q = 0.5459. Q = 0.6498. Q = 0.9982. Q = 0.9508. Q = 0.9367. Q = 0.8739. Q = 0.9446. Q = 0.8925. 抖色處理. 翻轉. 二值化 處理. 接著,我們將模擬二元交配法與多項式突變法中的分布索引 η m 與 η c 設為 10,再進行相同的實驗。實驗結果如表 4.3 所示,我們可從中觀察到,當分布索 引設為 10 的狀況下,在 400 代與 600 代這兩組實驗中,每組實驗執行 10 次後所 產生的最佳解集合的變異程度有變小的跡象。由這兩組實驗也可看出,將分布索 引設為 10 的狀況下,可以較快的速度尋找出較優越的解,且不同實驗所產生的 最佳解集合的差異程度也比較小。如何挑選一個較適當的分布索引,是未來可研 究的議題之一。. 39.
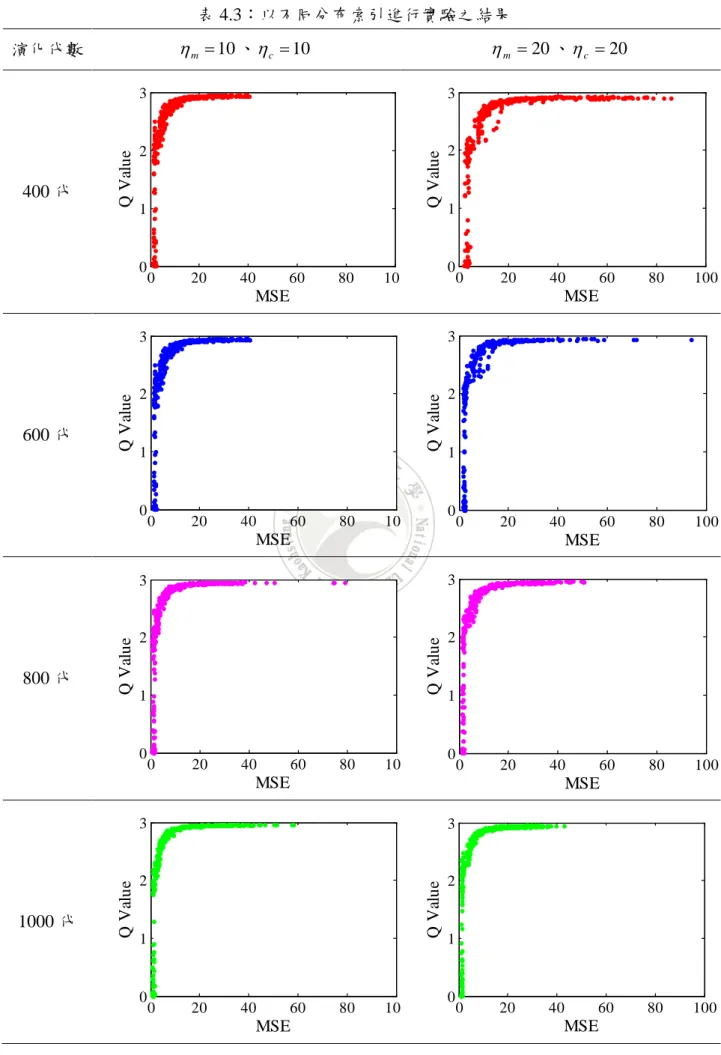
(48) 表 4.3:以不同分布索引進行實驗之結果. η m = 10 、 η c = 10. η m = 20 、η c = 20. 3. 3. 2. 2. Q Value. 400 代. Q Value. 演化代數. 1. 0. 0. 20. 40. 60. 80. 1. 0. 100. 0. 20. 3. 2. 2. Q Value. Q Value. 3. 1. 0. 0. 20. 40. 60. 80. 0. 10. 2. 2. Q Value. Q Value. 3. 1. 0. 20. 0. 20. 40. 60. 40. 80. 0. 10. 2. 2. Q Value. Q Value. 3. 1. 0. 20. 40. 80. 100. 0. 20. 40. 80. 100. 60. 80. 100. 60. MSE. 3. 0. 60. 1. MSE. 1000 代. 100. MSE. 3. 0. 80. 1. MSE. 800 代. 60. MSE. MSE. 600 代. 40. 80. 10. 1. 0. 0. 20. 40. 60. MSE. MSE 40.
