國 立 交 通 大 學
運輸科技與管理學系
碩
士
論
文
比較 k-NN 模式與時變係數模式對高速公路
旅行時間預測之研究
A Study of Comparison of k-NN Model and Time-Varying
Coefficient Model for Predicting Travel Time on Freeways
研 究 生:陳建旻
指導教授:王晉元
中 華 民 國 九 十 八 年 六 月
比較 k-NN 模式與時變係數模式對高速公路旅行時間預測之研究 學生: 陳建旻 指導教授: 王晉元
國立交通大學運輸科技與管理學系碩士班
摘 要
近年來政府大力推動智慧型運輸系統(Intelligent Transportation System, ITS),而先進用路人資訊系統(Advanced Traveler Information System, ATIS) 即為ITS 中的一子系統。在 ATIS 中,為了要給予用路人準確的資訊,以作 為路徑、運具選擇之依據,路徑旅行時間的預測是一項重要的課題。尤其 在高速公路路網建置完成後,適當交通預測資訊之提供對用路人行為決策 更顯得其重要,不僅可以作為駕駛者選擇適當之路徑與出發時間憑藉之依 據,用路者亦可藉此選擇最短之旅行時間到達目的地,以真正發揮高速公 路路網之整體績效。 本研究係針對國內高速公路為研究對象,利用探針車所蒐集到的即時 交通資料,分別利用 k-NN 模式與時變係數模式預測未來旅行時間,並針對 兩種模式的預測結果進行績效評估並作比較,以期能提供精準之旅行時間 預測,提供用路人路徑選擇或是出發時間決策判斷之依據。 本研究以國道一號高速公路楊梅到泰山收費站作為實際測試對象,經 由測試結果可得知,本研究所構建的 k-NN 與時變係數兩種旅行時間預測模 式,都是屬於高精準預測,而 k-NN 模式又能夠得到比時變係數模式更好的 預測結果。因此,從測試結果顯示出本研究的預測方法可實際應用在高速 公路上,且可提供用路人精準的旅行時間預測。 關鍵字: k-NN 模式; 時變係數模式; 旅行時間預測; 探針車
A Study of Comparison of k-NN Model and Time-Varying Coefficient Model for Predicting Travel Time on Freeways
Student : Jian-Min Chen Advisor : Jin-Yuan Wang Department of Transportation Technology and Management
National Chio Tung University
Abstract
In recent years, the government is actively promoting Intelligent
Transportation System (ITS), and Advanced Traveler Information System (ATIS) is a subsystem of ITS. Travel time prediction is a very important of ATIS. When drivers have to make a decision, it is more important for drivers to use suitable traffic information. Traffic information will allow drivers to select appropriate routes and departure time to avoid congestion and arrive in the destination with the shortest time.
In this study, the probe vehicles collect real-time traffic information, and use the k-NN model and Time-Varying Coefficients (TVC) model to predict the future travel time, respectively. Evaluation and Comparison of two models for forecasting the results, hope to provide accurate forecasts of travel time to travelers departure time or route choice decision-making judgements based on.
We use the 1st National Freeway Yangmei to Taishan Toll Station as the actual test object. The testing results show that k-NN model and TVC model are high precision prediction, and k-NN model predict better than TVC model. The prediction method can actually use on the highway, and can provide accurate prediction of travel time to drivers.
誌 謝
兩年的研究所生活,很快的即將畫下句點,也即將脫離學生生活,準備 踏入社會面對另一個嶄新的挑戰,在研究所期間,最感謝的人就是指導教 授王晉元老師,其認真負責的教學態度,讓學生在學業或生活上都受益良 多,每當我在學習上遇到瓶頸時,老師都會適時的給予鼓勵與幫助,讓我 得以突破困境,面對接下來的挑戰,在此僅致上學生最誠摯的謝意與敬意, 並感謝中華大學張靖老師與台北科技大學盧宗成老師能撥冗參與口試審查, 提供一些論文不足處的修改意見,使本論文更臻完備。 很高興在研究室遇到那麼多優秀的學長,其中最感謝的學長彥佑大人, 每當遇到問題時,都很有耐心的教導我並時常鼓勵我,讓我更有信心能順 利完成論文,也因為有你的幫忙,我才能如此順利畢業,要感謝小松學長 的教導,讓我開始接觸學習寫程式,感謝思文學長在課業學習上的幫助, 以及好友芬傑與士勛在研究之餘一起看球賽、分享生活甘苦的日子真的很 開心,老總不時的給予研究上的建議,並不厭其煩的仔細講解,聰儒、葉 珮一起在課業上學習,以及可愛的學弟妹宇凡、佳儒、小惠、Daisy 的陪伴, 讓我在研究所生活更多采多姿。 還要感謝的一直在背後默默支持我的爸媽,因為有你們的支持與照顧, 讓我得以順利完成學業,兩位姐姐在我心情低落時給予打氣、加油,不斷 地鼓勵我,以及嘉琳的支持讓我在學習上更具信心,表姊阿珍、表哥咪咪 當我學習的好榜樣,讓我在學習路上知道如何向前邁進。 能完成這篇論文,要感謝的人實在是太多了,曾給過我幫助或鼓勵的 人,我都不會忘記,非常感謝你們,也希望在此能與你們共同分享這份喜 悅,謝謝大家!陳建旻 新竹交大 2009/07/23
目 錄
中文摘要 ... i 英文摘要 ... ii 誌謝 ... iii 目錄 ... iv 表目錄 ... vi 圖目錄 ... viii 第一章 緒論 ... 1 1.1 研究動機 ... 1 1.2 研究目的 ... 2 1.3 研究範圍 ... 2 1.4 研究內容 ... 2 1.5 研究流程 ... 2 第二章 文獻回顧 ... 5 2.1 線性迴歸方法 ... 5 2.2 時間序列法 ... 6 2.3 類神經網路法 ... 7 2.4 k-NN 方法 ... 11 2.5 其他預測方法 ... 14 2.6 小結 ... 17 第三章 k-NN 模式構建 ... 18 3.1 k-NN 模式介紹 ... 18 3.1.1 k-NN 資料分群 ... 20 3.1.2 選擇距離量度 ... 20 3.1.3 k 值設定 ... 21 3.2 k-NN 模式構建 ... 22 3.3 k-NN 模式範例說明 ... 26 第四章 時變係數模式構建 ... 30 4.1 TVC 模式介紹 ... 30 4.1.1 TVC 資料分群 ... 32 4.1.2 迴歸基本統計假設 ... 32 4.1.3 檢定統計顯著性 ... 33 4.1.4 判定係數R2 ... 36 4.2 TVC 模式構建 ... 374.3 資料整理 ... 39 4.4 預測精確度之衡量 ... 42 第五章 數值測試 ... 43 5.1 模式構建與測試 ... 43 5.1.1 測試路段 ... 43 5.1.2 預測時段 ... 43 5.1.3 蒐集資料 ... 44 5.2 建立k-NN 預測模式 ... 46 5.3 k-NN 預測結果 ... 47 5.4 建立TVC 預測模式 ... 60 5.4.1 測試資料整理 ... 60 5.4.2 迴歸模式彙整 ... 81 5.5 TVC 預測結果 ... 82 5.6 績效評估 ... 90 第六章 結論與建議 ... 92 6.1 結論 ... 92 6.2 建議 ... 93 參考文獻 ... 94
