行政院國家科學委員會專題研究計畫 成果報告
以語料庫為本之西班牙語過去式的分析:結合學習者語料
庫與電腦輔助錯誤修正之研究
研究成果報告(精簡版)
計 畫 類 別 : 個別型
計 畫 編 號 : NSC 98-2410-H-006-074-
執 行 期 間 : 98 年 08 月 01 日至 100 年 02 月 28 日 執 行 單 位 : 國立成功大學外國語文學系(所)
計 畫 主 持 人 : 盧慧娟
計畫參與人員: 碩士級-專任助理人員:張展毓
碩士班研究生-兼任助理人員:陳亞杰 碩士班研究生-兼任助理人員:張展毓 碩士班研究生-兼任助理人員:何治儀 大專生-兼任助理人員:張以姍
大專生-兼任助理人員:張偉婷 大專生-兼任助理人員:林于涵 大專生-兼任助理人員:鄭潔 大專生-兼任助理人員:陳姿均 大專生-兼任助理人員:蘇珮瑄 大專生-兼任助理人員:洪昭綿
博士班研究生-兼任助理人員:白芳怡
報 告 附 件 : 出席國際會議研究心得報告及發表論文
處 理 方 式 : 本計畫可公開查詢
中 華 民 國 100 年 05 月 13 日
行政院國家科學委員會補助專題研究計畫 ■ 成 果 報 告
□期中進度報告
以語料庫為本之西班牙語過去式的分析:
結合學習者語料庫與電腦輔助錯誤修正之研究
計畫類別:■個別型計畫 □整合型計畫
計畫編號:NSC 98-2410-H-006-074-
執行期間: 98 年 8 月 31 日至 100 年 2 月 28 日
執行機構及系所:成功大學外文系
計畫主持人:盧慧娟
共同主持人:鄭安中
計畫參與人員: 張展毓、劉亭佑、陳妤婷、林雨蓁、林于涵、張以姍
成果報告類型(依經費核定清單規定繳交):■精簡報告 □完整報告
本計畫除繳交成果報告外,另須繳交以下出國心得報告:
□赴國外出差或研習心得報告
□赴大陸地區出差或研習心得報告
■出席國際學術會議心得報告
□國際合作研究計畫國外研究報告
處理方式:除列管計畫及下列情形者外,得立即公開查詢
□涉及專利或其他智慧財產權,□一年□二年後可公開查詢
中 華 民 國 100 年 2 月 28 日
一、 前言
語料庫語言學近一、二十年來的蓬勃發展為語言學研究開展了寬廣的視野,並成為語言學學門發 展中的重要潮流。計畫主持人因多年來進修方向與所進行之研究工作多與語料庫語言學有關,故對其 開發技術、應用工具與研究法皆有相當程度的接觸與認識;而近五年來所執行的國科會專題研究計畫 即是以自行建置的語料庫語料為分析對象,進行系列性之學習者語言的研究工作。
為突破與改善過去幾年來在語料庫建構和研究過程中所遭遇的瓶頸與困難,以其累積之相關研究經 驗為基礎,並輔以語料庫顧問盧文祥教授和協同主持人鄭安中教授的支援、協助與共同合作,本計畫 除結合電腦輔助機器學習錯誤偵測,以拓展台灣第二外語學習者語料庫的研發外,同時配合理論進行 在語言學之外語習得模式的分析與探究。主持人過去十年來主要以句法結構、詞彙搭配和聯繫動詞為 語言分析的研究重點;在搭配語料庫機器學習進階技術之語言分析主題與方向的延伸上,本計畫選定 西班牙文兩種過去式的研究。此一以語料庫為本的研究,結合資訊科技和應用語言學的分析探討,具 研究之學術與應用價值。
二、研究目的
本計畫的主要目的在於探究電腦輔助機器學習模式應用於語料庫研究的成效,以延伸學習者語料 庫建構的成果。在語料庫的建置工作方面,除豐富語料類型與逐年擴增語料量外,並透過語料庫工具 的輔助及標誌註記之軟體程式的應用與配合,進階至對西語學習者語料及西語母語者修正文語料在機 器學習層面的對比分析研究,並進而開發錯誤偵測與辨識的程式,以期達到半自動化辨識與修正學習 者語料的最終目標。最後,則輔以台灣西語學習者應用語言學領域的分析,進一步延伸語意之相關主 題,選定「過去式」的研究範疇,搭配西文兩種過去式的學習為研究主題,進行普遍化之學習者語料 正誤(學習者之目的語和中介語)對照的分析,以瞭解彼此間之差距及推論其相關因素,並進而驗證 應用語言學相關文獻所提出之理論與原則,以充實過去一系列有關西語學習的研究結果,逐步達到提 升學習成效之目標。針對錯誤偵測和過去式習得兩研究方向進一步分述如下。
(一)錯誤偵測
過去相關研究指出,有效地給予糾正對語言學習來說,具有正面的學習效果(Kubota, 2001; Lee, 2004; Truscott, 2007; Truscott & Hsu, 2008)。當今使用電腦來修正學習者的錯誤已是一種趨勢(Dagneaux, Denness, & Granger, 1998; Olsen & Williams, 2004),而如果這類錯誤修正是基於功能導向來提供的話,
學習者更可以從中探究錯誤的原因。本結案報告中將介紹一個可以用來幫助西班牙語學習者偵測錯誤 的系統之初步成果。不同於以往的研究,此套系統主要是從我們所建構的「台灣西語學習者語料庫」
(CATE) (Lu, 2010)擷取語料來進行分析,同時兼顧單一單位(the single-gram level)和多單位層級(the n-gram level)的錯誤檢測模式,並歷經預先訓練的過程。
(二)過去式習得
針對語言分析的主題,我們將回答以下兩個研究問題:1.在西班牙語兩種過去式(簡單過去式和 未完全過去式)和兩種聯繫動詞(ser 和 estar)的互動關係中,透過西班牙語兩種過去式出現在「ser 和
estar 加形容詞」的結構,觀察不同語言程度的台灣西語學習者的語言使用在書面表達的發展模式所呈 現的階段程序是什麼?2.在上述結構中,西語學習者在時態動貌上的選擇傾向為何?
三、文獻探討
相關文獻分以下兩方面探討。
(一)錯誤偵測
根據 Kukich 的研究(Kukich, 1992),處理語言錯誤主要有三個程序:1.必須找出錯誤發生的地方。
2.將錯誤的訊息提供給資料庫去進行最大可能性的判定。3.根據已知的資訊來修正錯誤。早期,所謂的
「錯誤修正」僅侷限在初階層級,如:檢測多餘、遺漏或錯誤的字母(Szanser, 1970)。大部份的人認為 很難為錯誤偵測建立一套普遍的規則。因此,有一些研究人員試著透過外部的訊息來達到錯誤修正的 目標,如:Golding et al. (1996)結合部分的語音資訊及貝氏統計方法來檢測拼字錯誤;Kyongho et al.
(Kyongho, H, & Yoo-Jin, 2000)則在考慮錯誤中字彙出現的頻率或字元間的距離等特點;Fossati et al.