(49) 4.2.2 單目標基因演算法之實驗數據 為了驗證多目標基因演算法在數位浮水印問題上的效能,將本論文所提出的 數位浮 水印 技術 ,利 用單目 標基因演算法(single-objective genetic algorithm, SOGA)進行測試。 單目標基因演算法的適應函數定義如(4-4): n. F = PSNR + λ × ∑ Q(W , Wi′). (4-4). i =1. 其中 W為原始浮水印, Wi′ 為從受某一種攻擊後的影像中擷取出來的浮水印; PSNR用來評估嵌入浮水印後的影像品質;n為攻擊類型總數,此實驗在進行基因 演算法所使用的攻擊類型有三種:JPEG壓縮、中值濾波以及重調尺寸,故 n = 3 ;. λ 為Q值的權重參數,在此我們設定 λ = 30 。PSNR的計算方式如(4-5)式所示。 255 2 PSNR ( X,X ′) = 10 × log10 MSE ( X,X ′) . MSE ( X,X ′) =. 1 MN. M. N. ∑∑ ( X (i, j ) − X ′(i, j )). (4-5). 2. (4-6). i =1 j =1. 其餘相關參數定義如下: 族群大小:32 演化代數:1000 交配機制:模擬二元交配法, η c = 20 ,交配機率 Pc = 0.9 突變機制:多項式突變法, η m = 20 ,突變機率 Pc = 0.1 基因數值界限:下界為 10 −6 、上界為 1 本實驗總共重複進行 10 次的運算,表 4.4 為 10 次測試後所得到的最佳解的適應 值,Q 值欄位表示演化過程中,經三種攻擊後所擷取出來的浮水印品質之總和。. 表 4.4:SOGA 重複進行 10 次測試之實驗數據 41.
(50) Fitness(F). PSNR. Q value (total). Test1. 118.7526. 33.2492. 2.8501. Test2. 118.7817. 34.8448. 2.7979. Test3. 121.8090. 35.6917. 2.8706. Test4. 118.5674. 35.9003. 2.7556. Test5. 119.8273. 35.2012. 2.8209. Test6. 116.6049. 35.1707. 2.7145. Test7. 120.0148. 35.3393. 2.8225. Test8. 117.6436. 33.7415. 2.7967. Test9. 119.9457. 34.2020. 2.8581. Test10. 115.2978. 36.6037. 2.6231. 表 4.5 為從 10 次實驗中,隨機挑選三次實驗的最佳解,進行實際測試的實驗數 據,分別為 SOGA_1、SOGA_2、SOGA_3。. 表 4.5:SOGA 之 3 次實驗的數據 SOGA_1. SOGA _2. SOGA _3. PSNR. 34.20. 35.20. 35.90. Non-attack JPEG 高斯白雜訊 胡椒鹽雜訊 低通濾波 中值濾波 均值濾波 高斯濾波 修整平均濾波 銳利化 直方圖等化 重調尺寸 外圍裁切. 0.9581 0.9344 0.7792 0.4824 0.8588 0.9552 0.6837 0.9518 0.0039 0.2562 0.9500 0.9259 0.6947. 0.9729 0.9623 0.9442 0.4900 0.9127 0.9106 0.6115 0.8847 0.5239 0.6181 0.8086 0.9372 0.6557. 0.9397 0.8973 0.7160 0.4766 0.7950 0.9223 0.6000 0.8207 0.0053 0.2885 0.6822 0.8921 0.8017. 42.
(51) 橫向裁切 旋轉 Contrast -20 抖色處理 翻轉 二值化處理. 0.9295 0.8001 0.9566 0.2453 0.9588 0.9349. 0.8838 0.6723 0.9716 0.6043 0.8945 0.8131. 0.3263 0.9146 0.9382 0.2724 0.6607 0.6256. 圖 4.4 分別為 SOGA_1、SOGA_2、SOGA_3 的實驗結果。. (a) PSNR = 34.20 dB (b) PSNR = 35.20 dB (c) PSNR = 35.90 dB 圖 4.4:SOGA_1、2、3 三個解進行浮水印嵌入所得到的影像 表 4.6 為圖 4.4 之三張影像經各種攻擊後擷取出來的浮水印及其品質。 表 4.6:SGA_1、2、3 之浮水印強韌度測試 SOGA_1. SOGA_2. SOGA_3. Q = 0.9581. Q = 0.9729. Q = 0.9397. Q = 0.9344. Q = 0.9623. Q = 0.8973. Non-attack. JPEG. 43.