表目錄
表 2.1 各種預測方法之比較 ... 16 表 3.1 各種資料庫之資料形式 ... 24 表 3.2 k-NN 距離量度資料表 ... 27 表 3.3 8:05 旅行時間資料表 ... 28 表 3.4 8:15 旅行時間資料表 ... 29 表 4.1 變異數分析表 ... 35 表 4.2 TVC 資料整理表 ... 40 表 4.3 MAPE 預測能力之等級 ... 42 表 5.1 各固定點編號名稱及位置 ... 43 表 5.2 旅行時間資料庫格式 ... 44 表 5.3 ETC 旅行時間資料庫格式 ... 45 表 5.4 門檻值對應 k 值(1) ... 48 表 5.5 k 值對應絕對誤差百分比(1) ... 49 表 5.6 k-NN 預測結果(1) ... 50 表 5.7 門檻值對應 k 值(2) ... 53 表 5.8 k 值對應絕對誤差百分比(2) ... 54 表 5.9 k-NN 預測結果(2) ... 56 表 5.10 上、下游固定點變數名稱對照 ... 61 表 5.11 k-NN 模式摘要(1) ... 62 表 5.12 變異數分析(1) ... 62 表 5.13 係數(1) ... 62 表 5.14 模式摘要(2) ... 63 表 5.15 變異數分析(2) ... 63 表 5.16 係數(2) ... 64 表 5.17 模式摘要(3) ... 64 表 5.18 變異數分析(3) ... 65 表 5.19 係數(3) ... 65 表 5.20 模式摘要(4) ... 66 表 5.21 變異數分析(4) ... 66 表 5.22 係數(4) ... 66 表 5.23 模式摘要(5) ... 67 表 5.24 變異數分析(5) ... 67 表 5.25 係數(5) ... 68 表 5.26 模式摘要(6) ... 68 表 5.27 變異數分析(6) ... 69表 5.28 係數(6) ... 69 表 5.29 模式摘要(7) ... 70 表 5.30 變異數分析(7) ... 71 表 5.31 係數(7) ... 71 表 5.32 模式摘要(8) ... 72 表 5.33 變異數分析(8) ... 72 表 5.34 係數(8) ... 72 表 5.35 模式摘要(9) ... 73 表 5.36 變異數分析(9) ... 73 表 5.37 係數(9) ... 74 表 5.38 模式摘要(10) ... 74 表 5.39 變異數分析(10) ... 75 表 5.40 係數(10) ... 75 表 5.41 模式摘要(11) ... 76 表 5.42 變異數分析(11) ... 76 表 5.43 係數(11) ... 76 表 5.44 模式摘要(12) ... 77 表 5.45 變異數分析(12) ... 77 表 5.46 係數(12) ... 78 表 5.47 模式摘要(13) ... 78 表 5.48 變異數分析(13) ... 79 表 5.49 係數(13) ... 79 表 5.50 模式摘要(14) ... 80 表 5.51 變異數分析(14) ... 80 表 5.52 係數(14) ... 80 表 5.53 迴歸檢定彙整表 ... 81 表 5.54 TVC 預測結果(1) ... 83 表 5.55 TVC 預測結果(2) ... 86
圖目錄
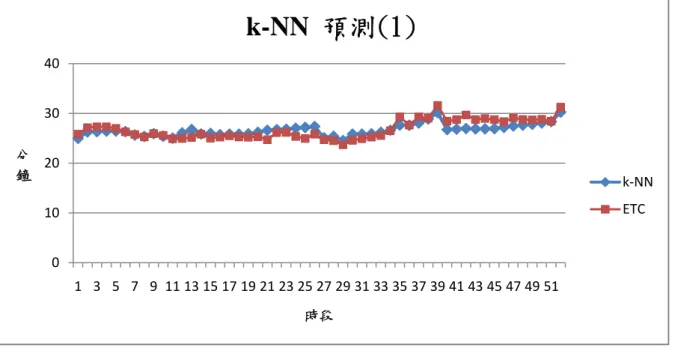
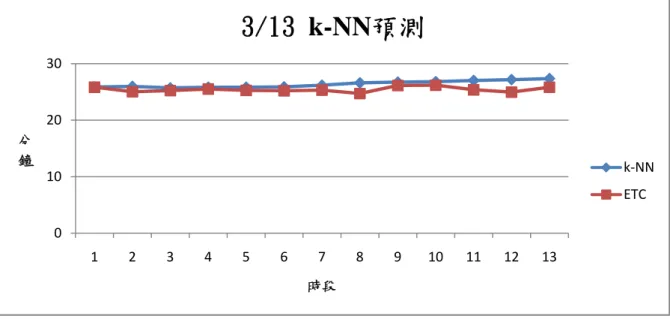
圖 1.1 研究流程圖 ... 4 圖 3.1 k-NN 流程圖 ... 19 圖 3.2 k-NN 模式構建流程圖 ... 23 圖 3.3 k-NN 範例路段示意圖 ... 26 圖 4.1 TVC 流程圖 ... 31 圖 4.2 TVC 模式構建流程圖 ... 38 圖 4.3 TVC 範例路段示意圖 ... 39 圖 5.1 旅行時間資料庫 ... 45 圖 5.2 ETC 旅行時間資料庫 ... 46 圖 5.3 k-NN 預測結果(1) ... 51 圖 5.4 3/6 k-NN 預測結果 ... 51 圖 5.5 3/13 k-NN 預測結果 ... 52 圖 5.6 3/20 k-NN 預測結果 ... 52 圖 5.7 3/27 k-NN 預測結果 ... 53 圖 5.8 k-NN 預測結果(2) ... 57 圖 5.9 3/1 k-NN 預測結果 ... 57 圖 5.10 3/8 k-NN 預測結果 ... 58 圖 5.11 3/15 k-NN 預測結果 ... 58 圖 5.12 3/22 k-NN 預測結果 ... 59 圖 5.13 3/29 k-NN 預測結果 ... 59 圖 5.14 迴歸標準化殘差 P-P 圖(1) ... 61 圖 5.15 迴歸標準化殘差 P-P 圖(2) ... 70 圖 5.16 TVC 預測結果(1) ... 84 圖 5.17 3/6 TVC 預測結果 ... 84 圖 5.18 3/13 TVC 預測結果 ... 85 圖 5.19 3/20 TVC 預測結果 ... 85 圖 5.20 3/27 TVC 預測結果 ... 86 圖 5.16 TVC 預測結果(2) ... 87 圖 5.17 3/1 TVC 預測結果 ... 88 圖 5.18 3/8 TVC 預測結果 ... 88 圖 5.19 3/15 TVC 預測結果 ... 89 圖 5.20 3/22 TVC 預測結果 ... 89 圖 5.21 3/29 TVC 預測結果 ... 90第一章 緒論
1.1 研究動機
中山高速公路的興建,帶動台灣西部經濟走廊的基礎,自民國 67 年全 線通車以來,車流量年年倍增,至今仍持續扮演台灣西部重要之旅次運輸 角色。而隨著交通量急遽成長,其車流量遠超過原先所估計,使得中山高 達到近飽和的狀態,交通壅塞的情形也變得比過去嚴重。為解決此問題, 政府又興建了福爾摩沙高速公路(北二高),在民國 93 已全線通車,加上近 年持續興建的國道路線及東西向快速道路,著實形成高速公路路網,也達 到促進地區均衡發展等目標。 然而隨著時間變化、道路狀況不同等因素,讓用路人對於高速公路旅 行時間變化無法掌握,而用路人只能憑藉過往經驗來選擇欲行駛之道路, 造成高速公路路路網無法發揮預期之功效,某些路段嚴重壅塞。而隨著科 技的日益進步,若能運用先進的運輸通訊設備,有效的預測未來旅行時間 的變化,提供給用路人即時、準確的動態交通資訊,不但能協助用路人作 出正確決策,節省行車時間,還可同時提升路網整體使用效率。近年來政府大力推動智慧型運輸系統(Intelligent Transportation System, ITS),而先進旅行者資訊系統(Advanced Traveler Information System, ATIS) 即為ITS 中的一子系統,主要將不同來源之交通資料作整合,提供用路人 即時或預測的交通資訊,例如:交通擁塞路段、事件發生地點、旅行時間 以及有關路況變化等資訊,此類動態交通訊息,讓用路人得以選擇適當行 車路徑,避開交通壅塞情況,進而以最佳旅行時間完成旅次需要。所以, 要如何正確預測旅行時間,提供用路人做出行前決策之依據,以降低在旅 次發生時之不確定性,為ATIS 應用中的一個關鍵課題。
目前全球定位系統(Global Positioning System, GPS)的發展已技術成熟, 加上其定位精確度高、不受任何天氣影響,且全球覆蓋率高(高達 98%)等優 點。因此,本研究選擇利用利用行駛在高速公路上,裝設有GPS 設備的探 針車,利用其所蒐集到的交通資訊,所推估出的旅行時間資料,使用 k-最 鄰近模式(k-Nearest Neighbor Model, k-NN Model)和時變係數模式(Time- Varying Coefficient Model, TVC Model),分別對高速公路旅行時間作預測, 以比較兩種方法預測的準確性,以提供用路人準確的旅行時間預測。 若能有效提供用路人準確的即時路況資訊,進而對旅次之出發時間、
路徑選擇和旅行時間,皆能進行有效之決策判斷依據,讓用路人更機動掌 握與調整行程,提昇運輸走廊之用路便利與智慧化,行駛於運輸走廊能獲 得更精確、更廣泛之交通資訊,藉以導引用路人充分利用替代道路以避開 壅塞路段,達到提升高速公路路網使用效率目的。
1.2 研究目的
本論文之研究目的,為利用高速公路上的偵測器位置作為固定點,將 探針車所蒐集到的交通資訊,所推估出的兩兩固定點之間的旅行時間,利 用k-NN 和 TVC 兩種模式分別作旅行時間預測,並分析比較兩種預測模式 準確度與績效,期望能提供用路人準確的高速公路旅行時間預測值作使 用。1.3 研究範圍
