建立全民健保應收保費預測模型―時間數列ARIMA模型之應用; The establishment of the premium receivable forecasting model in NHI---an application of time series ARIMA model
138
0
0
全文
(2) 自開辦至今安全準備金迄未歸零,惟健保局屢發出「健保財務危機」 之警訊,以提醒大眾共體時艱將收支赤字不斷拉近。. 圖 1.1 全民健康保險收支概況 億元. 3500.00. 3000.00. 2913.69 2587.52 2361.29. 2500.00 1983.76. 2247.98. 2439.96. 2696.54. 2877.22 2968.4. 2686.7. 2414.84. 2000.00. 應收保費 醫療費用 餘額. 1639.59 1500.00. 1000.00. 500.00. 344.17 113.31. 25.12. -99.18. 0.00 1995. 1196. 1997. -217.15. -91.18. 1999. 2000. 1998. (500.00). 年. 資料來源:全民健康保險統計(2000) 由全民健康保險局之保險收入及保險成本之落差來看,縮短落差 可從兩方面來著手,一方面增加保費收入,另一方面則抑制醫療費用 支出。在探討如何增加應收保費方面,和應收保費有關的財務問題 如:納保人口、平均眷口數、費率… 等方面需加以探討,而和應收保 費有關的財務以外之問題如:經濟成長率、人口月增加成長率、失業 率… 等,是否與保費收入有某種關係,亦值得去探討。因此,本研究 引用行政院主計處等相關單位資料及健保局每月應收保費收入檔資. 2.
(3) 料,希望以時間數列分析方法,來建立預測應收保費模型,探討影響 保費收入之因素及預測保費收入趨勢。因預測的目的在「估計」未來, 而其動機則是探究影響因素欲「控制」現象。因為祇有透過準確的預 測,瞭解應收保費結構變化,再配合組織系統運作,才能充分發揮經 營決策之效率(吳柏林,民 84) 。. 3.
(4) 第二節. 問題陳述. 全民健康保險系列民意滿意度調查結果,從剛開辦時的三成滿意 度情況,到民意調查突破七成以上的滿意度,再再證明健保局、醫事 團體、及全體民眾的努力所獲得的成果(全民健康保險系列民意調 查,民 85~民 89)。但是一個制度的好壞,民意調查滿意度不能做為 唯一衡量的標準,其他如財務的管理、民眾的認知、以及資源的分配 等,均為考驗健保制度能否永續經營的因素。但眾所週知,社會愈來 愈老化,醫療支出自然就愈多,加上民眾對醫療需求的增加與品質要 求的提升及醫療科技的進步,都讓醫療支出快速成長(Newhouse, 1992) 。在過去醫療費用支出的成長率一直維持在 10~12%左右,反觀 全民健保實施六年多來費率一直維持在 4.25%,而且是投保金額的 4.25%。而雇主及政府負擔之平均眷口數上限也由開辦時之 1.36 人降 至目前的 0.78 人,同時又將民眾自負眷口數上限由開辦時之五口調降 為三口,並將滯納金上限調降為 30%,這些措施均使保險費收入減 少,使保險費的成長率維持在 3%左右。因此,在財務方面,至八十 八年起保險費收入不足以支應醫療費用支出的情況發生(賴美淑,民 89)。 健保局為了維持收支平衡,實施了多項「開源節流」方案,才可 能達到此一目標(賴美淑,民 88)。因此,由表 1.1 可以看出,自八. 4.
(5) 十九年起醫療費用成長趨勢明顯下降,而應收保費成長趨勢則微升。 然而,依全民健康保險法之設計,健保財源是多元化,惟目前健保的 主要收入為保險費一項。本研究即以應收保費(費用年月)為分析之 數據,加以探討相較平均眷口數、眷口數上限、經濟成長率、人口月 增加率、失業率等因素,作為預測應收保費成長趨勢分析參考。. 表1.1. 全民健康保險保險收入與醫療費用支出概況收支概況 應收保費 醫療費用 年度 應收保費 醫療費用 餘額 成長率 成長率 1995. 1983.76. 1639.59. 344.17. 1196. 2361.29. 19.03%. 2247.98. 37.11% 113.31. 1997. 2439.96. 3.33%. 2414.84. 1998. 2587.52. 6.05%. 2686.70. 11.26% -99.18. 1999. 2696.54. 4.21%. 2913.69. 8.45% -217.15. 2000. 2877.22. 6.70%. 2968.40. 1.88% -91.18. 資料來源:全民健康保險統計(2000) 附註:1995年資料係3月至12月. 5. 7.42%. 25.12.
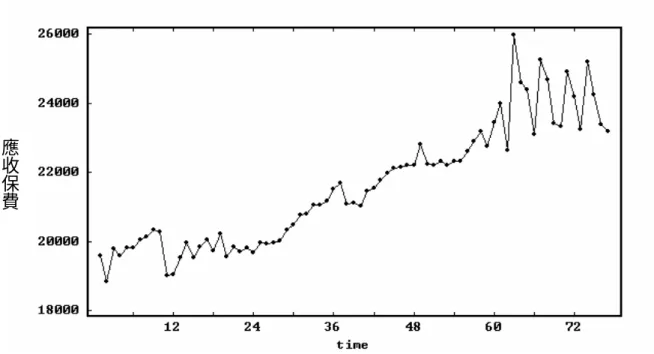
(6) 第三節. 研究問題. 全民健康保險應收保費之時間數列不能期望它們隨著時間變化 而保持著平穩狀況,由圖 1.1 可知數列之平均水準隨時間變化而改 變。但卻呈現著隨時間改變而向上攀升增加的型態,可知此數列的平 均並非維持在一固定的水平區間中,應為非平穩型的數列 (non-stationary series),而資料數列屬於不穩定數列最常採用 ARIMA 分析模式來建立預測模型,故本研究針對下列模型作探討。 一、利用 ARIMA 單變量時間數列分析法來建立全民健康保險應收保 費模式預測模式為何? 二、由於單變量模型缺乏先驗情報,對模型之解釋能力較難令人信 服,而在許多的例子中有可能發生一筆資料其目前的觀測值受到 過去的觀測值影響,並且與另一筆(或多筆)時間數列資料具有 相關性,亦即當輸入變數 Xt 發生變化時,其將有多少傳送到輸 出變數 Yt 之情形,因此應收保費是否受到納保人口、人口月增 加率、失業率以及經濟成長率等因素的前幾期影響的可能性,考 慮利用轉換函數模式( Transfer Function Model)來建立全民健康 保險應收保費模式是否會更精確。 三、應收保費時間數列常被各種外部性的事件,如平均眷口數及眷口 數上限的修正因素影響,而使時間數列受到干擾,影響模型建構. 6.
(7) 進而降低預測之精確結果。本研究希望評估這些外部事件的效果 或將這些介入因子引進時間序列的模型中,是否更能建立合適之 模型。 四、針對上述所建構之單變量時間數列模型、轉換函數模型、介入模 型比較分析,何者預測效果較準確。. 7.
(8) 第四節. 研究目的. 一、建立預測應收保費之單變量ARIMA模型。 二、建立預測應收保費之介入模型。 三、建立預測應收保費之轉換函數模型。 四、建立預測應收保費之多元轉換函數模型。 五、本研究所建立之分析模型,何者預測效果較佳。. 8.
(9) 第二章 相關文獻回顧 第一節. 各國健康照護服務系統實施概況與比較. 二次世界大戰以後,先進國家即不斷為追求健康人權的理想而努 力,一方面積極發展醫療資源,另一方面則擴大社會性健康保險的適 用對象,一些經濟合作暨開發組織的國家醫療體系的改革經驗正值得 我國借鏡,惟其健康照護系統各國有所不同。依體制來分大約可分三 大類:一為國民保健服務模型(NHS The National Health Service Model) ,其特色為範圍普及,財務來自一般稅收,全體民眾均納入保 險,醫療服務機構的所有權及控制權為政府所有,實施的國家例如: 英國、澳洲、丹麥、芬蘭、冰島、挪威、瑞典、紐西蘭、愛爾蘭、希 臘、義大利、西班牙、葡萄牙等。二為社會保險模型(SI The Social Insurance Model), 特色為強制性的全面保障,財務由雇主及員工共 同負擔,亦即保險財源以保險費為主,民眾加入不同的保險計劃,醫 療機構由政府或私人擁有,採此類的國家最多,包括:德國、法國、 加拿大、比利時、瑞士、荷蘭、盧森堡、奧地利、韓國、日本等國, 而美國之老人保險( Medicare) 、貧民保險(Medicade)亦屬之。三為 私人保險模型( PI The Private Insurance Model) ,以雇主為單位或以 個人為單位購買私人健康保險,財務由個人或與雇主共同分擔,醫療 機構由民間擁有,例如:美國。上述之國家我們亦可從醫療體系來歸. 9.
(10) 類,即自由市場、社會保險以及公醫制度。如美國的醫療體系屬於自 由市場制度,無論服務的提供,或財源的籌措都以民間為主,而且多 元化。加拿大與德國的醫療體系屬於社會保險制度,服務的提供由民 間部門與政府部門共同負責,但是財源籌措則以公共部門為主。英國 與瑞典的醫療體系屬於公醫制度,無論服務的提供或財源都以公共部 門為主。而醫療體系改革的方向為:美國追求管理式競爭,加拿大限 制總醫療支出,德國實施總額預算,英國提倡內部市場,瑞典實驗公 共競爭。是以,自由市場制度的國家追求公平而有效率的競爭,社會 保險制度的國家重視總醫療費用控制,而公醫制度國家則冀望提高醫 療服務的效率,儘管每一類型國家維持其應有之特色,但是不同類型 國家之間已經彼此互相學習。 我國憲法第一五五條及一五七條分別明文規定:「國家為謀社會 福利,應實施社會保險制度」及「國家為增進民族健康應普遍推行衛 生保健事業及公醫制度」。民國八十一年國民大會臨時會制定憲法增 修條文第十八條第三項(八十六年修憲改為增修條文第十條第四 項):「國家應推行全民健康保險,並促進現代和傳統醫藥之研究發 展」。因此,依據憲法及體認民意趨向,政府乃積極進行規劃全民健 康保險。然而,全民健康保險是我國近代最大的醫療保險措施與影響 深遠的社會建設,這不但是我國邁向「全民均健」之重要里程碑,也. 10.