(52) 高斯白 雜訊. Q = 0.7792. Q = 0.9442. Q = 0.7160. Q = 0.4824. Q = 0.4900. Q = 0.4766. Q = 0.8588. Q = 0.9127. Q = 0.7950. Q = 0.9552. Q = 0.9106. Q = 0.9223. Q = 0.6837. Q = 0.6115. Q = 0.6000. Q = 0.9518. Q = 0.8847. Q = 0.8207. 胡椒鹽 雜訊. 低通濾波. 中值濾波. 均值濾波. 高斯濾波. 44.
(53) 修整平均 濾波. Q = 0.0039. Q = 0.5239. Q = 0.0053. Q = 0.2562. Q = 0.6181. Q = 0.2885. Q = 0.9500. Q = 0.8086. Q = 0.6822. Q = 0.9259. Q = 0.9372. Q = 0.8921. Q = 0.6947. Q = 0.6557. Q = 0.8017. Q = 0.9295. Q = 0.8838. Q = 0.3263. 銳利化. 直方圖 等化. 重調尺寸. 外圍裁切. 橫向裁切. 45.
(54) 旋轉. Q = 0.8001. Q = 0.6723. Q = 0.9146. Q = 0.9566. Q = 0.9716. Q = 0.9382. Q = 0.2453. Q = 0.6043. Q = 0.2724. Q = 0.9588. Q = 0.8946. Q = 0.6607. Q = 0.9349. Q = 0.8131. Q = 0.6256. Contrast -20. 抖色處理. 翻轉. 二值化 處理. 46.
(55) 4.2.3 多目標與單目標的實驗結果比較 使用同樣的浮水印嵌入技術,分別結合 NSGA-II 以及 SOGA 進行實驗,其 實驗結果如前面的章節所示。採用本論文之方法的第四組實驗中的一組柏拉圖最 佳解集合,與 SOGA 的 10 次實驗所得到的最佳解進行比較。圖 4.5 證實了多目 標基因演算法求得的解比單目標基因演算法求得的解更優越,也更具多樣性。. 3. Q value. 2.5 2. 1.5 NSGA-II SOGA. 1 0.5 0. 0. 10. 20. 30. 40. 50. MSE 圖 4.5:NSGA-II 與 SGA 的最佳解之比較. 4.3 其他多目標基因演算法之實驗結果 Monemizadeh 和 Seyedin[37](以下簡稱 M&S[37])提出 DWT 結合 SVD 的數 位浮水印技術,並透過 NSGA-II 來求解最佳化。他們提出的方法是,將一大小 為 n × n 的浮水印嵌入至大小為 2n × 2n 的藏匿影像中;其嵌入步驟為,先對藏匿 影像進行一次離散小波轉換,轉換後會得到 LL、LH、HL、與 HH 四個頻率域的 係數。接著將這四個頻率域分別進行奇異值分解,分解後所得到的奇異值以 λik 表 示之,其中 i = 1, 2, , n , k = 1, 2, 3, 4 (分別代表四個頻率域)。接著再對浮水印進 行奇異值分解,分解後所得到的奇異值以 λ wi 表示之,其中 i = 1, 2, , n。透過(4-7) 式分別對四個頻率域進行浮水印的嵌入動作。 47.
(56) λ*i k = λik + α k λ wi. (4-7). 因為每張藏匿影像中嵌有四張相同的浮水印,故在擷取浮水印時,將會擷取到四 張浮水印。接著再從這四張擷取到的浮水印挑選出一張辨識度較高的浮水印進行 驗證。在他們的方法中,使用皮爾遜積差相關係數 值(pearson product moment correlation coefficient, PMCC)評估擷取出來的浮水印之品質,其公式如下:. ∑∑ [(I (i, j ) − I )(I (i, j ) − I )] M. PMCC (I , I W ) =. N. W. i =1 j =1. W. M N M N 2 2 ∑∑ (I (i, j ) − I ) ∑∑ (I W (i, j ) − I W ) i =1 j =1 i =1 j =1. (4-8). 其中 I 與 I W 分別為原始浮水印與受攻擊後擷取出來的浮水印, I 與 I W 分別為 I 與 I W 的平均值。皮爾遜積差相關係數是用來分析兩資料集合之間的相關程度, 積差相關係數可當作兩個資料集合間線性關係的一個指標,這個值會介於-1 到 +1 之間,其中正負號表示相關的方向,正相關表示線性相關的斜率為正,負相 關表示線性相關的斜率為負。所以,積差相關係數值越高,代表浮水印抗攻擊能 力越強,即強韌性高。使用 MSE 評估嵌入浮水印後的影像之品質。NSGA-II 所 使用的適應函數如下: n F1 = − ∑ PMCC ( I , I iW ) i =1 . (4-9). 其中 n 為攻擊類型總數,實驗中所使用的攻擊類型為 JPEG 壓縮、中值濾波以及 重調尺寸,故 n = 3 。. F2 = MSE ( X,X ′) MSE ( X,X ′) =. 1 MN. (4-10) M. N. ∑∑ ( X (i, j ) − X ′(i, j )) i =1 j =1. 48. 2. (4-11).