本研究以台灣地區國道一號高速公路收費站之間的旅行時間為主要研 究範圍,並以楊梅收費站到泰山收費站為實際測試對象,蒐集此路段上的 探針車旅行時間資料和高速公路電子收費系統(Electronic Toll Collection, ETC)旅行時間資料,利用探針車即時旅行時間資料預測未來的旅行時間, 以ETC 旅行時間當實際值檢驗預測結果。1.4 研究內容
本研究主要探討內容分述如下: 1.進行旅行時間預測模式之文獻蒐集與回顧 2.構建k-NN 旅行時間預測模式 3.構建TVC 旅行時間預測模式 3.以實際資料進行模式驗證 4.比較兩種預測模式的準確性 5.綜合上述研究成果,最後提出本研究之結論與建議1.5 研究流程
本研究流程如圖 1.1 研究流程圖所示,依照流程圖各步驟說明如下:1. 確認研究問題 本階段主要工作為分析研究目的,並了解外在限制與可用資源,以清 楚描述研究問題。 2. 相關文獻回顧 本階段主要工作為回顧國內外相關之實作研究,以分析過去研究優缺 點,作為本研究模式構建之基礎。 3. 模式方法構建 本階段主要工作為利用所蒐集到的探針車旅行時間資料,建立k-NN 和 TVC 兩種旅行時間預測模式,以比較兩種模式在預測上的績效。 4. 實作應用與模式修正 本階段主要工作為將旅行時間預測模式,應用在國號一號高速公路上, 以驗證此模式是否適用於現實狀況,並由運作結果對模式做調整與修正。 5. 結論與建議 對本研究之過程與結果作一結論並提出研究上的建議。
圖 1.1 研究流程圖 確認研究問題 相關文獻回顧 TVC 預測模式測試 構建k-NN 旅行時間 預測模式 構建TVC 旅行時間 預測模式 k-NN 預測模式測試 預測結果分析 預測模式準確度 評估 k-NN 模式是否 需要修正 TVC 模式是否 需要修正 結論與建議 是 否 是 否 蒐集探針車旅行 時間資料
第二章 文獻回顧
旅行時間預測較常見的方法為利用即時或事後所偵測到的交通資料, 用不同的方法來進行旅行時間預測,而旅行時間預測模式常用的方法有以 下四種:線性迴歸模式 (Linear Regression Model)、時間序列模式(Time Series Model)、類神經網路模式(Neural Networks Model)與 k-NN 模式
(k-Nearest Neighbor Model),以下針對這幾種預測方法作一簡單介紹及國內 外文獻回顧,並對各種方法進行優缺點比較分析。
2.1 線性迴歸方法
迴歸分析(Regression Analysis)是用來研究兩個或兩個以上變數間的關 係,此方法的主要目的是要建立一個迴歸模式,然後根據一個或多個自變 數(Independent Variable)之值,來預測依變數(Dependent Variable)或稱應變數 (Response Variable)之值。因此,迴歸分析的主要目的是在建立變數與變數 間之統計關係,然後利用此統計模式去做預測。迴歸分析可以分為簡單迴 歸(Simple Regression)和複迴歸(Multiple Regression),簡單迴歸是用來探討 一個應變數和一個自變數的關係,複迴歸是用來探討一個應變數和多個自 變數的關係,整理表示式如下: 簡單迴歸表示式: Y β 0 β 1X1 ε β 0為常數,β 1為迴歸係數,ε 為誤差 複迴歸表示式: Y β 0 β 1X1 β 2 X 2 …. βnXn ε β 0 為常數,β 1 ….. βn 為迴歸係數,ε 為誤差 Zhang [14]認為目前的旅行時間與未來的旅行時間中存在著線性關係,因此 利用此線性關係建立TVC(Time-Varying Coefficient)預測模式,利用目前高 速公路車輛偵測器所收集的資料預測未來的旅行時間,並且利用平均絕對 誤差百分比(Mean Absolute Percentage Prediction Error, MAPPE)來衡量此模 式的預測結果。此模式適用於每個路段皆有佈設車輛偵測器的高速公路。 此研究的測試方法有二:
(1)I-880 此測試資料來自一段在加州海沃(Hayward)長六英哩的 I-880 高速公路, 在這段高速公路上每隔三分之一英哩就有一個雙迴圈車輛偵測器,因此全 段總公有 35 個偵測器,而此測試範例是蒐集早上 5 點至早上 10 點北邊車 道的偵測器資料。 (2)I-405 此測試資料來自於加州的I-405 公路,此研究蒐集早上 5 點至早上 10 點的北邊車道資料,研究規模較上一個測試範例大。 測試結果方面,在以I-880 的資料測試下,依照時間的遠近誤差約在 5%至 10%,而在以I-405 的資料測試下,依照時間的遠近誤差約在 8%至 13%, 由於此模式的精確度會隨著預估時間的遠近,以及輸入資料量的多寡而有 所不同,因此適用於短距離的公路上。 Kwon [5]利用資料庫內的流量以及佔有率資訊及探針車所得到的旅行時間 資料來建立旅行時間預測模式。模式中將偵測到的流量、占有率即當時的 星期別及日期設定成一個集合Xi,對探針車所得到的實際旅行時間值作線 性迴歸模式,以此預測旅行時間,最後以MAPPE 方式來檢定預測績效。
2.2 時間序列法
時間序列分析有許多模式, 包括成長率模式、簡單移動平均模式 (simple moving average model)、指數平滑模式(exponential smoothing model)、簡單線性迴歸模式(以變數序列為因變數、時間為自變數),以 及Box-Jenkins 模式等。其中,以Box-Jenkins 模式之理論最為嚴謹,應用 也最廣泛,其依變數序列之特性,又可分為自我迴歸模式(Autoregressive, AR)、移動平均模式(Moving Average, MA)、混合自我迴歸移動平均模式 (ARMA),以及整合自我迴歸移動平均模式(ARIMA)等四種,主要應用於分 析歷史資料,並檢視資料本身之自我相關與偏自我相關等特性。採用ARIMA (Seasonal Autoregressive Integrated Moving Average)所構 建之預測模型,其構建過程分為四個階段,模型鑑定、參數估計、殘差檢 定與模型選擇,透過此四步驟便可協助我們找到最佳的配適模型。其主要 利用一連串的統計觀察值,依據時間的順序排列著,觀察的序列包含有實 際過程(real process)與干擾(noise)兩部分,最重要的部分式如何削減外在環 境所造成的干擾,因此自動迴歸與移動平均模式就這樣產生。基於這兩種
模型,任何不連續但固定兼具的序列則可以自動迴歸移動平均模式來表示, 模式如下: ... . . . 1 . . . 1 . . . 1 a 其中, 為一時間數列值; 為常數項; p, d, q 均為非負的整數,分別 代表自我迴歸、差分階數及移動平均的參數個數;
B
為後移運算子(Backward Shift Operator) ,即 = ; 為隨機干擾項,且為一白噪音(White Noise)。 Smith [11] 本研究討論統計上母數(parametric)與無母數(nonparametric)資料 在單點短期車流量預測上的差異及比較。此研究在選擇母數模式的部份, 以ARIMA作為預測模式,其主要是利用整合自我迴歸、移動平均兩種特性 所構成的模式去處理時間序列,而無母數迴歸模式則是利用k-NN模式進行 流量預測。 將以上兩種預測模式結果與naïve預測作比較,研究考量目前的流量可 能會與先前的流量有關,但是隨著時間距離的增加,其影響程度愈小,所 以嘗試將k-NN模式加入不同權重值進行預測值的計算。預測結果顯示, ARIMA預測結果最佳MAPE值約為8.8%,而k-NN模式的MAPE值約為9.4%,比 naïve的MAPE值10%預測效果來得好,由於此研究預測所使用的歷史資料天 數尚不足兩個月,因此研究結論提及若k-NN模式能利用更多歷史資料或其 它的距離量度作資料篩選, k-NN模式或許還能提供更好的預測結果。 Yang [13]把時間序列模式應用在幹道的旅行時間預測研究上。透過實際採 用裝有GPS 系統的探針車於美國明尼蘇達州 194 號高速公路作實際研究。 其方法是將蒐集所得資料視為時間序列,以ARIMA 模式進行旅行時間預測, 結果顯示此方法能夠有效預測短期內的旅行時間。2.3 類神經網路法
人工神經網路是由許多的人工神經細胞(Artificial Neuron)所組成,人工神經細胞又稱為類神經元、人工神經元或處理單元(Processing element),每 一個處理單元的輸出以扇狀送出,成為其他許多處理單元的輸入。處理單 元其輸出值與輸入值的關係式,一般可用輸入值的加權乘積和函數來表示: 其中: =模仿生物神經元的模型輸出訊號。
f=