(11) 是建立社會安全保障之一大步。其設計規劃與實施極為複雜,相關措 施繁多龐大,其雖經行政院經濟建設委員會及衛生署七年的審慎規 劃,參考各先進國家醫療保險制度,並廣泛諮詢國內外相關單位與專 家意見,當時對於健康保險現制的改革,全民健保小組的重要主張有 五點:一、將現有公、勞、農保制度之健康保險整合為一;二、實施 醫療費用部分負擔,減少醫療浪費;三、以被保險人為單位收取保險 費、廢除目前公保的論口計費制;四、按精算結果調整保險費率,政 府不一再撥補虧損,以及五、建立醫院成本會計制度,透明化與合理 化醫療費用支付制度。但在立法過程中,仍難免面臨若干爭議,然鑑 於當時尚有 787 萬人未納入醫療保險,其中又以兒童、老人等弱勢國 民居多。為儘速使這些國民早日享有適當的醫療照護,如期實施全民 健康保險確實有必要。至於其制度設計上一些見仁見智的看法,則可 俟後實行一段期間後再行檢討,基於上述之考量,我國全民健保終於 民國八十四年三月一日起實施。 健康保險為國家基於社會政策,應用保險的技術,對全體或特定 階層的國民於遭遇生育、疾病、傷害等危險事故時,保障被保險人的 經濟生活及身心健康期以發揮最大保護、互助合作及達成防貧作用的 一種社會保險制度(吳凱勳,民 83)。而全民健康保險的實施最主要 目的,依據全民健康保險法第一條就已經明示為,增進全體國民健康. 11.
(12) 辦理全民健康保險,以提供醫療保健服務。其基本目標:一、提供國 民適當醫療服務;二、有效利用醫療資源;三、減少就醫之財務障礙; 四、促進國民健康;其由中央衛生主管機關負責,於保險對象在保險 有效期間,在發生疾病、傷害、生育、事故時,依全民健康保險法規 定給與給付。故全民健康保險是以全體國民為保險對象,在自助互助 共同分擔危險的基本原則下,每位保險對象按月繳納保險費用,一旦 發生疾病、傷害、生育、事故時,由保險醫事服務機構提供醫療保健 服務的一種社會保險制度。 國際醫療制度比較,除因可作比對的資料有限外,亦因各國經濟 人口,文化制度等不同,使得在解釋醫療指標差異時,需小心各種的 干擾因素(例如:年齡結構、人口密度及分布、出生率、死亡率、疾 病發生率、保險給付範圍、醫療職業型態、行政效率、保險制度設計、 民眾醫療行為等)。而在同一指標比較時,又因為各國定義不同,而 有不同之計算基礎,例如:對於醫療保健支出,應包括哪些項目之費 用,國際間並無一致看法(如:社會服務、學校醫療保健、醫療環境 支出等是否應納入,即頗有爭議),而對於「醫院」、「養老院」等定 義,亦無共識,所以各國比較僅為初步比對方式,以下將分述我國健 康保險制度與各國在醫療保健經費、納保率、醫療資源、醫療利用率、 及醫療結果上之比較。. 12.
(13) 我國全民健保與各國比較,依據健保局彙整可分結構面、過程 面、結果面,三大部分來比較。在結構面方面,醫療保健支出占 GDP(Gross Domestic Product)比率均較 NHS(National Health Service )、NHI(National Health Insurance)平均值和美、日、韓等低, 表示我國醫療費用支出對於總體經濟壓力尚不太大,政府支出占 64%,民眾自付費用達 36%比例較高。全民健康保險法定之強制保險 人口為 97.5%,較 NHI 國家平均值(78%)高。每千人病床數(4.7)介於 NHS(3.9)與 NHI(5.9)平均值之間,較美國、韓國高,較日本低,所以 住院醫療資源應算充足,未來則需加強慢性病床的增設。每千人醫師 數(1.29)只較韓國(1.2)高外,均較 NHS、NHI、美、日等國低,顯示 國內醫師數仍略嫌不足。過程面方面,每人每年就醫次數(12.9)較 各國高,但每百人每年住院率(12.3)則較各國低。門診次數高的原因, 一方面可能因為採用論量計酬支付制度和民眾就醫自由,促使就醫頻 率較高,未來有必要加強支付制度的改革,如實施區域級以上門診合 理量及加重部分負擔;另一方面,亦有可能因為國人習於疾病初發即 看病,故少住院而多用門診服務。平均住院日數(9.2)則介於 NHS 和 NHI 平均值之間。結果面方面,對於整體制度,有 60.1%民眾認為現 行透過健保來提供醫療服務的模式已經「不錯,不需再改」或「只要 再稍加改善」 。而 NHI 國家有 43%認為只需小幅改革,多數均認為需. 13.
(14) 大幅改革或完全改革,NHS 國家則只有 24%滿意現行制度。對於詢 問民眾對於制度的滿意與否,全民健保民意調查,目前有 70%以上民 眾認為滿意,NHS 國家為 57%,NHI 國家則平均為 90%。每千人嬰 兒死亡率僅較日本高,與 NHS、NHI 國家相當,平均餘命(男性: 71.89 歲;女性:77.76)高於韓國,但較 NHS、NHI 國家平均少兩歲。 因為嬰兒死亡率、平均餘命等數值與整體經濟、衛生環境等相關,很 難於短期醫療保健介入即可看見成果,故需長期監測,但民眾滿意度 則是短期內評估介入結果很好的指標,而調查的結果,目前多數民眾 均滿意全民健康保險的實施。 (健保局網路資料,民 85) 我國全民健康保險自八十四年三月實施以來,在健保局的努力以 及各界的密切配合之下,健康保險之基本運作得以順利運轉,以達到 許多重要的成果:諸如擴大保險人口以落實全民納保目標,減少民眾 就醫財務障礙以提升就醫可近性,加強山地離島偏遠地區之醫療服 務,提供綜合醫療服務,擴大給付項目,維持財務平衡使保險財務收 支穩定,精簡人事及行政成本,合理調整給付標準,加強醫事服務機 構管理以提升醫療服務品質,及有效控制醫療費用以合理利用醫療資 源等,民眾滿意度亦愈來愈高。同時亦提到現階段仍面臨若干問題期 待解決,主要有:全民納保問題、保險財務平衡問題、支付制度問題、 門診與住院費用結構分配比率問題、醫學專科與醫院發展失衡問題、. 14.
(15) 慢性病患進住急性病床問題、中小型醫院生存空間萎縮問題… .等。 雖然現代進步的國家必須保障全體國民均能獲得適切的醫療保 健服務,而實施全民健康保險,雖可大幅提升國民社會安全與福利, 保障增進國民健康,但另一方面要耗用大量社會資源,雖然全民健康 保險業務實施至今已漸趨穩定,一切作業也在各界全力配合及督導, 積極推動,實施至今已七個年頭,但在穩步邁進的同時財務的隱憂也 開始逐漸浮現。. 15.
(16) 第二節. 影響全民健康保險經營成效之因素. 隨著國民所得的提高與人口老化,各國無論採取何種醫療保健制 度均共同面臨醫療費用不斷膨漲的問題( Glacer,1991) ,我國亦不例 外;目前全民健保財務收支狀況概要,可由三方面探討:一為民眾對 全民健保的滿意度,二為保費收入及成長率,三為醫療費用支出及成 長率(國家衛生研究院論壇,民 87);根據全民健康保險系列民意調 查,民眾對全民健保的滿意度節節高升(圖 2.1) ,可以看出滿意度從 剛開辦八十四年四月 33.0%,八十四年十月 50.90%,八十五年 68.60%,八十六年 73.0%,八十七年 72.5 %,八十八年 74.00 %,八 十九年 75.40 %(全民健康保險系列民意調查,民 85~民 89) 。另由全 民健康保險統計應收保費收入分別為八十四年為 1,983.76 億元(八十 四年三月至十二月) ,八十五年為 2,361.29 億元,八十六年為 2,439.96 億元,八十七年為 2,587.52 億元,八十八年為 2,696.54 億元,八十九 年為 2,877.22 億元;而醫療費用支出八十四年為 1,639.59 億元(八十 四年三月至十二月) ,八十五年為 2,247.98 億元,八十六年為 2,414.84 億元,八十七年為 2,686.70 億元,八十八年為 2,913.69 億元,八十九 年為 2,968.40 億元,由成長率來看應收保費收入成長率八十五年為 19.03%(八十四年三月至十二月):八十六年為 3.33%,八十七年為 6.05%,八十八年為 4.21%,八十九年為 6.70%,醫療費用成長率八十. 16.