(57) 其它實驗參數設置如下: 族群大小:32 演化代數:200 交配機制:模擬二元交配法, η c = 20 ,交配機率 Pc = 0.9 突變機制:多項式突變法, η m = 20 ,突變機率 Pc = 0.1 基因數值界限:下界為 10 −6 、上界為 1. 1. 1. 0. 0. 0. -1 -2 -3. 0. 1000. 2000. MSE. PMCC. 1. PMCC. PMCC. 此實驗總共重複進行 10 次,圖 4.6 為其中三次實驗的柏拉圖最佳解. -1 -2 -3. 0. 1000. 2000. MSE. -1 -2 -3. 0. 1000. MSE. (a)實驗一 (b)實驗二 (c)實驗三 圖 4.6:M&S[37]提出的方法,實驗中取三次實驗的柏拉圖最佳解 表 4.7 到表 4.9 是從 10 次實驗中,隨機挑選三個解進行測式所得的數據結果。表 中數據為 Q 值,粗體表示該頻域段擷取出來的浮水印品質是四個頻域中最好的。. 表 4.7:M&S[37]的方法之解一的數據 解一 (PSRN = 27.39 dB) Non-attack JPEG 高斯白雜訊 胡椒鹽雜訊 低通濾波 中值濾波 均值濾波 高斯濾波 修整平均濾波. LL. HL. LH. HH. 1 0.9920 0.9210 0.7800 0.5801 0.8002 0.4181 0.8874 -0.0963. 0.9982 0.0398 0.0752 0.0403 0.1223 0.1579 0.1029 -0.0377. 0.9373 0.0137 0.0037 0.0014 0.0025 0.0042 0.0022 0.0086 0.0008. 0.9876 0.0106 0.0072 0.0027 0.0068 0.0160 0.0058 0.0206 0.0062. 0.0671 49. 2000.
數據

+3
![表 4.9:M&S[37]的方法之解三的數據 解三 (PSNR = 15.81dB) LL HL LH HH Non-attack 0.9969 0.9853 0.9221 -0.1537 JPEG 0.9944 0.7184 0.0151 -0.0037 高斯白雜訊 0.9927 0.8122 0.2488 0.0032 胡椒鹽雜訊 0.9807 0.6334 0.1320 0.0010 低通濾波 0.9297 -0.0770](https://thumb-ap.123doks.com/thumbv2/9libinfo/8789641.219703/59.892.140.757.122.707/MampS方法之解數據PSNR=LLHLLHHHNonattackJPEG高斯白雜48胡椒鹽雜低通濾波.webp)

Outline
相關文件
Relation Between Sinusoidal and Complex Exponential Signals
在這一節裡會提到,即使沒辦法解得實際的解函數,我們也 可以利用方程式藉由圖形(方向場)或者數值上的計算(歐拉法) 來得到逼近的解。..
特性:高孔率、耐 130C 高壓滅菌,透光性佳,以 RI 值 1.515 之溶液潤濕過 濾膜即可用顯微鏡觀察過濾膜上的粒子。灰分含量 0.002 mg/cm 2 。一般用來
(2)在土壤動力學中,地震或地表振動產生之振動波,可分為實 體波(Body wave) 與表面波(Surface wave) 。實體波(Body wave)分為壓力波 P 波(Compressional wave)(又稱縱波)與剪
(approximation)依次的進行分解,因此能夠將一個原始輸入訊號分 解成許多較低解析(lower resolution)的成分,這個過程如 Figure 3.4.1 所示,在小波轉換中此過程被稱為
本論文之目的,便是以 The Up-to-date Patterns Mining 演算法為基礎以及導 入 WDPA 演算法的平行分散技術,藉由 WDPA
Finally, making the equivalent circuits and filter prototypes matched, six step impedance filters could be designed, and simulated each filter with Series IV and Sonnet program
而在利用 Autocloning 的方法,製作成金字塔形狀的抗反射 結構方面。分成非次波長結構和次波長結構來加以討論。在非次波長 結構時,我們使用