模仿生物神經元模型的轉換函數(Transfer Function),是一個用以將從其他 處理單元輸入的輸入值之加權乘積何轉換成處理單元輸出值的數學公 式。 =模仿生物神經元模型的神經節強度,又稱為連結加權值。 =模仿生物神經元模型的輸入訊號。 =模仿生物神經元模型的閥值。 介於處理單元間的訊號傳遞路徑稱為連結(Connection)。美一連結上有 一個加權值 ,用以表是第 i 處理單元對第 j 個處理單元的影響強度,如 圖 所示。 人工神經網路的基本結構可分為三個層次:1. 處理單元(Processing element, PE):為人工神經網路組成的基本單位,處 理單元的作用可以三個函數來說明: (1) 集成函數(Summation Function):將其它處理單元之輸出透過網路連 結傳至之訊息加以綜合。 (2) 作用函數(Activity Function):作用函數的目的是將即成函數值與處 理單元目前的狀態加以綜合,但一般人工神經網路模式的作用函數 採直接使用集成函數輸出,故其作用並不明顯。 (3) 轉換函數(Transfer Function):轉換函數的目的是將作用函數的輸出 值經轉換作用後成為處理單元的輸出,即處理單元即輸出值 (作用 函數輸出值)。而經由轉換函數的作用,使得人工神經元網路具有解 決非線性問題的能力。 2. 層(Layer):若干個具有相同作用的處理單元成為「層」,一般的人工神經
網路架構中主要分為三層。分別為輸入層、隱藏層與輸出層。 3. 網路(Network):若干個具有不同作用的「層」集合成為網路,而網路本 身則具有學習與回想的功能。 倒傳遞類神經網路架構圖 倒傳遞人工神經網路之學習演算過程一般包括下列幾項: 1. 設定網路參數、隨機設定出使權重ω與閥值θ。 2. 計算能量函數(或稱誤差函數):學習演算過程旨在降低網路輸出結果 與實際輸出值間之差距,而其間的差距一般以能量涵述表示其學習品 質,其式如下: 1 2 i 1 2 m 1 2 Y1 Y2 輸 入 層 隱 藏 層 輸 出 向 量 X1 X2 Xi 輸 入 向 量
:處理單元
1 2 其中: 為能量函數。 為實際值。 為輸出層(j)之輸出結果。 3. 以訓練樣本(一般而言為歷史資料)訓練網路,並使學習過程之能量函 數最小化。能量函數最小化的過程通常是以最陡坡將法(Gradient Steepest Descent Method)使能量函數最小化。而權重ω與閥值θ的 改變量△ω與△θ等於: △ω=-η ω ,△θ=-η θ 其中,η為學習效率,即控制每次加權值改變量的幅度,而學習效率 之大小對網路的收斂有決定性。經由網路學習使能量函數最小化之過 程,新的權重與閥值分別為ω(NEW)=ω+△ω 與θ(NEW)= θ+△θ。 4. 重複步驟三,直到收斂為止。 上述四個步驟為到傳遞人工神經網路主要的學習過程,藉由學習過程 變可使網路修正原先隨機設定之權重,進而達到降低誤差的目的;而 後以測試樣本(非學習樣本之歷史資料)測試網路之精確度。若網路輸 出結果合乎要求,則可應用至待推案例中;若不合乎要求,則重複步 驟三之學習過程,重新設定新的學習速率,反覆學習,值達合乎模式 的要求為止。 李季森[16]探討國內高速公路駕駛人變換車道行為與變換車道時間,進行探 討與推導相關公式,並進一步撰寫模擬程式,進而探討不同預測時間、流 量、探針車混合比例與區段長度等相關參數之實驗組合,並利用探針車所 收集之相關資料,透過倒傳遞類神經網路進行旅行時間之預測,以期提供 精準之旅行時間預測。經由反覆的校估與測試結果可知,所構建旅行時間 預測模式屬於「高精準預測」,可作為交通相關單位參考。 林士傑[17]利用運研所網站所提供的即時資訊、客運公車的 GPS 交通資訊, 及中華顧問工程司之交通千里眼(E-traffic)所提供即時交通播報資訊(如事 件、施工、車輛偵測器等),加上交通量調查報告與高速公路幾何資料等, 運用倒傳遞類神經網路準確預測高速公路旅行時間。該研究以北部區域路 段為研究範圍,構件預測模式,來提供用路人參考,以降低不確定性。
2.4 k-NN 方法
k-NN 方法基本的運算方式是先將歷史資料庫中的資料作分群,將輸入 的現況資料與分群後的歷史資料庫中作比對,找尋 k 組與現況資料最相近 的資料,利用這 k 組歷史資料的特性推估未來資料。所以在建立k-NN 預測 模式前,首先要做好分群的動作,通常依照星期(weekly)、季節(seasonal)、 或是將每天(daily)視為一個 pattern,亦或是根據資料分析來找出明顯的特徵 分群。 k-NN 模式在進行資料比對時,以距離量度來判斷現況資料與歷史 相近的程度,在資料選取時候,為了降低不同車道間所可能產生的偏差, 模式也可以用權重不同的加權方式,對於不同車道對預測結果的影響作考 慮,或是依照選取資料時間的相近程度,加上權重值作調整,增加比對資 料的可靠性。 在尋找 k 筆資料過程中,如何設定 k 值是一項需要解決的問題,而多 數的k-NN 文獻中顯示,需測試不同的 k 值,來尋找使預測誤差值降至最低 的解作為設定 k 值的最佳解,如此一來,可確保產生最小預測誤差,提供 最佳的預測結果。 Altman[1]提出了 k-NN 法,該方法先將歷史資料區分群,再將輸入資料與 分群後的歷史資料相比對,比對出該資料與那 k 組歷史資料較為類似,即 可利用 k 組歷史資料推測未來資料。 Smith [9]研究對四種模式進行績效評估,分析比較以下四種交通流量的預 測方法:歷史平均法、ARIMA 法、類神經網路法與 k-NN 模式,評估的方法 為利用歷史的流量資料預測未來的流量再和實際值作比對,判斷哪一個方 法的績效較差。結果發現,歷史平均法對於突發事件發生時,無法立即有 效判斷造成不準確的預測,ARIMA 預測模式方面,對於遺失的資料無法作 有效處理,且此方法較適合預測趨勢性與季節性等時間序列資料。而類神 經網路需要繁複的訓練過程,當資料量大時,誤差也隨之變大,且其與k-NN 比較其誤差值較大。 所以研究結果得到,雖然k-NN 方法在搜尋相鄰近資料較複雜,但 k-NN 預測模式誤差值比其他方法來的小,因此利用k-NN 模式針對流量進行預測 是可行的。 Smith [11]將權重(Weight)的想法加入 k-NN 的模型,考慮目前的流量可能會 與先前的交通流量有關係,但是隨著時間距離的增加,其影響的程度愈小,所以利用權重的方法進行修正,將不同時間所造成的影響納入考慮。 Clark[4]除了流量外,利用 k-NN 模式試著對其他可收集到的交通資訊與歷 史資料進行比對,如速度和佔有率,找尋即時資訊和哪一天的歷史資訊相 類似,而找尋的方式為歷史與即時資訊的平方差加總在距離量度內時,即 判斷該分群的歷史資訊與即時資訊相類似。結果發現當同時利用流量、佔 有率和速率這三項變數進行預測時,所得到的預測值相對於個別比對而言, 誤差有下降的現象,所以愈多變數進行討論可以得到更精確的結果。判斷 模式建立如下:
tss: total sum of squares
L L L q : 流量 v : 速率 o : 佔有率 L: 比對範圍的總偵測器數量。 rij: 即時時間(i)、偵測器(j)之交通資訊。 mij: 歷史時間(i)、偵測器(j)之交通資訊。 wq : 流量權重; vq : 速率權重; oq : 佔有率權重 Robinson [8]研究針對都市內的旅行時間進行預測,並提出了四點建立k-NN 模式時應先設定的條件,試著使用不同的距離量度來比對歷史資料,及找 出k值最佳解,四項條件如下所示: 1. 決定每一個特徵包含哪幾種行為模式。 2. 設定距離量度(distance metric)。 3. 決定判斷分群的樣本數量。 4. 利用加權法減少k-NN 模型的誤差。 Lam[6]利用每年的香港交通統計年報流量資料預測未來交通流量變化,本 研究利用兩種母數模式 ARIMA 和類神經模式與兩種無母數模式 k-NN 和 Gaussian Maximum Likelihood(GML)作預測效果比較。研究結果顯示,無母 數模式比母數模式預測誤差較小且效果較佳,k-NN 模式在短期流量預測效 果又比 GML 較佳,而 GML 模式對於周期性穩定的交通流預測會比 k-NN 模式效果來得好,因此研究建議,若要進行短期的交通流量變化預測,利 用k-NN 預測模式較適合。
Weng[12]收集北京高速公路的歷史資料利用 k-NN 模式預測未來速度變化,
將歷史資料依照交通流量特性作分群,選擇利用Euclidean Distance 作為距 離量度,並依照距離遠近加上權重值作調整,最後利用浮動車輛(floating car) 所收集的資料驗證預測結果,其EDP(Error Distributing Probability)超過 90%, 是一項非常有效的預測方法。 Smith[10]研究利用即時流量資料,利用 k-NN 模式預測未來流量,模式建 立前要先決定以下三項條件: 1. 狀態向量(State Vector) 2. 距離量度(Distance Metric) 3. 預測函數(Forecast Function) 利用Euclidean Distance 作為距離量度,找出每筆歷史資料與即時資料 的距離,選擇 k 筆最鄰近歷史資料作平均,即是研究所要的預測結果,最 後,測試不同 k 值所得到預測誤差,選擇最小誤差的 k 值使預測精確度達 到最高。 Chang[2]於美國馬里蘭(Maryland)在 25 英哩的快速道路間,使用 10 個偵測