(17) 五年為 37.11%(八十四年三月至十二月),八十六年為 7.42%,八十 七年為,11.26%,八十八年為 8.45%,八十九年為 1.88%。由以上的 統計資料,雖然全民健保制度得到大部分國人的肯定與支持,但是健 保財務卻潛藏著諸多隱憂,如不再妥善因應,即將出現資金入不敷出 的窘境(全民健康保險統計,民 84~民 89)。 而依衛生資料,全國醫療保健支出亦由民國八十四年之 3,712 億 元增為民國八十五年之 4,098 億元,八十六年為 4,308 億元,八十七 年為 4,717 億元,八十八年為 5,049 億元,八十九年為 5,254 億元;而 國內生產毛額(GDP)八十四年為 70,197 億元,八十五年為 76,781 億元,八十六年為 83,288 億元,八十七年為 89,390 億元,八十八年 為 92,899 億元,八十九年為 95,424 億元;由成長率來看全國醫療保 健支出成長率八十五年為 9.90%, 八十六年為 5.60%,八十七年為 9.50%,八十八年為 7.04%,八十九年為 4.06 %,國內生產毛額(GDP) 成長率八十五年為 6.10%,八十六年為 6.68%,八十七年為 4.57%, 八十八年為 5.42%,八十九年為 2.7 %;大致上所得較高國家的醫療 支出比率亦較高。我國目前醫療支出比率約比韓國略高,而較其他先 進國家為低,在國際間比較,尚為適當。然而值得關切的是,隨著全 民的開辦,健保醫療給付成為全國醫療保健支出大宗,而健保醫療給 付成長率則超過主要收入來源—保費收入的趨勢,因而影響全民健保. 17.
(18) 財務健全性。 世界各國實施健康保險的國家所面臨的問題,在政府方面主要考 慮於需顧及保險財務的收支平衡,認知政府的有限責任及審慎調整保 險相關費用;對保險對象而言,不外乎希望減輕保費負擔及就醫時之 部分負擔或自負額、增加給付項目與給付範圍;對醫療院所而言,則 是極力爭取保險給付項目,提高支付標準,甚至可允許視狀況向病人 收取差額。因此,如何在有限的資源與無窮慾望中取得平衡點,以滿 足各方需求,乃是各國所努力的目標。全民健康實施至今,醫療費用 上漲速度遠大於物價上漲與經濟成長率,且未見緩和,每月醫療費用 申報額已超過保險費應收額,目前以前期結餘撥補,若保險收入不能 增加或醫療費用支出無法得到有效控制,則保險財務必然告急。然而 因保險財務主要來源為保險費,而保險費取決於保險費率及投保金額 兩因素,其中投保金額受限於經濟成長,而保險費率又受到政治因素 之過度干擾,所以兩者之調升空間有限;因此,為使安全準備金不致 有用罄的一天,為維制度的永續經營健保局配合多項「開源節流」方 案;在開源方面如:代位求償,菸酒社會健康附加捐,對欠費被保險 人積極展開稽催行動,以及加強投保金額查核。在節流方面之方案有 針對虛、浮報醫療院所加強查核,對申報費用不合理之醫療院所加強 審核,對民眾加以宣導讓民眾了解珍惜醫療資源,另為更有效控制醫. 18.
(19) 療費用成長,針對使用偏高的門診、藥品、復健等醫療項目實施加收 部分負擔,以增加民眾的成本概念,另對醫療服務提供者,實施各種 醫療費用管控措施,藉以減少不當之醫療浪費,如建制高科技檢查即 時報備系統,以節制昂貴檢查項目利用。並進行藥價調查,調降偏高 之藥價基準,節省藥費支出;尤其為有效控制醫療費用成長於合理範 圍內,分別自八十七年七月實施牙醫總額預算制度,八十九年七月實 施中醫總額預算支付制度,及九十年七月實施基層醫療院所總額預算 支付制度,以及預計九十一年實施醫院總額預算制度,亦即藉階段性 實施總額支付制度,達到費用控管目的。經由上述種種的方案,醫療 費用的成長有明顯下降(賴美淑,民 88,民 89)。 全民健保實施已邁入第六個年頭,健保局本著健保資源分文皆為 民眾的血汗錢輕忽不得的心境,扮演好管家的角色。因此,在健保首 度出現赤字時,雖有安全準備金可為因應,但深覺若不及時發出警 訊,恐不利長遠發展,才會多次發布「健保危機」之訊息。所幸,在 健保局的提醒下,民眾均能共體時艱,將收支赤字不斷拉近,讓原預 計八十九年三、七、十月可能出現安全準備低於二百五十億元的危 機,一一安全渡過,化危機為轉機(賴美淑,民 89)。. 19.
(20) 圖2.1 滿意度調查 80.00% 70.00%. 73.00% 68.60%. 74.00%. 75.40%. 72.50%. 60.00% 50.90%. 50.00% 40.00% 30.00%. 33.00%. 20.00% 10.00% 0.00% 1995.04.20. 1995.10.25. 1996.12.02. 1997.11.18. 資料來源:中央健康保險局. 20. 1998.08.26. 1999.10.18. 2000.12.07.
(21) 第三節 影響應收保費之因素 社會保險制度是否能順利及健全推展,其財務穩定扮演著極為重 要的角色,通常保險制度會遭遇到被保險人與保險人雙方資訊不對稱 性問題,導致資源過度使用的道德冒險(moral hazard)現象,以致發 生財務嚴重虧損,最終將難以為繼。但對於保險的財源籌措方面更不 可忽略,攸關著全民健康保險制度能否健全永續經營。現行全民健保 的財源主要來自保險費,以保險費做財源最大的好處在於財務獨立於 政府行政預算之外,可確保健保財務的自主性。保險費計算的基礎是 薪資所得,故可視之為一種「薪資稅」,但某些行業薪資所得查核不 易,經濟狀況不一,遂將保險對象分為六類十三目,各保險對象依其 所屬的行業及身分以適當的類目及核定的投保金額投保。保險費徵收 時又依「人口數」多寡計費,但考慮多眷口被保險人負擔問題,於是 有最高付費眷口數上限之規定;另為保障多眷口數被保險人之工作 權,而有平均眷口數的設計。此外政府、雇主均有照顧被保險人及其 眷屬健康的責任與義務,故健保法中依類目別訂有政府、雇主及被保 險人對保險費分擔的比率。計算保險費另一重要基礎為保險費率,費 率具有調節財務收支不平衡的功能,全民健保法中訂有費率需依精算 程序決定,即為保障財務獨立、自主,使全民健保得以永續經營。. 21.
(22) 惟現行制度仍然問題重重,諸如:行政無法獨立自主,主管機關 甚多干預,監理會難以發揮超然的監督功能;財務上,醫療費用支出 的成長,遠超過保險費收入的增加;總額預算至今尚未全面實施,支 出上限的準則猶未確定。公務人員以外的受雇者投保金額的低報問題 相當嚴重,且選擇性投保現象浮濫,缺乏有效的方法改善(李險峰, 民88);我國全民健保以保險費為主,而以部分負擔為輔的財源籌措 方式,基本上與採行社會醫療保險體制的先進國家並無不同。保費的 計算通常依受雇者的薪資或自營作業者工作所得的某一比例(但有上 限),而由勞、資、政共同分擔。此種財源籌措方式常被批評為費基 太窄,無法應付醫療支出的膨脹,因而被迫不斷提高費率。且就對經 濟影響而言,雇主分擔保費的加重也將不利於就業與出口,尤其勞力 密集產業受到衝擊較大。然而主要財源的變動不易取得政治上的共 識,而改制的財務風險亦大,因而大多數國家仍然維持以薪資稅為主 要財源(Glaser,1991) 。由於現行健保係整合原有十三類健康保險制 度,並擴大投保對象至農、勞保眷屬及地區投保者而成為全民性社會 醫療保險體系,為避免改制前後各類別被保險人保費負擔差異調整太 大,因而無論就投保金額之界定與保費負擔比率,大致依循原有健保 制度或變動不大,而眷屬保費計算則採原公教眷保之論口計算方式 (羅紀瓊、尤素娟,民83)。但是原有十三類健保財務制度差異性很. 22.
(23) 大,納入同一體系內又容許相當的選擇性投保,將引發我國現行制度 特有的各類別被保險人保費負擔公平性的爭議,也會影響健保財務收 入的穩定,以及政府財政負擔的加重等問題。由於財務穩健乃全民健 保永續經營的關鍵所在。除上述政府財務責任應予釐清外,在財源融 通的取得方面,亦應配合長期給付結構的變動與財務負擔方式的調 整,規劃因應的適足財源。無論給付範圍的擴充,抑或保費計算基礎 與分擔方式的調整,均應完整評估其對健保財務的可能影響,而適當 調整費率,避免單方面提高給付,或降低保費負擔,以確保健保財務 收支平衡(鄭文輝、蘇建榮,民86)。劉宜君(民88) 研究指出,對於 國家機關保險財務管控能力之實證分析發現,應收保費收入主要受到 平均眷口數調降、高薪低報、中斷投保開單、… 等行政措施之影響。 曹立榮(民87) 亦指出,將保費收入面監理資訊分為納保率、眷口數、 保費收繳及有關之總體經濟指標如GDP 、 NI,以作為加強監理功能 以及增進保費收入之依據。而葉秀珍(民86)指出以現有健保體制而 言,被保險人一旦失業若以地區人口加保,則保費加重以及多一事不 如少一事之情況下,造成失業中斷投保,對保費造成負面影響。 為更了解全民健康保險法對有關保費收入之規定,將相關條文摘 述如下: 一、 第七、八條 將保險對象分為被保險人及其眷屬,又將被保險人. 23.
(24) 分為六類十三目。 二、 第十八條 第一類至第四類被保險人及其眷屬之保險費,依被保 險人之投保金額及其保險費率來計算。 三、 第十九條第三項 眷屬之保險費由被保險人繳納,超過三口者, 以三口計。 四、 第二十條 本保險之保險費率由保險人至少每兩年精算一次,每 次精算二十五年。 五、 第二十一條 第一類至第四類被保險人之投保金額由主管機關 擬定分級表,報請行政院核定之。 (分級表見附錄 A) 六、 第二十五條 第五類保險對象之保險費,以精算結果之全體保險 對象每人平均保險費計算之。 七、 第二十六條 第六類保險對象之保險費,以精算結果之全體保險 對象每人平均保險費計算之。眷屬之保險費由被保險人繳納,超 過三口者,以三口計。 八、 第二十八條 第一類至第四類被保險人所屬之投保單位或政府 應負擔之眷屬人數,依第一類至第四類被保險人實際眷屬人數平 均計算之。 由上述全民健康保險法有關規定,影響應收保費之因素,大致可 分為保險費率、納保人口(保險對象)、平均投保金額(投保金額) 、. 24.
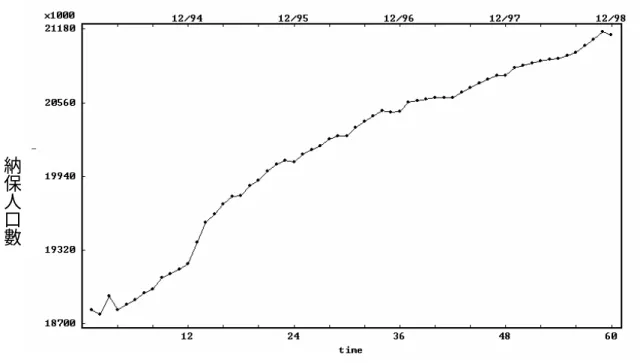
(25) 眷口數上限、及平均眷口數等。. 一、保險費率 —保險費率是計算保險費之重要因素,但由於其從全 民健保開辦至今費率一直維持在 4.25%,且與精算有關。. 二、眷口數上限—自八十八年七月一日起將自負眷口數上限由五 口調降為三口。. 三、納保人口—人口成長及納保率之提高,將會使納保人口增加, 進而增加保險費收入,根據全民健康保險局統計顯示全民健康 保險對象,在開辦初期為 1,881 萬人,至九十年六月以達 2,140 萬人,納保率已高達 96.2%(全民健保統計資料,民 90)。. 四、平均投保金額—薪資成長經濟景氣及投保金額分級表最高一級 調整等因素,皆會使平均投保金額產生改變。. 五、平均眷口數—全民健保開辦至今,影響保費收入最大者首推平 均眷口數的改變,健保法訂定開辦初期以平均眷口數 1.36 人計 算保費,但因實際平均眷口數甚低,因此,八十五年一月調降 為 1.1 人,八十五年十月調降為 0.98 人,八十七年三月一日調 降為 0.88 人及九十年一月調降為 0.78 人。 根據上述之分析可以看出,在保險費收入方面,納保人數及平均 投保金額的提高,皆會使應收保費上升,但調降眷口數上限及平均眷 口數則使應收保費減少。. 25.
(26) 全民健保財源以保險費為主,而保費的計算是依受雇者的薪資和 自營作業者所得的某一比率(但有上限),而由勞、資、政依不同比 例共同分擔。就學理上而言,雇主分擔的保費可能轉嫁,而政府補助 的保費來自一般稅收,其租稅負擔分配與被保險人自繳保費的負擔分 配情況也不同,因而完整的保費負擔分配,應將此二項實值歸宿併入 考量。另方面名目上的保費分擔比率,尚需考慮政治經濟面的勞、資 協商,以及社會保險的經營管理體制;就各國社會安全財源制度觀 察,往往形成勞工、雇主與政府各分擔約三分之一經費的黃金法則 (ILO,1984) ,我國全民健保整體保費在三者之間的分配,與此相近。 黃慧貞(民 85)曾針對我國全民健保第一、二、三類被保險人 所作的調查顯示,受訪者大都以其家庭自繳保費負擔的觀點,來評價 健保制度,可見名目負擔率,仍為被保險人關心的焦點。 強制性社會保險制度,強調社會連帶責任,被保險人有義務定期 繳納保險費,惟保險費與醫療實物給付間不具個人對償性。因此在實 質意義上,保險費可視為「準租稅(Quasi-tax)」,影響保費負擔公平 性的主要因素,為保險費課徵單位、投保金額、投保費率及保險負擔 比率,其中又以保險費課徵單位最具關鍵性,不同保險課徵單位的理 論依據,政策涵義及重分配效果機轉皆有所差異。我國現行全民健康 保險保險費課徵單位分歧,保險對象之保險費採論口計算,雇主保險. 26.
(27) 費採論保險人計算,政府保險費補貼,則採論口與論被保險人二種方 式混合計算。 被保險人及其眷屬保險費課徵單位,係採論口計費方式,第一類 至第四類依被保險人之投保金額及其保險費率計算,保險費率以百分 之六為上限,現行保險費率為 4.25%,其眷屬之保險費,由被保險人 繳納,自八十九年七月起超過三口者,以三口計。第五類依全體保險 對象每人平均保險費計算,由政府 100%負擔。第六類依全體保險對 象每人平均保險費計算,其眷屬之保險費,由被保險人繳納,自八十 八年月七月起超過三口者,以三口計。榮民本人之保險費,由政府 100%負擔。雇主保險費之課徵單位,採「論被保險人計費」,為避免 眷口數多的被保險人在勞動市場上受到就業歧視,雇主保險費課徵單 位不以論口計費,而係以論被保險人計費,不論員工眷口數多寡,雇 主為每一員工/被保險人需負擔(1+平均眷口數)人的雇主保險費, 「平 均眷口數」係依據第一類至第四類被保險人實際眷屬人數平均計算 (全民健康保險法,民 89)。 根據上述全民健康保險之保險費因投保金額、保險費率、負擔或 補助比率不同,而有高低之區別,其計算公式摘述如下: 一、. 被保險人及其眷屬負擔部份 :眷屬部分採論口計算,其 中眷屬人數超過三口著以三口計。. 27.
(28) 1.第一類至第四類被保險人及其眷屬 投保金額 × 保險費率 × 保險費負擔比率 × (本人+眷屬人數) 2.第六類第一目之榮民眷屬 平均保險費 × 保險費負擔比率× 實際投保人數 3.第六類第二目其他地區人口 平均保險費 × 保險費負擔比率× (本人+眷屬人數). 二、投保單位負擔部分:眷屬採用「論被保險人計算」方式,不 按每一受雇者眷口數計算,而是以平均眷口數計算。 投保金額 × 保險費率 × 保險費負擔比率 × (本人+平均 眷口數) 「平均眷口數」係依據第一類至第四類被保險人實際眷屬人數 平均計算。八十四年為 1.36 人,自八十五年元月一日起調整為 1.1 人,同年十月一日起調整為 0.95 人,八十七年三月一日調 整為 0.88 人,九十年元月一日起再度調整為 0.78 人。. 三、政府補助方面: 1.第一類至第四類保險對象(論被保險人計費): 投保金額 × 保險費率 × 保險費負擔比率 × (本 人+平均眷口數) 2.第五類保險對象(論口方式補貼). 28.
(29) 平均保險費 × 保險費負擔比率 × 實際投保人數 3.第六類保險對象(論口方式補貼) 平均保險費 × 保險費負擔比率× (本人+眷屬人數) 至於在社會醫療保險體制下,政府在財務方面應負何種責 任,視國情而定,也無定論。我國全民健保財務規劃之設計以自 給自足為原則,期獨立於政府一般預算之外,依此原則政府所應 負擔的財務原僅止於以雇主身分所需分擔的保險費,以及基於社 會正義而對低所得所給予的保險費輔助。然而,目前對各類受雇 者給予不同比率的保費輔助,並不符合醫療外部性或殊價財的學 理依據,在現行制度下,政府之預算已無法與全民健保之收支完 全獨立,且由於政府對不同職業身分之被保險人提供不同程度的 保險輔助費,可能又使部分被保險人藉名目上之身分轉移以減輕 保費負擔,同時因全民健保主要是透過強制保險的手段以達成社 會成員疾病風險共同分擔的目的。故對該保險體系之設計與營運 權責,理應由被保險人、投保單位與政府三者共同參與,但在現 行公辦健保體制之下,政府在制度的設計握有絕對的主導權,而 必須共同負擔保費之被保險人與投保單位並無實值參與全民健 保體系的營運與規劃,實有違權利義務相稱原則,依此觀點在現 行體制下要求政府承攬較多財務責任的籲求,恐難消弭。. 29.
(30) 第四節. 預測之模式 30.
(31) 一、預測之概論 「時間數列分析與預測」係屬一計量方法 ( quantitative method ),隨著電腦科技的發展,在經濟、社會、人口、環保、 經營規劃與管理控制等領域的應用,愈來愈受到重視,預測技術 更是不可或缺的決策過程。因為透過市場環境的預測,來觀察價 格的走勢和供需結構的變化,配合系統作業模式運作,將可充分 發揮經營決策的效率,對提高經營目標水準和獲得最佳經濟效益 亦有重大貢獻(吳柏林,民 84)。 一般而言,所謂時間數列(Time Series)係指以時間順序 型態出現之一連串觀測值集合,或更確切的說,對某一動態 (Dynamic System)隨時間連續觀察所產生有順序的觀測值之集 合,假若這種集合屬於連續型( Continuous) ,則稱為連續型時間 序列。假若這種集合屬於離散型( Discrete) ,則稱為離散型時間 序列。而預測方法基本上可以分為兩種基本型態:定性方法 (Qualitative methods)與定量方法(Quantitative methods),前 者通常以專家意見為主,依據過去經驗或特殊感官功能,對未來 的事件做本質、特性的預測。後者則是將歷史事件,化成時間序 列資料趨勢圖,並判別出他們的特徵以數理方法模式化後再做量 的預測。根據林惠玲及陳正倉所著應用統計學將一些較常用的時. 31.
(32) 間序列分析方法分為:時間序列的古典分析方法、迴歸分析法、 平滑法(smoothing method)及 Box-Jenkins 方法等。常用預測之 時間序列模式如下 : 1. 長期趨勢(long trend) 2. 迴歸分析法(regressive analysis method) 3. 平均預測法(The Averaging Forecasting Method) 4. 移動平均法(The averaging Forecasting Method) 5. 加權移動平均法(weighted moving average) 6. 指數平滑法(exponential smoothing) 7. 自我迴歸移動平均整合模式 ARIMA( Autoregressive Integrated Moving Average Model) 以上預測模式 1~6 項一般使用於平穩型數列,若資料數列 屬於無定向數列或非平穩數列則不宜採用,而採用最常用之 ARIMA 分析模式。時間數列模式就是從過去的觀察值,建立一 種適合的模型來預測未來的走勢,其與迴歸模式最大的不同在於 迴歸模式對於需求量而言,皆有一組其他變數在解釋而已。以時 間模式預測未來之需求量(或觀察值),則不需要解釋變數。因 為時間數列模式預測方法之觀點是所有這些解釋變數(外生變 數、社經變數)對需求量之影響力,皆會反應在需求量本身,由. 32.
(33) 於無需考慮其他外生變數所以應用上非常簡易。. 二、選取合適的預測方法 吳柏林(民 84)指出以下幾個作決策過程時必須考量因素: 1.需要何種型式的預測 預測的型式有三種:點預測、區間預測及等第(rank)預測 。 2.預測期間多長 這要按資料與決策的性質,可能需要預測時間點只有幾天或幾 週,也有可能長達數月甚至數年。 3.有多少項目需要預測 整體而言,不須對影響系統之每項變數作預測,過多變數的預測, 反而會模糊了系統目標,在多變量模式建立過程中,五個變數之 系統結構已相當複雜。 4.預測要精確到甚麼程度 預測得精確度關係到管理決策的品質,但精確度較高的預測,相 對付出的成本與時間亦較高。 5.系統結構的轉變 由於系統結構性的轉變(structure change),導致需求或供給的時 間數列走勢與過去迥異,預測者須配合動態變化的歷史演變,建 構符合目前狀況之模式,若潛泥於過去的經驗則難以對新市場的. 33.
(34) 變遷作一準確之預測。. 三、應用 ARIMA 模式建立預測模型的文獻 目前尚未有應用時間數列單變量模式、介入模式、轉換模式 分析全民健康保險應收保費的文獻;不過從被應用在其他領域的 文獻看來,此模式仍相當值得本研究作為借鏡。從近幾年的文獻 中可知,時間數列的介入分析已廣泛應用在政策評估上,也就藉 由分析時間數列資料的變動,探討政策的效果。因此,對於本研 究針對全民健康保險應收保費的影響分析上,此模式也極具應用 之價值。 1.時間數列分析 ARIMA 模式簡介 自 1970 年初 Box 與 Jenkins 教授推展 ARIMA 自我迴歸整合 移動平均 ARIMA(Autoregressive Integrated Moving Average Model)模式,主要方法為對歷史資料分析檢視其自相關與偏自 相關等特性,應用三階段模式建構過程,在 ARIMA model 中選取 一個適當模式來做預測。而我國在中央研究院刁錦寰院士與蔡瑞 胸教授大力推廣下使得時間數列以共變數分析的方法已被證實為 一有效的統計科學方法且比光譜分析易於解釋。 預測模式的建構一般都應用三階段建構法則:一、階次認定 (Order identification)二、參數估計(Parameter estimation)三、. 34.
(35) 診斷檢定(Diagnostic checking )來協助我們得到最佳的配適模 型其流程圖(圖 2.2)如下:. 模式判定. 參數估計. 診斷性檢定. 預測. 判斷模式欠佳 圖 2.2 三階段模式建構的流程 將步驟過程說明如下: A. 階次認定(Order identification) 藉分析時間數列的特性初步選取幾種可能的模式階次(項數) B. 參數估計(Parameter estimation) 參考統計理論與計算程式,將各候選模式的參數作一良好的估 計。 C.診斷檢定(Diagnostic checking ) 應用各種檢定程序,診斷檢定那些候選模式的合適性,那一模 式較能解釋資料結果且合乎精簡原則。 2.應用 ARIMA 模式建立預測模型的文獻 鄭紹鎧(民 89)在其不穩定時間數列之預測研究指出在過 去約二十年間 ARIMA (Autoregressive Integrated Moving Average Model)模型已被廣泛地應用在時間數列分析中。相關於此模型的. 35.
(36) 選模問題,亦是統計學者研究的重點。然而,資料產生自何種模 型卻永遠無法得知。故就實用者而言,關心模型的預測能力往往 比關心它是否為真模更重要。基於上述考慮,此文將從預測的觀 點來看 ARIMA 模型的選模。首先考慮在不穩定時間數列的預測 問題上,被應用得最廣泛的模型,ARIMA (O,1,1)。自從 Box 在 1961 年提出指數平滑公式以來,使用指數平滑法取代最大概似 估計法來估計 ARIMA(O,1,1)模型中的參數,為時間數列模型中 參數的估計帶來了許多的進步。而由 George C.T Tiao 與 Daming Xu 兩位於 1993 年發表改良的指數平滑法,將向前預測的期數導 入指數平滑公式裡,使得平滑參數成為向前預測期數的函數。在 不知正確模型為何的情況之下,使用指數平滑法來進行未來期數 的預測,有相當好的表現。另外一方面,Ing(2001)則證明了對任 意階數的 ARIMA(P,l,q)模型都可以用高階(意謂階數隨著資料增 加而增加)的 AR 模型來逼近並取得真有一致性的預測結果。為 了比較兩種預測方法的好壞,以模擬的方式,在多個不穩定的時 間數列模型下,以 AIC 選取(高階的)AR 模型,並以選出模型與 指數平滑法做預測能力上的比較。發現以 AIC 選模,不僅具備 計算便捷的優點,且當資料並非來自 ARI(LIA(O,1,1)模型時,選 中的 AR 模型在預測能力上明顯優於指數平滑法;而即使資料的. 36.
(37) 確產生自 ARIMA(0,1,1)模型,AIC 的預測表現亦不遜於指數 平滑法。徐瑞玲(民 87)在其時間序列模型建立之各種分析方 法之比較與實證研究中說明時間數列分析自一九七 O 年 Box-Jenkins 發展出自我迴歸移動平均整合模式(簡稱 ARIMA(P,d,q))建立法後,便更普遍地應用於經濟、企管、工程 及物理等相關領域上。但利用 Box-Jenkins 的鑑定方法一般只對 MA 或 AR 模型有效,而對混合的 ARMA 模型則不適用。其後 陸續有統計學者提出不同的鑑定方法,但都無法有效地決定 P、 d、q 階數。直至一九八四年以後,Tsay 和 Tiao 兩位學者才又提 出了一套有效的鑑定法則,利用擴展的樣本自我相關函數 (Extended Sample Autocrretion Function)或正規分析(Canonical Analysis)求出的最小正規相關係數(The Smallest Correlation)做為 鑑定 p、d、q 的準則。這兩種方法的優點皆為可直接處理平穩或 非平穩型時間數列,而不用事先決定差分的階數,而且對混合 ARIMA 模型亦有效。對於有異常點(Outlier)存在的時間數列,其 可能由於某些外在的介入因素所引起,而 ARIMA 模型對資料的 配適是不足夠的。因此,該如何發現異常點的存在及加入合理的 介入模式亦構成了模型鑑定的問題。此文除對 Tsay 和 Tiao 的方 法做一說明外,亦利用其鑑定方法對存在有異常點的時間數列做. 37.
(38) 一分析,並由實證研究探討其對季節模型的鑑定效果。 邱雅苓(民 90)利用台灣地區 1954 至 1999 年國民醫療保 健資料,建構總體時間序列以及門檻模型,探討決定長期醫療支 出成長的因素。實證結果顯示,影響醫療支出成長的需求面因 素,包括每人每年國內生產毛額、與被保險人口比例,而供給面 因素則有每萬人口醫師數、每萬人口病床數以及失業率。這些變 數經由單根與共整合檢定,發現皆為一階穩定之序列,且變數間 在長期間有一穩定的關係。研究並以每人每年國內生產毛額、被 保險人口比例、每萬人口醫師數、每萬人口病床數以及失業率, 分別作為門檻變數;以探討醫療支出長期成長之結構性變化。結 果顯示,每人每年國內生產毛額為決定醫療保健支出的重要因素: 但健康保險的存在減弱每人每年國內生產毛額對醫療支出之影 響,甚至比每人每年國內生產毛額對醫療支出之影響更形重要。 可能由於總體資料的型態,導致實證分析並未能發現台灣醫療市 場有「供給誘發需求」的情形。此外失業率的提高,亦使得醫療 保健支出相對顯著成長,這樣的結論在失業率節節高升的今日, 實在值得政府相關單位加以重視並解決的。 另應用 ARIMA 模式建立預測模型國防預算的決定,一直是 很多學者所研究的範疇之一。其中,最常被學者們採用的國防預. 38.
(39) 算數量模型為「理性整體模型」,所謂理性整體模型是指以整體 的相關因素為考量,來決定其預算額度。其考慮期間較長,且注 重政治、經濟及國際局勢的變化對國防預算的影響。正確的國防 管理決策必須建立在良好的規劃程序之上及考量政府財政困 難。如何建立一套合理的財務規劃機制與國防財力的管理模式, 對國防預算預作有效的規劃、分配與控制,期使現今所面臨預算 不足的衝擊降到最低。陳貴強(民 87)於國防財務規劃之研究時間數列預測模式與財務決策支援系統的建立中實證結果有以 下的發現:(一)國防預算獲得預測方面;利用 BOX-Jenkins ARIMA Model 對我國國防預算進行估測,其準確度是相當高的,單變量 ARIMA (1,1,1,)模式平均預測效度為 95.5%,而移轉函數之賦稅 收入 rsb (2,2,1)模式平均預測效度更高達 99,16%,其餘之移轉函 數如 GDP、中央政府總預算平均預測效度都在 93.73%以上,表 示其對國防預算,具有高度的移轉效果,國防預算可直接分別透 過賦稅收入、GDP、中央政府總預算為投入變數進行估測。影響 國防預算因素相當多,移轉函數的選取相當重要,在長期時間的 變動需要不斷的進行模式的修正,才能選取最適模式進行預測, 以達到預測的最佳效果。(二)財務決策系統方面:利用財務決 策支援系統進行國防預算敏感度分析,可使決策者了解決策變動. 39.
(40) 對預算結構變化的影響,進而幫助決策者預判財務決策。而軍事 投資排序系統可直接運用於實務工作上,協助各單位對工作計劃 發生變動時能迅速了解其變動情形以利後續作業。楊志清(民 88)亦應用時間序列 ARIMA 模式,並加以考慮採用國民生產毛 額(GNP)、經濟成長率、國民所得與中共國防預算等因素,利用 單變量時間數列模型、轉換函數模型與動態迴歸模型等方法,來 建構較適的模型。並探討 GNP,經濟成長率、國民所得及中共 國防預算對臺灣國防預算編列之影響,以期能提供決策者參考運 用。研究結果得知台灣國防預算之編製過程會受本身資料前兩 期、中共國防預算當期及國民所得當期與前一期之影響。此一結 果,不僅可提供預算決策或管理者再於預算編審過程中的一個理 論基礎依據,並且可以將中共國防預算列為一參考指標。同時該 研究亦發現台灣國防預算的估計預測以單變量時間數列的預測 會比轉換函數模型來的準確。 Box and Tiao(1975)應用時間數列介入模式分別分析高速公 路通車和減少汽油中碳氫化合物比例的新環境法通對於洛杉磯 臭氧減量的問題,在此研究的是探討 1955 年 1 月至 1972 年 12 月間美國洛杉磯市區每月臭氧量的改變。於 1960 年初,發生兩 件與臭氧排放有關的事件,一為高速公路通車,另一為減少汽油. 40.
(41) 中碳氫化合物比例的新法案通過。這兩件事對於臭氧量的影響, 會有一個階段變化(step change)的效果。放在模式中按時點分可 設一個虛擬變數,即 1960 年 1 月前的月份設為 0,1960 年 1 月後 的月份設為 1。 依 1960 年所通過新法的內容,1966 年新出廠的 車輛都必需改裝可以減少臭氧的新引擎。此情況會緩慢的減少臭 氧排放量,故臭氧量的改變並非呈階段變化,而是呈趨勢反應, 即其反應效果將會逐年的因新引擎車輛增加而顯現出來。但如果 僅就月別資料來看,會發現這些事件對臭氧量的改變並不顯著。 經深入瞭解發現冬、夏雨季大氣溫度與陽光強度的差異,會使夏 季臭氧污染的程度高於冬季。所以另一個虛擬變數設為 1966 年 至 1970 年的 6 至 10 月月份為 1,其他為 0;第三個虛擬變數則設 1966~1970 年冬季(11,12,1~5 月)月份為 1 其他為 0。加入虛擬變 數後,時間數列介入模型分析所得到之結論如下:1960 年初的兩 個事件對於臭氧減量有顯著且持續的影響,而 1966 年後採行的 車輛引擎更新措施,在夏季臭氧有顯著的減少,但在冬季則否。 李佳叡(民 88)應用時間數列介入模式分析實施隔週休二 日對到訪森林遊樂區人數改變。此研究所用的 Box-Jenkins 的 ARIMA 時間數列分析模型及 Box-Tiao 的介入分析模型,在實證 資料分析中展現良好的分析能力,對於資料特性以及形態的掌握. 41.
(42) 完整。遊樂區遊客人數皆具有季節性,而時間數列模型可將這季 節性的部份包含於內,這是此模型的特色。然而,若以 t-test 單 純的比較隔週休實施前後,即 86 與 87 年的遊客人數,並無法解 決當遊客人數資料本身具有趨勢時所產生的誤差,也就是說 t-test 無法分辨遊客人數的增加或減少是因為資料本身趨勢所造 成或是隔週休二日的實施所造成。舉例來說,當遊客人數資料本 身具有一增加的趨勢,若此時用 t-test 檢定所得到的結果是 87 年遊客量大於 86 年遊客量,則無法得知此增加的遊客量是因其 本身增加的趨勢所造成的或是因隔過休二日的實施所造成。 Box-Tiao 的介入分析模型即是建立在資料的特性之上再去分析 介入因素所產生的影響或衝擊,故這個介入因素在模型化的分析 中可以有效的衡量。當資料本身具有趨勢及季節性週期時,時間 數列模型較其他模型更可以發揮。因此,本文的主要概念為以溪 頭、阿里山、奧萬大、墾丁、知本、太平山六處森林遊樂區為研 究對象,藉由所蒐集的 1993 年 1 月至 1999 年 6 月止之近六年半 遊客人數,並且應用時間數列介入分析模型來進行分析。此模型 主要利用虛擬變數的技術去確認介入事件所造成衝擊的程度、類 型以及持續的時間。模型分析的結果顯示,隔周休二日的實施會 對於此六個遊樂區之遊客人數產生多樣化的影響。溪頭的遊客顯. 42.
(43) 著增加,但墾丁的遊客卻顯著減少,奧萬大的遊客人數則在旺季 大幅增加,淡季時卻減少。不過,對於其他三個森林遊樂區的遊 客人數則無顯著的影響,六個森林遊樂區在規模、地理位置、地 點上的差異都可能是造成其影響程度不同的原因。. 第五節 43. 結論.
(44) 影響應收保費之因素經過文獻之探討可分兩方面,第一方面和應 收保費有關的財務問題如:納保人口、平均眷口數、眷口數上限;另 一方面和應收保費有關的財務以外之問題:經濟成長率、人口月增加 率、失業率… 等 全民健保是否能永續經營,繫於其財務收支是否能平衡,為了解 影響健保財務平衡之因素,在探究醫療費用支出方面之研究相當多, 而在探究保費收入方面則較少;在成長趨勢方面,除了要預測醫療費 用成長趨勢外,更應預測應收保費之趨勢,尤其全民健保預計於九十 一年實施西醫醫院總額支付制度,屆時將可以控制醫療費用支出之預 算,反而保費收入是否足以支付更顯重要。因此,本研究期能以時間 數列分析方法建立預測應收保費模型,提供執政者、管理者或有關單 位預測應收保費,作為訂定醫療費用成長上限之參考。. 第三章. 研究設計與方法. 44.
(45) 第一節 理論模型 一、研究架構 2.轉換函數模型. 1.單變量模型. 納保人口 失業率 人口月增加率 經濟成長率. 診斷性檢驗. 預測效益 評估. 參數估計. 建立合適 預測模型 圖 3.1 研究架構. 二、研究對象與操作型定義 1.研究變相 45. 3.介入模型 平均眷口數 眷口數上限.
(46) A.自變相 和應收保費有關的財務問題:納保人口 和應收保費有關的財務以外之問題:人口月增加率、經濟成 長率、失業率 制度修訂因素:平均眷口數、眷口數上限 B.依變相:每月應收保費 2.研究變相之操作型定義 表 3-1 研究變相之操作型定義 研究變相 一、自變相 1.納保人口 2.經濟成長率 3.失業率. 操作型定義. 變相屬性 備註. 全民健康保險被保險人數+眷 連續變項 屬數 指平均「每人實質國民所得」比率變項 之年增加率 失業人數/勞動力 比率變項. 4.人口月增加率 與上月底人口數比較,折合年 比率變項 增加率 0/00 二、依變相 1.應收保費 健保局每月所開之繳費通知 連續變項 單為準. 第二節 資料來源 本研究是以健保局應收保費、納保人口、平均眷口數、眷口數上 46.
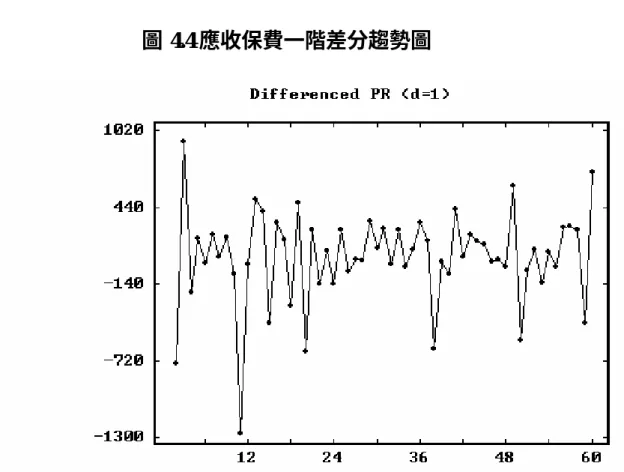
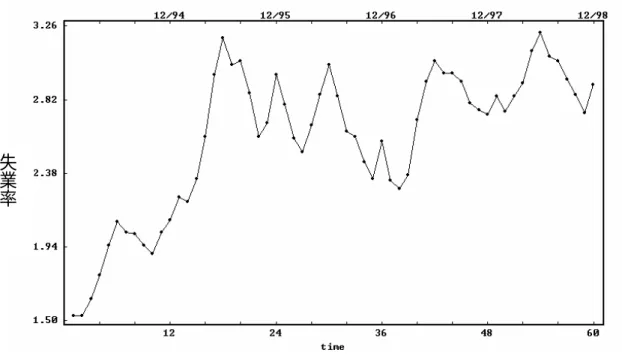
(47) 限以及經濟成長率、失業率、人口月增加率等資料為主,並蒐集上述 資料從 84 年 3 月至 90 年 6 月止共 76 筆,來進行分析,資料來源如 下:. 一、依變相 應收保費─全民健康保險統計(84 年-90 年). 二、自變相 A.納保人口 —全民健康保險統計(84 年-90 年) B.經濟成長率 —行政院財政部財稅中心資料(84 年-90 年) ,並利用內插法 將季資料轉換為月資料。 C.失業率 —行政院財政部財稅中心資料(84 年-90 年)。 D.人口月增加率 —中華民國台閩地區統計季刊(84 年-90 年) E.平均眷口數、眷口數上限 —為虛擬變相. 第三節 分析方法 本研究資料經繪圖觀察每月應收保費呈現一種不穩定的情形. 47.
