國立臺中教育大學教育資訊與測驗統計研究所
碩士論文
指導教授:郭伯臣 博士
吳慧珉 博士
應用自然語言處理技術之
華語閱讀輔助工具
對華語學習者閱讀華語的成效探究
研究生:崔卿鎬 撰
中
華
民
國
一
○
四
年
六
月
謝辭
我在韓國的大學畢業後抱著遠大的夢想來到台灣,為了成為一名好的中文 教育專家,開始在台中教育大學教育資訊與測驗統計研究所攻讀碩士學位。從 入學到現在快 3 年的時間,因得到所上老師、同學、朋友、家人的指導與鼓 勵,才能達到完成學業的目的地。由衷感謝陪伴我一路走到今天的大家。 首先要感謝郭伯臣老師,在學術方面與生活態度方面我學到了不少東西。 人的時間與能力有限,團隊精神能夠解決個人解決不了的問題。我看到的郭老 師不管是周末還是平日,一天到晚把大部分的時間都放在處理所上的計劃與學 術研究,當大學教授已經很久了,還是比學生更晚離開研究室。老師讓我體會 到一個真理就是所有的成功,都來自不倦的努力和奔跑。還有感謝吳慧珉老 師,每次給我學術上的鼓勵與指導,稱讚能讓巨大的鯨魚跳舞,我遇到人生挫 折,失去了信心,對學業無法主動的時候,因為得到老師的又細心又溫暖的指 導,才能順利完成這篇碩士論文。還有真心感謝施淑娟老師與陳桂霞老師還有 陳世銘校長給我的實質的幫助與關懷,深深感受到老師們對所上學生的溫暖與 有責任的態度。還有感謝所上的其他老師們,學長姐與同學們,還有我特別珍 惜的韓文班學生們。 我雖然要離開台灣,不知道什麼時候才能回來,但歡迎大家來韓國找我, 我盡力好好招待大家。每次遇到人生的困難和挫折,我會拿出來我的碩士畢業 證書回憶今天,同時勇敢地去面對它還有克服它,要成為一名能夠為學校增光 添彩的中教大資統所畢業生。 崔卿鎬 中華民國一○四年敬致摘要
本研究旨在探討應用自然語言處理技術之中文閱讀輔助工具對於華語學習 者華語閱讀的效果。研究者主要利用 Python 程式語言的 Jieba 中文自然語言處理 模組,開發華語閱讀輔助工具。實驗對象為臺中市華語教學中心的外國學生。學 生總共考三種不同測驗,其中第一測驗所有受試者都在不使用華語閱讀輔助工具 的情況下接受測試,第二與第三測驗採用交叉實驗設計法,兩組學生交叉使用華 語閱讀輔助工具與不使用華語閱讀輔助工具的方法接受測試。 研究結果如下: 一、華語水準相當的兩組學生使用華語閱讀輔助工具的華語閱讀成績皆高於不使 用華語閱讀輔助工具的情況。 二、無論學生的華語水準如何使用華語閱讀輔助工具的華語閱讀成績皆高於不使 用華語閱讀輔助工具的情況。唯獨在不同華語水準組間進步程度不同,特別在初 級與高級學生之間的進步程度相差比較大。 三、詞間有空格的母語組學生使用華語閱讀輔助工具的華語閱讀成績高於不使用 華語閱讀輔助工具的情況;詞間沒有空格的母語組學生則兩者之間沒有顯著性差 異。 四、過半數的學生將本研究開發之華語閱讀輔助工具評價為「對閱讀華語有幫助」、 「願意使用」,持有正面肯定的態度。 關鍵詞:自然語言處理技術、華語閱讀輔助工具、華語閱讀。Abstract
This study is to explore the effect of the Chinese reading assistant tool applying Natural Language Processing(NLP) skills on the reading activity of the Chinese learner. The assistant tool is written by Python progamming language and mainly use Jieba Chinese NLP module. The subjects of this study are the foreign students from the Chinese language center of universities in Taichung. Every examinees take three kinds of Chinese reading test. The first Chinese reading test is taken without tool. The second and third Chinese reading test use Cross-over design, two groups of students seperately take two kinds of test under different conditions which are with Chinese reading assistant tool and without Chinese reading assistant tool.
The results of the study are as follows:
1. The equal level of two random groups made significant advance in their test achievement under the with Chinese reading assistant tool condition.
2. Regardless of Chinese level, whoever use the Chinese reading assistant tool made significant progress in their test scores under the with Chinese reading assistant tool condition. Also, There is a relatively great difference of advance degree between basic and advance level of Chinese learners.
3. The group of students whose mother tongue with word spacing, there is significant advance in their test achievement under the with Chinese reading assistant tool condition. The group of students whose mother tongue is without word spacing, there is not meaningful advance in test achievement.
4. Majority of the examinees satisfied with the Chinese reading assistant tool.
目錄
摘要...Ⅰ Abstract...Ⅱ 目錄...Ⅲ 表目錄...Ⅴ 圖目錄...Ⅵ 第一章 緒論...1 第一節 研究動機...1 第二節 研究目的...1 第三節 研究問題...2 第四節 名詞釋義...2 第二章 文獻探討...7 第一節 內容基模與閱讀...7 第二節 文本增顯與閱讀...8 第三節 應用自然語言處理技術之 Python 模組...11 第三章 研究方法...23 第一節 研究流程...23 第二節 華語閱讀試題設計...24 第三節 華語閱讀輔助工具介紹...25 第四節 華語閱讀輔助工具實地實驗...27 第五節 華語閱讀輔助工具滿意度調查問卷...29 第六節 統計分析...30 第四章 研究結果與討論...33 第一節 使用華語閱讀輔助工具前學生華語閱讀成績之分析...33 第二節 華語閱讀輔助工具對學生閱讀成績之影響...34 第三節 華語閱讀輔助工具對不同華語水準學生閱讀成績之影響...36 第四節 華語閱讀輔助工具對不同母語學生華語閱讀成績之影響...40 第五節 華語閱讀輔助工具滿意度問卷...42 第五章 結論與建議...45 第一節 結論...45第二節 研究限制...46 第三節 建議...47 參考文獻...49 中文部分...49 韓文部分...51 英文部分...52 附錄...56 附錄 1 華語閱讀 A 測驗...56 附錄 2 華語閱讀 B 測驗...63 附錄 3 華語閱讀 C 測驗...70 附錄 4 華語閱讀測驗答案卷...77 附錄 5「華語閱讀輔助工具」學生滿意度問卷...78 附錄 6 華語閱讀輔助工具實地實驗之照片...80
表目錄