器與五個 LED 看版,將偵測所得資訊以旅行時間估計模型(Travel Time Estimation Module)來建立現有的歷史旅行時間資料庫,再透過此資料庫使 用旅行預測模型(Travel Time Prediction Module)來預測旅行時間。
而事故偵測模型(Incident Detection Module)可將路段事故預先知會駕 駛人,並將事故路段視為不可行,避免因為事故造成的擁塞使得預測結果 偏差。遺失資料模型(Missing Data Module)可防止因為偵測器失靈所造成的 資訊延滯與遺失,結合以上四種模型,可在各LED 提供用路人通往下個交 流道出口的估計旅行時間。
研究中將旅行時間預測模組分為k-NN 模式(k-Nearest Neighbors Model) 與增強時變係數模式(Enhanced Time-Varying Coefficient Model)兩大部分。 k-NN 模式會根據目標路段的交通狀態(traffic pattern)和幾何特徵(geometric features),在歷史資料庫中比對最接近目前交通狀態的資料,再拿來進行預 測;若沒有找到 k 筆最接近目前交通狀態的歷史資料,則使用增強時變係 數模式,找出每日與每週間旅行時間的關係來進行預測。整個模組運作的 流程圖如下圖所示:
[資料來源:Chang, 2004]
2.5 其他預測方法
陳建名[19]以市區公車裝配 GPS 回傳的即時資料為主要來源,將公車旅行 時間分為運行時間和停等時間,研究訂定一個門檻值,當公車在正常情況 下行駛,使用歷史平均速度做預測,當實際速度與歷史平均速度差超過門 檻值即判斷交通狀況出現異常,即利用前車資訊做預測。 研究將歷史資料庫依車速高低不同切割成數個不同交通時段,而在不 同時段,研究以不同預測模式來預測公車於路口停等號誌之時間,研究結 果顯示,在尖峰期間,受到交通管制影響,使得停等時間預估產生較大誤 差,影響預測結果,而在路線較短的時候,也會產生較高的誤差。吳佳峰[15]透過車輛歷史旅行資料預估車輛旅行時,模式採用裝設 GPS 之 探針車輛所傳回之定位資訊推估車輛所在位置,從車輛速度變化觀察實際 車流之交通情況。研究將車輛總旅行時間分段加總,將旅行時間分為車輛 運行時間和車輛停等時間兩部分,當道路狀況出現了非重現性之壅塞時, 以前車資訊調整預估車輛運行時間。 研究以實際國內客運業者車輛旅行資料對預估模式做實例之測試,從 測試結果發現模式在未遭遇非重現性之壅塞時,預測旅行時間有著相當不 錯之準度,而當遭遇非重現性壅塞時,模式亦能透過預估旅行時間之調整 機制,控制在可接受之誤差範圍內。
Choi[3]利用GPS與數位化道路地圖(Digital Road Map)來計算路段之動態旅
行時間。對於動態交通資訊而言,旅行時間預測為一項重要的要素,研究 利用GPS與GIS技術來蒐集都市街道之動態路段旅行時間,並對於測量路段 旅行時間的技術作比較。在都市幹道網路上,路段旅行時間為行駛時間 (running time)與延滯時間(delay times)的總和,易受到號誌系統與交通環境 所影響。研究利用流動車輛法(floating car method),用以得到點至點的旅行 時間,不過此方法須蒐集較多的交通資料,如各個車道、方向、時段的交 通資料,最後利用實際收集到的交通路網資料來與本研究所計算出來的旅 行時間值進行績效評估,證實預測結果準確。
表 2.1 各種預測方法之比較 預測方法 理論內容 優點 缺點 線性迴歸 利用一個或多個自變 數來預測應變數,其中 自變數與應變數皆為 線性關係,利用所獲得 之樣本資料去估計模 型中參數的計量分析 方法。 1.根據統計理論基 礎,解釋變數與因變 數之關係,較有說服 力。 2.有同趨勢之規律性 時,根據大量樣本個 數,即可計算出線性 迴歸方程式。 1.係數固定,故對外 在因素的改變,缺 乏反映之彈性。 2.不適用於少量樣本 之場合。 時間序列 發掘時間序列變數現 在與過去的關係,預測 此變數未來的趨勢 值,時間相隔越短之兩 觀測值,其相關性越 大,此方法基本上不採 用其他的變數,只採用 過去的資料來構建預 測模式。 1.對於週期性、季節及 循環性之趨勢易於 掌握。 2.純粹以變數歷史數 據作為預測基礎,資 料收集容易。 1.模式選擇需高度技 巧與經驗。 2.缺乏統計理論基 礎,造成模式解釋 不易。 類神經網路 模擬人類腦神經組織, 以歷史或模擬資料作 為訓練樣本,利用輸 入、輸出、隱藏層等各 種不同方式連結,透過 訓練的方式,讓類神經 網路反覆學習,直到對 每個輸入都能正確對 應到所需要的輸出。 1.能解決較複雜、非線 性關係的問題。 2.事前無須任何假設 輸入與輸出變數之 間的關係。 3.應用範圍相當廣 泛,舉凡生物、醫 學、運輸…等皆有所 應用。 1.模式需經過足夠之 樣本進行訓練始能 使用。 2.容易產生過度訓練 或訓練不足。 4. 最佳隱藏層數目 及神經元數目決 定無規則可循。 k-NN 是一種利用歷史資料 特性推估未來資料的 方法。先將資料作分 群,透過現況資料與歷 史資料進行比對,找出 k筆最近的歷史資料預 測未來資料。 1. 當歷史資料有遺漏 或錯誤而沒有辦法 得到完整資料時, 能適時利用其他歷 史資料作彌補。 2. 資料經過分群後, 大幅減少搜尋時 間,加快預測速 度。 1. 搜尋相鄰近資料 過程較複雜。 2.必須找出k值最 佳解。 資料來源:本研究整理
2.6 小結
經由本章節對於各種預測方法之介紹後,考量各種預測方法之適用性, 作為本研究旅行時間預測模式之構建基礎。從上述文獻回顧中可發現線性 迴歸方法是一種可以的方式是一種概念較簡單,但又不失預測準確度的方 法,可運用在預測旅行時間週期性的變化上。在以往的線性迴歸預測模式 中,多採用一個迴歸模式作預測,當時間變化或外在因素改變時,因迴歸 模式缺少彈性變化,無法即時反應旅行時間變化情況,容易產生較大預測 誤差,因此本研究採用的TVC 模式,能夠改善這項缺點,其作法為先將歷 史資料做分群,以此建立各分群的迴歸模式,並隨時更新參數,當收到一 筆即時資料時,可立即判斷該筆資料屬於哪一分群,代入該分群的迴歸模 式輸出預測結果,如此可即時反應各個時段旅行時間的變化,因此本研究 選擇TVC 模式作為旅行時間預測模式之一。 而由於考量路段上會碰到偵測資料遺失的情況,造成旅行時間預測誤 差變大,甚至造成無法預測的情況發生,經由以上的文獻回顧可得知,k-NN 預測模式在資料遺失處理上,能適時利用其他歷史資料作彌補,不會因資 料缺漏而有無法預測的情況發生,以及在國外研究文獻上,也證實k-NN模 式的預測準確度高,因此本研究選擇使用k-NN作為另一預測模式,並與TVC 模式作預測比較,評估兩種方法應用在高速公路旅行時間預測的準確性, 以提供用路人更準確的預測資訊。第三章 k-NN 模式構建
本研究發展之旅行時間預測模式,為採用裝設GPS 定位之探針車輛所 回傳之定位資訊,所推估出的旅行時間作為構建預測模式的資料來源,分 別利用k-NN 模式和 TVC 模式進行旅行時間預測,並比較兩種預測模式的 準確度與績效,以提供用路人有效的預測資訊。本章將先針對k-NN 預測模 式進行構建,首先介紹k-NN 模式建立流程,依照建立模式流程各步驟進行 探討,以構建適合本研究預測模式完整架構,待確認模式流程架構後,即 依照流程各步驟開始進行。3.1 k-NN 模式介紹
建立旅行時間預測模式的目的在於,從即時的交通資訊預測未來的旅 行時間為何,本研究採用k-NN 方法進行模式構建,其基本的運算方法為先 將歷史資料作分群,當收到一筆即時資料時,可立即判斷即時資料屬於哪 一分群,在分群的歷史資料庫中利用距離量度比對即時資料與歷史資料, 如此先進行資料分群動作,可減少資料比對的時間。 在比對完歷史資料後,可得知各筆歷史資料的距離量度,從各距離量 度中尋找 k 筆與即時資料最鄰近的歷史資料,表示這 k 筆歷史資料與即時 資料相似,將這 k 筆歷史資料加入權重值作調整,則此加權後的平均值即 是本研究所取得的預測結果。因此要建立一個完整的k-NN 模式,必須先確 認各個步驟的作法,本研究將依照k-NN 流程圖的每個步驟進行逐步探討, 以建構完整k-NN 旅行時間預測模式。k-NN 流程如圖 3.1 所示:圖 3.1 k-NN 流程圖 將歷史資料作分群 判斷即時資料屬於哪一分群 比對即時資料與分群中的 找出最鄰近的 k 組歷史資料 將 k 筆資料作加權平均 輸出預測結果
3.1.1 k-NN 資料分群
在建立預測模式前,首先要做好分群的動作,當接收到一筆即時資料, 能夠利用較短時間在龐大的資料庫中搜尋需要的歷史資料,減少比對時間, 迅速將預測結果提供給用路人。因此在建立k-NN 預測模式前,做好歷史資 料分群是首要工作,研究文獻中有依照星期別、季節、或是將每天視為一 個分群,或是根據資料分析來找出明顯的特徵分群。若是按照每天的資料 作分群,可再將當天的交通狀況區分出尖峰與離峰交通狀態,或是將每周 的交通狀況區分出假日與非假日的交通趨勢,也可以將每季的交通狀況則 區分出不同季節的交通變化,如夏季的交通行為與冬季的交通行為就會有 所不同。3.1.2 距離量度(Distance Metric)