(48) (Nonstationary Series),故研究方法採用時間序列(Time Series)分 析之 ARIMA 模式,以時間變數本身來解釋其變化的情形,並做預測 供決策分析、控制研究、模擬及最適分析,本研究以電腦套裝軟體 SCA 為分析工具。針對應收保費、納保人口、經濟成長率、失業率、人口 月增加率等資料分析與討論,採用時間數列中的(p,d,q)階之自我 迴歸整合移動平均模型(Autoregressive Interated Moving Average Model of order (p,d,q):單變量 ARIMA(p,d,q)模型、介入分析模 型(Intervention Analysis Model)及轉換函數模型(Transfer Function Model)等三個方式來建構出最適模型。 一、單變量 ARIMA 模型 1.模型建構及分析 以應收保費為觀測值,假設隨機變數 X,為在時間 t 的一個 觀測值,則一組 X 所組成的序列就可稱為一個隨機過程(stochastic process),為得到最適的預測模式,必須經過模型鑑定、參數估 計、模型偵測三個步驟才能完成。 2.ARIMA(p,d,q)模型介紹 自我迴歸移動平均過程係為了精簡模型,將移動平均過程與 自我迴歸過程相互結合。假設 Zt 為所觀測之第 t 期時間數列資 料,吾人並以數列{Zt }表示此數列資料。Box 和 Jenkins(l977)所. 48.
(49) 提出的 ARIMA(p,d,q)模型為 Z t = C + φ1 Z t −1 + φ 2 Z t − 2 + ...... + φ p Z t− p + a t − θ 1a t −1 −θ 2 a t − 2 − ...... −θ q at − q. … … … … … … … … … … … … … … … … … … … … … … … … (3.1) 或 (1 − φ1 B1 − φ 2 B 2 − ..... − φ p B p ) Z t = C + (1 − θ 1B 1 − θ 2 B 2 − .... − θ q B q ) at. … … … … … ..… … … … … … … … … … … … … … … … … … (3.2) 或可記為 φ p ( B) Z t = C + θ q ( B) at .…. … … … … … … … … … … … … … .… (3.3). 其中, (φ1 , φ 2 ,....., φ p ) 為自我迴歸參數, (θ 1 , θ 2 ,....,θ q ) 為移動平均參 數,C 為一常數。 此模型是目前比較常用時間數列模式其建構之模式為一重複試誤 過程(Trial and Error Interative Process)如圖 3.2 所示. 原始資料. 49.
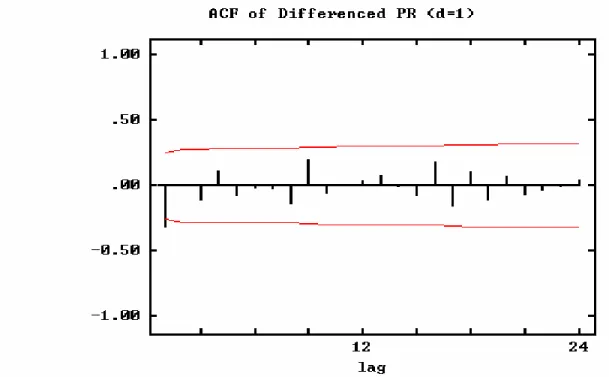
(50) 資料繪成圖形. 觀察是否為平穩數列. 否. 1. 普通差分 2.季節性差分. 是. 計算ACF及PACF. 暫定模式. 參數估計. 重新鑑定模式. 否. 模式檢定是否合適 是 預 測. 圖3.2 模型之建立與預測流程圖. 由圖 3.2 可知模式建立之程序,依序簡述如下: A. 數列繪圖觀察 首先將收集到的資料(觀測值 Zt)按時間順序繪成圖形,. 50.
(51) 觀察圖形變化情形,先觀察其波動情形,如波動太大(變異程 度很大),需作資料轉換。 B. 觀察是否為平穩數列 經由數列繪圖亦可觀察數列是否平穩,若時間數列其統計 特性不隨時間之變化而改變者,該數列即為平穩型隨機過程, 假若數列在一定週期內,其平均值逐漸上升或下降,呈現漂浮 無定向的情形,及其平均值隨時間而改變就是非平穩型數列, 則必須做適當的差分(Difference)轉化成穩定型時間數列。 差分有兩種,一種為普通的差分,另一種為季節性差分,經過 適當的差分之後無定性時間數列即轉化成穩定型時間數列。 C.差分 普通差分運算子(Difference Operator) ∇Zt = Zt − Zt −1 = (1 − B)Zt .. ∇ 2 Zt = [(Zt − Zt −1 ) − (Zt −1 − Zt −2 )]. .. … … ..第一次差分. = (1 − B) 2 Zt = (1− 2B + B2 )Z t = Zt − 2Zt −1 + Z t −2. … … … .第二次差分. 季節性差分 ∇ s Z t = Z t − Z t −s. 若為月資料 S=12. ∇ 12 Z t = Z t − Z t −12. 若為季資料 S=4. ∇ 4 Zt = Zt − Zt −4 51.
(52) D.計算 ACF 及 PACF 平穩型數列平均值 E(Zt)=μ,其變異數為 σz 2= E(Zt -μ) 2 Zt 與 Zt+k(相隔 k 個時期)之自我互變異數,以γk 表示, γ k=Cov(Zt,Zt+k)=E{( Zt -μ)( Zt+k-μ)} Zt 與 Zt+k 相隔 k個時期之自我相關係數, (Autocorrrelation at lag K)以ρ k 表示 ρk =. Cov ( Z t , Z t+ k ) Var ( Z t ) Var ( Z t +k ). =. γk γk = σ 02 γ 0. … … … … … … … … … … (3.4). 註:平穩型數列 Var(Zt)= Var (Zt+k),γ 0=σz 2= E(Zt -μ) 2, 若將ρk 當做為時間位差 k 之函數則稱為自我相關函數 (Autocorrelation Function)簡稱為 ACF;因理論值γk與ρk 均未 知,所以要以收集的時間數列資料來估計其值則ρk 之估計為 γk =. 式中. CK , K = 1, 2,3, … … … … … … … … … … … … … … … … … (3.5) C0 1 Ck = N. N −K. ∑ (Z t =1. t. − Z )( Z t + K − Z ). −. Z 為此數列之平均值,且 C0 =. 2. 1 N. N. ∑ (Z. t. − Z). 2. t −1. Zt 與 Zt+k 在相隔 k 期之偏自我相關係數(partial Autocorrelation at lag k) 以ψ kk 當作時間位差 k 之函數,則稱為偏自我相關係數 (partial Autocorrelation function),簡稱為 PACF。及{ψ kk:k=1,2,3… } 為不同時間位差之偏自我相關係數之集合。 52.
(53) 計算 ACF 及 PACF 之目的是初步決定 ARIMA 模式的階數 (p,q),當自我相關函數 ACF 不容易很快消失時,顯示該數列為 一無定向型數列。故首先需對數列取差分一直到數列之 ACF 很 快的消失為止,即表示數列已經差分後轉換成為平穩型數列;此 時所差分之次數則以 d 表示之。其次,再依樣本之 ACF 與 PACF 來決定 ARIMA(p,d,q)中的 p 與 q 值,以判斷數列應屬於何種模 型。 E.暫定模式 自我迴歸整合移動平均模式( ARIMA)是由自我迴歸過程 (Autoregressive)與移動平均過程(Moving Average)兩者整 合而成,如果數列為非平穩數列,則必須先差分,故其基本模 式之形式為: φ p ( B )∇ d Z t = C + θ q ( B) at … … … … … … … .… … … … … … … (3.6). 是經過 AR(p)、MA(q)差分結合而成,茲分述如下: a.自我迴歸過程 設 Zt ,Zt-1,Zt-2… … 代表一時間數列之隨機過程,當期之數 值 Zt 是同一數列諸個前期之數值 Zt-1,Zt-2… … Zt-p 迴歸,即是諸 個前期之數值和當期干擾項 at 之線性組合 Z t = C + φ1Z t−1 + φ 2 Z t −2 + ...... + φ p Z t − p + at. 53.
(54) C:常數項;φi:自我迴歸參數 上式稱為 p 階自我迴歸模式,簡稱 AR(p)。即該是以 Zt 做應變數,而以諸個前期之數值當作自變數之迴歸模式 AR( p) 過程,可藉後移運算子(Backward Shift Operator)B 來改寫為 Z t = C + (φ 1B 1 − φ 2 B 2 − ... − φ p B p ) Z t + at … … … … … … … … ...(3.7). 或 (1 − φ1 B1 + φ 2 B 2 + ... + φ p B p ) Z t = C + a t … ..… … … … … … … ..(3.8) 令 φ p ( B ) = 1 − φ1 B1 − φ 2 B 2 − ... − φ p B p 則 3.8 式可記為 φ ( B ) Z t = C + at … … … … … … … … … … ..… … … … … … … ..(3.9). 後運算子 B 之定義為 B1 Zt = Zt-1 B2 Zt = Zt-2 Bj Zt = Zt-j 以上為 AR(自我迴歸)過程 b.移動平均過程 對有限的移動平均過程其模式簡稱為 MA(q)為諸個有 限個前期的震動 at 之線性組合 Z t = u + at − θ 1a t−1 − θ 2 at −2 − ...... − θ q a t− q …. … … … … … … … … (3.10). 式中-θ1,-θ 2,… ,-θ q 為一有限集合之權數,權數之負號僅為方. 54.
(55) 便計算之用。模式 3.10 表示 q 皆之移動平均過程利用後移運算 子 MA(q)可表示為 Z t = u + (1 − θ 1B 1 − θ 2 B 2 − .... − θ q B q ) at = u + θ q ( B )a t … … .… … .(3.11). 式中θ q ( B ) = (1 − θ1 B1 − θ 2 B 2 − .... − θ q B q ) at c.混合自我迴歸與移動平均過程 在同時考慮 AR(p)與 MA(q)兩個模式,近一步建立 兩者之結合模式可獲得更為精簡之模式,此種模式一般稱為 (p,q)階混合自我迴歸與移動平均過程( Mixed Autoregressive Moving Average Process of Order(p,q)),其型式為: Z t = C + φ1 Z t−1 + φ 2 Z t − 2 + ...... + φ p Z t − p + a t − θ 1at −1 − θ 2 a t− 2 − ...... − θ q at − q. 或 (1 − φ1 B1 − φ 2 B 2 − ..... − φ p B p ) Z t = C + (1 − θ 1B 1 − θ 2 B 2 − .... − θ q B q ) at … … … … … … … … … … … … … … … … … … … … … … … … … … … … … … … … … … … … … ... (3.12) 即 φ p ( B) Z t = C + θ q ( B )a t … … … … … … … … … … … … … ..(3.13) 上式簡稱為 ARMA(p,q),式中(φ1, φ 2,… ., φp)稱為自我 迴歸參數,(θ1 ,θ 2 ,… .θ q)稱為移動平均參數,C 為一常數。 當數列為非平穩數列時就必須差分,定義差分運算子 (Difference Operator)∇為 ∇Zt =Zt -Zt-1=(1-B)Zt … … … … … … … … … … … … … (3.14). 55.
(56) 因此, ∇與後移運算子 B 之間關係為∇=1-B 故 ∇2=(1-B) 2 ∇3=(1-B) 3 ∇d=(1-B) d d.自我迴歸整合移動平均模式 經過 d 次差分(d>0)後之數列再以 ARMA 模式來表示就 成為自我迴歸整合移動平均模式(Autoregressive Interated Moving Average Model)或簡稱為 ARIMA(p,d,q),亦即是前述(3.6)式 φ p ( B )∇ d Z t = C + θ q ( B) at. p,d,q=非負整數 B=後移運算子 ∇=差分運算子. φ P ( B ) = 1 − φ1B − φ2 B 2 − .... − φ P B p θ q ( B ) = 1 −θ1 B − θ 2 B 2 − ..... − θ q B q at =時間為 t 期之干擾項 { at }為白噪音(white noise)過程 F.參數估計 當一般數列被鑑定為某種形態之模式後,必須利用統計理. 56.
(57) 論對暫定模式所含有的未知參數推算出最佳或最有效的估計 值。假設一時間數列 Z1,Z2,… .Zn 可用 ARIMA(p,d,q)模式暫定, 也就是 a t = Wt − φ Wt−1 − ..... − φ pWt− p − C + θ 1 at −1 + .... +θ qa t− q … ..… … … (3.15). (3.15)式中,wt=(1-B)dZt,已知白噪音 at 為一常態分配,期望值為 零,變異數為σ a ,所以其密度函數為 2. P at. σ. 2 a. a2 exp − t 2 … … … … … … … … … … … … .(3.16) 2 2σ a 2π σ a 1. =. −. n. n 2 −2. P W φ , θ , C,σ a = (2π ) 2 (σ a ) 2. ∗. … (3.17) 1 n 2 exp − (Wt − φ1Wt −1 − ... − φ pWt − p − C + θ 1at + .... + θ q a t− q ) 2∑ 2σ a t=1 . (3.17)上式中W , φ ,θ , 分別為 Wt,φ,θ的列向量。當一組資料 已知時,參數的概似函數為 −. n. 2 −. L φ ,θ , C ,σ a W = (2π ) 2 (σ a ) 2. n 2. 1 n 2 ˆ … … … (3.18) exp − a ( φ , θ , C ) t 2∑ 2σ a t=1 . (3.18)式中 aˆt 為經由已知的觀測值與擬合值計算而得的,即 aˆt = Wt − E Wt Wt −1 ,Wt − 2 ,.... 。再對(3.18)式取對數形式,可得 S (φ ,θ , C ) n n 2 2 InL φ , θ , C,σ a W = − In ( 2π ) − Inσ a − … … … … ..(3.19) 2 2 2 2σ a n. (3.19)式中 S (φ , θ , C) = ∑ aˆ(φ ,θ , C ) 2t 表示誤差項的平方和函數。 t =1. 因為 InL φ , θ , C,σ a W 中只有 S (φ ,θ , C ) 含有含參數φ ,θ ,所以為求 2. 57.
(58) Max InL φ , θ , C,σ a W 就是求 MinS (φ ,θ , C )。在φ ,θ , C 這些參數決定後 2. σˆa 的最大概似估計值為σˆa =. S (φˆ,θˆ, Cˆ) n. 。. G.模型鑑定 一數列經過模型檢定、參數估計得到最佳估計值後,還須 利用檢定方法檢定所得模型與數據之配合是否適當,是否可準確 的代表所觀察之現象及模式是否合乎精簡原則,如果所得模型無 缺適當性,則模型可供應用;反之,若模型不適當,則必須重新 進行鑑定、估計與診斷、檢定的步驟,直到能獲得一適當模型為 止。模型偵測的主要工具是殘差(Residuals)。在應用時若殘差通 過獨立常態 N(O,σ 2a)之分配檢定,則吾人可宣稱{Xt }為由此一 ARIMA(p,d,q)模型產生。 當一組數據被鑑定為某一模式且其參數亦經由電腦估計程 式求得最佳估計值後,對於這樣一個暫定的模式,還需要利用 各種檢定方法來判斷擬合數據是否適合此一模式,其中最可靠 的方法為從擬合模式中計算殘差 aˆt 之樣本自我相關函數,首先 考慮 aˆt , t = 1,2,3,..., 一般化模式 ARIMA(p,d,q)為 φ p (B )Wt = θ q ( B )at. 且. Wt (1 − B ) (Z t − µ ) d. 其近似最大可能估計值被估計為 (φˆ,θˆ) ,則可得 58.
(59) aˆt =. ˆ θˆ (B )φ (B )ω −1. p. q. t. 一般稱此 aˆt , t = 1,2,3,......, k 為無法觀察得到的隨機震動之估計 值。假若暫定的模式事實上是正確的話,則可以證得 at ,t=1,2,3,… .k 為獨立之隨機震動,使得 at 之自我相關值ρk 皆等 於 0,即ρk=0,. k=1,2,3,… .,k。因此,利用從計算 aˆt 之樣本自我. 相關值γ k γ k (aˆt ) =. ∑ (aˆ − aˆ)(aˆ − aˆ) , k = 1,2,3,....., k ∑ (aˆ − aˆ) t− k 2. t. … … … … … … … … .( 3.20). t. 因此,參數估計後,對一個暫定的模式,需要檢定模式是否適 合,檢查的方法有二: a.γ k = ( aˆt ) 變異數 當 n 很大時,{at }之自我相關係數 γ k = ( aˆt ), k = 1,2... 為不相關 且近似常態分配,其平均數為零,標準誤差為. 1 ,一般可利用 n. 2 之值判定γ k = ( aˆt ) 是否 n 2 為白噪音數列,若超出兩倍標準差 ,就不適當。 n. 逐一檢定γ k = ( aˆt ), k = 1,2,... 是否超過. b.整體 χ 2 準則 當有大量觀測值且 at 為獨立之 N = ( 0,σ a ) 數列,則 2. 2 ) Q = n∑ γ (a t ) ~ k. k =1. k. χ. 2 k − p− q. … … … … … … … … … … … … … … ..(3.21). (3.21)式中 n 為實際{a) t } 之個數,k 為所計算之殘差自我相關 值之個數,p 與 q 為模式之參數個數。若 Q > χ (1−α , k − p− q ) 表示殘 2. 59.
數據


+5
相關文件
臺中榮民總醫院埔里分院復健科 組長(83年~今) 中山醫學大學復健醫學系職能治療 學士.. 南開科技大學福祉科技與服務管理研究所
三、有關長期失業者要件之「連續失業期間達 1 年以上」,係指自失業者 至公立就業服務機構辦理資格認定之日起算,原則應依勞工保險加退
3.CKD Stage 5 病人照護目標,應進行慢性腎臟病之醫病共同決 策(Shared Decision Making,
一、本部同意臺中榮民總醫院詴驗主持人變 更為李建儀醫師。二、本詴驗主持人應任用
考試應攜帶國民身分證(或仍在有效期限之駕照、有照片之健保卡或護照),以備查
(二)社會組、長青組、壯年組、媽媽組,應攜帶國民身分證 或健保卡正本 (外籍選手
二、應檢人員須攜帶附有照片足資證明身分之國民身分證、護照、全民健康保險卡或駕駛執 照之身分證明文件、准考證、術科測試通知單及規定之自備工具應檢,請於 7
近年來,大蒜對人體保健及疾病治療的研究陸續發表,許多人開始重視大蒜在醫療上,以及保健方面