(Fossati & Eugenio, 2007)則使用一個混合三單位元的機制去探勘拼字的錯誤。
探測錯誤的工具在西班牙文方面的開發成果尤其有限,如:GramCheck (Bustamante & León, 1996) 可以偵測到配合、介系詞、被動式使用及動名詞的錯誤;Galicia-Haro et al. (1999)利用詞類系統(POS) 所提供的資訊去偵測重音錯誤;Kolesnikova et al. (Kolesnikova & Gelbukh, 2010)透過監督式機器學習技 術偵測西班牙語動詞和名詞搭配兩單位元組合的錯誤。此外,免費的西班牙語拼字與文法檢查的線上 網 站 (http://lomastv.com/free-online-spanish-spelling-grammar-checker.php) 及 免 費 的 線 上 拼 字 檢 查 (http://www.jspell.com/public-spell-checker.html)是兩個西文學習的線上資源,而這兩個線上的學習網 站,錯誤修正的層級僅限於拼字和陰陽性、單複數、人稱配合的檢查。
(二)過去式習得
中文和印歐語系在時態和動貌上最大的相異在於動詞的表現方式。印歐語系像是西班牙文或英文 是透過動詞字尾變化和時間副詞來表達現在、過去與未來的時態和動作正在進行或已經完成的動貌。
然而,中文卻無動詞變化形式,而是由時間副詞、詞彙語意、篇章中的上下文語意和語用以及由助詞 像是「了、在、著」來表達時態和動貌。因此以中文為母語的學習者在學習西班牙文時,必須改變過 去處理時態與時貌的習慣並學習藉由動詞表達時態與動貌的方式。
Vendler (1967)指出詞彙動貌代表著動詞與動詞述語的內在詞彙語意,依不同類型的動詞述語區分 四種基本動貌類型:狀態、活動、實現和完成。動詞形式的分類還可以以三種基本語義特點區分:動 態、持續和結束性(Comire, 1976; Andersen, 1989, 1991)。在 Vendler 的四項分類中,只有「狀態」是屬 於非動態述語,而只有「完成」是非持續性的。在動態的類型中,「實現」和「完成」是有結束點的;
反之,「活動」則無與生俱來的結束點。
在第二語時態動貌之語言習得的相關理論與研究中,時態動貌的差異可由語意、言談和語用三個 不同的語言學層次作區分。有關闡釋在課堂中學習外語的學生如何藉由詞尾變化來標記時態動貌的主
要理論框架包括:詞彙動貌理論(語意觀點)、言談理論(上下文觀點)、預設的過去測試理論(認知觀點) 和普遍語法假說(句法因素)。配合我們語料庫進階技術的研究,在語言分析的討論上將著重於詞彙動貌 理論(語意觀點)的探討。詞彙動貌理論(Lexical Aspect Hypothesis)由 Andersen (1986, 1991)所提出,嘗試 針對時態動貌詞素和詞彙動貌類型之關聯性做出解釋。該理論指出:在語言發展的初期階段,學習者 的時態動貌使用是依據其與生俱有的詞彙動貌為判斷基礎。也就是說,初學者不會對時態或文法動貌 編碼。Andersen (1991)認為第二語學習者在動貌習得發展中有以下的漸進程序:由「瞬間的」到「具 結束性的」到「動態的」,最後才到「狀態的」。Andersen (1986)提出第二語學習者在學習西班牙語時 態的發展程序是:簡單過去式的使用從瞬間的非持續性詞彙類的動詞(完成)開始逐漸發展到持續性,然 後到狀態性詞彙動詞;而未完成過去式的使用是從狀態性詞彙逐漸發展到非狀態性詞彙動詞;共有八 個發展階段的排序,如表一所示。
表一 發展階段排序 階
段
狀態 活動 實現 完成
1 現在式 現在式 現在式 現在式
2 現在式 現在式 現在式 簡單過去式
3 未完成過去式 現在式 現在式 簡單過去式
4 未完成過去式 未完成過去式 簡單過去式 簡單過去式
5 未完成過去式 未完成過去式 簡單過去式/未完成過去式 簡單過去式
6 未完成過去式 簡單過去式/未完成過去式 簡單過去式/未完成過去式 簡單過去式
7 未完成過去式 簡單過去式/未完成過去式 簡單過去式/未完成過去式 簡單過去式/未完成過去式
8 簡單過去式/未完成過去式 簡單過去式/未完成過去式 簡單過去式/未完成過去式 簡單過去式/未完成過去式
表一顯示:表完成的標誌(簡單過去式)最早出現在完成性詞彙的動詞的第二階段,在實現詞彙是 第四階段以及表活動詞彙的第六階段,而表狀態之詞彙是則直到第八階段才出現。另一方面,表未完 成(未完成過去式)的標誌出現得較晚,是從表狀態的第三階段逐漸擴展到表活動的第四階段,在表實 現和完成的詞彙動詞則分別到第五階段和第七階段才出現。
四、研究方法
(一)錯誤偵測 1. 語料來源
本計畫成果的錯誤偵測系統所使用的資料是來自我們之前語料庫的建構成果「台灣西語學習者語 料庫」(CATE, Lu (2010), http://corpora.flld.ncku.edu.tw/)。西語學習者語料庫是一個從 2005 年開始收集 的第三語學習者書面語語料庫,具有多面向的檢索查詢功能。目前可公開檢索的內容是 2005-2006 年 所收集,共 1,058 篇文本(181,322 字)。其特色之一是所有的學習者語料皆經由西語母語者修正過。本 研究篩選其中文章長度超過100 字者,共使用 669 篇修改過的修正文作為分析的語料來源,計 119,192 個字。每篇文章皆透過Tree Tagger (Schmid, 1994)進行 POS 標記,以提供訓練階段的額外訊息。
2. 單一單位層次
從過去的研究不難發現大部分發生在單一單位層次錯誤偵測中的誤判多與專有名詞有關。為解決這 個問題,我們設計一個建有專有名詞清單的資料庫架構,用它來檢查匯入的新文章。此架構系統在偵 測單一單位層次的錯誤主要分兩部份進行。在修正的文章中,我們會先消去特殊的字元及POS 標記的 字(標號、非西文)。接著,建立一個關鍵值架構,以用來編存成一個特定的單字列表。為了獲取專有名 詞列表,我們進一步保存名詞及那些不明的詞類訊息以進行研究,並將之儲存於專有名詞暫存資料庫 中。當我們集合了資料庫裡的專有名詞,匯入的字可先與關鍵值的語言模型做比對。上述單一單位的 錯誤偵測在我們的系統中是應用 Python 程式語言和標記語言(HTML)格式輸出。從我們的資料來源當 中,我們截取了10,535 個字及 1,292 個專有名詞來當作我們的語言模型。
3. 多單位層次
只在單一單位層次上進行錯誤回報對學習者而言是不足的,進一步去檢測文法上的錯誤絕對有其必 要性。在我們系統上多單位的錯誤檢測主要是基於「聯結式架構(cascade architecture)」完成的。使用聯 結式架構,早期錯誤會很快地被回報出來。我們使用Python 程式語言去執行這個架構,設定單位數 n 為3。每個聯結式架構代表著一個基於 POS 標記結果的群組,每一個結構中包含三個相關的連續階段:
詞類(POS)、字根(lemma)和字(word)。首先,將新的多單位字串放入 POS 訊息中檢查它在第一階段的 POS 排列,如果多單位在 POS 排列上不符合 POS 階段的模組,就不是一個正確的組合,因此會被判 定成一個錯誤。在第二個階段中,我們進行字根間連結的檢查,若多單元字根沒有符合建構的模型,
那就表示有錯誤的存在。最後,檢查單字的組合,如果沒有和語言模組配合,那就會被判別為錯誤,
例如,時態錯誤等。
(二)過去式習得 1. 語料來源
所分析的語料是透過檢索「台灣西語學習者語料庫」的書面語語料,目前已收集了近 2,500 篇的 文本,約 34,000,000 字的語料。西語學習者語料庫的檢索可以限定學習者的條件以及文本的特性,藉 由輸入關鍵字,針對所搜尋到的語料進行觀察與分析。因為每一篇作文都經由西語母語者修正過,所 以可以進行正誤對比的分析與研究。過去式習得研究所採用的語料是「西語學習者語料庫」中2009 年 針對兩個聯繫動詞(ser 及 estar)使用所收集到的語料。語料收集的過程包括:參與者必須在四十五分 鐘內,在不使用任何工具書的情況下,敘述圖畫中的故事寫下兩篇作文。參與者包括了淡江大學、靜 宜大學、文藻外語學院以及成功大學外文系西語組的學習者。
2. 語料分析
在文本中,如果沒有使用到任何一次過去式,我們便不予採用。這些參與者在參與語料收集的活 動前皆接受西文能力的檢定,我們藉此來客觀區分學習者的西文程度,以避免使用學習時數做為區分 的標準而造成與學習者真正的西文語言程度間之誤差。根據西文能力的檢定結果,將參與者分為初階 與中階兩個西文程度。本研究共分析了108 篇的文本,總字數量是 23,000 字。我們使用西班牙馬德里 自治大學的語料庫工具(UAM Corpus Tool),設計了 32 個註記類型,再針對我們的語料一一進行過去式
時態與動貌的註記,共註記了2,074 筆資料。
五、結果與討論
(一)錯誤偵測
在我們的測試實驗中,資料是從語料庫中隨機選擇了 10 篇學習者原始文,單一單位及多單位層級 則是分別處理,其結果藉由與語料庫的修正文相比較,以作為評估的參考依據。測試的文章是學習者 的作文,如圖一所示,我們以顯眼的底色標示出單一單位的錯誤,將滑鼠移至錯誤處時,更正建議會 顯示在錯誤近處的框格內作為提示。此外,還可以在每篇文本的下方得知錯誤的總數。
圖一:單一單位之錯誤偵測結果與修正建議
另一方面,在多單位錯誤偵測的結果中可以觀察到每三單位在測試的文章中皆包含 POS 標示的錯 誤組合(見圖二),其結果可與語料庫的修正文做比較。例如,句子包含三個單位”uno quiera ganar”在 原文的右手邊為被標記的錯誤及在左手邊是被母語者修正的部份(見圖三,文章中藍色底線和字的部 份)。另外,圖四呈現字根和單字層級的錯誤偵測結果:在句子有一個三單位的字串“no necesita tener”
包含了一個被偵測到的錯誤,根據「台灣西語學習者語料庫」原始文(見圖五)所被標示的錯誤,在修正 文中被西語母語者修正為“no se necesita tener”。
圖二:多單位層級在詞類階段的錯誤偵測結果
圖三:「台灣西語學習者語料庫」原始文與修正文對比結果
圖四:多單位層級在字階段的錯誤偵測結果
圖五:「台灣西語學習者語料庫」原始文與修正文對比結果