在 k-NN 模式中,距離量度的主要功能為比對現況資料與歷史資料相近 程度的一種判斷工具。當距離量度小於門檻值,則可判斷此筆現況與歷史 資料相類似,相反的,當距離量度大於某門檻值,則判斷此筆現況資料與 歷史資料差異較大。距離量度較常見的主要有下列三種,分述如下: (一) 歐幾里得距離(Euclidean distance) 設有 n 個事物,每個事物有 m 個屬性,則第 i 個事物與第 j 個事物間的 歐幾里得距離如式 3-1 所示: 3‐1 (二) 馬式距離 (Mahalanobis distance,D
2 ) 馬式距離D
2可用矩陣如式 3-2 來表示:上式中,
C
W為聯合組內共變數矩陣(pooled within-group covariance matrix),馬式距離
D
2是歐幾里得距離平方的一種引申: 3‐3d
ij2X
iX
j ’X
iX
j /D
ij2X
iX
j ’C
W‐1X
iX
j3‐2
i1 1
,
i2 2
,
i3 3
, .…,
im
1 1 2 2
意即,在求
d
ij2時,C
W‐1C
WI
(單元矩陣)。換言之,當各軸的單位長度相 等,且各軸互為垂直時,歐幾里得距離平方與馬式距離D
2相同。(三)街道區距離 (city block distance)
設有 n 個事物,每個事物有 m 個屬性,則第 i 個事物與第 j 個事物間的 街道區距離可以如式3‐4 衡量:
3‐4
3.1.3 k 值設定
k 值的選定,是決定預測誤差大小的關鍵步驟,若是選取太大或太小的 k 值,容易產生較大的預測誤差,導致預測結果產生偏差,因此一般研究在 k 值設定這一步驟時,通常都是測試選取不同 k 值,找出各個 k 值所得應到 的誤差結果,由此取得使誤差最小的 k 值,以此設定為 k 值最佳解,如此 可確保預測誤差達到最小。 本研究 k 值的設定,主要先設定不同的門檻值來進行 k 值選取,當比 對的距離量度小於此門檻值,即判斷該筆資料與即時資料相近,依照各門 檻值內所得到的不同 k 值,找出該時段預測誤差最小的 k 值,以此作為該 時段的最佳 k 值解,由於每五分鐘即預測一次,k 值也隨著每五分鐘變化一 次,以找出適合該時段的最佳 k 值解。 | |3.2 k-NN 模式構建
本研究構建之一旅行時間預測模式,為使用k-NN 方法依照上述 k-NN 流程步驟,構建高速公路旅行時間預測模式。首先,在資料分群的步驟, 依照星期別作區分,與即時資料進行比對,比對時,將同時段、兩兩固定 點之間的即時旅行時間資料與歷史旅行時間資料互相作比對,找出 k 筆最 鄰近的歷史旅行時間資料,將這 k 筆旅行時間資料依照距離量度的大小作 加權平均,以此輸出旅行時間預測值。 研究將針對各時段的 k 值進行分析,找出 k 值最佳解。以下將相關預 測步驟進行說明,本研究k-NN 模式構建之相關流程可表示如圖 3.2 所示。圖 3.2 k-NN 模式構建流程圖 即時旅行時間資料 (時間 t) 比對即時資料與歷史資料 找出該時段的 k 值 最佳解 歷史旅行時間 資料庫 資料庫進行 分群處理 分群後的歷史旅 行時間資料庫 將 k 筆歷史資料作 加權平均 輸出旅行時間預測值 (時間 t) t t 1 選取 k 筆歷史資料
而本研究 k-NN 模式構建流程運作主要可分為下列五個步驟,說明如下: Step 1.交通資料蒐集 本研究利用行駛在國道一號高速公路上裝設有GPS 的大客車探針車 蒐集完整交通資訊,利用路段上偵測器位置作為固定點位置,推估出路段 上兩兩固定點之間的旅行時間資料作為預測資料來源,檢驗預測結果時, 以ETC 所蒐集兩收費站之間的旅行時間當作實際資料與預測結果作比對, 以評估預測績效。由於本研究主要預測小客車的旅行時間,因此在 ETC 資 料方面,將使用小客車的旅行時間作使用。各種資料庫之資料形式,整理 如表 3.1 所示: 表 3.1 各種資料庫之資料形式 資料來源:本研究整理 主要資料內容 資料形式 GPS 探針車 資料庫 車輛編號 經度座標 緯度座標 日期、時間 車速 ex.車輛 656-FC 東西經(度、分) 南北緯(度、分) 年/月/日 時:分:秒 公里/小時 歷史旅行時間 資料庫 上、下游固定點編號 日期、時間 上、下游固定點間旅行時間 行車方向 S:南 ; N:北 年/月/日 時:分:秒 秒 S:南 ; N:北 ETC 旅行時間 資料庫 日期、時間 ETC 起、迄點代碼 平均旅行時間 行車方向 車種代碼 年/月/日 時:分:秒 22002:楊梅收費站 14003:泰山收費站 分鐘 S:南 ; N:北 31:小客車,41:大客車 資料格式 資料庫
Step 2. 將歷史資料作分群 建構 k-NN 模式時需先將歷史資料作分群,當收到一筆即時資料時能 夠立即判斷資料屬於哪一分群,再比對即時資料與群中的歷史資料,如此 可減少比對時間,增加預測速度。本研究 k-NN 模式將依照不同的星期別 將資料作分群,將一周七天資料分成七群,若遇到特殊節日,須獨立出來 考慮。 Step 3. 比對即時資料與歷史資料 利用距離量度比對即時與歷史資料,以得到各筆歷史資料與即時資料 的差異程度。本研究的距離量度採用歐幾里德距離(Euclidean Distance)算 法,比對與即時資料同星期別、前後半小時的歷史資料,將兩兩固定點間 的即時旅行時間資料與歷史旅行時間資料,依照歐幾里得距離方法作平方 差加總,找出該分群資料庫中各筆歷史資料與即時資料的距離量度。 Step 4. 選取 k 筆資料 依照距離量度的大小排序,選取 k 筆最小距離量度的歷史資料,而 k 值設定方式,必須要找到 k 值最佳解,也就是讓預測誤差最小的 k 值解, 作為設定 k 值的條件。 Step 5. 利用加權法減少 k-NN 模式誤差 由於現況的旅行時間會與先前的旅行時間相關,但是隨著時間距離的 增加其影響程度越小,所以我們可以根據歷史資料距離即時資料的時間差 距或是距離量度的大小,將這 k 筆資料加入權重值做調整,以減少旅行時 間預測誤差。 Step 6. 輸出旅行時間預測值 將預測的旅行時間輸出,並將此旅行時間預測值存入歷史資料庫中, 提供給下一個時段的旅行時間預測模式作使用。
3.3 k-NN 模式範例說明
以下舉一範例作說明:要預測 2008/3/6(四)早上 8 點從 A 收費站出發到 B 收費站間的旅行時間,其中有五個固定點 x1、x2、x3、x4、x5,在早上 8 點一組收到兩點間即時旅行時間資料。 範例假設如下: 1. 歷史旅行時間資料庫內只有 2008 年 1、2 月份的資料。 2. 只搜尋同時段旅行時間資料。 在 2008/3/6(四)早上八點鐘收到即時旅行時間資料,若只搜尋同時段 旅行時間資料,也就是在比對歷史資料的時候,只比對 2008 年 1、2 月份 同星期別(禮拜四)早上八點鐘的資料。 3. 權重值皆設定為 1。 4. k 值設定為 3。 之後使用實際資料時會重新作設定。 圖 3.3 k-NN 範例路段示意圖 本範例將分成三個步驟來進行,說明如下: A 收 費 站 B 收 費 站 x2 x3 x4 x1 x5Step1. 比對即時資料與歷史資料 因為已將 1、2 月份歷史資料庫依照同星期別作好分群,因此,在比對 資料時只比對同時段的歷史資料,所以總共有 1/3(四)、1/10(四)、1/17(四)、 1/24(四)、1/31(四)、2/7(四)、2/14(四)、2/21(四)、2/28(四)這九天, 比對各偵測器間八點鐘的歷史旅行時間資料。 Step2. 找出各筆歷史資料的距離量度 各筆歷史資料的距離量度如表 3.2 距離量度資料表所示。 表 3.2 k-NN 距離量度資料表 時間單位:秒 各筆歷史資料與即時資料的距離量度算法如下所示: 1/3 : 280 200 370 250 390 290 350 260 181.9341 1/10 : 280 260 370 390 390 500 350 280 227.1563 時間 x1~x2 旅行時間 x2~x3 旅行時間 x3~x4 旅行時間 x4~x5 旅行時間 距離量度 1/3 AM 8:00 200 250 290 360 181.9341 1/10 AM 8:00 260 390 500 280 227.1563 1/17 AM 8:00 250 440 280 330 147.3092 1/24 AM 8:00 300 460 390 360 130.384 1/31 AM 8:00 280 300 500 420 187.3499 2/7 AM 8:00 400 360 250 380 110.4536 2/14 AM 8:00 350 500 400 290 198.2423 2/21 AM 8:00 290 470 390 300 171.4643 2/28 AM 8:00 330 360 330 410 181.9341 3/6 AM 8:00 280 370 390 350 …