表 3-1 華語閱讀試題設計狀況...24 表 3-2 華語閱讀輔助工具實地實驗設計...28 表 4-1 A 測驗成績之獨立樣本 t 檢定表...34 表 4-2 第一組 B、C 測驗成績之重複樣本 t 檢定表...35 表 4-3 第二組 B、C 測驗成績之重複樣本 t 檢定表...35 表 4-4 初級學生華語閱讀成績之 Mann-Whitney U 檢定表...36 表 4-5 中級學生華語閱讀成績之 Mann-Whitney U 檢定表...37 表 4-6 高級學生華語閱讀成績之 Mann-Whitney U 檢定表...37 表 4-7 不同水準學生組間華語閱讀成績變化程度之單因子變異數分析表.39 表 4-8 不同水準學生組間華語閱讀成績變化程度之 Scheffe 多重比較表...39 表 4-9 雙因子變異數分析之主因子間效果檢定表...40 表 4-10 詞間沒有空格的母語組華語閱讀成績之單因子變異數分析表...41 表 4-11 詞間有空格的母語組華語閱讀成績之單因子變異數分析表...42 表 4-13 滿意度調查問卷之描述性統計分析表...43圖目錄
圖 2-1 DAG 例子...13 圖 2-2 DAFSA 例子...13 圖 2-3 字典樹例子...14 圖 2-4 動態規劃法例子...15 圖 2-5 HMM 維特比演算法例子...19 圖 3-1 研究流程...23 圖 3-2 華語閱讀輔助工具開始運作的畫面...25 圖 3-3 操作文章分析的畫面...26 圖 3-4 結果顯示視窗的第一部分...26 圖 3-5 結果顯示視窗的第二部分...27 圖 4-1 華語閱讀輔助工具與不同水準學生組間成績變化情形...38第一章 緒論
韓國近年來對華語教育的需求日漸增加。因為韓國經濟與中國有密切的關 係,所以華語的地位已經提升至最主要的第二外語。但是目前在韓國正規課程裡 面的華語教育時數不足,實難以達成培養基礎外語能力的第二外語教育目標。為 了實現此目標,教師鼓勵學生自主學習是必要的,但在科技化教育的趨勢下,除 了在情意上的鼓勵之外,如能提供學生華語自主學習的科技輔助工具,可能能更 有效幫助學生學習華語。本研究開發華語閱讀輔助工具,希望能夠幫助學生華語 自主學習,達成華語教育目標。第一節 研究動機
在韓國,現在華語是最熱門的外語,其主要原因是韓國與中國的經濟貿易量 持續增加,韓國整體貿易出口的 26%針對中國市場,這數值與 1992 年的 3.5%相 比增加了約 8 倍。中國在 2004 年已經成為韓國的第一大貿易對象國(Hyundai Economic research center, 2014)。因此在韓國對華語的看法與以往不同,華語已經 成為最主要的第二外語。 韓國從高中階段開設華語課程,教育部所規定的高中 3 年華語課程總時數僅 為 68 個小時(課程時數的 1 個小時等於 50 分鐘)。國外的研究指出一年的外語 學習時間不到 95 個小時,既無法實現功能性溝通的教育目標,也無法培養出流 利的外語能力(Archibald et al., 2006)。因此為了達成培養基礎外語能力的華語教 育目標,華語教師務必鼓勵學生自主學習。如上所述,考慮到韓國華語教育的狀 況,學生自主學習是必要的,但在科技化教育的趨勢下,除了在情意上的鼓勵之 外,如能提供給華語學習者華語自主學習的科技輔助工具,以幫助閱讀華語,可 能能更有效幫助學生學習華語,彌補華語課程時數不足之問題。 目前韓國當地在外語教育領域自然語言處理技術之應用的研究大多數限於 英語教育(Jin, 2007;Kim&Chae, 2008;Lee, 2010;Lee&Noh, 2010),將自然語言處理技術應用在華語教育領域。的成效仍有待研究評估,故本研究主要應用自 然語言處理技術,開發華語閱讀輔助工具,並評估成效。
第二節 研究目的
本研究旨在應用自然語言處理技術,開發華語閱讀輔助工具,以便有效幫助 學生閱讀華語。設計華語閱讀輔助工具時,考慮能夠幫助學生閱讀華語的因素(華 語閱讀與詞間空格之間的關係、關鍵詞對華語閱讀的影響、圖片解釋與文字解釋 對華語閱讀的影響),決定了華語閱讀輔助工具之各項功能,其主要功能如下: 一、華語與韓文不同,詞彙之間沒有以空格區分,所以若是不經過閱讀,即無法 直覺地分辨不同的詞彙。因此華語閱讀輔助工具針對華語文章加以斷詞處理,接 著在不同詞彙之間產生空格,以幫助學生直覺性判斷。 二、華語閱讀輔助工具為了幫助學生閱讀華語,由華語文章裡面擷取關鍵詞,接 著在網路上抓取關鍵詞的圖片,將其圖片提供給學生,以幫助了解閱讀文章之核 心內容,並且以劃底線的方式標示關鍵詞,提高學生對關鍵詞的注意力。 本研究為了驗證此閱讀輔助工具的成效,針對「實用視聽華語第 2 冊」以上 程度的華語學習者進行華語閱讀測驗,接著透過華語閱讀輔助工具問卷調查,了 解受試者對閱讀輔助工具之滿意度。本研究的目的如下: 一、提出華語閱讀輔助工具之設計; 二、根據設計內容,開發應用自然語言處理技術之華語閱讀輔助工具; 三、針對華語學習者進行閱讀測驗,驗證華語閱讀輔助工具對閱讀華語的成效; 四、透過華語閱讀輔助工具問卷調查,了解受試者對華語閱讀輔助工具滿意度。第三節 研究問題
根據上面的研究動機與研究目的,本研究提出的研究問題如下: 一、華語閱讀輔助工具對整體學生閱讀成績的影響如何? 二、華語閱讀輔助工具對不同程度學生閱讀成績的影響如何?三、華語閱讀輔助工具對不同母語學生閱讀成績的影響如何? 四、學生對華語閱讀輔助工具的滿意度如何?
第四節 名詞釋義
壹、基模
基模(Schemata)是心理學家 Bartlett 所提出的專有名詞,Bartlett 的定義為 「基模是對於過去反應或經驗的活動性結構(an active organization of past reaction or past experience)」(Bartlett, 1932)。Rumelhart(1977)認為基模是先備知識結構, 所謂的先備知識結構指的是呈現記憶裡的概念時所需要的資料結構。知識結構除 了對象的訊息之外,此知識的運用方法也在內,透過經驗或學習存放在記憶裡的 知識結構即為先備知識結構。 基模可以分成兩種,一種是形式基模(formal schemata)。每篇文章具有固定 的篇章結構(rhetorical structure)以及體裁(genre)等形式上的特徵。我們可以 依據形式上的特徵判斷文章的種類。只要知道文章的種類,我們能夠使用與文章 種類有關的知識,更快速地達成閱讀目標。達成閱讀目標的過程當中我們所使用 的與文章形式有關的知識結構即謂「形式基模」;另一種是內容基模(content schemata),內容基模是與文章內容有關的背景知識結構。與文章的形式無關,讀 者只要具備與文章內容有關的知識,即能更快速地達成閱讀目標,屬於此類型的 知識結構即可謂內容基模。本研究將關注的部分為內容基模與閱讀的關係。
貳、輸入強化
為了讓學習者能夠關注教育目標項目,使用不同的方法操作學習文本或資料, 讓教育目標項目變得更凸顯的教育介入,即謂輸入強化(Smith, 1993)。輸入強化 的方法可以分成兩種(Long, 1990)。一種是「Focus on formS」。Focus on formS 將 意思與形式分開,讓學習者僅關注形式的部分。例如,教師對於語法規則的解釋 屬於 Focus on formS。另一種是「Focus on form」。Focus on form 讓學習者同時關注意思與形式的部分。例如,大劑量輸入(input flood)、輸入處理(input processing)、 文本增顯(textual input enhancement)等皆屬於 Focus on form。本研究將關注的 部分為文本增顯與閱讀的關係。
參、自然語言處理
一、自然語言處理 人類根據已有的知識結構創造的語言叫做「人工語言(constructed language)」。 相對的,人類在日常生活當中使用的語言則稱為「自然語言(natural language)」。 自然語言處理研究的內容是對自然語言加以適當的處理,使電腦理解人類的語言, 實現人與電腦之間的有效溝通。 二、中文斷詞 以空格區分不同獨立詞彙的作業叫作中文斷詞。電腦理解人類語言的作業, 均是由斷詞作業開始,因此自然語言處理領域斷詞作業是一個基本的程序。因為 中文與其他語言不同,詞間沒有留空格,所以在中文自然語言處理領域,斷詞是 既不可缺少也難以實現的作業(Huang, Chen & Chang, 1997)。本研究將關注統計 式斷詞法-圖形理論(graph theory)、隱藏式馬可夫模型(hidden markov model) 與維特比演算法(viterbi algorithm)。三、關鍵詞擷取
關 鍵 詞 擷 取 技 術 是 在 資 訊 檢 索 ( information retrieval )、 文 本 分 類 ( text categorization)、話題檢測(topic detection)、文件摘要(document summarization) 等的文字探勘(text mining)領域裡為了擷取文本的主要屬性而使用的技術方法。 電腦根據特定的模型計算文本中詞彙的重要度,再以重要度的排序決定該文本的 關鍵詞。本研究將關注 TF-IDF 模型(term frequency-inverse document frequency model)。
Python 是在 1989 年由吉多·范羅蘇姆開發的一種物件導向(object-oriented programming)、直譯式(interpreted)電腦程式語言。Python 提供強大的標準程式 庫(standard library)與第三方程式庫(third-party library)。Jieba 即是 Python 第 三方庫的一個模組。它支援中文自然語言處理的斷詞功能以及關鍵詞擷取功能, 適合當作本研究華語閱讀輔助工具之重點開發模組。
第二章 文獻探討
本研究將開發華語閱讀輔助工具,必須按照閱讀理論以及自然語言處理技術 方法設計閱讀輔助工具的各項功能。本章旨在探究設計華語閱讀輔助工具時所使 用的閱讀理論以及自然語言處理技術方法之相關文獻,歸納出工具設計的恰當性。第一節 關鍵詞與閱讀
本節將探討關鍵詞與閱讀之間的關係。若是關鍵詞與閱讀之間有正面關係, 能夠以關鍵詞提示為本研究華語閱讀輔助工具的功能之一。 Cook(1989)表示,人類的心智被關鍵詞句或前後文脈受到激勵之後,啟動 知識基模(the mind stimulated by key words or phrases in the text or by the context activates a knowledge schema)。謝瑜苓(2002)針對在台韓裔兒童進行華語閱讀測 驗,調查如何運用較成熟的自我檢控策略以及閱讀策略。研究結果指出大多數的 外籍兒童在真實閱讀情境中先尋找關鍵字詞,尤其是在閱讀高難度文章的時候尋 找關鍵字詞的情形更普遍。王英君(2000);王佳玲(2001)的研究中表示,國小 學生使用的華語閱讀策略總共為十大類,依使用次數排序為之後發現第二常用的 方法為上下關鍵字,但若其範圍限定為國小閱讀障礙學生的話,上下關鍵字策略 的使用次數最高。李佳蓁,江秋樺(2008)的研究顯示,教師能將關鍵詞或概念 的視覺描述當作前導組體,增強學生的理解。潘冠蓉(2012)的研究探討學生出 題歷程中教師提供關鍵詞與否對於學生公民科學學習成就的影響。研究結果指出, 學生出題提示關鍵詞組與不提示關鍵詞組之間在公民科學習成就以及出題表現 能力上都有顯著性差異,並且前者的成績與表現比後者優越。蔡承勳(2011)應 用 Web2.0 服務發展自動化閱讀輔助系統。系統主要功能為自動判斷出文章的關 鍵字,並且以超媒體註記形式標註在關鍵字旁,以便學生了解關鍵字的意思。研 究結果指出系統對先備知識程度比較中、低能力的學生有顯著的幫助。蘇彥寧, 陳信欽,黃悅民(2013)的研究使用創新閱讀輔助電子書系統,幫助國小學生國語閱讀活動。國小教師在閱讀活動的時候需要強調字詞概念的理解,幫助學生完 成閱讀活動,因此結合電子書與關鍵詞分析技術,主動提供文本關鍵詞給學生參 考。針對 28 名國小學生進行實驗,得知學生對關鍵詞提供功能滿意度頗高,同時 表示高度意願使用中文閱讀輔助系統。白敦文,黃俊穎,張大惠,鄭伯順(1998) 的研究開發比例式分段中文閱讀機,幫助提高一般學生還有學習障礙學生閱讀中 文的速度與理解的能力。在比例式分段中文閱讀機具有分段分詞處理、詞句語音 合成以及關鍵詞圖片提示之功能,受試者皆為腦性麻痺、自閉症病患與學習障礙 學生,接受測試之後發現在短期記憶能力表現上,有明顯的進步,同時回答正確 率也提高了一倍(從 33.0%提升到 60.6%)。 我們藉由這些研究能夠了解關鍵詞提示能夠激勵人類的基模,能夠幫助學生 閱讀行為,並且根據文獻探討得知學生在閱讀的時候願意將關鍵詞當作閱讀策略, 因此本研究華語閱讀輔助工具使用關鍵詞提示功能,幫助學生閱讀華語。
第二節 文本增顯與閱讀
如上所述,為了讓學習者能夠關注教育目標項目,使用不同的方法操作學習 文本或資料,讓教育目標項目變得更凸顯的教育介入,即謂輸入強化(Smith, 1993)。 輸入強化的兩大範疇為透過文本操作實現輸入強化的文本增顯(typographical enhancement)與透過語音操作實現輸入強化的語調強化(intonational enhancement) (Kim, 2003),本節主要探討的內容為前者的文本增顯。壹、文本增顯與閱讀關係之探究
Doughty(1991)在教學英文關係子句(relative clause)的時候將 ESL 成人班 學習者分成兩組。一組在學習過程當中使用文本增顯方法-顏色、底線、加大字 形,另外一組不使用文本增顯方法。最後得到的測驗結果表示不管是內容為主或 是形式為主的測驗,在教學的時候使用文本增顯方法的學生的成績優於不使用的 學生。Jourdenais, Stauffer, Boyson & Doughty(1995)教學西班牙語的未來完成式
時態與過去式時態,將以英文為母語的西班牙語學習者分成兩組,一組在學習過 程中使用文本增顯方法-底線、加大字形、粗體、字形、網底,另外一組不使用 文本增顯方法。最後得到的結果表示使用文本增顯方法的學生對寫作與回想測驗 的成績優於不使用的學生。White(1998)在教學英文所有格(possessive case)的 時候將以法語為母語的 ESL 兒童班學習者分成兩組。一組在學習過程當中使用文 本增顯方法-底線、加大字形、粗體、斜體,另外一組不使用文本增顯方法。研 究結果指出兩組的學生後測的所有格使用次數比前測多,但至於成績的變化,使 用文本增顯方法的受試者群組發生顯著性變化。Wong(2000)教學法語關係子句 的過去時態,使用文本增顯方法-底線、加大字形、粗體、斜體,結果發現文本 增顯對語言形式測驗有明顯的作用,但是至於閱讀內容測驗,學生使用文本增顯 時能夠回想更多的詞彙與話題。Leow(2001)針對以英文為母語的華語學習者進 行命令句教育,使用的文本增顯方法為底線與粗體。他的研究結果表示在教育目 標項目認知、文本理解上使用文本增顯的群組與不使用的群組之間有顯著性的差 異。 我們藉由這些研究能夠了解文本增顯能夠幫助學生閱讀行為,因此本研究 華語閱讀輔助工具使用文本增顯方法之關鍵詞底線標示功能,幫助學生閱讀華 語。
貳、字詞間隔與閱讀關係之探究
除了在上面介紹的文本增顯方法之外,本研究將探究的文本增顯方法為字詞 間隔。中文與英文、韓文不同,一個句子內不同詞彙之間沒有留空格。因此對不 少詞間有空格的母語使用者而言,華語閱讀不是只要知道詞彙的意思就能解決的 事情。例如,學生遇到「把他的確實行動做了分析」這樣的句子時,在它裡面的 「的確實」這一段會有斷詞歧義問題,既可以斷成「的確/實」也可以斷成「的/確 實」。雖然學生都知道「的確」與「確實」的意思,但在閱讀的時候仍然會遇到這種二選一的判斷問題。若是像詞間有空格的母語,一開始就用空格標示各個不同 的詞彙,能夠使讀者直覺地解決歧義段落的問題。
Sainio, Hyönä, Bingushi & Bertram(2007)根據受試者的動眼狀況判斷日文閱 讀(日文與中文同樣地詞間沒有空格)的效率程度。所謂的動眼狀況,閱讀時讀 者的眼珠沿著文本的行列延續地轉動,並且在轉動眼珠的時候一處一處地掃視。 他們總共測驗四種句子,第一種為斷詞的平假名(hiragana)句子(簡稱 HSP), 第二種為沒有斷詞的平假名句子(簡稱 HUSP),第三種為斷詞的平假名與片假名 (katakana)的混合句子(簡稱 KSP),第四種為沒有斷詞的平假名與片假名的混 合句子(簡稱 KUSP)。研究結果表示 HSP 比 HUSP 閱讀速度(reading rate = words / min)快,並且注視(fixation)次數也比較低。Hsu & Huang(2000)將中文句 子設計成三類,第一類為詞間沒有空格的傳統式句子,第二類為每個字間加空格 的句子,第三類為詞間加空格的句子。研究結果受試者的閱讀速度最快的是第三 類,速度最慢的是第一類。答對率最高的是也第三類,最低的是第二類,由此可 知,詞間留空格的句子對閱讀皆有幫助。Bai, Yan, Liversedge, Zang & Rayner(2008) 將中文句子設計成五類,前三類與 Hsu & Huang(2000)的一樣,後兩類為每個 字間加標籤與詞間加標籤。透過動眼測試得到的結果指出無論是空格或是標籤, 以詞為單位的句子閱讀速度最快。Bassetti(2009)研究將中文句子設計成四類, 第一類為詞間沒有加空格的羅馬拼音句子,第二類為詞間加空格的羅馬拼音句子, 第三類為詞間沒有加空格的漢字句子,第四類為詞間加空格的漢字句子。施測對 象為國外華語學習者與中國人。透過圖片連結測驗得到的研究結果表示對華語學 習者而言,無論羅馬拼音句子或是漢字句子只要詞間加空格的話,能夠提高閱讀 速度。但對中國受試者而言,羅馬拼音句子詞間加空格與沒有加空格在閱讀速度 上沒有顯著性的差異,至於漢字句子,在詞間加空格的時候閱讀速度比較快。 我們藉由這些研究能夠了解詞間留空格對閱讀速度與閱讀測驗表現皆有提 升的效果,因此本研究華語閱讀輔助工具使用在不同詞彙之間留空格的功能,幫
助學生閱讀華語。
参、視覺輔助與閱讀關係之探究
本研究亦探究的文本增顯方法為視覺輔助中的圖片註解方法。曾有不少研究 者為了證明一句「一張圖勝過一千個詞(A picture is worth a thousand words)」而 進行研究。Al-Seghayer(2001)針對 30 名 ESL 學生進行詞彙測驗。首先將英文 文章設計成三類,第一類為文章用文字註解,第二類為文章用圖片註解,第三類 為文章用影片註解,最後讓學生閱讀不同設計類型的英文文章進行測驗。測驗結 果表示在詞彙測驗、表達能力測驗與滿意度調查上閱讀影片註解文章的學生表現 最佳,其次是圖片註解,文字註解方式的學生表現最差。李正聖 ( 2005 )的研究 針對中下科學文章閱讀能力的學童,進行閱讀理解測驗,實驗組在閱讀文章前閱 讀圖形式前導組體。分析測驗結果得知,實驗組的閱讀理解力會明顯優於未閱讀 前導組體者(F(2,9)= 5.41, P< .05)。也就是說,圖形前導組體對中下科學文章閱 讀理解能力之六年級學童,在文章閱讀理解上有明顯幫助。李雅惠 ( 2006 )的研 究針對國中八年級學生進行國文閱讀理解測驗,了解構圖教學法對學生國文閱讀 理解能力的影響,結果顯示構圖教學法在國文閱讀理解能力上有顯著影響(t= .256,
p< .05)。Carol, Holly, Cathleen & Steven(2011);Yeh & Wang(2003);Farley, Pahom & Ramonda(2014)的研究與 Al-Seghayer(2001)相似,表示包括圖片提 示方式的多媒體註解有助於提高學生對學習的興趣及效果。 我們藉由這些研究能夠了解視覺輔助教學措施能夠幫助學生閱讀行為,因此 本研究華語閱讀輔助工具使用圖片提示功能,幫助學生閱讀華語。
第三節 應用自然語言處理技術之 Python 模組
我們在第二節探究了對學生華語閱讀有幫助的兩個因素。第一、關鍵詞提示 能夠激勵學生的內容基模,以幫助華語學習者的閱讀華語。第二、文本增顯-劃 底線、詞間留空格、加圖片註解的方法能夠幫助學生的華語閱讀。接下來要關注的內容是如何將能夠幫助學生閱讀華語的因素實現在華語閱讀輔助工具內。如上 所述,本研究在開發閱讀輔助工具的時候主要使用 Python 第三方程式庫的 Jieba 中文自然語言處理模組。因此本節將探討的自然語言處理技術範圍限 Jieba 模組 採用的技術。Jieba 模組能夠在 Github 網站(https://github.com/fxsjy/jieba)下載使 用,並且公開其原始碼,以便了解模組運作原理或者自行編輯。
壹、自然語言處理技術-Jieba 模組的中文斷詞
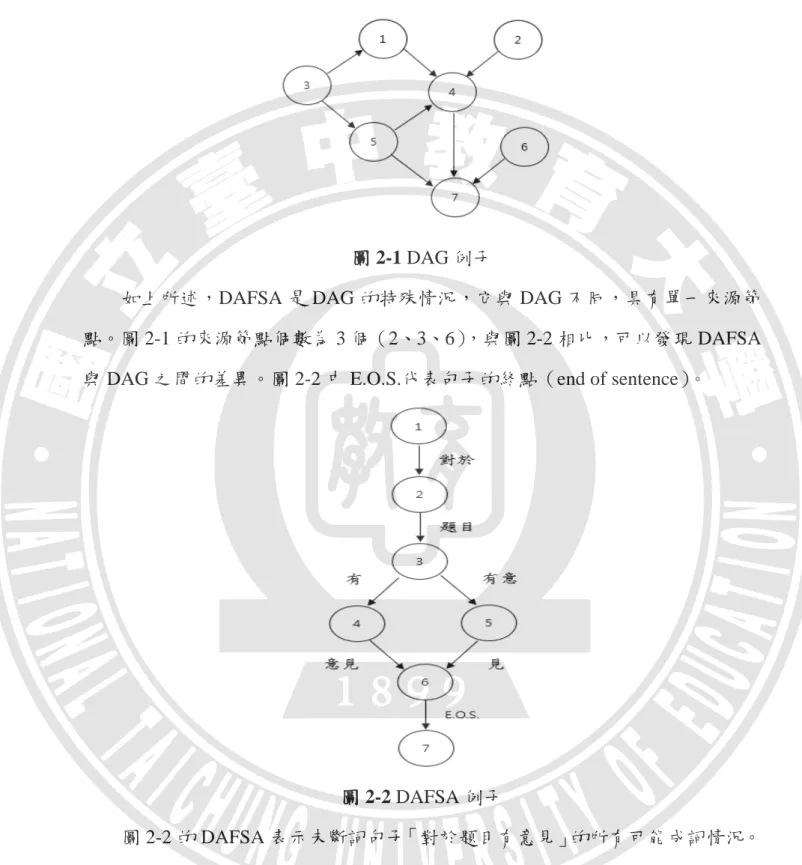
在不同詞彙之間留空格是本研究華語閱讀輔助工具的主要功能之一。為了實 現此功能,必須使用自然語言處理的中文斷詞技術。本研究將使用 Python 的 Jieba 自然語言處理模組實現中文斷詞,其簡單的程序如下: 第一、使用字典樹(trie)結構快速地產生未斷詞句子的決定型非循環有限狀 態機(deterministic acyclic finite state automaton;簡稱 DAFSA)。第二、根據語料 庫詞頻訊息,求得 DAFSA 內每個成詞情況的機率值,採用動態規劃法(dynamic programming)查找未斷詞句子的最佳成詞情況,完成初步的斷詞作業。第三、至 於不存在語料庫中的未知詞處理,使用隱藏式馬可夫模型(hidden markov model; 簡稱 HMM)與維特比演算法(viterbi algorithm),完成最終的斷詞作業。接下來我們仔細地了解每個步驟的斷詞處理過程以及相關理論。 一、Jieba 模組中文斷詞處理的第一步驟
在第一步驟 Jieba 模組首先產生未斷詞句子的 DAFSA,句子的 DAFSA 表示 未斷詞句子中所有可能成詞的狀況,DAFSA 是圖形理論中的有向非循環圖形 (directed acyclic graph;簡稱 DAG)之特殊情況。DAG 與資料結構相關,它由 「節點(node)」與「分支(branch)」兩個要素組成,DAG 的邊具有方向性但並 沒有循環性,能夠釐清每個節點之間的先後關係(Jørgen, 2008)。如圖 2-1,節點 7 號與節點 4、5、6 號的關係很明確,因為它們之間的分支以箭頭形式表示方向, 所以我們能夠得知先處理節點 4、5、6 號之後再處理節點 7 號。
圖 2-1 DAG 例子
如上所述,DAFSA 是 DAG 的特殊情況,它與 DAG 不同,具有單一來源節 點。圖 2-1 的來源節點個數為 3 個(2、3、6),與圖 2-2 相比,可以發現 DAFSA 與 DAG 之間的差異。圖 2-2 中 E.O.S.代表句子的終點(end of sentence)。
圖 2-2 DAFSA 例子
圖 2-2 的 DAFSA 表示未斷詞句子「對於題目有意見」的所有可能成詞情況。 到這裡我們會有疑惑,Jieba 模組判斷成詞與不成詞的標準是什麼?Jieba 模組使 用內建詞典,詞典共計兩萬多個詞彙,並且詞典將詞彙在語料庫(Jieba 模組使用 中國人民日報語料庫)內出現的次數與它的詞性也包含在內,但如果每次判斷未
斷詞句子之成詞狀況時,一一查找詞典內所有詞彙,最差時間複雜度(worst case time complexity)即為系統查找詞典內所有詞彙的時間。因此 Jieba 模組採用字典 樹結構,將內建詞典的所有詞彙重新排列,以便縮短系統在判斷未斷詞句子之成 詞狀況時所需要的時間,快速地產生未斷詞句子的 DAFSA。所謂的字典樹結構 (Fredkin, 1960)是一種電子詞典的資料組織方式(Kim, 1994),理論上檢索速度 與詞典的詞彙數量沒有密切的關係,主要依靠要檢索的目標詞彙的字數。如圖 2-3,若是系統在兩萬字詞典裡查找「中華民國」的話,字典樹結構不需要一一查找 所有詞彙,首先檢索字典樹結構的前綴字「中」,其次是檢索在「中」分支下的 「華」,再次是檢索「中華」分支下的「民」,最後檢索在「中華民」分支下面的 「國」。 圖 2-3 字典樹例子 藉由圖中的例子,我們能夠了解 Jieba 模組如何根據字典樹結構減少產生未 斷詞句子 DAFSA 的時間複雜度,它僅需要系統查找屬於共同前綴分支的詞彙的 時間,圖 2-3 中 E.O.W.代表詞彙的終點(end of word)。
二、Jieba 模組中文斷詞處理的第二步驟 Jieba 模組在第一步驟產生了未斷詞句子的 DAFSA,DAFSA 的不同「節點」 之間有不同的「分支」,因此我們在很多條分支中要尋找最佳路徑。在未斷詞句子 的 DAFSA 裡能夠求得最佳分支集合,即等於成功地找到未斷詞句子的最佳成詞 情況。 Jieba 模組採用動態規劃法尋找最佳分支集合,動態規劃法是由 Rechard Bellman 在 Rand 研發公司開發的演算法設計方式(Bellman, 1954 ; Dreyfus, 2002)。 主要想法為首先求出在每個階段的最佳解之後,將它當作一個集合元素,求出所 有階段的最佳解之後,將所有的元素加入至同一個集合中,最後得到的集合即為 動態規劃法之最佳解。我們透過圖 2-4 的例子可以了解動態規劃法。 圖 2-4 動態規劃法例子 如圖 2-4,動態規劃法由「節點」與「分支」兩個要素組成,由起始節點(0, 0) 到終結節點(3, 0)必須經過每個階段的不同節點之一,在圖 2-4 方塊內部括號的數 字依照順序表示階段(Stage)與位置(State),箭頭上的數字表示對於移動至下 一個階段的節點所需要的經費(Cost)。例如我們要求出的最佳解是最高經費的集 合,從起始節點(0, 0)到在 i 階段 j 位置節點(i, j)的最高經費命名為 Cost(i, j),那麼
計算 Cost(i, j)的公式如下:
Cost(i, j) = max { c(k, l, i, j) + Cost (k, l) } (1) 其中 k 表示 i-1 階段,l 表示 k 階段的位置,c(k, l, i, j)表示從 k 階段 l 位置節 點(k, l)到 i 階段 j 位置節點(i, j)的經費。我們根據圖 2-4 計算 Cost(i, j)如下:
Cost(1, 0) = 2 Cost(1, 1) = 5 Cost(1, 2) = 4
Cost(2, 0) = max{5+ Cost(1, 0), 11+ Cost(1, 1) , 7+ Cost(1, 2)} = 16 Cost(2, 1) = max{1+ Cost(1, 0), 8+ Cost(1, 1) , 3+ Cost(1, 2)} = 13 Cost(2, 2) = max{3+ Cost(1, 0), 6+ Cost(1, 1) , 9+ Cost(1, 2)} = 13 Cost(3, 0) = max{8+ Cost(2, 0), 3+ Cost(2, 1) , 2+ Cost(2, 2)} = 24
從計算結果我們得知圖 2-4 的最佳路徑為(0, 0)→(1, 1)→(2, 0)→(3, 0),並且 在每個階段最高經費的總和為 24,因為動態規劃法的最佳解值等於由起始節點到 終結節點的最佳經費之總和,因此圖 2-4 的最佳解值即為 24。 回到 Jieba 模組,在未斷詞句子的 DAFSA 裡面存在著不同的「節點」與「分 支」,我們在圖 2-4 例子裡,在算 Cost(i, j)的時候使用的每個分支上的數值是任意 賦予的,但在 Jieba 模組裡的 Cost(i, j)不能任意計算,它使用根據語料庫詞頻的計 分公式,針對每個分支賦予一個分數。Jieba 模組使用的計分公式(2)如下: 𝑆𝑆𝐵𝐵𝐵𝐵= log𝑓𝑓𝑓𝑓𝑤𝑤𝑡𝑡 (2) 其中,𝑆𝑆𝐵𝐵𝐵𝐵代表第 i 個分支 Bi的分數;𝑓𝑓𝑤𝑤代表在分支 Bi上的字詞 w 在語料庫 內出現的次數;𝑓𝑓𝑡𝑡代表語料庫內所有字詞出現次數的總和。 接下來按照動態規劃法選擇在每個階段得分最高的分支,找出所有階段的最高 得分之分支後,將分支元素加入至同一個集合中,最後得到的集合即為未斷詞句 子的最佳路徑,所謂的最佳斷詞情況,到此完成了初步斷詞作業。 三、Jieba 模組中文斷詞處理的第三步驟 透過第一、二步驟得到了初步斷詞的結果,但在那兩個階段我們僅使用中國
人民日報語料庫與內存詞典進行中文斷詞處理,因此若是不存在語料庫與詞典中 的詞彙出現在未斷詞句子裡的話,有可能得到不正確的斷詞結果。在第三步驟 Jieba 模組會處理未知詞問題,完成中文斷詞作業,模組採用隱藏式馬可夫模型 (HMM)以及維特比演算法(viteribi algorithm)解決未知詞問題。在此將探討 HMM 與維特比演算法。 HMM 從馬可夫鏈(markov chain)發展出來的統計模型,馬可夫鏈假設時間 t上的變量只會受到離時間 t 之前 r 個變量的影響,以數學方式表示如下: 如果 r = 0,即為 0 次馬可夫鏈,P(ot | ot-1 ot-2…o1) = P(ot)
如果 r = 1,即為 1 次馬可夫鏈,P(ot | ot-1 ot-2…o1) = P(ot | ot-1) (3)
如果 r = 2,即為 2 次馬可夫鏈,P(ot | ot-1 ot-2…o1) = P(ot | ot-1, ot-2)
HMM 的母的為表示隱藏著的狀態(hidden states)與觀察到的變量(observable states)之間的關係,由不同狀態間的轉移機率(transition probability)與每個狀態 的放射機率(emission probability)、初始狀態機率(initial state’s probability)之三 個因素組成(Miller et. al., 1999)。簡單而言,HMM 即為根據觀察值,估計三個 主要機率因素的最佳化作業(Il-Seok Oh, 2008),以數學方式表示如下: Θ= ( A, B,π) (4) 其中 A 代表轉移機率向量,B 代表放射機率向量,π代表初始狀態機率向量。 轉移機率向量以「A = | aji |」符號表示,aji代表在時間 t-1 上的狀態 sj轉移至 在時間 t 上的狀態 si的機率,以數學方式表示如下: aji = P(qt = si | qt-1 = sj), 1≦j, i≦n,∑ 𝑎𝑎𝑛𝑛𝐵𝐵=1 𝑗𝑗𝐵𝐵 = 1 (5) 其中 n 代表所有狀態 s 的數量,qt代表隨機變數,其主要功能為儲存在時間 t 上的狀態 si,qt-1也代表隨機變數,其主要功能為儲存在時間 t-1 上的狀態 sj。 放射機率向量以「B = | bi(vk) |」符號表示,bi(vk)代表可觀察到的變量 vk在 狀態 si裡出現的機率,以數學方式表示如下: bi(vk) = P(ot = vk | qt = si ), 1≦i≦n, 1≦k≦m,∑𝑚𝑚𝑘𝑘=1𝑏𝑏𝐵𝐵(𝑣𝑣𝑘𝑘) = 1 (6)
其中 ot代表隨機變數,其主要功能為儲存最後在時間 t 上觀察到的 vk,m 代 表所有可觀察到的變量 v 的數量。 初始狀態機率向量以「π= |πi |」符號表示, HMM 根據π決定從哪一個狀 態開始啟動,πi表示從狀態 Si開始的機率,以數學方式表示如下: πi = P(qi = si ), 1≦i≦n,∑ 𝜋𝜋𝑛𝑛𝐵𝐵=1 𝐵𝐵 = 1 (7) 若是已經得知上述的三個主要因素-轉移機率、放射機率、初始狀態機率的 值,接著根據我們所知道的模型Θ與觀察值的向量 O= (o1, o2, …, oT)推論最佳的 狀態向量 Q= ( q1, q2, q3, …,qT),即在各種候選狀態向量當中選擇機率值最高的 最佳化問題,叫作解碼(decoding),到這裡我們需要使用維特比演算法。 如上所述,維特比演算法的目的在於求解最佳化問題,即在已經得到觀察到 一連串變量的情況下找出具有最高出現機率的狀態向量。維特比演算法屬於我們 在上面已經探討過的動態規則法(McCallum et. al., 2000),因此此演算法與動態 規則法其邏輯大同小異。 先命名一個隨機變量χt(i)-用於儲存 HMM 流程到時
間 t 上狀態 si的時候觀察到一個變量 ot的最高機率路徑,以數學方式表示;
χt(i) = [ maxχt-1(j)aji ]*bi(ot),2≦t≦T, 1≦i≦n
χ1(i) =πibi(o1),1≦i≦n (8)
τt(i) = argmax[χt-1(j)aji ],2≦t≦T, 1≦i≦n
其中χ1(i)表示第一次經過轉移之後的最高機率路徑,τt(i)用於儲存在時間 t-1 上 n 個狀態中,因具有最高機率值而被選擇的狀態。 解碼過程即為得到所有的τ之後,將在時間 T 上的最高機率狀態τ轉換為 𝑞𝑞�𝑇𝑇,然後按照順序追蹤每一個τ,最後能夠找到最佳路徑向量 𝐐𝐐� = (𝑞𝑞�1, 𝑞𝑞�2…, 𝑞𝑞�𝑇𝑇), 到此所有過程即為維特比演算法,以數學方式表示; 𝑞𝑞�𝑇𝑇 = argmaxχT(j) 𝑞𝑞�𝑡𝑡 =τt+1(𝑞𝑞�𝑡𝑡),t = T-1, T-2, …,1 我們可以用圖 2-5 的例子了解維特比演算法,圖片 2-4 如下: (9)
圖 2-5 HMM 維特比演算法例子 再回到 Jieba 模組斷詞作業了解維特比演算法,假設有未斷詞句子「我在網 路上觀看善與惡之戰」,「善與惡之戰」是一部電影的題目,但若是在語料庫內沒 有「善與惡之戰」這條名詞,初步斷詞結果可能為「我/在/網路/上/觀看/善/與/惡 /之/戰/」。Jieba 模組針對一個字一個字地切割的段落使用 HMM 與維特比演算法 加以修正式斷詞處理。在圖 2-5 的例子裡「善/與/惡/之/戰」為觀察到的變量 o, 被隱藏著的狀態 s 為 B(詞的開始:begin of word)、M(詞的中間:middle of word)、 E(詞的結束 end of word)、S(一個字的詞 single letter word)四種。如上所述, HMM 以三個機率-轉移機率、放射機率、初始狀態機率表示觀察到的變量與被 隱藏著的狀態之間的關係,因此在 Jieba 模組裡面內存了三個「.py」檔案- prob_trans.py, prob_emit.py, prob_start.py 已經定義好公式(4)的Θ參數 A、B、 π,模組在估計參數的時候利用中國人民日報語料庫。參數估計已經完成,因此 省下的步驟是根據Θ參數建構「善與惡之戰」之 HMM(如圖 2-5),然後利用公 式(8)、(9)的維特比演算法找出最高機率的斷詞情況,例如我們最後得到的最 佳路經向量𝐐𝐐� = (B, M, M, M, E),那麼模組將初始斷詞結果「善/與/惡/之/戰」修 正為「善與惡之戰」,然後終結所有斷詞作業。因為具體的計算過程與圖 2-5 動態
規劃法的計算例子類似,所以在本節用直覺性的說明取代了其計算過程。
貳、自然語言處理技術-Jieba 模組的關鍵詞擷取
從閱讀文章裡面擷取關鍵詞之後給學生提供該關鍵詞圖片,同時在文章中的 每個關鍵詞下面劃條底線是本研究華語閱讀輔助工具的主要功能之二,實現此功 能的關鍵技術為自然語言處理的文字探勘技術,特別是關鍵詞擷取。隨著網路上 電子文件數量的增加,以有效率地檢索為目的的關鍵詞擷取研究也越來越受到重 視,也有各種研究介紹不同的關鍵詞擷取方法-利用字詞共同出現(word co-occurance)統計資訊的方式(Matsuo, Ishizuka, 2003)、利用網頁排名(page rank) 的方式(Wang et. al., 2007)、利用支持向量機(support vector machine)的方式(Yu et. al., 2006)、利用神經網路(neural network)的方法(Taeho Jo et. al., 2006)、利 用 TF-IDF(term frequency - inverse document frequencey)加權技術的方法(Juanzi Li, 2007)等。Jieba 模組在擷取關鍵詞的時候使用的方法為 TF-IDF 加權方法,因 此我們在這裡要探討的是 TF-IDF 加權法。 TF-IDF 加權法評估在文本內詞彙之間相對的重要性,TF-IDF 值高的詞彙代 表它所屬的文章內容以及主題的機率高,因此我們可以將該詞彙當作文章的關鍵 詞。如公式(12),TF-IDF 加權值等於將 TF 值乘以 IDF 值的結果,TF 值代表特 定詞彙出現在同一個文章內的頻率,在計算關鍵詞加權的時候利用詞彙出現頻率 的根據為反映越重要的詞彙在文章內出現的次數也越多的假設,因此如公式(10), TF 值的計算方法為將特定詞彙出現的次數除以所有詞會出現的次數。但擷取關 鍵詞時若是僅考慮 TF 值,會犯選擇無意義高頻詞的錯誤,例如在文章中「我們、 的、在、了」等的詞彙雖是出現次數頗高,但它們並不代表此文章的內容與主題, 因此為了避免發生這種問題,擷取關鍵詞時考慮 IDF 值。如公式(11),IDF 值的 計算方法為將語料庫的所有文章數量除以包含特定詞彙的文章數量,因此在所有 文章裡出現次數高的詞彙之 IDF 值比較低,但是相對的,在特定主題的文章內出現次數才會高的詞彙之 IDF 值比較高,如上所看到的,IDF 值告訴我們該詞彙是 無法代表文章內容的普遍高頻詞或是能夠代表文章內容的特殊高頻詞,TF-IDF 加 權法公式如下: tfi,j = 𝑛𝑛𝑖𝑖,𝑗𝑗 ∑ 𝑛𝑛𝑘𝑘 𝑘𝑘,𝑗𝑗 (10) idfi = log |𝐷𝐷| |{𝑑𝑑𝑗𝑗|𝑤𝑤𝑗𝑗∈𝑑𝑑𝑗𝑗}| (11)
TFIDFi,j = tfi,j * idfi (12)
其中 ni,j表示詞彙 wi出現在文章 dj的次數,∑ 𝑛𝑛𝑘𝑘 𝑘𝑘,𝑗𝑗表示在文章 dj裡所有詞彙 出現的次數,|D|表示在語料庫內所有文章的數量,|{dj|wj∈dj}|表示包含詞彙 wj的 文章 dj的數量。 總而言之,TF-IDF 加權法以在文章裡面出現的頻率高並且在其他文章裡面出 現的次數少的詞彙當作關鍵詞,本研究的華語閱讀輔助工具採用 TF-IDF 加權法 找出閱讀文章內的關鍵詞,然後以提供圖片與劃底線的文本增顯方法幫助華語學 習者閱讀華語。
第三章 研究方法
本研究的主要目的是開發應用自然語言處理技術之華語閱讀輔助工具,並且 驗證該工具對學生閱讀華語的輔助成效。基於本研究的目的做研究設計,在本章 主要說明的內容為研究流程、華語閱讀試題設計、華語閱讀輔助工具介紹、華語 閱讀輔助工具實地實驗、實地實驗問卷設計、統計分析,總共分六節,說明如下:第一節 研究流程
本研究以開發適用自然語言處理技術之華語閱讀輔助工具為重點,為了驗證 其成效,需要針對華語學習者進行華語閱讀測驗以及問卷調查,最後根據測驗與 問卷調查之分析結果,探討華語閱讀輔助工具對於提升華語學習者閱讀華語之成 效以及對於不同華語程度學生與不同母語學生閱讀測驗表現之成效。本研究的流 程如圖 3-1 所示: 圖 3-1 研究流程第二節 華語閱讀試題設計
為了驗證華語閱讀輔助工具之成效,需要針對在學習華語的外國學生進行閱 讀測驗,因此請一位華語教育專家(文藻外語大學應用華語文系畢業;2012 年 9 月~2014 年 6 月任教於越南順化外國語大學中文系)編製三份複本閱讀測驗(A、 B、C 測驗),每份測驗有 5 篇文章與 20 個題目。更具體的試卷狀況如表 3-1: 表 3-1 華語閱讀試題設計狀況 試卷分類 主 題 內 容 字 數 難 度 A 試卷 20 題 介紹台灣 台灣的氣候 293 字 下 傳統節日 春節 383 字 中 台灣景點 承載著滿滿願望的天燈-平溪 473 字 上 傳統節日 中秋節的由來 327 字 上 介紹台灣 水果王國 245 字 下 B 試卷 20 題 台灣景點 夏天的好去處 370 字 下 介紹台灣 台灣的交通 412 字 上 傳統節日 第二個情人節 338 字 上 台灣景點 到阿里山坐小火車 356 字 下 介紹台灣 地方名產有哪些? 340 字 中 C 試卷 20 題 傳統節日 清明節掃墓 258 字 下 台灣景點 到貓空坐纜車 314 字 中 介紹台灣 一定要逛的台灣夜市 411 字 上 傳統節日 為什麼在端午節要吃粽子? 224 字 下 台灣景點 故宮博物院 403 字 上 若是每份測驗的主題、難度與總字數都相差太大的話,學生的測驗結果因測驗種類而有所不同,因此編製測驗時各測驗的主題都一樣,以介紹臺灣、傳統節 日、臺灣景點三種主題組成。並且以測驗文章的詞彙、語法與字數為決定測驗難 度的標準,將「實用視聽華語第 3 冊」的詞彙與語法作為中級難度,在每份試卷 內均有兩篇初級的文章、一篇中級的文章、兩篇高級的文章。雖是 A 測驗與 B、 C 測驗閱讀文章的細節主題狀況稍微不一致,但是大體上傳統節日、台灣景點等 主題皆屬於介紹台灣,並且 A 測驗是前測,其目的為確認隨機分配的兩組學生能 力之間沒有差異,與 B、C 測驗的目的不一樣,因此我們可以接受 A 測驗與 B、 C 測驗閱讀文章的細節主題狀況不一致的問題。
第三節 華語閱讀輔助工具介紹
本研究的華語閱讀輔助工具用 Python 程試語言編寫,華語閱讀輔助工具主要 使用第三方庫的模組像 Jieba、beautifulsoup、wxpython,使用 Jieba 模組進行中文 自然語言處理-中文斷詞、關鍵詞擷取,使用 beautifulsoup 從網路上抓取圖片, 使用 wxpython 在 windows 平台上呈現 Python 程式碼的 GUI(graphical user interface)。如上所述,本研究華語閱讀輔助工具之功能有三項-不同詞彙之間留 空格、提供學生擷取的關鍵詞以及其圖片、在顯示的文章內用底線標示關鍵詞, 華語閱讀輔助工具之操作說明與相關圖片如下: 一、不需要提前安裝任何軟體,直接點開 AppGUI.exe 檔案,華語閱讀輔助工具 開始運作,出現兩個視窗。 圖 3-2 華語閱讀輔助工具開始運作的畫面二、複製想要分析的文章之後,貼進去 AppFrame 視窗裡面,再按「開始」鍵。 圖 3-3 操作文章分析的畫面 三、華語閱讀輔助工具分析完成後透過顯示視窗提供分析的結果,結果顯示視窗 總共分成兩個部分,第一部分為顯示關鍵詞以及它的圖片,一次最多提供 6 個關 鍵詞,如果關鍵詞數量超過 6 個或者沒有圖片的關鍵詞,華語閱讀輔助工具將不 會顯示在結果視窗內,若是關鍵詞數量不到 6 個的情況,華語閱讀輔助工具將只 會顯示已經擷取的關鍵詞與其圖片。 圖 3-4 結果顯示視窗的第一部分
四、華語閱讀輔助工具透過顯示視窗提供分析的結果,結果顯示視窗之第二部分 為顯示經過詞間留空格處理以及關鍵詞底線標示處理之後的文章。 s 圖 3-5 結果顯示視窗的第二部分
第四節 華語閱讀輔助工具實地實驗
本研究採用交叉實驗設計法,將 76 名受試者隨機分配成兩組,所有受試者 接受三種不同測驗,其中第一次測驗時兩組學生都在不使用工具的情況下接受 A 測驗,第二次測驗與第三次測驗時第一組學生與第二組學生將使用華語閱讀輔助 工具與不使用華語閱讀輔助工具的兩個條件交叉著進行測驗,第二次測驗時第一組 學生不使用華語閱讀輔助工具的情況下考 B 測驗;第二組學生則使用華語閱讀輔助工 具,第三次測驗時第一組學生使用華語閱讀輔助工具的情況下考 C 測驗;第二組學生則 不使用華語閱讀輔助工具。最後完成所有測驗之後,針對受試者進行華語閱讀輔助工具 實地實驗經驗之問卷調查,確認受試者對於華語閱讀輔助工具各項功能的滿意度 狀況,華語閱讀輔助工具實地實驗設計所示如下:表 3-2 華語閱讀輔助工具實地實驗設計 A 測驗 B 測驗 輔助工具 使用與否 C 測驗 輔助工具 使用與否 問卷調查 第一組 前測 後測 不使用 後測 使用 調查 第二組 前測 後測 使用 後測 不使用 調查
壹、研究樣本
以臺中市區三間大學-臺中教育大學、逢甲大學、東海大學附設華語教學 中心的外國學生為施測對象,受試者的華語文水準均為「實用視聽華語第二 冊」以上,按照正在學習的課本階段分類學生的華語程度背景,正在學習「實 用視聽華語第 2 冊」學生的華語程度背景分類成初級;正在學習「實用視聽華 語第 3 冊」學生的華語程度背景分類成中級;正在學習「實用視聽華語第 4 冊」學生的華語程度背景分類成高級,因此本研究受試者的華語程度背景共有 初、中、高級的三個程度。樣本數量原本共計 91 人,但是有些受試者僅參加部 分測驗,因此到最後能夠使用的樣本數量共計 76 人。受試者依程度分類,初級 學生人數為 27 人;中級學生人數為 24 人;高級學生人數為 25 人,並且根據使 用的母語特徵分類,不同詞彙之間留空格的母語(如英文、韓文、越南語等) 學生組的人數為 44 人,不同詞彙之間沒有留空格的母語(如日文、泰文)學生 組的人數為 32 人。進行測驗時將 76 名受試者隨機分配成第一組與第二組,兩 組的學生人數各為 38 人。貳、施測流程
一、第一次測驗時不使用電腦與華語閱讀輔助工具,兩組學生同時接受 A 測 驗,測驗時間為 50 分鐘,前十分鐘簡單地介紹整體實驗的流程,剩下的 40 分 鐘進行施測。二、從第一次測驗結束之隔週開始進行第二次測驗,受試者進入電腦教室之後 說明測驗流程以及華語閱讀輔助工具的使用方法,說明時間為 10 分鐘。 三、說明結束之後開始施測,兩組學生同時接受 B 測驗,但第一組學生不使用 華語閱讀輔助工具;第二組學生則使用華語閱讀輔助工具,施測時間為 40 分 鐘。 四、中場休息後,進行第三次測驗,受試者進入電腦教室之後提醒學生第三次 考試時交叉條件,兩組學生同時接受 C 測驗,但第一組學生使用華語閱讀輔助 工具;第二組學生則不使用華語閱讀輔助工具,施測時間為 40 分鐘。 五、C 測驗結束後,主試者請受試者填寫華語閱讀輔助工具實地實驗經驗問卷 調查,過 10 分鐘後結束所有華語閱讀輔助工具實地實驗流程。
第五節 華語閱讀輔助工具滿意度調查問卷
本研究基於李克特量表(Likert scale)做調查問卷,李克特量表用在測量個 人對於某一個對象的態度。為了以數字表示個人對於某一個對象的態度狀況,李 克特量表採用多項選擇題的形式,每個選項代表一個態度,從第一個選項到最後 一個選項,每個互相對稱的選項組合具有正相反的態度屬性。 本研究採用李克特五點量表測量學生對華語閱讀輔助工具各項功能的滿意 度,問卷內的每個問題帶有五個選項,並且第一選項與第五選項,第二選項與第 三選項為互相對稱的組合,因此它們代表的態度屬性也要正相反。如上所述,本 問卷的目的為測量學生對華語閱讀輔助工具的滿意度,換句話說,若是華語閱讀 輔助工具能夠幫助學生的華語閱讀,即學生對華語閱讀輔助工具的滿意度高,相 反的,若是輔助工具對於學生華語閱讀沒有幫助,即學生對華語閱讀輔助工具的 滿意度低,最後做出來的五等選項如下: 一、幫助很多(Very helpful) 二、有幫助(Helpful)三、普通(Average)
四、幫助很少(Not very helpful) 五、沒有幫助(Not helpful) 本問卷題目共有六題,其中五項為了解學生對於華語閱讀輔助工具每項功能 的經驗感受,最後一項題目為了解學生對於華語閱讀輔助工具的滿意程度,問卷 內容詳見附錄二。
第六節 統計分析
所有施測流程結束,將原始資料輸入電腦並進行統計分析,在本節介紹分析 資料時所使用的統計方法,分析測驗信度時使用 Cronbach’s Alpha 係數與 Pearson 相關係數,分析測驗與調查問卷結果時主要使用描述性統計分析、獨立樣本 t 檢 定、重複樣本 t 檢定、雙因子變異數分析、單因子變異數分析。 如上所述,本研究的第一個問題為華語閱讀輔助工具對華語學習者閱讀華語 的成效為何,為了回答此問題,我們將要比較學生不使用華語閱讀輔助工具的情 況下得到的閱讀測驗結果與在使用華語閱讀輔助工具的情況下得到的閱讀測驗 結果。但是交叉實驗設計的特點,將整體受試者隨機分配成兩組,並且兩組學生 在不同的條件下接受華語閱讀測驗,因此需要確認兩組學生能力沒有顯著差異之 後,再透過重複樣本 t 檢定探討華語閱讀輔助工具對華語學習者閱讀華語之成效。 至於第二個研究問題,因為不同華語程度學生測驗成績無法滿足組內變異數 同質性假設,所以透過無母數檢定的 Mann-Whitney 方法,檢視在初、中、高級 三等不同華語水準學生組內不使用華語閱讀輔助工具與使用華語閱讀輔助工具 之成績是否有差異。最後透過以華語程度為單因子的變異數分析,探討閱讀測驗 成績變化程度在不同華語水準的學生組間是否有差異。 至於第三個研究問題,透過以不同母語特徵與華語閱讀輔助工具使用與否為 雙因子的變異數分析,檢視母語特徵、華語閱讀輔助工具使用與否對學生華語閱讀測驗分數引起的效果以及兩個主因子交互作用是否對測驗分數有影響。接著進 行以華語閱讀輔助工具使用與否為單因子的變異數分析,檢視在兩種不同母語組 內不使用華語閱讀輔助工具與使用華語閱讀輔助工具之測驗成績是否有差異。
至於第四個研就問題,採用李克特五點量尺設計問卷,使用描述性統計分析, 敘述學生對於華語閱讀輔助工具與其各項功能的滿意度。
第四章 研究結果與討論
本章旨在分析華語閱讀測驗結果與實地實驗問卷調查之回答,以了解華語閱 讀輔助工具對於華語學習者閱讀華語的影響以及學生對華語閱讀輔助工具的態 度。 首先要確認在測驗內是否有與測驗目的無關的試題,進行統計分析之前排除 具有問題的資料,即能得到可靠度更高的分析結果,因此基於 Cronbach’s Alpha 係數法檢視每份測驗與調查問卷試題的內容一致性程度。並且本研究施測時採用 交叉實驗設計法,受試者接受三份複本測驗,因此需要分析 A、B、C 測驗之間的 Pearson 積差相關係數,檢視複本信度(parallel-form reliability),判斷三份測驗是 否具備 恰當 的同質 性。分 析結 果得知 ,三份 華語 閱讀測 驗以及 調查 問卷 之 Cronbach’s Alpha 係數介於.78 ~ .864,顯示所編製之測驗工具有良好的內部一致 性,並且 A、B、C 複本測驗之 Pearson 積差相關係數介於.735 ~ .900,顯示測驗 工具之間有相當高的同質性。第一節 使用華語閱讀輔助工具前學生華語閱讀成
績之分析
透過獨立樣本 t 檢定,確認隨機分配的第一組與第二組學生使用華語閱讀輔 助工具前之華語閱讀成績沒有顯著差異,即兩組學生的華語閱讀能力沒有顯著性 差異。 表 4-1 為兩組學生不使用華語閱讀輔助工具的 A 測驗成績之獨立樣本 t 檢定 表,在顯著水準α=.05 下,第一組(M = 13.84, SD = 3.37)與第二組(M = 14.68, SD = 3.72)未達顯著差異(t(74) = -1.034, p >.05),顯示兩組在使用工具前經由 A 測驗所得到的華語閱讀成績無顯著性的差異。表 4-1 A 測驗成績之獨立樣本 t 檢定表 組別 平均數 標準差 自由度 t 值 顯著性(雙尾) 第一組 13.84 3.37 74 -1.034 .305 第二組 14.68 3.72 本研究以 A 測驗測量不使用華語閱讀輔助工具時學生的華語能力,再根據測 得的分數進行獨立樣本 t 檢定,透過檢定結果得知,使用華語閱讀輔助工具前兩 組學生的華語閱讀成績沒有顯著差異,即兩組學生具備的華語能力相當。
第二節 華語閱讀輔助工具對學生閱讀成績之影響
在本節探討華語閱讀輔助工具對隨機分配的兩組學生閱讀成績之影響,根據 兩組學生不使用華語閱讀輔助工具與使用華語閱讀輔助工具的兩種不同條件下 所測得的閱讀測驗成績進行重複樣本 t 檢定,檢視兩種不同條件下兩組學生成績 變化的情形如何。壹、華語閱讀輔助工具對第一組學生閱讀成績之影響探討
表 4-2 為第一組學生 B 測驗(不使用華語閱讀輔助工具)與 C 測驗(使用華 語閱讀輔助工具)重複樣本 t 檢定的摘要表,第一組學生 B 測驗平均分數為 14.05 分、標準差為 3.53;C 測驗平均分數為 15.68 分、標準差為 2.86,C 測驗平均分 數比 B 測驗平均分數提高了 1.63 分,在顯著水準α=.05 下,有顯著性差異(t(37) = -4.824, p < .05),顯示不使用華語閱讀輔助工具與使用華語閱讀輔助工具的測驗 成績有達到顯著差異,即可知華語閱讀輔助工具的使用對提昇第一組學生的華語 閱讀成績有影響,平均提高 1.63 分。表 4-2 第一組 B、C 測驗成績之重複樣本 t 檢定表 條件 平均數 標準差 t 值 顯著性(雙尾) 不使用工具(B) 14.05 3.53 -4.824 .000 使用工具(C) 15.68 2.86 不使用(B)-使用(C) -1.63 2.09
貳、華語閱讀輔助工具對第二組學生閱讀成績之影響探討
表 4-3 為第二組學生 B 測驗(使用華語閱讀輔助工具)與 C 測驗(不使用華 語閱讀輔助工具)重複樣本 t 檢定的摘要表,第二組學生 B 測驗平均分數為 16.03 分、標準差為 3.82;C 測驗平均分數為 14.03 分、標準差為 3.98,B 測驗平均分 數比 C 測驗平均分數提高了 2.00 分,在顯著水準α=.05 下,有顯著性差異(t(37) = 6.681, p < .05),顯示不使用華語閱讀輔助工具與使用華語閱讀輔助工具的測驗 成績有達到顯著差異,即可知華語閱讀輔助工具的使用對提昇第二組學生的華語 閱讀成績有影響,平均提高 2.00 分。 表 4-3 第二組 B、C 測驗成績之重複樣本 t 檢定表 條件 平均數 標準差 t 值 顯著性(雙尾) 不使用工具(C) 14.03 3.98 6.681 .000 使用工具(B) 16.03 3.82 使用(B)-不使用(C) 2.00 1.85 雖然兩組學生在不同條件下接受不同測驗(第一組-B 測驗時不使用華語閱 讀輔助工具,C 測驗時使用華語閱讀輔助工具;第二組 B 測驗時使用華語閱讀輔 助工具,C 測驗時不使用華語閱讀輔助工具),但是在第一節已經驗證過兩組學生 的華語能力沒有顯著差異,因此能夠判斷在 B、C 測驗之間的成績變化不是因兩 組學生華語能力之不同而發生,是因華語輔助工具使用之有無而發生,第一組學 生華語閱讀測驗成績在使用工具時提高 1.63 分,第二組學生閱讀測驗成績在使用 華語閱讀輔助工具時提高 2.00 分。由此可知,華語閱讀輔助工具對兩組學生華語閱讀成績有提昇效果。
第三節 華語閱讀輔助工具對不同華語水準學生閱讀
成績之影響
本節討論華語輔助工具使用與否對不同華語程度背景學生測驗成績所引起 的影響,採用無母數檢定的 Mann-Whitney 方法,檢視在初、中、高級三等不同 華語程度學生組內不使用華語閱讀輔助工具與使用華語閱讀輔助工具之成績是 否有差異。首先進行以華語程度與華語閱讀輔助工具使用與否為雙因子的變異數 分析,結果 Levene’s 錯誤共變異等式檢定顯示,不同程度學生組內無法滿足變異 數同質性假設(F(5, 146) = 4.568, p < .05),因此無法使用變異數分析內容解釋研 就結果,改用無母數檢定的 Mann-Whitney 方法,比較不同水準學生組內得分之 情形。最後根據組內得分之相差值,進行以華語程度為單因子的變異數分析,探 討測驗成績變化程度在不同華語水準的學生組間是否有差異。壹、初級學生華語閱讀成績之影響探討
表 4-4 為初級學生不使用華語閱讀輔助工具與使用華語閱讀輔助工具的兩種 條件下得分之 Mann-Whitney U 檢定結果,學生使用華語閱讀輔助工具時華語閱 讀成績(Mdn = 14)比不使用華語閱讀輔助工具時(Mdn = 11)高,並且兩種條 件下的成績有顯著差異,U = 143.50,Z = -3.850,p < .05,r = -.741,即可知華語 閱讀輔助工具對參加本測驗的初級程度學生華語閱讀成績有提升效果。 表 4-4 初級學生華語閱讀成績之 Mann-Whitney U 檢定表 條件 中位數 U 值 Z 分數 r 值 顯著性(雙尾) 不使用工具 11.00 143.50 -3.850 -.741 .000 使用工具 14.00貳、中級學生華語閱讀成績之影響探討
表 4-5 為中級學生不使用華語閱讀輔助工具與使用華語閱讀輔助工具的兩種 條件下得分之 Mann-Whitney U 檢定結果,學生使用華語閱讀輔助工具的華語閱 讀成績(Mdn = 16)高於不使用華語閱讀輔助工具的情況(Mdn = 13.5),並且兩 種條件下的成績有顯著差異,U = 142.50,Z = -3.027,p < .05,r = -.618,即可知 華語閱讀輔助工具對參加本測驗的中級程度學生華語閱讀成績有提升效果。 表 4-5 中級學生華語閱讀成績之 Mann-Whitney U 檢定表 條件 中位數 U 值 Z 分數 r 值 顯著性(雙尾) 不使用工具 13.50 142.50 -3.027 -.618 .002 使用工具 16.00参、高級學生華語閱讀成績之影響探討
表 4-6 為高級學生不使用華語閱讀輔助工具與使用華語閱讀輔助工具的兩種 條件下得分之 Mann-Whitney U 檢定結果,學生使用華語閱讀輔助工具的華語閱 讀成績(Mdn = 19)高於不使用華語閱讀輔助工具的情況(Mdn = 18),並且兩種 條件下的成績有顯著差異,U = 199.50,Z = -2.267,p < .05,r = -.453,即可知華 語閱讀輔助工具對參加本測驗的高級程度學生華語閱讀成績有提升效果。 表 4-6 高級學生華語閱讀成績之 Mann-Whitney U 檢定表 條件 中位數 U 值 Z 分數 r 值 顯著性(雙尾) 不使用工具 18.00 199.50 -2.267 -.453 .023 使用工具 19.00 透過 Mann-Whitney U 檢定結果得知,在初、中、高級三等不同華語程度學 生組內不使用華語閱讀輔助工具與使用華語閱讀輔助工具之成績有顯著差異,並 且使用華語閱讀輔助工具的學生華語閱讀成績皆高於不使用華語閱讀輔助的情 況,由此可知,華語閱讀輔助工具對不同華語水準學生組間成績變化引起提升作用,再加上,Mann-Whitney U 檢定的效果量(Effect size)r 值表示,華語閱讀輔 助工具對初級學生的華語閱讀測驗分數影響力最大(r = -.741),其次是中級(r = -.618),影響力最小的是高級(r = -.453)。Becker(2000)指出 Effect size 的大小 定義標準,r 值屬於從 0.0 到 0.2 區間的時候定義為影響力小,從 0.3 到 0.5 區間 的時候定義為影響力中等,從 0.6 以上的時候定義為影響力大。根據 Becker 的標 準,我們可以說除了高級以外的水準,華語閱讀輔助工具對學生華語閱讀測驗成 績的影響力很大。上述內容,詳如圖 4-1 所示: 圖 4-1 華語閱讀輔助工具與不同水準學生組間成績變化情形
肆、不同水準學生組間華語閱讀成績變化程度之探討
不同水準學生組內以使用華語閱讀輔助工具時得分與不使用華語閱讀輔助 工具時得分的相差值當作測驗成績變化程度,採用單因子變異數分析,檢視不同 水準學生組間成績變化程度是否有差異。接下來透過 Scheffe 法進行事後比較, 查看對不同水準學生組間成績變化程度產生顯著差異的要素。 表 4-7 為不同水準學生組間華語閱讀成績變化程度之單因子變異數分析表,在顯著水準α=.05 下,達顯著差異(F(2, 73) = 6.161, p < .05),表示初、中、高 級三等不同水準學生組間的華語閱讀成績變化程度有顯著差異。 表 4-7 不同水準學生組間華語閱讀成績變化程度之單因子變異數分析表 平方和 自由度 平均值平方 F 值 顯著性 群組之間 41.796 2 20.898 6.161 .003 在群組內 247.625 73 3.392 總數 289.421 75 表 4-8 為不同水準學生組間華語閱讀成績變化程度之 Scheffe 多重比較表, 在顯著水準α=.05 下,僅在初級與高級學生組間的成績變化程度達顯著差異(F(2, 73) = .927, p < .05),表示初級與高級學生組間的差異使不同水準學生組間成績變 化程度達顯著差異。 表 4-8 不同水準學生組間華語閱讀成績變化程度之 Scheffe 多重比較表 平均差異 95%信賴區間 I 水準 J 水準 (I - J) 標準誤差 顯著性 下限 上限 初級 中級 .514 .517 .612 -.777 1.805 高級 1.756 .511 .004 .478 3.033 中級 初級 -.514 .517 .612 -1.805 .777 高級 1.241 .526 .068 -.074 2.557 高級 初級 -1.756 .511 .004 -3.033 -.478 中級 -1.241 .526 .068 -2.557 .074 透過單因子變異數分析,發現不同水準學生組間華語閱讀成績變化程度有顯 著差異,再使用 Scheffe 法進行事後比較,發現不同華語水準學生組間的顯著差 異因為受到初級與高級學生組間之差異的影響而產生,因此可以確認工具對不同 水準學生華語閱讀成績產生的變化程度不一樣,並且在初級與高級學生組間的成 績變化程度相差比其他水準明顯。