(二)過去式習得
我們的研究結果顯示,在正確度方面,學習者使用時態的傾向分別從正確度最高的現在式到過去 式。如果進一步把過去式部分以動貌區分為簡單過去式和未完全過去式時,未完成過去式的正確率是 高於簡單過去式的。從發展階段的角度而言,正確率都是中階的學習者高於初階的學習者。我們可以 勾勒出以下發展趨勢圖,那就是從現在式開始發展,接著下一步是未完成過去式,最後才是簡單過去 式。在詞彙動貌假說當中,Andersen 所提出的理論對於我們所研究的狀態動詞而言,以英文為母語的 學習者,他們的學習模式是先從現在式的正確使用逐漸進展到未完成過去式,再到簡單過去式。而我 們的以中文為母語的學習者在時態與動貌習得發展階段的初期研究結果和過去以英文為母語的學習者 之相關研究結果類似。因此我們目前的研究發現可以回答我們所提出的第一個研究問題(在西班牙語 兩種過去式(簡單過去式和未完成過去式)和兩種聯繫動詞(ser 和 estar)的互動關係中,透過西班牙語 兩種過去式出現在「ser 和 estar 加形容詞」的結構,觀察不同語言程度的台灣西語學習者的語言使用 在書面表達的發展模式所呈現的階段程序是什麼?)。
接著,我們進一步去比較未完成過去式與兩個聯繫動詞ser 和 estar 互動的表現情形。研究結果顯 示:在初階的學習者當中,ser 所達到的正確率位高於 estar。此一結果與我們過去只研究聯繫動詞在現 在式的使用正確率的發現相同。另一方面,當我們只針對中階學習者的聯繫動詞在過去時態使用正確 率進行觀察時,estar 的聯繫動詞正確率反而高於 ser;而在 ser 和 estar 都是表狀態的聯繫動詞情況下,
以中文為母語的學習者對描述一個動作結果的「estar+形容詞或過去分詞」結構,正確使用率較高。這
可能與此一結構在西語中較高的出現率有關,但仍須進一步的研究才能驗證此推論。總之,此一研究 發現支持Andersen 所提出的詞彙動貌理論對表狀態的動詞的假設。這樣的研究結果可以讓我們去回答 研究問題二(在「ser/estar+形容詞或過去分詞」結構中,西語學習者在時態動貌上的選擇傾向為何?)。
接著,我們進行母語者的語料分析研究,我們從母語者語料庫搜尋語料來進行第一語和第二語的 轉移研究。首先,在母語者語料庫方面,西語的母語者語料庫採用的是「西班牙語語料庫」(Corpus del Español),西班牙語是我們學生的第三語;而在第二語語料庫方面我們所採用的是「現代英語語料庫」
(Corpus of Contemporary American),這是我們學生的第二語;而在學生的母語中文方面,我們所採用 的是中研院的「現代漢語平衡語料庫」。我們以學習者作文語料當中所出現的形容詞作為關鍵字,分別 以西文、中文和英文從上述三個語料庫的語料中搜尋,根據搜尋結果的分析結果如下:在西語方面,
特別針對狀態動詞而言,我們發現未完成過去式其使用率高於簡單過去式;而在英文的查詢方面,我 們發現英文區分動貌的過去式和過去進行式,以過去進行式而言,其出現頻率是較低的。在應用方面,
我們可善用西文和英文的查詢結果結合於西語教學中。另外,在中文的語料庫部分,我們觀察到四個 動貌標誌「過、在、著、了」在我們所研究的狀態動詞當中並沒有發現足以證明正向轉移的充分證據。
六、結論
(一)錯誤偵測
在學習者文本的錯誤偵測的測試結果中,我們已可做到:標示單一單位的錯誤與提供修正建議,並 計算出錯誤總數。另外,在多單位(目前設定為 3)錯誤偵測的結果中可以觀察到詞類、字根或詞彙 的錯誤組合,其結果可與「台灣西語學習者語料庫」的母語者修正文做比較。
截至目前為止,在多單位層級的偵測結果的視覺化處理上對使用者的便利性仍嫌不足,還需要更進 一步提升。未來,我們將結合組塊技術(chunking technology) 提供使用者在多單位層級錯誤偵測的 結果報告,並進階至以短語為本的錯誤偵測結果。
(二)過去式習得
我們的研究結果顯示:時態動貌的習得在狀態動詞對於以英語為母語和以中文為母語的外語學習 者在學習西文時其習得程序是類似的:他們在時態上面都是先習得現在式,接下來才是過去式;而過 去式在狀態動詞這一類是先習得未完成過去式,也就是他們的預設值,再習得簡單過去式。另外,我 們更進一步在未完成過去式的分析中發現:以中文為母語的西語學習者較早正確使用聯繫動詞當中的 ser,而非 estar。最後根據我們對母語語料庫的檢索以及分析結果,認為學習者的第一語中文和第二語 英文在我們所研究的狀態動詞當中,對於第三語西班牙語的習得並沒有充分的證據足以顯示「轉移」
在其中扮演了具影響性的角色。在未來研究工作中,我們將持續分析相關的語料,特別是針對我們所 持續建構的語料庫在2010 年所收集到的「小紅帽」看圖說故事的文本,我們將進行其他述語類型動詞 的語意分析,來增進對過去式研究主題的全面性探討。
七、參考文獻
Andersen, R. (1986). El desarrollo de la morfología verbal en el espanol como segundo idioma. In Meisel, J.
(Ed.), Acquisición del Lenguaje/ Aquisição da Linguagem. Frankfurt/M : Vervuert.
Andersen, R. (1989). The theoretical status of variation in interlanguage development. In S. Gass & C.
Madden (Eds.), Variation in Second Language Acquisition volume II: Psycholinguistic Issues (pp.
46-64). Clevedaon, Avon: Multilingual Matters.
Andersen, R. (1991). Developmental sequences: The emergence of aspect marking in second language acquisition. In T. Huebner and C.A. Ferguson (Eds.). Crosscurrents in Second Language Acquisition and Linguistic Theories (pp.305-24). Amsterdam: John Benjamins.
Bustamante, F. R., & León, F. S. (1996). GramCheck: a grammar and style checker. Paper presented at the Proceedings of the 16th conference on Computational linguistics - Volume 1.
Chang, Cheng-Yu and Hui-Chuan Lu. 2010.12. “Corpus-based Error Detection for Learners of Spanish.” The Fourteenth International Conference on Language Instruction of ROCMELIA. Kaohsiung, Tiwan.
Comrie, B. (1976). Aspect. Cambridge: Cambridge University Press.
Dagneaux, E., Denness, S., & Granger, S. (1998). Computer-aided error analysis. System, 26(2), 163-174.
Fossati, D., & Eugenio, B. (2007). A Mixed Trigrams Approach for Context Sensitive Spell Checking. Paper presented at the Proceedings of the 8th International Conference on Computational Linguistics and Intelligent Text Processing, Mexico City, Mexico.
Galicia-Haro, S. N., Bolshakov, I. A., & Gelbukh, A. F. (1999). A Simple Spanish Part of Speech Tagger for Detection and Correction of Accentuation Error. Paper presented at the Proceedings of the Second International Workshop on Text, Speech and Dialogue.
Golding, A. R., & Schabes, Y. (1996). Combining Trigram-based and feature-based methods for context-sensitive spelling correction. Paper presented at the Proceedings of the 34th annual meeting on Association for Computational Linguistics.
Kolesnikova, O., & Gelbukh, A. (2010). Supervised Machine Learning for Predicting the Meaning of Verb-Noun Combinations in Spanish. In G. Sidorov, A. Hernández Aguirre & C. Reyes García (Eds.), Advances in Soft Computing (Vol. 6438, pp. 196-207-207): Springer Berlin / Heidelberg.
Kubota, M. (2001). Error correction strategies used by learners of Japanese when revising a writing task.
System, 29(4), 467-480. doi: Doi: 10.1016/s0346-251x(01)00026-4
Kukich, K. (1992). Techniques for automatically correcting words in text. ACM Comput. Surv., 24(4), 377-439.
Kyongho, M., H, W. W., & Yoo-Jin, M. (2000). Typographical and Orthographical Spelling Error Correction.
Paper presented at the 2nd International Conference on Language Resources & Evaluation.
Lee, I. (2004). Error correction in L2 secondary writing classrooms: The case of Hong Kong. Journal of Second Language Writing, 13(4), 285-312.
Lu, H.-C. (2010). An annotated Taiwanese Learners' Corpus of Spanish, CATE. Corpus Linguistics and Linguistic Theory, 6(2), 297-300. doi: 10.1515/cllt.2010.011
Lu, Hui-Chuan Lu & An Chung Cheng. 2010.11. “Corpus-based Study on Third Language Acquisition of Spanish Past Tense and Aspect.” International Conference on Applied Linguistics. Chiayi, Taiwan.
Olsen, K., & Williams, J. (2004). Spelling and grammar checking using the Web as a text repository. Journal of the American Society for Information Science and Technology, 55(11), 1020-1023.
Schmid, H. (1994). Probabilistic Part-of-Speech Tagging Using Decision Trees. Paper presented at the Proceedings of the International Conference on New Methods in Language Processing.
Szanser, A. J. (1970). Automatic error-correction in natural languages. Information Storage and Retrieval, 5(4), 169-174.
Truscott, J. (2007). The effect of error correction on learners' ability to write accurately. Journal of Second Language Writing, 16(4), 255-272. doi: DOI: 10.1016/j.jslw.2007.06.003
Truscott, J., & Hsu, A. Y.-p. (2008). Error correction, revision, and learning. Journal of Second Language Writing, 17(4), 292-305. doi: DOI: 10.1016/j.jslw.2008.05.003
Vendler, A. (1967). Linguistics in Philosophy. Ithaca, NY: Cornell University Press.
Corpus de Aprendices Taiwaneses de Español.
http://corpora.flld.ncku.edu.tw/
Corpus del Español.
http://www.corpusdelespanol.org/.
Corpus of Contemporary American http://www.americancorpus.org/
Free Online Spanish Spelling and Grammar Checker
http://lomastv.com/free-online-spanish-spelling-grammar-checker.php Free Online Spell Checker
http://www.jspell.com/public-spell-checker.html Sinica Corpus.
http://db1x.sinica.edu.tw/kiwi/mkiwi/.
UAM Corpus Tool
http://www.wagsoft.com/CorpusTool/
國科會補助專題研究計畫成果報告自評表
請就研究內容與原計畫相符程度、達成預期目標情況、研究成果之學術或應用價
值(簡要敘述成果所代表之意義、價值、影響或進一步發展之可能性) 、是否適
合在學術期刊發表或申請專利、主要發現或其他有關價值等,作一綜合評估。
1. 請就研究內容與原計畫相符程度、達成預期目標情況作一綜合評估
■達成目標
□ 未達成目標(請說明,以 100 字為限)
□ 實驗失敗
□ 因故實驗中斷
□ 其他原因
說明:
2. 研究成果在學術期刊發表或申請專利等情形:
論文:□已發表 □未發表之文稿 ■撰寫中(已發表於 2 學術研討會) □無
專利:□已獲得 □申請中 □無
技轉:□已技轉 □洽談中 □無
其他:(以 100 字為限)
3. 請依學術成就、技術創新、社會影響等方面,評估研究成果之學術或應用價
值(簡要敘述成果所代表之意義、價值、影響或進一步發展之可能性)(以
500 字為限)
語料庫的研究與發展為近年來語言學新的發展趨勢,目前國內外皆以英文語料庫所累積 的資料為大宗。語料庫除提供研究者便捷的檢索工具和豐富的語料,更提供語言教學者和 學習者在教與學的過程中避免錯誤及正確修正的參考,有利研究與教學成效的提昇。
本研究成果除了擴展既有的語料庫建構成果外,更輔以應用結果探討與分析學習者不同 層次的學習模式。在選定西班牙文過去式的研究主題中,探討學習者在使用兩種過去式的 傾向與發展程序。
目前在西班牙文錯誤偵測程式系統的開發已有初步的成果,未來除持續測試語料與新增 錯誤辨識階層,更將結合修正建議模式,讓系統的功能與使用介面更加完善齊備,其整體 成果對語料庫和語言教學之研究有其具體貢獻。
附件
國科會補助專題研究計畫項下出席國際學術會議心得
報告
日期:100 年 2 月 28 日
一、參加會議經過
個人是經由語言學討論群 lingustics list (http://www.linguistlist.org/)之 calls and conferences 得知此會議公開徵稿之相關訊息,經摘要投稿、審查、接受的程序後完 成全文,出席會議並口頭發表論文:Análisis de Errors a Partir de Corpus。此次會議 是在西班牙聖地牙哥大學 (University of Santiago)舉行,由西班牙語言學會(SEL)主 辦。會期前後共四天(2.1-2.4),會議形式包含了四個場次的專題演講,演講者都是當 今西班牙語語言學著名的重要學者專家,如:Guillermo Rojo, Pierre Swiggers, Kees Hengeveld 及 Jesús de la Villa 教授。專題演講的題目橫跨語言學相關領域,依序分 別為“La frecuencia de los fenómenos sintácticos”,“Figuras(s) de la gramática: apuntes para una morfología de la lingüística”, “La Gramática discursivo funcional” 以 及
“Estrategias lingüísticas: la expression del tiempo relative en griego antiguo”。此外,此 學術會議所發表的論文涵蓋了語料庫語言學不同的主題與範疇,包含以下次領域平 行搭配:corpus linguistics, discourse analysis, pragmatic problems, grammar, clinical linguistics, Spanish teaching, linguistics and interaction, press language, phonetics and phonology, morphology, phraseology, syntax, functional grammar, computational linguistics, classical linguistics, lexicon and grammar, dictionaries, language contact, historical grammar, grammar and variation, language acquisition, formal syntax 等。論文 的發表者包括來自世界各地的學者專家,共發表 165 篇分析及探討有關西班牙語語 言學議題的學術專業論文。整體而言,研討會包含多樣化的語言學相關領域的新知
計畫編
號
NSC98-2410-H-006-074-
計畫名
稱
以語料庫為本之西班牙語過去式的分析:結合學習者語料庫與電腦 輔助錯誤修正之研究
出國人
員姓名
盧慧娟服務機
構及職
稱
成功大學外文系 教授
會議時
間
99 年 2 月 1 日
至
99 年 2 月 4 日
會議地
點
Universidad de Santiago de Compostela, Spain
會議名
稱
(中文)第三十九屆西班牙語語言學協會國際研討會
(西文)
XXXIX Simposio Internacional de la Sociedad Española de Lingüística (SEL)發表論
文題目
(中文)「語料庫為本的錯誤分析」
(西文)
“Análisis de Errors a Partir de Corpus”2
與研究成果,充實且豐富會議的水準與內涵,讓與會學者收穫良多。
二、與會心得
出席本次國際研討會的收穫包括:(一)出席聆聽之專家學者對本人所發表之論
文「語料庫為本的錯誤分析」給予的回應:(1)介紹三個開發的語料庫相關工具:「台
灣西語學習者語料庫」、「西語搭配詞工具」和「西英漢平行檢索器」。與會者對於其
公開檢索的進階介面、半自動註記功能與多語平行對應之特色與屬性感興趣,願意 透過資料交換與技術交流的模式延展、開發語料庫的學術附加價值。(2)在語言分 析的應用層面,結合上述三工具,本論文的應用部分從錯誤分析的角度切入,以西 文的兩個聯繫動詞 ser 和 estar 為學習語分析的基礎,呈現善用語料庫工具以提昇研 究效率的範例,並針對第二語發展性階段理論提出第三語的新佐證。與會者則試圖 從其它母語者的西語學習案例與本研究及過去相關研究銜接,勾勒出西語聯繫動詞
學習發展的普遍概況與傾向。(二)藉以吸收其他專家學者在語料庫語言學理論與應
用的研究成果:參考他人的建構特色,學習其檢索功能,觀摩其應用層面與剖析技 術。和過去參加以語料庫為主軸的研討會議不同,在本次會議中,在西班牙語為基
礎的研究著力點上獲得較多的激勵。(三)透過此會議結識相關領域,特別是西語系
國家外,以西班牙語為外語研究領域的專家學者,商談日後學術合作及語料庫技術 交流的機會。
當今台灣在語言學領域的學術環境中,語料庫發展是語言學近年來快速蓬勃發 展的學門領域,相較於英語所獲得的關注,第二外語是較被忽略的;而結合第二外 語(或第三語)西班牙語和語料庫語言學的研究成果更是明顯不足的。由於研究的 特殊性、重要性與必要性,計畫主持人由外語習得理論著手,整合語料庫技術和語 料庫研究法,以探究第二外語學習的研究議題與方向。個人長期以來的專業進修規 劃包括定期出席具代表性的語料庫國際學術會議(Corpus Linguistics Conference 及 American Association of Corpus Linguistics Conference),藉以豐富相關見聞與增長科 技能力;此外,在應用語言學的第二外語領域中,則是透過參與西語系國家的相關 研討會充實該領域的新知。本人於此次會議中除聆聽多場有關語言學理論與應用相 關的專題演講和學術論文發表外,也有機會接觸到個人較少涉略的醫療語言學領 域,以及瞭解到語料庫語言學理論、語料庫建置和以語料庫為本的語言分析等相關 領域在西語系國家的發展概況,藉此難得機會與其他專家學者溝通與討論,擴大日 後的研究面向與深化其學術內涵。個人十六年來長期接受國科會出席國際會議之旅 費補助,得以前往世界各地發表研究成果,於研討會獲取回饋、學習的機會,於會 後反省、改善,並於日後進步、成長。
三、考察參觀活動(無是項活動者略)
無
四、建議
五、攜回資料名稱及內容
大會手冊與摘要。
六、其他:附件
SEL2010.ppt
4
論文全文
Análisis de errores a partir de corpus Hui-Chuan Lu & An Chung Cheng National Cheng Kung University TAIWAN
1. Introducción
En este trabajo, presentaremos tres instrumentos desarrollados para facilitar el análisis de datos provenientes de los aprendices, en comparación con los traducidos en distintos idiomas, esto con la intención de compartir nuestras herramientas y así mejorar el entendimiento del proceso de enseñanza-aprendizaje.
Los tres instrumentos son: CATE, Colocación Española y Concordancia Paralela.
CATE, Corpus de Aprendices Taiwaneses de Español es un corpus que provee abundantes datos provenientes de los aprendices y posee avanzadas funciones de consulta.
Colocación Española ofrece las listas de palabras combinatorias, al igual que CATE con funciones de consulta muy avanzadas. Y Concordancia Paralela hace concordar las frases paralelas en diferentes idiomas.
En la parte de aplicación, nos dedicaremos a realizar un estudio analítico de la estructura formada por verbos copulativos SER/ESTAR+adjetivos. Los resultados obtenidos brindarán una nueva evidencia que soporta las investigaciones ya existentes, además demuestran la utilidad y eficiencia de las herramientas presentadas.
2. Tres herramientas desarrolladas
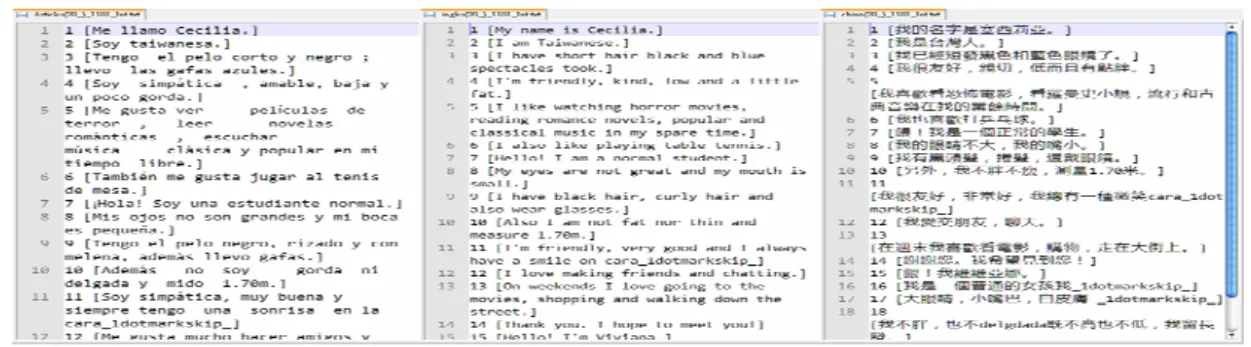
Las herramientas que conformarán nuestros pilares fundamentales en esta investigación son: Corpus de Aprendices Taiwaneses de Español, Colocación Española y Concordancia Paralela. Aprovechando las 3 herramientas, examinaremos el desempeño de los estudiantes, analizando los datos que aparecen en (1) los textos escritos por los aprendices taiwaneses que estudian español como tercera lengua, inglés como segunda y que tienen el chino-mandarín como lengua materna, (2) los textos realizados por los estudiantes, que han sido corregidos por hablantes nativos de español, y (3) los textos corregidos que han sido traducidos paralelamente a inglés y chino-mandarín por “Google traductor” (http://translate.google.com/#).
El presente estudio proporciona la posibilidad de realizar una comparación entre los elementos que resultan en el uso de cada una de las herramientas. En nuestro estudio contamos con datos extraídos del Corpus de Aprendices Taiwaneses de Español (CATE), un corpus en que se recopilan los textos originales redactados por nuestros aprendices de diferentes niveles y estos mismos textos revisados por hablantes nativos de español, los cuales funcionan como referencia para compararlos entre sí. Además, se cotejan los datos de diferentes idiomas mediante la Concordancia Paralela para derivar las posibles variables que afectan el aprendizaje con respecto a las transferencias de distintas interlenguas.
2.1. Herramienta 1: CATE
Ante la necesidad de basarnos en el corpus de aprendices para profundizar nuestras investigaciones de la lingüística aplicada, empezamos la creación de CATE a partir de 2005. Nuestra construcción de CATE (Corpus de Aprendices Taiwaneses de Español) se dedica a compartir recursos como datos de producción escrita realizados por los aprendices taiwaneses. Desde el año 2005 hasta hoy, hemos recopilado 1913 textos escritos y aproximadamente 340,000 palabras, y hemos hecho pública la primera etapa de los datos recogidos en los años 2005 y 2006 (http://corpora.flld.ncku.edu.tw).
Figura 1. CATE
2.2. Herramienta 2: Colocación Española
Después de bajar los datos obtenidos en la herramienta 1, los colocamos en la herramienta 2, Colocación Española, para obtener las listas de elementos combinatorios
6
formados por SER/ESTAR+Adjetivo bajo un punto de vista estadístico.
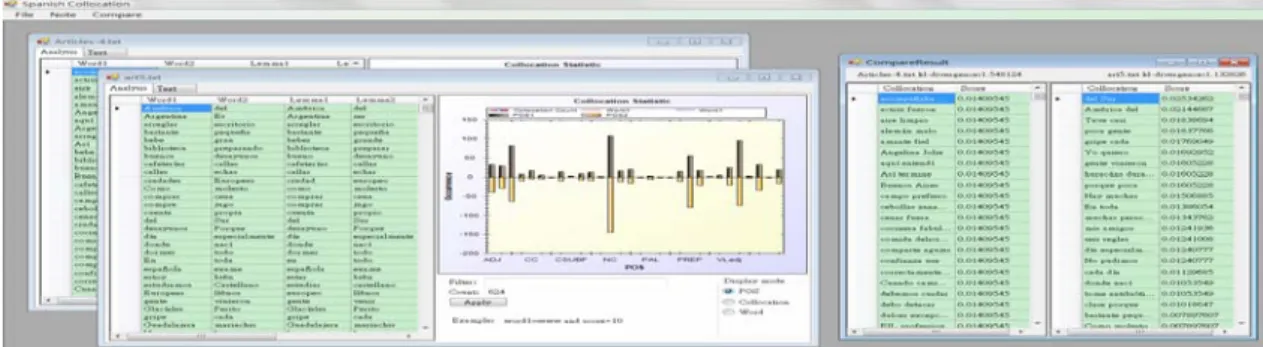
Esta segunda herramienta ha sido diseñada por el laboratorio de WMMKS de CSIE, NCKU en el año 2009, cuya función es facilitar la producción de anotaciones automáticas de los elementos combinatorios según los datos importados. Su contribución principal se atribuye a la posibilidad de consultar las colocaciones desde una definición más amplia incluyendo palabras, POSs y lemas. Además, nos facilita la tarea de contrastar las listas de colocaciones deducidas de dos corpora, en nuestro caso, el de los textos originales y los revisados.
Figura 2. Colocación Española
2.3. Herramienta 3: Concordancia Paralela
Para identificar las relaciones entre nuestras lenguas en estudio, (español, inglés y chino) haremos una observación más avanzada de los datos paralelos que se obtienen de
“Google traductor”, comprobando a la vez los factores de transferencia que pueden influir en la clasificación de los usos dados por los estudiantes. Asimismo, con la finalidad de lograr resultados óptimos, realizaremos un análisis de contraste, mediante la herramienta llamada ParaConc. Este instrumento facilita nuestro estudio comparativo, detectando las similitudes y diferencias entre los tres idiomas para identificar las posibles transferencias L1 (chino) y L2 (inglés) que podrían ocurrir en el aprendizaje de la L3 (español).
Después de compilar los datos, alineamos los textos paralelos, aprovechamos los instrumentos en línea (CKIP y TreeTagger) para separar las palabras chinas y POS-etiquetar para las palabras en tres lenguas diferentes (español, inglés y chino).
Luego los importamos a la Concordancia Paralela y hacemos uso de un sistema de
búsqueda diseñado para observar frases de distintas lenguas en paralelo. Este instrumento muestra una interfaz diferente a la del modelo de CATE y Colocación Española. Esta herramienta puede facilitar eficazmente las comparaciones y los contrastes de los distintos idiomas traducidos y al mismo tiempo realizar un valioso aporte en la enseñanza y en la investigación.
Figura 3. Concordancia Paralela
3. Aplicación
Basándonos en los tres instrumentos presentados anteriormente, los temas a los que nos hemos dedicado en el trabajo analítico incluyen el léxico (las colocaciones) y la gramática (las coligaciones) tales como los artículos, los verbos copulativos SER/ESTAR y los tiempos pasados. Tomamos como ejemplo el estudio de la estructura SER/ESTAR+Adjetivo para señalar la aplicación de las herramientas.
3.1. Propósito de estudio
El propósito del presente estudio se logrará basándonos en los resultados deducidos mediante el análisis de los datos recopilados en el corpus de aprendices CATE y la comparación entre sus textos revisados y corregidos por hablantes nativos de español y los traducidos automáticamente de Google Traductor. El siguiente estudio está dedicado a analizar los datos y su distribución, para obtener una generalización de la inclinación que se da en los usos de los verbos copulativos en estudio en las diferentes etapas de desarrollo de los estudiantes taiwaneses. También contrastamos 3 idiomas diferentes asociados con nuestro tema, los que estudian español (L3) después de Inglés (L2), para deducir las posibles variables relacionadas con los efectos de la transferencia de L1 y L2
8
en L3.
3.2. Estudios antecedentes
VanPatten (1985, 1987) propone las fases del desarrollo sobre la adquisición de verbos copulativos: 1. No existen verbos copulativos en la lengua adquirida (*Juan alto.) 2. En la fase principiante de la adquisición, se nota el uso excesivo del verbo copulativo SER, es decir, se reemplaza por el otro verbo copulativo ESTAR (*Ella es estudiar.) 3. La adquisición de ESTAR+Gerundio (Ella está estudiando.) 4. La adquisición de ESTAR+
adverbio de lugar (Sus padres están en Colombia.) 5. La adquisición de ESTAR+
Adjetivo (Juan está enfermo.)
Quizá algunos investigadores creen que todos los procesos de la adquisición de lenguas no-nativos son iguales, sin embargo, los conocimientos previos y experiencias de aprendizaje tienen un impacto considerable en el proceso de adquisición, por lo que es necesario distinguir diferentes tipos de adquisición. Leung (1998, 2002, 2005, 2006) indica que para los aprendices de un tercer idioma hay dos fuentes de transferencia en la adquisición del conocimiento de idiomas: la primera lengua y el segundo idioma. En la adquisición de la segunda lengua, la transferencia sólo puede ser de la primera lengua, pero la fuente de la adquisición de la tercera lengua puede ser al mismo tiempo de la primera y de la segunda. Así que la adquisición del tercer lenguaje, en un cierto nivel, debe ser diferente de la adquisición de una segunda lengua.
Acerca de los factores que afectan a la tercera lengua o multi-lenguaje en la adquisición, Ringbom (2007) indica dos factores que se relacionan con el presente estudio: la distancia del lenguaje y los niveles de conocimientos de los idiomas.
Distancia se refiere a la pertinencia y la similitud entre la lengua de destino y la lengua materna. En el aprendizaje multilingüe, generalmente se asume que el lenguaje más cercano a la adquisición de la lengua de destino tiene más influencia y no importa si la lengua cercana es la lengua materna o no. La adquisición también pueden verse afectada por varios idiomas simultáneamente. El impacto de cros-lingüística se produce en las primeras etapas, cuando el conocimiento de la lengua de destino todavía es superficial e incompleto para los alumnos, sus necesidades del idioma de destino es lo más urgente que satisfacer (Odlin (1989), Ringbom (1986), Williams & Hammarger
(1998)). Sin embargo, la transferencia de conocimientos de diferentes lenguas también se produce en el nivel avanzado de aprendizaje. La adquisición y la transferencia suelen ser negativas en la etapa temprana. Por otro lado, es más probable que el impacto positivo de la transferencia de conocimientos, aparezca en el nivel avanzado de aprendizaje. Los estudiantes se benefician del conocimiento que tienen de otros idiomas, especialmente en los aspectos cognitivos del vocabulario. Ringbom (1987) señala que la transferencia morfológica es un tipo muy básico, porque no requiere una capacidad muy alta de lenguaje para dar lugar a dicha transferencia. Por el contrario, la transferencia semántica sólo se podría alcanzar cuando los estudiantes están muy conscientes del idioma no-nativo.
3.3. Metodología
Basándose en los resultados de estudios anteriores, en esta presentación se demostrará la Colocación Española diseñada para analizar estadísticamente los datos guardados en el corpus CATE y averiguar la tipología de estructura observada, contrastando los textos paralelos utilizando la Concordancia Paralela.
3.3.1. Datos
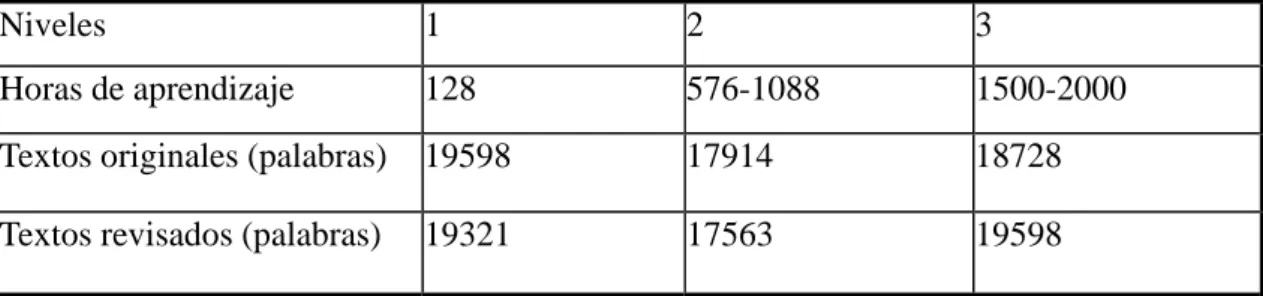
Para evitar la información ruidosa, hemos extraído los textos utilizando los siguientes criterios con respecto a las características constantes de los datos: la longitud de 100-200 palabras, con un tipo de texto descriptivo y el tema relacionado con el ocio y la vida rutinaria.
Cuadro 1. Características de datos analizados
Niveles 1 2 3
Horas de aprendizaje 128 576-1088 1500-2000 Textos originales (palabras) 19598 17914 18728 Textos revisados (palabras) 19321 17563 19598
Para observar las diferencias entre las distintas etapas de desarrollo, nos hemos
10
centrado en tres grupos de alumnos con diferente cantidad de horas de aprendizaje (niveles 1, 2 y 3), y excluyendo a los alumnos con situaciones especiales (como los inmigrantes, los de intercambio o los transfer). En total, se utilizaron de 17.500~20.000 palabras para los textos originales y revisados en cada nivel.
3.3.2. SER/ESTAR + X búsqueda
Cuando importamos los datos, primero nos fijamos en el tamaño máximo de la ventana, que es 5 (el intervalo entre dos palabras) sin disponer, también nos fijamos en las palabras clave sin desencadenar el filtro de palabras frecuentes, luego se elige el método estadístico de chi-cuadrado. Después establecemos las condiciones para los resultados de los elementos combinatorios que tenemos la intención de obtener para el análisis posterior, por ejemplo, Lemma1=SER o ESTAR.
3.4. Resultados y debate
Observamos que los aprendices del nivel principiante usan menos verbos copulativos, en comparación con los que se usan en los textos revisados, se da lo contrario en los niveles posteriores.
Cuadro 2.
V SER ESTAR SER+ESTAR
original revisado original revisado original/revisado
1 259 242 67 84 326/326
2 182 127 25 37 207/164
3 207 197 28 35 235/232
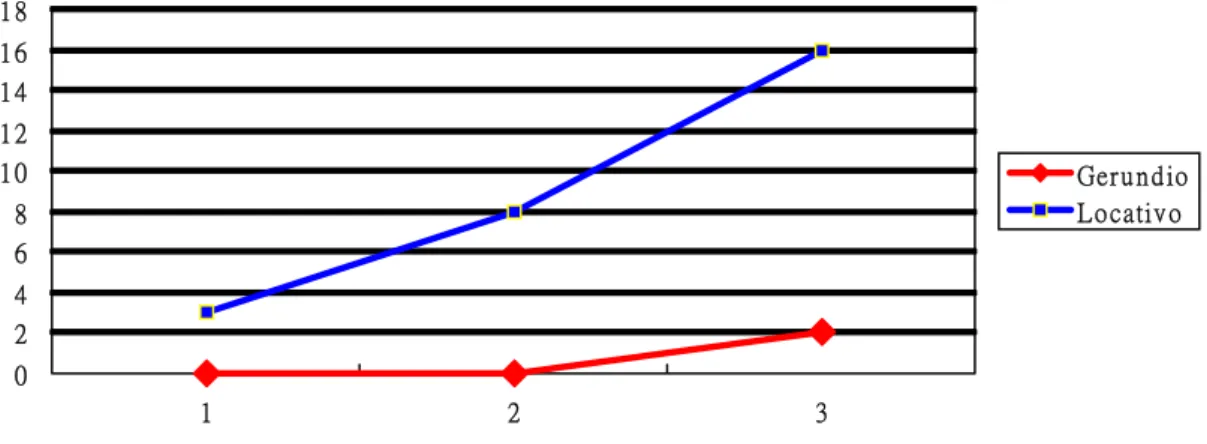
En el Cuadro 2, se nota que los aprendices usan más SER que ESTAR en todos los niveles. Sin embargo, nos damos cuenta de que la tercera propuesta, etapa ESTAR+Gerundio, aparece más tarde para nuestros aprendices taiwaneses que la cuarta etapa ESTAR+locativo.
0 2 4 6 8 1 0 1 2 1 4 1 6 1 8
1 2 3
Ger u n d io Lo cativ o
Figura 5. Desarrollo de aprendizaje
Los porcentajes de aparición señalan que la estructura de ESTAR+Adjetivo aparece en una etapa más tarde, como se propone en la última etapa.
0%
50%
100%
1 2 3
1 46%
2 47%
3 77%
SER/ESAR+Adj
Figura 6. Comparación de aprendizaje
Según los fenómenos observados, en relación con las etapas de desarrollo, tratamos de dar razón al orden jerárquico al contrastar textos paralelos en tres lenguas distintas, español, inglés y chino (la lengua meta, la segunda lengua y la lengua materna), usando la herramienta de la Concordancia Paralela.
Según los resultados deducidos, observamos que L1 juega un papel más esencial en las etapas de desarrollo. Ofrecemos las siguientes evidencias para apoyar nuestras conclusiones: En primer lugar, los verbos copulativos españoles se traducen en TO BE en inglés mientras que la posición se ocupa por un ZHI invisible en chino. En general, el
12
verbo copulativo ZHI en chino se expresa sólo cuando la oración implica un sentido enfático o contrastivo. Por lo tanto, se explica la omisión del verbo copulativo en el nivel principiante si se atribuye a la transferencia de L1. El verbo copulativo SER se asocia primero con TO BE de L2, el único verbo copulativo en inglés, por lo que SER se usa con mucho más frecuencia que ESTAR. La transferencia de L2 puede intervenir y desempeñar un papel en la segunda etapa. El orden reverso de las etapas 3 (ESTAR-Gerundio) y 4 (ESTAR-Locativo) propuestas anteriormente en contraste con nuestros resultados observados, se debe a la relación estrecha entre la equivalencia de uno correspondiente a uno entre el morfema “ZAI” en chino (L1) y ‘en’ en español para el caso de ESTAR+locativo. Sin embargo, el uso de ESTAR+Gerundio es mucho más complicado al traducirse en “ZHENG (ZAI)” u otras expresiones. Por último, ESTAR/SER+Adjetivo aparece en una etapa más tarde, porque dos verbos copulativos españoles compiten la posición antes del adjetivo y dificulta la decisión de utilizarse, esto se observa en las traducciones en chino y en inglés donde existen matices de interacciones entre varias posibles colocaciones.
3.5. Material didáctico
Nuestros instrumentos también pueden servir de recursos o referencia para diseñar material pedagógico, porque los datos representativos de los ejemplares erróneos, contrastes entre errores, correcciones, traducciones de L2 y L1 se pueden obtener y derivar fácilmente. Todo esto proporciona una dirección más clara para el diseño de material pedagógico en la enseñanza y el aprendizaje de los verbos copulativos en español.
4. Trabajo Futuro
Para el primer instrumento CATE, por el momento, nos basamos en los resultados construidos a fin de desarrollar un sistema semi-automático de detección y corrección de errores, para ahorrar el consumo de tiempo que se tarda en la revisión de los textos originales en el futuro, avanzando hacia el camino de Procesamiento de Lengua Natural.
Con respecto al segundo instrumento, Colocación Española, vamos a ampliar la función de consulta de elementos combinatorios del bi-gramo a la N-gram a fin de
abarcar una mayor gama de elementos yuxtapuestas para los estudios futuros. También estamos desarrollando un sistema de análisis sintáctico y semántico y un plan de combinación de los primeros instrumentos, para enriquecer sus funciones de búsqueda y los aspectos de la aplicación.
Con respecto al último instrumento, Concordancia Paralela, que se diseña para contrastar los textos paralelos y traducidos en tres idiomas (Español, Inglés y Chino) se está desarrollando hacia un destino de utilidad amable, dirigiéndose a alinear semi-automáticamente y POS-etiquetar las traducciones en diferentes idiomas.
Por último, además de los temas relacionados con el desarrollo de aprendizaje que hemos estudiado, tales como las colocaciones y los verbos copulativos, también queremos investigar otros temas, por ejemplo: los pretéritos y los artículos, con el objetivo de obtener una visión completa y sistemática del aprendizaje de L3. Al tomar ventaja de estas nuevas funciones mencionadas anteriormente, la investigación relacionada con el análisis del lenguaje, puede dirigirse a una perspectiva más amplia.
Basándonos en los 3 instrumentos presentados, esta investigación se dedicó a analizar los verbos copulativos usados por los taiwaneses aprendices de español, mediante el estudio de los datos recopilados en el corpus llamado CATE y la comparación con los textos revisados. Este estudio también consultó los textos paralelos traducidos automáticamente en chino e inglés, para evaluar las influencias de interlenguas y averiguar las posibles variables de transferencia. Esto nos permitió obtener un conocimiento general, de la inclinación que se da en el uso de los verbos copulativos, en las diferentes etapas de desarrollo por las que atraviesan los estudiantes taiwaneses al querer aprender español. Los resultados de nuestra investigación comparativa nos permiten ofrecer directrices para el diseño de material pedagógico en la enseñanza y el aprendizaje.
5. Conclusión
Siguiendo la tendencia actual de la lingüística de corpus, hemos desarrollado 3 instrumentos, de los cuáles uno está dispuesto a promulgar la facilitación de los análisis relacionados con el aprendizaje de español y otros dos van a estar disponibles. En comparación con otros instrumentos existentes que no están disponibles al público, los
14
nuestros serán un servicio libre para realizar consultas incluyendo palabras, POS y lema.
La combinación de un corpus de aprendices, una herramienta de colocación y un instrumento de concordancia paralela que han sido creados, abre un acceso eficiente para obtener resultados sistemáticos en el área de la lingüística aplicada. Al usar estos instrumentos en un estudio empírico, hemos proporcionado los resultados de las etapas de desarrollo y los patrones tipológicos de los usos de los verbos copulativos en español presentes en los alumnos. Por último, esperamos que los investigadores y profesores que compartan nuestros intereses puedan beneficiarse mediante la aplicación de nuestros instrumentos, tanto en el análisis de datos como en el diseño de material didáctico.
Agradecimientos
Agradecemos por el apoyo financiero de los siguientes proyectos de investigación:
Landmark Project of National Cheng Kung University 97-R021 and 98-R021.
Asimismo, damos gracias por la ayuda de los siguientes profesores: Wen-Hsian Lu y Hsueh Lu Lo. Además, nos gustaría expresar nuestro sincero agradecimiento a todos los asistentes y participantes que han colaborado en el presente estudio.
Referencias bibliográficas
Leung, Y-k. I. (1998). Transfer between interlanguages. In: Greenhill, A., Hughes, M., Littlefield, H. and Walsh, H. (1998)Proceedings of the 22nd Annual Boston University Conference on Language Development, I-II. Somerville, MA : Cascadilla. S. 477-487.
Leung, Y-k. I. (2002). Functional categories in second and third language acquisition: A cross-linguistic study of the acquisition of English and French by Chinese and Vietnamese Speakers. Ph.D. dissertation: McGill University.
Leung, Y-k. I. (2005). L2 vs. L3 initial state: A comparative study of the acquisition of French DPs by Vietnamese monolinguals and Cantonese-English bilinguals.
Bilingualism: Language and Cognition, 8(1), 39-61.
Leung, Y-k. I. (2006). Full transfer vs. partial transfer in L2 and L3 acquisition. In R.
Slabakova, S. Montrul, & P. Prévost (Eds.), Inquiries in linguistic development:
In honor of Lydia White (pp. 157-188). Amsterdam: John Benjamins.
Odlin, T. (1989). Language tranfer. Cross-linguistic influence in language learning.
Cambridge: Cambridge University Press.
Ringbom, H. (1986). Crosslinguistic influence and the foreign language learning process.
In E. Kellerman, and M. Sharwood-Smith (Eds.), Crosslinguistic influence in second language acquisition (pp. 150-162). Oxford: Pergamon Press.
Ringbom, H. (1987). The role of the first language in foreign language learning.
Clevedon: Multilingual Matters.
Ringbom, H. (2007). Cross-linguistics similarity in foreign language learning. Clevedon : Multilingual Matters.
VanPatten, B. (1985). The Acquisition of "ser" and "estar" by Adult Learners of Spanish:
A Preliminary Investigation of Transitional Stages of Competence. Hispania, 68(2), 399-406.
VanPatten, B. (1987). Classroom Learners' Acquisition of Ser and Estar: Accounting for Developmental Patterns. In B. VanPatten, T. R. Dvorak & J. F. Lee (Eds.), Foreign Language Learning: A Research Perspective (pp. 61-75). Rowley:
Newbury House.
William S. & Hammargerg, B. (1998). Language switches in L3 production: implications for a polyglot speaking model. Applied Linguistics, 19, 295-333.
Herramientas y corpus Colocación Española
Concordancia Paralela
Corpus de Aprendices Taiwaneses de Español
國科會補助計畫衍生研發成果推廣資料表
日期:2011/05/11
國科會補助計畫
計畫名稱: 以語料庫為本之西班牙語過去式的分析:結合學習者語料庫與電腦輔助錯誤 修正之研究
計畫主持人: 盧慧娟
計畫編號: 98-2410-H-006-074- 學門領域: 西班牙語教學研究
無研發成果推廣資料
98 年度專題研究計畫研究成果彙整表
計畫主持人:盧慧娟 計畫編號:98-2410-H-006-074-
計畫名稱:以語料庫為本之西班牙語過去式的分析:結合學習者語料庫與電腦輔助錯誤修正之研究 量化
成果項目
實際已達 成數(被接
受或已發 表)
預期總達成 數(含實際 已達成數)
本計畫 實際貢 獻百分
比
單位
備註(質 化 說 明:如 數 個 計 畫 共 同 成 果 、 成 果 列 為 該 期 刊 之 封 面 故 事 ...等)
期刊論文 0 0 100%
研究報告/技術報
告 1 1 100%
盧慧娟,2011,「以語料庫為 本 之 西 班 牙 語 過 去 式 的 分 析:結合學習者語料庫與電 腦輔助錯誤修正之研究」,九 十八年度行政院國家科學委 員 會 專 題 研 究 計 畫 結 案 報
告 。
(NSC98-2410-H-006-074)。
研討會論文 2 2 100%
篇
Lu, Hui-Chuan Lu &; An Chung Cheng. 2010.11. ' Corpus-based Study on Third Language Acquisition of Spanish Past Tense and Aspect.'
International Conference on Applied Linguistics.
Chiayi, Taiwan.
Chang, Cheng-Yu and Hui-Chuan Lu.
2010.12. 'Corpus-based Error Detection for Learners of Spanish.'
The Fourteenth International Conference on Language Instruction of ROCMELIA. Kaohsiung, Tiwan.
論文著作
專書 0 0 100%
申請中件數 0 0 100%
專利 已獲得件數 0 0 100% 件
件數 0 0 100% 件
技術移轉
權利金 0 0 100% 千元
碩士生 3 0 100%
博士生 1 0 100%
博士後研究員 0 0 100%
國內
參與計畫人力
(本國籍) 人次
期刊論文 0 0 100%
研究報告/技術報
告 0 0 100%
研討會論文 0 0 100%
篇
Lu, Hui-Chuan & ; An Chung Cheng. 2010.2. ' An&;aacute;lisis de Errores a Partir de Corpus. ' 39 Simposio Internacional de la SEL.
Santiago de Compostela, Spain.
Cheng An Chung & ; Hui-Chuan Lu. 2010.3. ' The role of transfer in the acquisition of Spanish copulas by Chinese L1 speakers.'
AAAL2010 Annual Conference. Atlanta, USA.
論文著作
專書 0 0 100% 章/本 申請中件數 0 0 100%
專利 已獲得件數 0 0 100% 件
件數 0 0 100% 件
技術移轉
權利金 0 0 100% 千元
碩士生 0 0 100%
博士生 0 0 100%
博士後研究員 0 0 100%
國外
參與計畫人力
(外國籍)
專任助理 0 0 100%
人次
其他成果
(
無法以量化表達之 成果如辦理學術活 動、獲得獎項、重要 國際合作、研究成果 國際影響力及其他 協助產業技術發展 之 具 體 效 益 事 項 等,請以文字敘述填 列。)無。
成果項目 量化 名稱或內容性質簡述
測驗工具(含質性與量性) 0
課程/模組 0
電腦及網路系統或工具 0
教材 0
科 教 處 計 畫
舉辦之活動/競賽 0
研討會/工作坊 0
電子報、網站 0
加 填 項
目 計畫成果推廣之參與(閱聽)人數 0
國科會補助專題研究計畫成果報告自評表
請就研究內容與原計畫相符程度、達成預期目標情況、研究成果之學術或應用價
值(簡要敘述成果所代表之意義、價值、影響或進一步發展之可能性) 、是否適
合在學術期刊發表或申請專利、主要發現或其他有關價值等,作一綜合評估。
1. 請就研究內容與原計畫相符程度、達成預期目標情況作一綜合評估
■達成目標
□未達成目標(請說明,以 100 字為限)
□實驗失敗
□因故實驗中斷
□其他原因
說明:
2. 研究成果在學術期刊發表或申請專利等情形:
論文:□已發表 □未發表之文稿 ■撰寫中 □無
專利:□已獲得 □申請中 ■無
技轉:□已技轉 □洽談中 ■無
其他:(以 100 字為限)
3. 請依學術成就、技術創新、社會影響等方面,評估研究成果之學術或應用價
值(簡要敘述成果所代表之意義、價值、影響或進一步發展之可能性)(以
500 字為限)
語料庫的研究與發展為近年來語言學新的發展趨勢,目前國內外皆以英文語料庫所累積的 資料為大宗。語料庫除提供研究者便捷的檢索工具和豐富的語料,更提供語言教學者和學 習者在教與學的過程中避免錯誤及正確修正的參考,有利研究與教學成效的提昇。
本研究成果除了擴展既有的語料庫建構成果外,更輔以應用結果探討與分析學習者不同 層次的學習模式。在選定西班牙文過去式的研究主題中,探討學習者在使用兩種過去式的 傾向與發展程序。
目前在西班牙文錯誤偵測程式系統的開發已有初步的成果,未來除持續測試語料與新增 錯誤辨識階層,更將結合修正建議模式,讓系統的功能與使用介面更加完善齊備,其整體 成果對語料庫和語言教學之研究有其具體貢獻。