2/28 : 280 330 370 360 390 330 350 410 181.9341 Step3. 選擇 k 筆資料 因為 k 值設定為 3,所以從距離量度中篩選最小的三筆,分別為 1/17、 1/24、2/7 這三天。 可得: VD1~VD2 旅行時間為:(250+300+400)/3=316.67(秒)≒5.28(分鐘)。 由於每五分鐘可收到一筆即時資料,而 x1~x2 的旅行時間已超過五分 鐘,因此 x2~x3 的旅行時間必須搜尋下一時段(8:05)的旅行時間資料如表 3.3 所示。 表 3.3 8:05 旅行時間資料表 從表 3.3 可得: x2~x3 旅行時間為:(280+300+290)/3=290(秒) ≒4.83(分鐘)。 因為未超過五分鐘,因此 x3~x4 的資料還是用 8:05 分的資料來計算: x3~x4 旅行時間為:(300+360+330)/3=330 (秒) 5.5(分鐘)。 由於 VD2~VD3 旅行時間 4.83(分鐘)加上 x3~x4 旅行時間 5.5(分鐘)總 共為 10.33 分鐘,已超過十分鐘,因此 x4~x5 的旅行時間,需要蒐尋下兩 個時段(8:15)的旅行時間資料如表 3.4 所示。 時間 x1~x2 旅行時間 (秒) x2~x3 旅行時間 (秒) x3~x4 旅行時間 (秒) x4~x5 旅行時間 (秒) 1/17 AM 8:05 270 280 300 310 1/24 AM 8:05 320 300 360 370 2/7 AM 8:05 430 290 330 350
表 3.4 8:15 旅行時間資料表 從表 3.4 可得: x4~x5 旅行時間為:(320+350+330)/3=333.33 (秒) ≒5.56(分鐘)。 Step4. 輸出旅行時間預測值 整理以上的旅行時間資料結果可得到: x1~x2 旅行時間為:(250+300+400)/3=316.67(秒)≒5.28(分鐘)。 x2~x3 旅行時間為:(280+300+290)/3=290(秒) ≒4.83(分鐘)。 x3~x4 旅行時間為:(300+360+330)/3=330 (秒) 5.5(分鐘)。 x4~x5 旅行時間為:(320+350+330)/3=333.33 (秒) ≒5.56(分鐘)。 因此,預測 3/6 早上 8 點鐘 A 收費站到 B 收費站旅行時間為: (5.28 + 4.83 + 5.5 + 5.56) = 21.17 (分鐘)。 時間 x1~x2 旅行時間 (秒) x2~x3 旅行時間 (秒) x3~x4 旅行時間 (秒) x4~x5 旅行時間 (秒) 1/17 AM 8:15 280 270 320 320 1/24 AM 8:15 320 320 310 350 2/7 AM 8:15 330 280 300 330
第四章 時變係數模式
在上一章已介紹完k-NN 旅行時間預測模式,本章將介紹本研究所使用 的另一項旅行時間預測模式-時變係數模式(Time-Varying Coefficient Model, TVC Model),其基本概念為多元線性迴歸模式(Multiple Linear Regression Model)為基礎,本章將從 TVC 基本概念作介紹,經由構建流程每一步驟深 入作探討,以建構完整TVC 旅行時間預測模式。
4.1 TVC 模式介紹
上述提到的多元線性迴歸模式,又稱為複迴歸模式(Multiple Regression Model),其主要在自變數的部分,為探討兩個以上的自變數與因變數之間 的關係,利用最小平方法(Method of Least Squares) 校估各個迴歸係數,建 立多元線性迴歸方程式,當得到自變數xi時,即可預測依變數y
。
其模式型 態如式4‐1 所示:y α β
1x
1β
2x
2… β
nx
nε
i 4‐1y
為依變數 (dependent variables)。α
為常數 (constant)。
β
i為迴歸係數 (regression coefficients)。
x
i 為自變數 (independent variables)。εi
:誤差值 (error)。 TVC 模式也就是利用複迴歸模式為基礎,依照時間變化係數跟著作改 變。而本研究利用蒐集資料的時間差異,所對應不同的迴歸係數,以此建 立不同時間點所形成的迴歸模式,TVC 流程圖整理成圖 4.1 所示。因此, 建構TVC 模式前可先利用分群方式將資料作處理,將整理好的分群歷史資 料利用統計軟體SPSS 進行線性迴歸模式分析,依此建立各個分群的線性迴 歸模式,當輸入一筆即時資料,立即可判斷即時資料屬於哪一分群,將此 即時資料代入相同分群的迴歸模式,即可輸出所要的預測結果。圖 4.1 TVC 流程圖 將歷史資料作分群 建立各分群的迴歸模式 檢定迴歸模式的統計顯著性 分析修正判定係數R2的解釋 能力 輸出預測結果 將即時資料代入分群迴歸 模式 迴歸分析的基本統計假設
以下將會依照TVC模式流程圖每個步驟作一詳細說明,以建構完整 TVC旅行時間預測模式。
4.1.1 TVC資料分群
在上一章構建k-NN模式中也有提到資料分群步驟,在本研究k-NN模式 與TVC模式分群的目的及方法並不完全相同。在k-NN模式中,分群的目的 主要是能減少資料比對的時間,增加預測速度,因此依照不同的星期別來 作分群。而TVC模式分群的目的是為了找出旅行時間的周期性變化,以此 構建各分群的迴歸模式,讓迴歸預測模式能夠隨著時間作改變。 因此,本研究為了找出旅行時間週期性的變化,將依照不同星期別以 及將每天的交通狀況區分為尖峰、離峰時段作分群,尖峰時段為星期一到 星期五早上七點到九點和下午五點到七點,其餘皆屬離峰時段,試著利用 此分群方式,構建本研究的TVC旅行時間預測模式。4.1.2 迴歸基本統計假設
在使用迴歸分析前,必須要確認資料是否符合迴歸分析的基本統計假 設,否則,當資料違反迴歸分析的基本統計假設時,會導致統計推論偏誤 的發生。 迴歸分析的基本統計假設有下列四項: ¾ 線性關係 依變數和自變數之間的關係必須是線性,也就是說,依變數與自變數存 在著相當固定比率的關係,若是發現依變數與自變數呈現非線性關係時, 可以透過轉換(transform)成線性關係,再進行迴歸分析。 ¾ 常態性(normality) 若是資料呈現常態分配 (normal distribution),則誤差項也會呈現同樣的分 配,當樣本數夠大時,檢查的方式是使用簡單的 Histogram (直方圖), 若是樣本數較小時,檢查的方式是使用Normal Probability Plot (常態機率 圖)。¾ 誤差項的獨立性 自變數的誤差項,相互之間應該是獨立的,也就是誤差項與誤差項之間 没有相互關係,否則,在估計迴歸參數時,會降低統計的檢定力,我們 可以藉由殘差(Residuals)的圖形分析來檢查,尤其是與時間序列和事件相 關的資料,特別需要注意去處理。 ¾ 誤差項的變異數相等(Homoscedasticity) 自變數的誤差項除了需要呈現常態性分配外,其變量數也需要相等,變 量數的不相等(Heteroscedasticity)會導致自變數無法有效的估計應變數,例 如:殘差分佈分析時,所呈現的三角形分佈和鑽石分佈,在SPSS軟體中, 我們可以使用Levene test,來測試變異數的一致性,當變異數的不相等發生 時,我們可以透過轉換(transform)成變異數的相等後,再進行迴歸分析。
4.1.3 檢定統計顯著性
複線性迴歸分析除了求取參數係數值外,還必須確定所得到的參數係 數值是否有效,再求解迴歸方程式前,線性迴歸模型只是一種假設,因此 還要進行統計測試,以確保所得之參數在統計上式有意義價值,以下介紹 迴歸分析所需進行知統計測試,原則上區分成兩個部分,整體迴歸模式建 立之測試和個別參數係數值顯著性之測試,整體的檢定滿足顯著性後,才 有意義進一步進行個別參數之檢定,如下: (一) 整體迴歸模式建立之測試 在迴歸分析中,欲知n個自變數對應變數是否有影響,則必須對模式建 立一統計檢驗,迴歸模式的顯著性檢定,一般都使用F test (檢定),F檢定 將所有自變數計算進來,看應變數 Y 和所有自變數 Xn 是否有統計的顯 著性。 F 檢定的虛無假設(Null hyposesis)如下: H0 : β 1 β 2 ….. βn 0 4‐2 H1 : Not all β i0 i 1,2, …., n F 值的計算公式如4‐3所示:
F
SSR SSE N
MSR/MSE 4‐3
¾ SSR:迴歸平方和(Sum of Squares Regression, SSR),是Y的預測值和Y的 均值之間差異平方的總和,計算公式如式4-4所示: 4‐4 Yi : Yi的預測值 ; Y : Y的平均值
¾ SSE:誤差平方和(Sum of Squares Error, SSE),是Y的實際值和Y在迴歸 上的預測值之間差異平方的總和,計算公式如下:
4‐5
¾ 總平方和(Sum of Squares Corrected Total, SST) ,計算公式如下:
4‐6 4‐7 SST SSE SSR 4‐8
¾ MSR: Mean Square Regression ¾ MSE: Mean Square Error
變異數分析(ANOVA)如表4.1所示,其中k表共有k個待判定的迴歸係數,N 共有多少個觀測量。 SSR Yi Y SSE Yi Yi SST Yi Y SYY Yi Y Yi Yi Yi Y
表4.1變異數分析表 來源 平方和 自由度 平均平方和 F檢定 迴歸 SSR k MSR MSR/MSE 殘差 SSE N-k-1 MSE 總和 SST N-1 算出F 值後,由 F 分佈表所查到之 F , ,N 值作比較,α 為選定之 顯著水準。若根據統計量計算所得的值F > F , ,N ,則我們在顯著水 準α 下,拒絕 H0,認為線性迴歸方程式是顯著的,表示此組係數項 β 對 Y 是有貢獻的;反之,認為線性迴歸方程式不顯著,不管提供之F 值為多少, 對Y 的值都沒有貢獻,表示所建立之線性迴歸方程有問題。 (二) 個別參數值顯著性之測試 若係數項β對 Y 是有貢獻的,但並非代表係數項β中之美一個係數都有 貢獻未確定哪些係數是否對 Y 有貢獻,則必須針對參數值之顯著性作一測 試如下: 4‐9 利用 t 統計量進行檢定: t βi S βi
~
t(
n-k-1)
4‐10 由此方法可算得每個參數的t 統計量,再根據選定的顯著水準即可判定 是否接受H0,若拒絕H0,表示此估計參數是顯著的,自變數Xi對應變數Y 有顯著影響,在迴歸模式中有其存在的必要。若結果是接受H0,表示此參 數不顯著,此參數在迴歸模式中無其存在之必要,一般一次t 檢驗後,只剔 除一個變量,這個變量是所有不顯著變量中t 值最小,然後重新建立迴歸模 式,在進行檢驗,直到所建立的迴歸模式即自變量都是顯著時為止。 H0 : β i 0 H1 : β i
0
4.1.4 判定係數
R
2(一) 判定係數 迴歸估計最理想的情況是所有的觀測點皆落在估計的迴歸線上,此時 誤差測度的部份為零,即SSE 0,Y 之變異情形可完全由 X 的線性函數解釋 之,也就是Y 之總變異等於迴歸變異,SST SSR。另一種情形與上述完全 相反,迴歸估計造成較大的誤差,而最差的狀況是所有變異皆為誤差變異, 即SST SSE,SSR 0。 由上面的敘述,我們得到了依值限迴歸模型的指標係數,稱為判定係 數(Coefficient of Determination),用以衡量線性關係之強度,以符號R2表示, 定義如下: R SSRSST ,0 R 1 4‐11 R2之值亦表示Y 的總變異中可藉由迴歸線解式的比例,其值越接近 1, 表示迴歸線的解釋能力越強,反之,其值越接近 0,則表示此組資料配式此 直線關係並不適當。其分子部份是因引進自變數X 進入迴歸式後,應變數 Y 的總變異減少的百分比,當R 越大,表示 X 解釋 Y 變異之能力越強。 (二) 修正判定係數 在多元迴歸模式中,一般皆認為R2愈大愈好。但事實上,判定係數R2 愈大,並不一定表示該模式愈好,因為在R2公式中,自變數每多放一個, 則其誤差平方和必定會降低,所不同的只是降低幅度大小問題而已,因此 每增加一個自變數時必定會增加。因此當研究放入一些毫無意義之自變數 時,必定可使R 增加,而誤認該變數或該模式是有意義的,因此要修正上 述之缺失,就必須考慮以修正後或調整後判定係數(Adjusted Determination Coefficient),來檢驗模式是否良好,而調整判定係數之公式定義為: 4‐12 R 1 SSE N 1 SST N k 1 1 1 R N 1 N k 1
4.2 TVC 模式構建
構建TVC 旅行時間預測模式前,須先將歷史資料作分群,本研究的 TVC 模式將依照不同的星期別及尖峰、離峰時段將資料作分群,並建立各個分 群的迴歸模式,當收到一筆即時旅行時間資料時,判斷該筆資料屬於哪一 分群,將資料代入符合該分群的TVC 模式,即可輸出旅行時間預測值。以 下將相關預測步驟進行詳細說明,其構建模式之相關流程可表示如圖 4.2 TVC 模式構建流程圖所示。圖 4.2 TVC 模式構建流程圖 資料庫進行分群處理 分群後的歷史 旅行時間資料 校估每個分群的迴歸 參數值 產生各個分群的迴歸模式 輸出旅行時間預測值 (時間 t) t=t+1 即時旅行時間 (時間 t) 歷史旅行時間資料庫 是否有發生 交通事故 將受影響的資料刪除 是 否
4.3 TVC 模式資料整理
(一) 確認路段上固定點的數量 在TVC 模式中,本研究利用 ETC 旅行時間當作應變數Y,兩固定點之 間的旅行時間當作自變數Xi,由於本研究利用偵測器的位置作為固定點, 因此要先確認所要預測的路段上共有多少偵測器來決定固定點的數量,才 可得知需要設多少自變數,由於我們要預測的路段是泰山到楊梅南下路段 的旅行時間,假設這路段上共有五個固定點 d1、d2、d3、d4、d5 如圖 4.3 所示,每五分鐘可蒐集到一組資料,共有四筆同時段、兩兩固定點之間的 旅行時間資料(d1~d2、d2~d3、d3~d4、d4~d5),因此可將這四筆旅行時間資 料設為自變數X1、X2、X3、X4,同時段從泰山收費站出發到楊梅收費站的 ETC 旅行時間資料設為應變數 Y。 (二) 將資料作整理 假設歷史資料庫中有 2008 年 1、2 月份各禮拜四的資料,我們要預測 3 月份各禮拜四早上 8:00 的旅行時間,首先依照分群方式先整理 1、2 月份 個禮拜四尖峰時段 7:00~9:00 的資料,共有 1/3、1/10、1/17、1/24、1/31、 2/7、2/14、2/21、2/28 這九天,將ETC 旅行時間資料設為應變數Y,兩 點間的旅行時間資料為自變數Xi,可將資料整理成如表 4.2 所示。當資料 整理完成後,即可匯入本研究所使用的統計軟體SPSS 進行線性迴歸模式分 析,以建立完整線性迴歸預測模式。 圖 4.3 TVC 範例路段示意圖 泰 山 收 費 站 楊 梅 收 費 站 d2 d3 d4 d1 d5表 4.2 TVC 資料整理表 日期、時間 資料型態 Y X1 X2 X3 X4 1/3(四) AM 7:00 1/3 早上 7:00 從泰山出發到楊梅 ETC 旅行時間 1/3 7:00 d1 到 d2 旅行時間 1/3 7:00 d2 到 d3 旅行時間 1/3 7:00 d3 到 d4 旅行時間 1/3 7:00 d4 到 d5 旅行時間 1/3(四) AM 7:05 1/3 早上 7:05 從泰山出發到楊梅 ETC 旅行時間 1/3 7:05 d1 到 d2 旅行時間 1/3 7:05 d2 到 d3 旅行時間 1/3 7:05 d3 到 d4 旅行時間 1/3 7:05 d4 到 d5 旅行時間 1/3(四) AM 7:10 1/3 早上 7:10 從泰山出發到楊梅 ETC 旅行時間 1/3 7:10 d1 到 d2 旅行時間 1/3 7:10 d2 到 d3 旅行時間 1/3 7:10 d3 到 d4 旅行時間 1/3 7:10 d4 到 d5 旅行時間 依照TVC 模式構建流程圖所示,其詳細流程運作主要可分為五個步驟, 以下將詳細作說明: Step1.交通資料蒐集 本模式利用行駛在國道一號高速公路上楊梅到泰山之間的探針車所 蒐集的交通資料,所推估的兩兩固定點之間的旅行時間資料當作資料來源, 以此作為迴歸模式的自變數Xi,ETC 旅行時間資料當作迴歸模式的應變數 Y,因此需要蒐集固定點之間旅行時間資料與 ETC 旅行時間資料。 Step2. 將歷史資料作分群 本模式依照不同的星期別及尖峰、離峰時間,將資料作分群處理,其 中如果遇到特殊節日,須獨立出來考慮。而當歷史資料發現該時段有發生 交通事故或道路施工等特殊狀況,會造成車速減緩影響正常行車時間,必 須將受到影響的資料予以刪除,若不予以刪除,將造成迴歸模式預測時產 生誤差,誤認該時段為塞車情況,產生不正確的預測結果。 Step3. 校估迴歸模式參數值
本模式利用統計軟體 SPSS 進行迴歸模式分析,採用最小平方法校估 各分群的迴歸模式係數,並依照係數的顯著程度作調整,若有係數呈現不 顯著性,則予以刪除,再重新作回歸模式分析,直到所有係數都為顯著為 止。 Step4. 產生各個分群的時變係數模式 校估後的迴歸模式係數,代入迴歸式中建立完整迴歸式,並建立各個 分群的迴歸模式,提供旅行時間預測使用。 Step5. 輸出旅行時間預測值 將收到的同時段、兩兩偵測器間的旅行時間資料帶入該分群的迴歸模 式,可得到一旅行時間預測值,將此預測的旅行時間輸出,並將此旅行時 間存入資料庫中,提供給下一個時段的旅行時間預測模組使用。
4.4 預測精確度之衡量
本研究採用之預測精確度衡量準則,是以平均絕對誤差百分比(Mean Absolute Percentage Error, MAPE)為評估指標,來衡量預測值與實際值之差 異,其計算公式如式 4-13 所示: