國立台中教育大學教育測驗統計研究所理學碩士論文
指 導 教 授:郭伯臣 博士
以貝氏網路為基礎之適性測驗選題策
略演算法
研 究 生:曾筱倩 撰
中 華 民 國 九 十 七 年 六 月
摘 要
貝氏網路是一種機率推論模式,將其應用在知識概念的判斷上,不僅有預測 的能力,也可以針對不確定性的問題進行推論,根據貝氏網路此特性,本研究欲 建立一個以貝氏網路為基礎的適性測驗,希望可以透過貝氏網路的診斷達到預測 並診斷學生的子技能及錯誤類型的有無,以往已有相關的論文探討此方面研究, 但其使用的AO*演算法,在計算上需耗費大量的時間,故希望可以試著改良AO* 演算法。並探討不同適性選題策略對於預測與診斷學生的子技能與錯誤概念有無 的正確率之比較。 本研究之研究結論分述如下: 一、在探討不同選題策略所形成的適性測驗,對貝氏網路估計學生子技能與錯誤 概念之成效方面發現,以貝氏網路為基礎的選題策略其成效良好,其中AO* 及M-AO*的方法在正確率方面沒有太大的差異,但在運算速度上,以M-AO* 方法的速度較AO*方法來的快速。 二、比較固定不同施測題數下,預測學生之子技能及錯誤類型的正確率方面。以 95%的答對率為基準,發現AO*及M-AO*的方法省題效果最好,達到95%的 答對率也只需要做三題即可達到,省題比率達到73%。 關鍵詞:電腦化適性測驗、貝氏網路、AO*Abstract
Bayesian network is a probability inference model. It can predict and inference
the uncertainty problem when it apply to diagnosis the knowledge concepts. According
to the characteristic. This research will build an adaptive testing based on Bayesian
network. There are many research to confer about the problem, but it use AO*
algorithm. It cost a lot of time on counting. In this research trying to improve the
algorithm.
The result of this research are as follow:
1. When discussion the adaptive testing using different item selection strategy on
diagnosis the student’s outcome. The strategy based on adaptive testing is the best.
There is no different between AO* and M-AO* method. But when consider about
the counting efficiency M-AO* method is better then AO* method.
2. Under the accuracy is 95%. It indicates that the AO* and M-AO* method can
reduce most of items. It needs only three items, it’s reduce items ratio can be 73%.
目錄
摘 要 ... I ABSTRACT ... II 目錄 ... III 表目錄 ... IV 圖目錄 ...V 第一章 序論 ...1 第一節 研究動機 ...1 第二節 研究目的 ...2 第三節 名詞解釋 ...3 第二章 文獻探討 ...5 第一節 電腦適性測驗 ...5 第二節 知識結構 ...9 第三節 貝氏網路 ...11 第四節 基於貝氏網路的適性測驗選題策略 ...15 第五節 ABDUCTIVE推論 ...22 第三章 研究方法 ...34 第三章 研究方法 ...34 第一節 研究流程 ...34 第二節 問題解決 ...35 第三節 實驗設計 ...39 第四節 研究範圍與限制 ...42 第五節 研究工具 ...45 第六節 評估方法 ...45 第四章 研究結果 ...48 第一節 不同選題方法應用於適性測驗上之比較 ...48 第二節 選題數不同的適性選題分類正確率之比較 ...51 第五章 結論 ...53 參考文獻 ...54 中文部份 ...54 英文部分 ...56表目錄
表 2-1 試題 J 與試題 K 之機率四分割表 ...9 表 2-2 貝氏網路在教育上之應用 1 ...14 表 2-3 貝氏網路在教育上之應用 2 ...14 表 2-4 貝氏網路在教育上之應用 3 ...15 表 2-5 變數名稱代表意含對照表 ...23 表 3-1 分數概念相關能力指標之子技能 ...43 表 3-2 分數概念相關能力指標之錯誤類型 ...43 表 3-3 正確率計算方法...45 表 4-1 不同選題策略、題數之正確率摘要表 ...51圖目錄
圖 2-1 電腦適性施測流程圖...6 圖 2-2 貝氏網路非循環的有向圖...12 圖 2-3 策略的範例...16 圖 2-4 三題選兩題施測的策略示意圖...17 圖 2-5 策略 S 的分解圖...19 圖 2-6 醫學相關之貝氏網路圖...23 圖 2-7 利用修剪法之廣度優先搜尋之最佳優先演算法展開的狀態空間樹 ...28 圖 2-8 ABDUCTIVE INFERENCE 演算法流程...33 圖 3-1 研究流程圖...34 圖 3-2 AO*運用 ENTROPY 示意圖 ...35 圖 3-3 應用 MPE 改良 ENTROPY 示意圖 ...35 圖 3-4 以知識結構為基礎之適性測驗選題法示意圖...40 圖 3-5 貝氏網路圖...44 圖 3-6 交叉驗證法設計圖...46 圖 4-1 隨機選題法不同題數之正確率...48 圖 4-2 以知識結構為基礎之適性測驗選題法不同題數之正確率...48 圖 4-3 以貝氏網路為基礎結合亂度之適性測驗選題法不同題數之正確率 ...49 圖 4-4 運用 MPE 改良以貝氏網路為基礎之適性測驗選題法不同題數之正確率 ...49 圖 4-5 比較四種選題方法之正確率...49第一章 序論
第一節 研究動機
教學評量是在教學的活動中常使用的工具,評量的目的不僅是評定學生的成 就高低,更主要的目的是幫助學生在完成一定的學習範圍後,可以藉由評量的方 式,瞭解自己的不足之處,並針對不足之處作加強學習。新的評量改革潮流中, 許多專家學者皆強調一個完整的評量歷程應該包括安置性評量、形成性評量、診 斷性評量以及總結性的評量(余民寧,1997;李坤崇,1998;簡茂發,1999)。 但以往的紙筆測驗只提供了學生表現的整體分數,運用整體分數的排列可以了解 學生的等級和篩選的目的,卻無法讓教師、學生瞭解學生學習歷程中的盲點,讓 學生知道並修正其錯誤概念。而在這資訊爆炸的時代,資訊融入教學已經是衍然 而生的一個課題,想要藉由電腦與網際網路的特性,透過電腦適性診斷測驗來改 善以往的傳統測驗,讓學習者與教師可以更快的了解學生的學習成效。 貝氏網路(Bayesian network)近年來在人工智慧的應用上崛起,在許多領域 之中皆被廣泛的運用,像是醫學領域的疾病診斷、資訊科學的人工智慧、體育方 面的得分預測,都可以應用貝氏網路來達成。就其應用的特性而言,有著不確定 性的因素成分,以及所欲探討的多變項特性,與教育環境中學生的能力與錯誤類 型的診斷,有非常大的相似之處,故將貝氏網路應用在教育測驗上有其可行性。 許多心理計量的先進亦以此統計方法應用於教育評量(Mislevy, 1995, 1998; Almond, 2003),在國內有相當多的研究將貝氏網路應用於教育測驗上,像是能力 指標的診斷測驗(施淑娟,2006;黃雅鳳,2006)、電腦化適性測驗(李俊儀, 2005;林垣圻,2006)等,這些文獻均顯示貝氏網路應用在教育評量有許多優勢。 貝氏網路是一種機率推理模式,可將資料與專家的知識判斷結合,不僅有預 測的能力,也可以針對不確定性問題進行演算與推論,將變數間的關連性表現出 來。在教育測驗上的應用,則是推算出題目與題目內所潛藏的錯誤類型的關連性,進而分析出學生所具有的錯誤類型資訊。也就是說,最重要的是能將傳統人 工的學生錯誤類型判別的方式,轉變成利用電腦自動化診斷學生作答反應,且能 大量節省人工判斷的時間,以利於有更多地時間用於補救教學。 本研究使用林美君(2007)目標研究線上診斷測驗及補救教學系統研發的資 料,建立一個以「錯誤類型」和「技能」為診斷單位,將學童的實際作答反應樣 本分成訓練和測試樣本,訓練樣本用來訓練貝氏網路,而測試樣本則用來測試其 達到的正確率,透過貝氏網路預測並且診斷學童具有的錯誤概念和技能,找出最 佳分類決斷值,做較接近真實的分類及診斷,以此分類決斷值用在以貝氏網路為 基礎的電腦化適性測驗的分類判斷標準。 因為貝氏網路是一種機率推論模式,將其應用在知識概念的判斷上,不僅有 預測的能力,也可以針對不確定性的問題進行推論,根據貝氏網路此特性,本研 究欲建立一個以貝氏網路為基礎的適性測驗,希望可以透過貝氏網路的診斷達到 預測並診斷學生的子技能及錯誤類型的有無,以往已有相關的論文探討此方面研 究,但其使用的AO*演算法,在計算上需耗費大量的時間,故希望可以試著改良 AO*演算法。並探討不同適性選題策略對於預測與診斷學生的子技能與錯誤概念 有無的正確率之比較。
第二節 研究目的
基於上述研究動機,本研究欲探討以貝氏網路為基礎之適性測驗的預測精準 度,以及不同選題策略的精準度比較。基於上述研究動機,本研究之研究目的分 述如下: 一、探討不同選題策略所形成的適性測驗,對貝氏網路診斷學生子技能與錯誤概 念之正確率的變化。 二、比較固定不同施測題數下,預測學生之子技能及錯誤類型的正確率。第三節 名詞解釋
一、知識結構
本研究所稱之知識結構是由Bart & Krus(1973)所提出順序理論(ordering
theory, OT),利用OT分析學生的作答反應,瞭解學生知識的上下位關係,以往的
OT是用來探討教材以及教學法的好壞,但本研究中用此方法來作為學生的知識結 構,將學生的知識概念分為上下位關係,上位者稱之為上位試題,該試題其下位 者稱之為下位試題,並以此試題結構作為適性測驗選題標準,若學生答對上位試 題,則我們將其下位試題也視為是答對的狀況。 二、貝氏網路 貝氏網路是一種機率圖形模式,模式中各個變項代表是一個事件,用有向箭 頭連結各個變項,形成貝氏網路圖﹔在給定證據之後,利用貝氏定理的先驗機率 和聯合機率,推論後驗機率(posterior probability),用以了解事件發生的機率有 多大。貝氏網路也叫做貝氏信念網路(Bayesian belief networks)、因果關係網路 (casual networks)、機率網路(probabilistic networks)或者為知識地圖(knowledge
map),主要以有向的無迴路圖(directed acycle graph, DAG)為基礎,應用其變
數之間的因果關係與其相互影響的機率。完整的貝氏網路包含二個部分,分別是 節點(node)及連結(link)。在貝氏網路中,節點代表欲研究的變項;連結代表 的是變項之間的相互關係。連結的有無即代表其節點之間的關係是否為條件相依 或條件獨立的情形,其影響程度則是以條件機率來表徵;在本研究中節點代表了 試題、子技能、錯誤概念以及能力指標,連結用來表示各節點間的關係。 三、電腦化適性測驗 電腦化適性測驗是一種電腦化的測驗,電腦依受試者的作答反應從題庫中依
管制題目的規則,選出受試者要作答的下一題,因此,不同受試者的作答題目情 況不一樣,卻能達成一定範圍的診斷正確率,不會因作答題數少或作答題目的不 同,而診斷的正確率降低。 四、AO*演算法 AO*主要的評估函數是根據A*的設計方式,加上其運用搜尋法則在AND/OR 塗上,故將其重新命名為AO*,將其用在適性測驗選題上,其選題依據為,依試 題反應的狀況去計算截至目前為止的期望亂度值,再依據計算出的期望亂度 (expected entropy)決定下一步要使用那一試題施測。每次從施測過後,剩下的 試題中,找出期望亂度最小的試題,作為下一題施測題目,如此反覆直到達到測 驗終止標準為止。 五、MPE演算法
MPE(Most probable explanation)為貝氏網路中的一個推論架構,本研究嘗
試利用修改試題期望亂度的公式,結合MPE與Abductive inference的方式,利用 MPE可以找出單點最大機率值的方式,避免過度的搜尋,藉以改良傳統利用期望
亂度計算時,所需要耗費的大量時間,利用找出單點最大可能發生的機率值,將 其餘資訊視為均勻分配,也就是亂度值為最複雜的情況下,以此降低運算的複雜 度。
第二章 文獻探討
本研究目的為利用貝氏網路在知識概念的判斷上,不僅有預測的能力,也可 以針對不確定性的問題進行推論的特性,建立一個以貝氏網路為基礎的適性測 驗,希望可以透過貝氏網路的診斷達到預測並診斷學生的子技能及錯誤類型的有 無,並找出最適切的分類決斷值,以此決斷值作為以貝氏網路為基礎的電腦化適 性測驗之分類判斷標準。並探討不同適性測驗選題策略對於預測與診斷學生的子 技能與錯誤概念有無的正確率之比較。因此在本章的文獻探討當中,將針對適性 測驗、知識結構、貝氏網路、以貝氏網路為基礎之適性測驗以及Abductive 推論 等相關研究,進行探討與分析整理。第一節 電腦適性測驗
電腦化適性測驗是一種電腦化的線上測驗,電腦可以依據受試者的反應,去 挑選適合該受試者作答的下一題試題,因此不同的受試者會有不同的施測題目。 受試者雖然依據不同作答類型,會有作答題目以及其作答題數都會有所不同,但 在一定的試題管制規則中,卻仍可以達到一定規範的診斷正確率,不會因為該受 試者的施測題數少或者施測題數的不同,而造成其診斷的正確率降彽。 當測驗的難度能夠適合考生的能力程度時,這時測驗所測量到的考生能力最 為精確。但通常一份測驗卷試題難度,很難滿足或適合每位考生的能力水準,因 此要能做到試題難度隨考生能力不同(即個別差異)而調整的測驗方式,唯有採 行適性測驗(余民寧,1993)。然而,早期這種適合個別情況的測驗方式,在實 施上相當困難,近年來,隨著電腦科技的進步,測驗方式逐漸由紙筆測驗演變成 電腦測驗,因此,適性測驗的理念遂得以與電腦測驗融合,使得此種能提高測驗 效率及提供最精確能力測量的理念能夠更順利實施,這便發展成為近年來相當熱 門的電腦化適性測驗。因此,所謂電腦化適性測驗(computerized adaptive testing,據考生對已施測試題的反應而對考生該項能力或特質作一評估,再基於此一能力 估計值有效選擇下一個題目,如此反覆進行選題、施測與能力估計之循環過程, 至達到穩定的能力或特質估計為止。因此,此種測驗可說是結合了測驗理論、適 性測驗、及電腦的智慧型施測方式,其中涉及題庫、起始點、測驗理論、試題選 擇方式、計分方式與中止標準等六大要素,每一種要素都有幾種可能的選擇。如 圖2-1所示。 圖 2-1 電腦適性施測流程圖
一般的電腦化適性測驗可以分為以試題反應理論(Item Response Theory, IRT) 為主的,以及利用知識或試題結構為主的兩種(郭伯臣,2004),以下將分別介 紹。 一、以試題反應理論為主的電腦適性測驗 以試題反應理論為主的電腦適性測驗,是應用試題反應理論所發展出來之一 種新的實施測驗方式。要實施適性測驗,也唯有在電腦誕生發明後,才有可能施 行。電腦科技的發達,日新月異,它的超大容量可以貯存測驗訊息(如:測驗試 題及其特徵指標)、編製、施測、和記錄測驗分數,因此使得推行適性測驗變得 愈來愈可行(Bunderson, Inouye & Olsen, 1989; Wainer, 1990)。
以試題反應理論為主的電腦化適性測驗(computerized adaptive testing, CAT) 裡,呈現給考生的試題順序,是依據考生在前一個試題上的表現好壞來作決定 初值設定 適性選題 作答反應 估計 Profile 終止條件 結束測驗 開始測驗 成立 不成立
的。在開始進行電腦化適性測驗之時,先由電腦終端機隨機呈現一組測驗試題(也 許是兩題或三題),在考生作出反應之後,電腦便根據這些反應資料,估計出考
生的初步能力估計值(initial ability estimate);然後,電腦會根據這些初步能力估
計值,從現有的題庫(item bank)中挑選出最能對能力水準的估計發揮最大貢獻 力量的試題,再呈現這些試題給考生作答,根據考生先前的表現好壞,呈現下一 個要給考生作答的試題。 換句話說,根據考生先前的表現情形,來決定下一階段將呈現給受試者作答 的試題,而且這樣的試題是能對考生能力的估計精確性提供最大訊息量,循此原 則,直到滿足一個預先設定的信賴水準或終止標準時,測驗即結束。透過這樣的 機制,使得測驗的長度可以縮短,也不會犧牲測量精確性。換言之,對於高能力 的受試者無需提供較為容易的試題作答,對於低能力的受試者,也不會有試題難 度太高而造成心理上的打擊,因為這些試題是相對於他們的能力水準來選取的。 因此就電腦化適性測驗來說,不僅可以做到精確估計考生能力來進行「因材施 測」,更可節省許多施測時間和成本,優點相當明顯。 此種施測方式是採機動的選題方式去配合受測者的表現,換言之,需要從題 庫中根據試題的統計特質,即試題參數(item parameters)去選題,且受測者每 完成一個反應,能力水準要再被估計,涉及的計算過程頗為複雜,因此需藉助電 腦方能實施,所以此種測驗方式又稱為電腦化適性測驗。基於IRT理論的電腦適 性測驗,將根據受試者的作答情形,依照能力值的不同,給定不同的試題。換言 之,一般以試題反應理論為基礎的電腦化適性測驗,施測結果為一能力值或量尺 分數。由於學生的錯誤類型並不具順序性或線性排列,即並非所有學生皆會先出 現錯誤類型1而後才出現錯誤類型2,因此無法單獨將錯誤類型與某一分數進行對 應,只能根據受試者的作答情形,依照能力值的不同,給定不同試題。所以IRT 較適合用在成就測驗,如大學學力測驗。 二、以知識或試題結構為主的電腦適性測驗
以知識結構為基礎之適性化診斷測驗系統,首先需建立知識結構,並依據此 知識結構作為適性測驗的選題策略,能提供學生一個適性測驗立即的成績回饋, 並於測驗後給予學生個別化、量身訂作的補救教學,讓學生知識的建構能有最好 的效果。黃珮璇、王暄博、郭伯臣、劉湘川(2006)的研究證實了以知識結構為 主的國小數學科電腦化適性診斷測驗具強韌性(robustness),即電腦化適性診斷 測驗系統之成效在廣泛應用於各單元或其它相關主題時,依然存有良好的表現。 曾彥鈞、劉育隆、郭伯臣、楊智為(2006)實作開發出以知識結構為基礎的適性 化診斷測驗系統,目前系統實際上已有94、95年康軒、南一版數學各單元教材上 線,並由多位研究生進行實際使用、作為施測平台。許多研究(白曉珊、劉育隆、 郭伯臣、施慶麟,2006;林立敏、白曉珊、郭伯臣、劉育隆,2006;莊惠萍、劉 育隆、郭伯臣、曾彥鈞,2006;趙琬津,2006;盧炎成,2006)指出,以知識結 構為基礎之適性化診斷測驗系統根據學生知識結構設計適性施測流程,可依不同 受試者的作答情形而給予適當的試題,藉此節省大量的試題並可對學生的剖面圖 得到精確的估計,確實可以有效節省施測題數,並有適性化的功能,且提供個別 學習診斷報告書,讓學生可以立即知道自己的錯誤觀念,也有利教師進行補救教 學。
第二節 知識結構
郭伯臣、謝友振、張峻豪、蔡坤穎(2005)指出使用良好的試題結構,可有
效降低施測題數,該研究中比較了三種估計試題結構方法,「順序理論」(ordering
theory, OT)、「試題關聯結構分析法」(item relationship structure analysis, IRS)及 Diagnosys,研究結果顯示,使用OT結構之適性測驗選題策略,所需訓練樣本較
少與可節省較多施測題數,優於IRS與Diagnosys,故本研究採用OT這種順序理論 技術來估計試題結構,並用於適性測驗流程之建立。茲將此理論敘述於下。
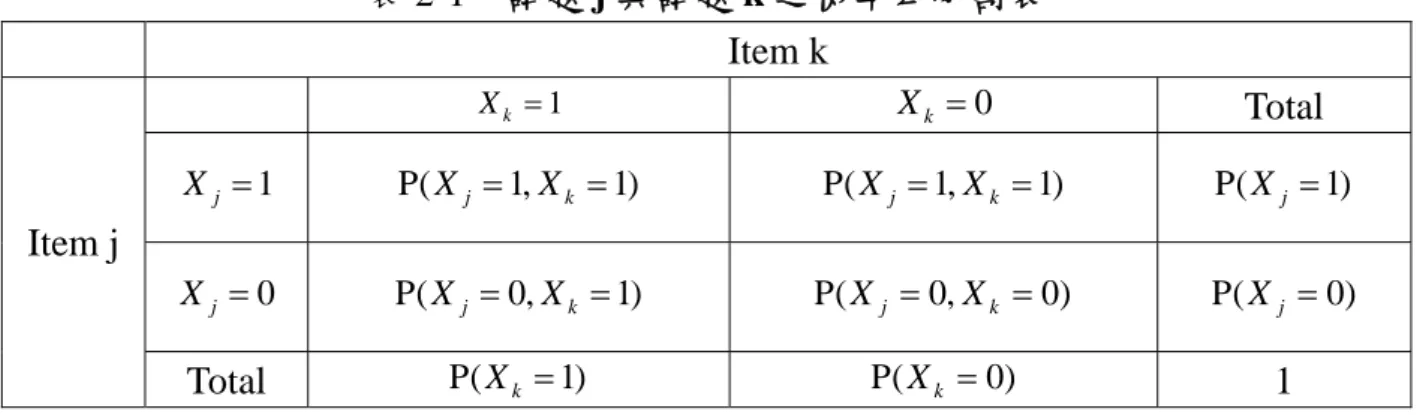
令X =(X1,X2, ,Xn)表示一個向量包含n個二元試題成績變數,每一個受試
者者作答n題得到一個0與1的向量x=(x1,x2, ,xn)之後,試題j跟k的聯合邊界機 率(the joint and marginal probabilities)可以如表2-1表示。
表 2-1 試題 j 與試題 k 之機率四分割表 Item k 1 = k X Xk =0 Total 1 = j X P(Xj =1,Xk =1) P(Xj =1,Xk =1) P(Xj =1) 0 = j X P(Xj =0,Xk =1) P(Xj =0,Xk =0) P(Xj =0) Item j Total P(Xk =1) P(Xk =0) 1 順序理論OT中若設定ε*jk =P(Xj =0,Xk =1)<ε,且0.02≤ε ≤0.04 (Airasian & Bart, 1973; Bart & Krus, 1973)。故試題 j 能夠向試題 k 連結。而兩者之間的 關係可以被紀錄成Xj → Xk,這也表示X 是k X 的上位概念,即j X 是達成j X 不k
可或缺的條件。 一、專家知識結構
專家知識結構由學者專家建立,在知識結構中,上層的結構是屬於比較困難 的部份,稱之為上位概念,下層的結構則為各概念的下位概念(黃碧雲,2005)。 在本研究中,編製診斷測驗試題所依據的專家知識結構,是由多位國小教師及專 家,依據學理及教學經驗,分析相關小數加減教材內容及教學目標,找出單元內 重要的學習概念,再根據學生的學習歷程、概念發展順序及概念間的相關性,繪 製出本單元的專家知識結構,再依照知識結構來出題。 二、學生知識結構 學生試題結構是由學生紙筆測驗作答情形估計而得,是依照學生作答反應情 況,運用試題結構演算法所得出的概念發展順序及概念間上、下位關係的結構關 係,在許多文獻中顯示,學生結構與專家結構不一定相同,且學生知識結構的建 立需由專家手動判斷,過程費時亦費力。 三、試題結構理論
有二種經常用來定義試題間順序性的方法:一種為 Airasian & Bart 的「順序 理論」,另一種則為 Takaya 的「試題關聯結構法」,早期這些方法常用於比較不 同教學方法或不同版本教材,是否造成學生知識結構不同,採用紙筆測驗的結果 來進行學生知識結構之估計。 在郭伯臣、謝友振、張峻豪、蔡坤穎(2005)的研究中指出,使用良好的試 題結構,可有效降低施測題數,該研究中比較了三種估計試題結構方法,「順序 理論」、「試題關聯結構分析法」及 Diagnosys,其研究結果顯示,使用順序理論 (OT)結構的適性測驗選題策略,所需訓練樣本較少,可節省較多施測題數,即 依據該理論所建構出的試題結構較完整,較接近學生真實的試題結構,所以成效 優於 IRS 與 Diagnosys,故本研究採用 OT 順序理論技術來估計試題結構,並 用於適性測驗流程之建立。
第三節 貝氏網路
一、貝氏網路 由於科學方法要求嚴密性,為避免引用極端資料可能會扭曲研究結果,因 此,古典推論模式並不允許將先前知識引入計算中。然而在許多情況下,善用先 前知識並結合可觀察的資訊是有助於推論的,此種統計推論模式被稱為貝氏推論 統計。以貝氏推論統計為基礎並透過圖形理論(graphical theory)表達變項間關 係或是解決計算複雜度(calculating complexity)問題的統計模型稱為貝氏網路 (bayesian network)(Richard & Neapolitan , 2003)。貝氏網路可叫做因果關係網路(causal network)或機率網路(probabilistic
network)。貝氏網路是廣泛應用於人工智慧、決策系統、電腦科學以及工程界的
診斷工具之一,對於不確定性的管理與評估有很好的表現(Spiegelhalter, Dawid,
Lauritzen & Cowell,.1993; Jensen, 2001)。
貝氏網路是以條件機率(conditional probability)為基礎,所建構出來的具方 向性的非循環有向圖(directed acyclic graph, DAG)。一個貝氏網路包含二部份, 分別為節點與節點之間的連線,節點表示變項,連線則表示變項間的因果關係, 連線的有無代表節點間是否有因果關係,其影響程度藉由條件機率來表達。 二、貝氏定理 貝氏定理(bayesian rule)是貝氏網路的基礎,就貝氏定理簡介如下: P(B) A)P(A) | P(B B) | P(A = (2.1) 1.條件機率 P(B|A)表示在 A 的條件之下,B 發生的機率。 2.機率 P(A)和機率 P(B)則表示 A 和 B 各自發生的機率。 3.P(B|A),P(B)和 P(A)在研究中是先用訓練的資料所求得的。 由以上貝氏定理可以看出,使用貝氏方法最大的優點為貝氏結合事前機率 (經驗值)與樣本機率(可經由訓練樣本得知),且有效的利用樣本資訊,引入經
驗值來得到理想的統計數據。傳統的統計方法只由樣本數統計,比較起來貝氏方 法可以得到更多資訊,況且貝氏方法利用到以前的經驗(即事前機率),因此在 分析時不需太多樣本數即可得到不錯的結果(黃雅鳳,2006)。
三、貝氏網路圖形
貝氏網路圖形是一個以條件機率(conditional probability)為基礎所建構出來 的具方向性的非循環有向圖(directed acyclic graph, DAG),如圖 2-2 所示。圖中
的每一個節點(node)表示一個事件(event),節點間的連線(link)則表示事件 之間的因果關係,而連線的有無及其影響程度,依其強弱則藉由條件機率來表 達;該網路中之節點表示隨機變數,而連結線用來表示兩個變數間的關聯或因果 關係,所以此有向圖是這些變數之聯合機率分佈的分解表示法(呂靜芳,1999)。 Pearl(1988)將貝氏網路中,變數之間的影響用因果關係來表示,當變數 A 確定有影響變數 B 的因果關係時,從 A 到 B 將產生一個相依的連結邊。此時, 節點 A 稱為節點 B 的父節點,而節點 B 稱為節點 A 的子節點。 圖 2-2 貝氏網路非循環的有向圖 在本研究中,以節點代表能力指標、子技能、錯誤類型與試題,以有向邊連 結成貝氏網路結構,節點之間的連結,視有向邊的有無,來代表節點之間的關係 是否為條件相依或條件獨立的情形;節點之間有連結表示條件相依,具有因果關 係,節點間沒有連結就被稱為條件獨立。本研究將學生紙筆測驗的資料,利用貝 節點( node ) B A C (link) 條件機率 節點( node ) 節點( node )
式定理運算程式進行資料分析,結合透過領域專業人士之主觀認知所建立的貝氏 網路,以圖形結構建製的貝氏網路,可以為學生的評量資訊建立模型,提供教師 圖形化的觀察,並由系統分析推估出學生具有的錯誤類型訊息,研究結果亦可為 後續的補救教學的依據。 四、貝氏網路在教育測驗上之相關應用 為了探討如何將貝氏網路應用於實際教育評量中,近年來已累積了一些相關 的研究成果,其中包括理念的闡述(Mislevy, 1994);學科領域應用(Mislevy, 1995);建立以機率推理為基礎的智慧家教系統(Mislevy & Gitomer, 1996);以貝 氏網路建立評量設計的概念架構,再利用 MCMC 技術估計實徵資料所需的條件 機率(Mislevy, Almond, Yan & Steinberg, 1999);以及如何建立以貝氏網路的圖形 模式為基礎的電腦適性測驗(Almond & Mislevy, 1999)。
本研究在將貝氏網路應用於實際教育評量中,也有相當多的研究結果,概括 可分列為三種類型:1.診斷錯誤概念。2.理論與技術上的應用。3.將貝氏網路應用 於適性化測驗。 1.診斷錯誤概念 貝氏網路在教育測驗上最基本且主要的應用是診斷錯誤概念的研究,依研究 範圍有區分為以教材單元為主的以及能力指標為主,另一個在教學上的應用是在 診斷錯誤概念之後,可在加上相關的補救教學,其相關文獻整理如表 2-2。
表 2-2 貝氏網路在教育上之應用 1 研究範圍 研究者 研究內容摘要 教材單元 施淑娟、許雅菱、 李俊儀、郭伯臣、 劉湘川(2004) 以國小四年級「小數加減」單元為研究 範圍,建立貝氏網路來進行診斷測驗 郭伯臣、黃雅鳳、 謝典佑、劉湘川 (2007) 以六年級數學領域之「分數與小數」相 關指標為例編製以貝氏網路為基礎之能 力指標測驗。 能力指標 汪端正、蘇文君、 郭伯臣、楊智為 (2006) 以數學領域「數與量」能力指標為研究 範圍,探討技能層之間的上下位關係, 應用四層之貝氏網路進行診斷測驗。 補救教學 黃雅鳳(2006) 以數學領域「分數小數」相關指標建立 貝氏網路,並製作補救教學動畫,以利 在診斷測驗後進行有效的補救教學。 2.理論與技術上的應用 關於貝氏網路的理論與技術上的應用部分,包括貝氏網路的設計、多重貝氏 網路的應用及結合資料探勘的技術等,其相關研究整理如表 2-3。 表 2-3 貝氏網路在教育上之應用 2 研究範圍 研究者 研究內容摘要 謝典佑、許曜瀚、 楊智為、許天維 (2007)。 探討結合結構理論與貝氏網路之學生 概念診斷模型於診斷學生概念及錯誤 類型上的正確率。 許雅菱(2005) 探討以證據中心為基礎的評量設計,以 貝氏網路為基礎,建構以概念性的評量 架構為主的評量傳遞模式。 在教育測驗 分析上之綜 合應用 郭伯臣、李俊儀、 許雅菱、林文質、 (2005) 建立符合證據為中心的數學評量設計 的貝氏網路,以教材單元為例,進行研 究探討。
3.將貝氏網路應用於適性化測驗 還有部分研究是將貝氏網路應用於適性化測驗上,包含適性化測驗的可行 性、適性測驗演算法及電腦化適性測驗系統等。其相關的研究整理如表 2-4。 表 2-4 貝氏網路在教育上之應用 3 研究範圍 研究者 研究內容摘要 謝典佑、曾筱倩、 郭伯臣、許天維 (2007) 結合知識本體論與貝氏網路之電腦適性 診斷,藉以診斷出學生的錯誤概念以及 所擁有的子技能。 楊智為、劉育隆、 楊晉民、曾彥鈞 (2006) 利用試題順序理論進行電腦化適性測驗 後,使用貝氏網路作為診斷工具。能節 省施測題數並保有一定的正確率。 適性化測 驗 李俊儀(2005) 以國小數學診斷測驗為例,探討以貝氏 網路為基礎的電腦適性測驗選題策略。 由這些文獻結果可知,利用貝氏網路分析學生所具有的錯誤類型資訊,除了 大量節省人工判斷的時間,還能提供有效的診斷訊息。因此,貝氏網路的機率推 理模型,在教育測驗上是一個很有效的診斷工具
第四節 基於貝氏網路的適性測驗選題策略
基於貝氏網路的適性測驗選題策略目前僅有少數的研究涉及此一領域, Almond & Mislevy(1999)先以 Graph Models 的方式來解釋 IRT 的 CAT,然後再以 Multidimensional IRT (MIRT)的觀點來解釋 Bayesian Networks 在教育測驗 及適性測驗上的應用。Almond & Mislevy 他們的基本觀點是將複雜貝式網路作為 CAT 的用途,分解成學生模式和較小的證據模式集合。
一、用機率模型建立策略 策略(strategy)表示為了達成所要的目標,使用者應該執行哪些步驟。例如: 步驟(step):可能是使用者執行一個動作,使用者做了一個可以看到的行為,或 使用者回答了一個問題。因為步驟是不確定,每個步驟必須依前一步所有可能組 合的結果,描述使用者下一步應該做的。因此,每個策略能用方向樹(directed tree) 表示。樹的節點有兩種型態:一種是可能性節點(chance node),另一種是終端 節點(terminal node),每個可能性節點對應著策略的一個步驟。終端節點是樹的 葉,策略的結束,一個過程(session)對應樹(tree)上的一條路徑(path),即 一連串的步驟,從樹(tree)的根開始,在終端節點結束。在圖 2-3 表示兩個問題 組成的適性測驗。方形表示可能性節點,橢圓形表示終端節點,每個可能性節點 (chance node)標示著對應步驟,每一個邊的出現來自可能性節點(chance node),用對應節點的輸出標示。策略用樹表示:假如對第一個問題X 的回答是2 對的,則第二個問題就是X ,否則第二個問題選3 X1。 圖 2-3 策略的範例
Note. From Vomlel, J. (2004). Building Adaptive Tests using Bayesian networks, Kybernetika, Volume 40, Number 3, 2004, 333 - 348.
所有可能策略的空間(space)能用一個 AND/OR 圖表示,AND 節點對應可 能性節點(chance node),OR 節點對應判斷節點(decision nodes)。看圖 2-4,兩
X1 X1=1,X2=1 X3 X2 X1=答對 X1=答錯 X1=1,X2=0 X1=0,X3=1 X1=0,X3=1 X2=答對 X2=答錯 X3=答對 X3=答錯
個問題組成適性測驗的所有可能的測驗策略,當全部可能問題 X 的試題庫有三個
問題,其中一個策略用高亮度標示,它是從X2開始,第二問題根據X2的答案選
擇,不是選問題X3就是X1。
圖 2-4 三題選兩題施測的策略示意圖
Note. From Vomlel, J. (2004). Building Adaptive Tests using Bayesian networks, Kybernetika, Volume 40, Number 3, 2004, 333 - 348.
設 S 表示對一個給予的問題,所有可接受策略的集合,L(s)表示一個策略s∈S 全部末端節點的集合。評估函數定義f :∪s∈SL(s) R ,它的目標是在這過程 (session)結束時,將這函數最小化。在策略 s 提出的步驟,其結果是未知的, 只有在終端節點 ∈ 機率L P(e ),能從貝氏網路表示的領域模型計算出來。每一 個策略s∈S,評估函數(evaluation function)的期望值定義為 X1 X3 X2 X2 X3 X2 X1 X3 X1 X3 X3 X1 X2 X1 X2 X1=0,X2=0 X1=0,X3=0 X1=1,X2=0 X1=1,X3=0 X2=0,X3=0 X2=0,X3=1 X1=0,X2=1 X1=1,X2=1 X2=1,X3=0 X2=1,X3=0 X1=0,X3=1 X1=1,X3=1
) (e ) (e (s) (s) L f P Ef =
∑
⋅ ∈ (2.2) 要尋找一個策略s*∈S,從全部s∈S,將Ef (s)的值最小化。簡而言之,即是 要找尋出一個以貝氏網路為基礎的最佳選題決策樹,以下將探討一些文獻中,建 立最佳選題決策樹的方法。 二、以貝氏網路為基礎的適性測驗選題策略 適性測驗用來診斷個人的技能,適性測驗使用貝氏網路,對一個受測的學生 和給予的問題模式化,自動依循個別受測者的程度去測驗,稱為適性測驗,典型 地適性測驗,在預定題數的問題被回答完之後,或者受測學生的相關資訊已達到 所要目標,適性測驗就結束測驗。假設Y ={Y …1, ,Yk}為學生模式中要測量機之技 能、能力或迷思概念,y=(y1,…,yk)為 Y 的一種狀態;X={X1,…,Xm}為題庫 中之試題,P(Y) = P(Y1,…,Yk)為所要估計之學生模式的聯合機率密度函數,而在 本研究中以貝氏網路來加以表徵,並藉以減低運算量。Vomlel(2004)提出以 Shannon 亂度(entropy)觀點來作為適性測驗的選題準則,定義 S 表全部可能測 驗策略的集合。每個主考人都希望在測驗結束時,能測出有關學生的資訊最多, 要讓這夢想成真的方法是在測驗結束時,機率分布最小化P(Y1,...Yk)的 Shannon entropy。P(Y1,...Yk)的亂度定義如下:∑
= = ⋅ = = − = k y y k k k k y P Y y Y y Y y Y P Y P H ,..., 1 1 1 1 1 ,..., ) log ( ,..., ) ( )) ( ( (2.3) ) (Y P 的亂度期望值為∑
∈ ⋅ = ) ( 1, , | )) ( ( ) ( ) ( s L l l k l H s P e H P Y Y e E … (2.4) l e 為策略 s 最終節點之一,L(s)為策略 s 所有最終節點所形成之集合。在求期望亂度最小化的過程中,會須要耗費相當大量的時間去計算推論,因 而衍生了策略分解、動態歸化法以及 Admissible heuristics 的方法來加快推論的過 程以及運算速度,下列針對策略分解、動態規劃法以及 Admissible heuristics 分述 如下: 1. 策略分解(Strategy decomposition) 一個策略 s 的分解,它將用來描述搜尋演算法,基於動態規劃法(dynamic programming)和定義一個可接受的嘗試錯誤函數(admissible heuristic function), 它適用在搜尋最佳策略的過程。 設s'代表一個策略,是可接受策略(admissible strategy)s 的子策略和策略 s 有相同的根ϑ,假如 s'≠ ,我們稱 's是一個未完成策略(incomplete stategy),s 假如 v 是策略 s 的一個節點,用 →v s 表示 s 的子策略,s 當它的根,L(s→v)⊂ L(s), 接下來做策略s的分解。看圖 2-5 圖 2-5 策略 S 的分解圖
Note. From Vomlel, J. (2004). Building Adaptive Tests using Bayesian networks, Kybernetika, Volume 40, Number 3, 2004, 333 - 348.
節點 r 是來自策略s'葉的集合L(s'),我們得到一組策略{s→r,r∈L(s')}每個策 略 →r s 來自L(s')一個節點作為根,注意
∪
r∈L(s')L(s→r) =L(s)。 1 r r2 r3 ϑ ) (s→r1 L L(s→r2) L(s→rq) ) ' L(s定義策略 s 的葉其條件期望值 )) e | ( ( ) (e H P Y EH = (2.5) 在 s 上證據e ,連結到非葉(non-leaf)節點 n 的子節點 ch(n)集合,我們定n
義遞迴條件期望亂度(conditional expected entropy recursively) ) (e ) e | (e ) e | (s ) ( m n ch m n m n H P H E =
∑
⋅ ∈ (2.6) 注意,EH(s)≡EH(φ),用EH* (en),表示策略 * s 在給予證據e 下最佳條件期n 望亂度,利用下列的公式,使用策略 s 的分割,去計算 s 的期望亂度∑
∈ ⋅ = ) (s' L ) (e ) (e (s) r r H r H P E E (2.7)2. 動態規劃法(dynamic programming approach)
有了上述的分解,我們可以基於動態規劃法,容易地建構搜尋演算法。這演 算法第一次評估所有可能策略的全部葉 )) e | ,..., ( ( ) (e 1 k H H P Y Y E* = (2.8) 然後向上進行,所以在每個可能性(chance node)(AND)節點 n,它用 2.9 式計算 ) (e ) e | (e ) (e ) ( m H n ch m n m n H P E E* =
∑
⋅ * ∈ (2.9) 並且,在每個判斷(decision)(OR)節點 n,它選擇最小E 的子節點H ) (e min ) (e ) (n H m ch m n H E E* * ∈ = (2.10) 在根節點結束時,EH* (φ)是從所有可能策略,期望亂度的最小值。假如這判斷(decision)節點的最好子節點(the best children)被儲存,最佳化策略s 能被* 容易地向上追蹤。
試著避免過度搜尋,透過有可接受的嘗試錯誤函數(admissible heuristic function)推動,執行從上到下的嘗試錯誤式搜尋(heuristic search)。要提出此方 法,需要兩個輔助定理,敘述如下。 輔 助 定 理 1 : P(A,B) 是 機 率 分 布 , 定 義 在 多 維 離 散 變 數 A 和 B 和
∑
= = = =b aP A a B b B P( ) ( , ) 值 的 笛 卡 兒 乘 積 ( cartesian product ), 則 )) ( ( )) , ( (P A B H P B H ≥ 回 想∪
) ' ( Ls L(s ) L(s) r r ∈ → = , 因 此 ,∑
∑
∈L(s') r∈L(s→r)(e
)
=
1
rP
r 和 ) ' ( L ), (e s P r r ∈ r∈L s( ')是 s 全部葉(leaves)的機率分布。 如此,我們定義策略 s 全部葉,機率分布的亂度(entropy),用兩個等式表示∑
∑ ∑
∈ − ⋅ = ∈ ∈ → − ⋅ = (s) L L(s') L(s ) ) (e log ) (e ) (e log ) (e )) (e ( r r r r r P P P P P H (2.11) 定義策略 s'全部葉,機率分布的亂度。∑
∈ ⋅ − = ) (s' L ) (e log ) (e )) (e ( r r r r P P P H (2.12) 輔助定理 2:設 's 是未完成策略(imcomplete strategy),u 是策略r s→r的葉數, ) ' ( L s r∈ ,則∑
∈ ⋅ ≤ − ) (s' L log ) (e )) (e ( )) (e ( r r r r P u P H P H (2.13) 定理 1:假定一個未完成策略 s',在每個葉r∈L(s')有亂度H(P(Y |er))。則對任 何策略s∈S的期望亂度,策略 s'是它的子策略,下式成立∑
∈ − ⋅ = ) ' ( L ) log )) e | ( ( ( ) (e (s) s r r r r H P H P Y u E (2.14) 假定有可接受的策略 S 集合,是由有 n 個問題的測驗策略組成。假如每個問 題有兩個可能結果,則每次測驗策略對應一個有u=2n個葉的樹,搜尋之前用定制。 2 log )) ( ( ) (s H P Y n EH * ≥ − (2.15) 在適性測驗(adaptive testing)這提供亂度(entropy)很自然的解釋。假如有 關學生的知識用機率分布P(Y)的亂度(entropy)H(P(Y))表示,則我們至少需要 2 log )) ( (P Y H 個問題,每個問題有兩個答案;針對學生的知識狀態去產生精準資訊。 這是定理 1 的結果,EH(s')是有可接受的嘗試錯誤(admissible heuristics)。 我們可以在 * AO 演算法使用嘗試錯誤EH(s')。這種演算法的每一步驟,是從全部 所有可能展開的策略中選最小值的策略 's 。我們擴展一個非展開的節點,也就是 從選到的策略s'節點的子節點。設定EH(en)=EH(en)的值並且利用遞迴公式,我 們重新計算 n 的全部子孫節點的值。使用可接受的嘗試錯誤(admissible heuristics) 保證第一次展開的完全策略是最佳的策略。
第五節 Abductive 推論
當我們在貝氏網路裡進行更進一步的研究時,我們將會探討到演算法與推論 的部份,這邊要介紹的是Abductive推論(abductive Inference),除了逼近找到機 率值的演算法外,我們對於所找到每個變數證據的條件機率值及所獲得證據的 Most probable explanation(MPE)所感到興趣,而在找到確定MPE的這個過程,我們將其稱為Abductive Inference,以下將用例子對Abductive Inference和MPE做 解釋。
貝氏網路用於找出不確定性問題方面,有著相當大的助益,這裡用一個醫學 的例子用以解釋。所欲探討的問題是,一個病人能否藉由一些非直接的測試以及 問題的探究,去獲得他是否有此疾病的探討,在此例子裡將運用計算其個別條件 機率的方式去測試個別的病人是否患有此疾病。各變數的表示方法將羅列於下
表: 表 2-5 變數名稱代表意含對照表 變數 變數狀態 該變數影響的狀況 h1 病人有抽菸的歷史 H h2 病人沒有抽菸的歷史 b1 病人有支氣管炎 B b2 病人沒有支氣管炎 l1 病人有肺癌 L l2 病人沒有肺癌 f1 病人有感到疲勞 F f2 病人沒有感到疲勞 c1 病人胸部X光判讀為陽性 C c2 病人胸部X光判讀為陰性 圖 2-6 醫學相關之貝氏網路圖 以上表為例,我們在知道病人有抽菸歷史以及胸部X光檢查結果為陽性時, 我們將更進一步的去探討,這位病人是否患有肺癌(P(l1|h1,c1))和支氣管炎 (P(b1|h1,c1)),因此衍生出一個演算法可以去履行這類的推論。然而對於醫生們 H C F L B P(h1)=.2 P(l1|h1)=.003 P(l1|h2)=.00005 P(c1|l1)=.6 P(c2|l2)=.02 P(f1|b1,l1)=.75 P(f1|b1,l2)=.10 P(f1|b2,l1)=.5 P(f1|b2,l1)=.05 P(b1|h1)=.25 P(b2|h2)=.05
而言,與其說他們對於各個症狀引起病症的可能機率感興趣,不如說他們對於最 有可能影響(MPE)病症的原因更感興趣。因此,對於醫生而言,他們想知道的 是病人同時罹患肺炎和支氣管炎;罹患肺炎未罹患支氣管炎;未罹患肺癌但罹患 支氣管炎,以及皆未罹換肺炎及支氣管炎的最大可能機率為何。他們期望能透過 了解病人的症狀,進而可以知道病人最有可能罹患的疾病為何,而在尋找最大可 能解釋機率的這個過程,我們將其稱之為Abductive Inference,接下來我們將對其 在貝氏網路上做一些定義: 定義(G , P),其中G=(V , E)將其定義為一個貝氏網路,並且令M ⊆ ,V V D⊆ 且M ∩ D=φ,M是一個呈現的資料集,而D是一個說明的集合,令m是變 數M集合中的數值,則變數D的最大可能值則如下式所示 ) | (d m P (2.16) 我 們 將 其 稱 為 m 的 MPE , 而 這 個 尋 找 的 過 程 , 我 們 將 其 稱 為 Abductive Inference。對於Abductive Inference以及他的實際操作例子,對此將做更深入的探 討與舉例。 此演算法的問題在於其運算複雜度相當的大,舉個例子來說,當每個變數都 有兩種可能的情況,而共有k種可能變數,則將會有 k 2 種可能解釋的情形,Cooper
( 1990 ) 指 出 應 用 在 貝 氏 網 路 裡 的 Abductive Inference 是 一 個 NP-hard (non-deterministic polynomial)問題。並提出利用修剪法之廣度優先搜尋(best-first
search with branch-and-bound)來改善此方法。
一、關於Abductive Inference 的廣度優先搜尋法
修剪法之廣度優先搜尋,一般而言,此種方法通常被用來解決那些,問 題的選擇是取決於所欲探討問題的函數最大值或最小值,Neapolitan & Naimipour (1998)發表了一個非正式論文來介紹這個技術。我們這裡將用這個技術來建立 Abductive Inference的演算搜尋法。
針對我們欲探討的例子,將會用到一些專業的醫療術語來表達,首先我們先 假設那些可以解釋疾病所形成的集合將可組成K種可能的疾病,集合中的每一個 可原因,都可能用來表示或不表示各別病人的健康狀況,將其用數學的表示方法 如下所示: } ,..., , {D1 D2 Dk D= (2.17) 藉此可知道每個病人的各個病徵M都有其特定的值所形成的集合m可以作為 表示,目標是要找到最大機率可以解釋該疾病的病徵資料集,因此我們必須假設 每個可以解釋疾病的病徵都只有兩個值。令A=Di1,Di2,...,Dij是D的子資料集,舉 例來說,現在總共有四種疾病,但當我們只用D1, D3來表示該事件時,他同時也 等同於D1 =有、D2 =無、D3 =有、D4 =無,我們可以將此疾病的條件機率表示 為如下式所示 ) | , (D1 D3 m P (2.18) 欲解決找出該疾病的最大可能病徵集合上,最常使用的是建立一個狀態空間 樹,而狀態空間樹上的每個節點都會包含著D的子集合,樹的根節點包含一個空 集合,左邊的子節點包含{D ,右邊的子節點包含一個空集合;接著往下發展的1} 左邊的子節點包含了{D1,D2},右邊的子節點則包含了{D 。一般而言,對同一1} 水平節點i來說,左邊的節點會多包含了Di+1,且其右邊的節點未包含。在狀態空 間樹裡的每個葉節點表示了一個可能解,為了解決這些問題,我們將計算每個葉 節點的條件機率集合,並找出一個該節點的最大機率值。 當然在搜尋的目標上,我們希望可以避免找到狀態空間樹的太多節點,因而 衍生出一個用於建立的函數,對於每個節點,將他的子節點會造成的條件機率影 響,給予一個上界,當在計算節點時,需要計算的為該節點的條件機率值、以及
其子節點的上界可能機率值。利用上界當做一個規範有兩個目的,第一、對於上 界比最佳條件機率值還要小的節點,可以予以忽略不用展開;第二、可以確保下 一個要展開的節點是具有最大的上界值。用此種方法找到的節點都將會是最佳解 的狀態,這樣技術我們稱之為修剪法之廣度優先搜尋之最佳優先演算法。在以圖 示表示這項技術之前,我們必須先將其界線的函數做一些定義,以下便是對此函 數所做的一些定義: 定義若 A和 'A 為某個疾病的兩個子集,則 ) ( ) ' (A P A P ≤ (2.19) 且 ) ( ) ( ) |' ( m P A P m A P ≤ (2.20) 証明:利用貝氏定理予以證明 ) ( ) ( ) ( ) ( ) ' | ( ) ( ) ' ( ) ' | ( ) |' ( m P A P m P A P A m P m P A P A m P m A P ≤ ≤ = 因此根據上式定理,可以發現 ) ( ) ( m P A P 為其子節點的一個上界,在用圖示介紹之前, 先針對一些技巧說明,當發現在給定其子節點計算出的上界值沒有比最佳解來的 好時,則將此節點稱之為不可行節點(nonpromising),其餘的,我們稱之為可行 節點(promising)。 二、圖示Abductive Inference 在用圖2-7說明Abductive Inference演算法實際運行的狀況時,這邊將舉一個醫 療上的例子用以說明。在我們的可解釋函數集 D 裡面分別有四種疾病 4 3 2 1,D ,D ,D D ,及病徵的狀況集 M 與其集合內所表示的值 m ,這個範例是一個以
貝氏網路為一架構,其病徵與疾病之間存在著機率關係。 圖2-7是一個用修剪法之廣度優先搜尋之最佳優先演算法展開的狀態空間 樹,其中用不同顏色標示的為此狀態結構數所找出的最佳解,搜尋的過程將如下 所示,我們將用best來表示當前的最佳解,P(Best|m)將用來表示最佳解的條件機 率值,在這裡的目標就是要找出最佳Best節點其最大條件機率值,這裡一開始給 定 01 . ) (m = P 1.計算節點(0,0) (1)計算條件機率值 01 . ) | ( m = P φ (2)令 φ = Best 1 . ) | (Best m = P (3)計算其先驗機率值及最大彈性程度 9 . ) (φ = P 90 01 . 9 . ) ( ) ( = = = m P P bound φ 2. 計算節點(1,1) (1)計算條件機率值 4 . ) | (D1 m = P (2)因為.4當前最佳解P(Best|m)好,固令 } {D1 Best= 4 . ) | (Best m = P (3)計算其先驗機率值及最大彈性程度
009 . ) (D1 = P 9 . 01 . 009 . ) ( ) ( 1 = = = m P D P bound 圖 2-7 利用修剪法之廣度優先搜尋之最佳優先演算法展開的狀態空間樹 3. 計算節點(1,2) (1)其條件機率值與其父節點相同,為.1 (2)其先驗機率值及最大彈性程度也和其父節點相同為.9和90 P(D1, D4|m)=.65 bound=90 P(D |m)=.41 bound=0 P(D4|m)=.6 bound=0 P(φ|m)=.1 bound=0 P(D1,D2|m)=.1 bound=.3 P(D |m)=.4 1 bound=.9 P(D2|m)=.15 bound=.5 P(φ|m)=.1 bound=90 P(D1,D3|m)=.05 bound=.1 P(φ|m)=.1 bound=90 P(D |m)=.4 1 bound=.9 P(φ|m)=.1 bound=90 P(φ|m)=.1 bound=90 (0,0) (1,1) (1,2) (2,2) (2,1) (2,3) (2,4) (3,3) (3,1) (3,2) (3,4) (4,4) (4,3) (4,2) (4,1)
4. 定義可行性節點,展開具有最大彈性程度的節點 (1)此節點為(1,2),並接著計算其子節點 5. 計算節點(2,3) (1)計算條件機率值 15 . ) | (D2 m = P (2)計算其先驗機率值及最大彈性程度 005 . ) (D2 = P 5 . 01 . 005 . ) ( ) ( 2 = = = m P D P bound 6. 計算節點(2,4) (1)其條件機率值與其父節點相同,為.1 (2)其先驗機率值及最大彈性程度也和其父節點相同為.9和90 7. 定義可行性節點,展開具有最大彈性程度的節點 (1)此節點為(2,4),並接著計算其子節點 8. 計算節點(3,3) (1)計算條件機率值 1 . ) | (D3 m = P (2) 計算其先驗機率值及最大彈性程度 002 . ) (D3 = P 2 . 01 . 002 . ) ( ) ( 3 = = = m P D P bound (3)此為不可行節點,因為其最大彈性程度維.2小於最佳解P(Best|m)=.4 9. 計算節點(3,4) (1)其條件機率值與其父節點相同,為.1 (2)其先驗機率值及最大彈性程度也和其父節點相同為.9和90 10. 定義可行性節點,展開具有最大彈性程度的節點
(1)此節點為(3,4),並接著計算其子節點 11. 計算節點(4,3) (1)計算條件機率值 6 . ) | (D4 m = P (2)因為.6比當前最佳解P(Best|m)好,固令 } {D4 Best= 6 . ) | (Best m = P (3)令其最大彈性程度為0,因為此節點為狀態空間樹的葉節點 (4)此節點變成當前最佳解P(Best|m),因為節點(2,3)的值.5小於 6 . ) | (Best m = P 12. 計算節點(4,4) (1)其條件機率值與其父節點相同,為.1 (2)令其最大彈性程度為0,因為此節點為狀態空間樹的葉節點 13. 定義可行性節點,展開具有最大彈性程度的節點 (1)此節點為(1,1),並接著計算其子節點 14. 計算節點(2,1) (1)計算條件機率值 1 . ) | , (D1 D2 m = P (2) 計算其先驗機率值及最大彈性程度 003 . ) , (D1 D2 = P 3 . 01 . 003 . ) ( ) , ( 1 2 = = = m P D D P bound (3)此為不可行節點,因為其最大彈性程度維.3小於最佳解P(Best|m)=.6 15. 計算節點(2,2) (1)其條件機率值與其父節點相同,為.4
(2) 其先驗機率值及最大彈性程度也和其父節點相同為.009和.9 16. 定義可行性節點,展開具有最大彈性程度的節點 (1)此節點為(2,2),並接著計算其子節點 17. 計算節點(3,1) (1)計算條件機率值 05 . ) | , (D1 D3 m = P (2) 計算其先驗機率值及最大彈性程度 001 . ) , (D1 D3 = P 1 . 01 . 001 . ) ( ) , ( 1 3 = = = m P D D P bound (3)此為不可行節點,因為其最大彈性程度維.1小於最佳解P(Best|m)=.6 18. 計算節點(3,2) (1)其條件機率值與其父節點相同,為.4 (2) 其先驗機率值及最大彈性程度也和其父節點相同為.009和.9 19. 定義可行性節點,展開具有最大彈性程度的節點 (1)此節點為(3,2),並接著計算其子節點 20. 計算節點(4,1) (1)計算條件機率值 65 . ) | , (D1 D4 m = P (2)因為.65比當前最佳解P(Best|m)好,固令 } , {D1 D4 Best= 66 . ) | (Best m = P (3)令其最大彈性程度為0,因為此節點為狀態空間樹的葉節點 21. 計算節點(4,2) (1)其條件機率值與其父節點相同,為.4
(2)令其最大彈性程度為0,因為此節點為狀態空間樹的葉節點 22. 定義可行性節點,展開具有最大彈性程度的節點 (1)沒有可行性節點、需要展開的節點,固已完成狀態空間樹的展開 因此我們得到疾病的最大機率的集合為{D1,D4},且其條件機率值為 65 . ) | , (D1 D4 m = P 由上述例子可以得知,此搜尋法則可以減短搜尋的時間,如上述例子為說明, 我們用此搜尋法只需要展開15個節點,但是如果將所有可能節點展開,則會有23 個節點存在,故用此方法可以避免展開一些不需要的節點。 在將廣度優先搜尋法應用在Abductive Inference時,必須用到優先佇列 (priority queue),佇列的排序根據其先驗機率值遞增排序,排序在最前面的最容 易被踢除,位於最後面的當作最佳解的限制。其演算方法如下所示: 問題:定義一個所有可能解釋情形的定義域,其中我們假設 A是 ' A 的一個子 集合,則 ) ( ) ' (A P A P ≤ 輸入:正整數n,貝氏網路(G , P),其中G=(V , E),並且令M ⊆ ,V D⊆V 且M ∩ D=φ,M是一個呈現的資料集,而D是一個說明的集合,令m是變數M集 合中的數值。 輸出:一個可以解釋該問題的MPE最佳集合,Pbest是一個最佳的機率,再給 定M = 的情況下。 m
圖 2-8 Abductive Inference 演算法流程
Note. From Richard E. Neapolitan. (2003). Learning Bayesian Networks. Prentice Hall.
void Copper (int n,
Bayesian-network & (G , P) where G=(V , E) ordered-set-of-diseases D,
set-of-symptom M, set- of-symptom-values m,
set-of-indices & Best, float & Pbest) {
Priority-queue-of-node PQ; Node X,Y;
X.level=0; //set X to the root. X.A=φ; //Store empty set at root Best=φ;
Pbest=P(Best|m); X.bound=bound(X); Insert(PQ,X); While (empty(PQ)){
remove(PQ,X); //Remove node with best bound if (X.bound>Pbest){
Y.level=X.level+1; //Set Y to a child of X Y.A=X.A; //Set Y to the child that includes Put Y.level in Y.A; //the next disease
if (P(Y.A|m)>Pbest){ Best=Y.A; Pbest=P(Y.A|m); } Y.bound=bound(Y); if (Y.bound>Pbest) insert(PQ,Y);
Y.A=X.A; //Set Y to the child that does Y.bound=bound(Y); //not include the next disease if (Y,bound>Pbest)
Insert(PQ,Y); }
} }
int bound (node Y) {
if (Y.level==n) //A leaf is nonpromising return 0;
else
return (P(Y.A)/P(m)); }
第三章 研究方法
本研究旨在探討以貝氏網路為基礎的適性測驗,在診斷學生的認知情形,以 及學生在學習上可能會遇到的困難,我們試著比較不同施測題數下,學生的學習 錯誤類型的診斷與其正確率的變化,更加深的探討在不同適性選題策略底下,觀 察其正確率的變化。本研究嘗試利用貝氏統計方法來分析實徵資料來辨識其正確 率,並藉以探討不同影響變項對其正確率的影響,藉以驗證本研究所欲探討的問 題,本章節共分為六個部份:一、研究流程;二、問題解決;三、實驗設計;四、 研究範圍與限制;五、研究工具;六、評估方法。第一節 研究流程
本研究所涉及的主要有幾個步驟:文獻探討、資料蒐集與分析、程式化演算 法、撰寫程式、進行實驗、綜合評估、提出適當的演算法則、整理比較研究結果, 詳細的流程如圖 3-1: 圖 3-1 研究流程圖 確定研究主題 相關文獻探討 資料蒐集與分析 程式化演算法 利用所撰寫的程式對所蒐 集到的資料進行分析 整理並比較不同方法的辨 識率效果 結果與建議 論文撰寫完成 實驗設計第二節 問題解決
在運用以貝氏網路為基礎的適性測驗時,以往的研究用結合 Shannon 亂度 (entropy)的方式計算,但依照其演算法所衍生的公式計算,如數學式 2.14 所示, 其所需的運算量是相當龐大的,以一份 30 題的測驗為例,其所需要的運算量就 為 30 2 次,而每一個給定學生下一施測試題步驟都必須計算並展開一次,故其所 需要計算的決策空間數以及運算量,皆呈指數成長,本研究提出嘗試以 MPE 的 方法去改良 AO*方法需要展開所有可能集合的方式,將其運算量從 30 2 次降為 1 次,其概念圖示如下: 圖 3-2 AO*運用 entropy 示意圖 圖 3-3 應用 MPE 改良 entropy 示意圖 Y 為學生的能力,也就是本論文中所欲探討的錯誤類型、子技能、能力指標, 其中橫軸為 Y 的狀態值,也就是不同學生能力的有無所形成的組合,P 為機率值, P PM Y P PM PA Y其中 PM(probability maximum)為所有狀態的最大機率值,PA(probability average) 為扣除最大機率值的其餘節點,將其餘節點視為均勻分配,也就是亂度值最亂的 情況下的機率值。其數學公式推導過程如下所示: )) 1 ) ( # ) ( log( ) ( ))) ( log( ) ( ( )) 1 ) ( # ) ( 1 log( )) ( 1 ( ))) ( log( ) ( ( ) ) 1 ) ( # ) ( 1 log( 1 ) ( # ) ( 1 ))) ( log( ) ( ( ) )) ( log( ) ( )) ( log( ) ( ( )) ( log( ) ( ) ( } { } { − + − ≤ − − − + − ≤ − − − − + − ≤ + − = − =
∑
∑
∑
− − Y Y P Y P Y P Y P Y Y P Y P Y P Y P Y Y P Y Y P Y P Y P Y P Y P Y P Y P Y P Y P Y Entropy i i k k k k k k k i k k k k k i i i k k i i i 其中各符號表示如下 i :尚未施測的試題。 k :當前所做的試題。 i Y :該學生答 i 題的反應類型。 ) (Yi P :該學生答 i 題的反應類型機率值。 ) (Yk P :該學生答 k 題的反應類型最大機率值。 ) ( # Y :尚未施測的試題數 利用 MPE 的最大機率特性,改善原本 AO*的方法,將修改後的評估函數, 當作選題的依據,找出單點的最大機率值,其餘的皆把它當作最大亂度的情形加 以判斷。將其評估函數修改為如下式所示: )) 1 ) ( # ) ( log( ) ( ))) ( log( ) ( ( ) ( − + − ≤ Y Y P Y P Y P Y P Y Entropy k k i i 其中P(Yk)利用關於Abductive Inference 的廣度優先搜尋法當作其搜尋的過 程去計算出,Y為學生的子技能狀態,其所呈現的集合為{Y1,...,Yi},每個子技能都有兩種狀態,可以用0和1表示。搜尋的過程中,欲建立一個狀態空間樹,而狀 態空間樹上的每個節點都會包含著Y的子集合,樹的根節點包含一個空集合,左 邊的子節點包含{Y ,右邊的子節點包含一個空集合;接著往下發展的左邊的子1} 節點包含了{Y1,Y2},右邊的子節點則包含了{Y 。一般而言,對同一水平節點1} i 來說,左邊的節點會多包含了Yi+1,且其右邊的節點未包含。在狀態空間樹裡的 每個葉節點表示了一個可能解,為了解決這些問題,計算每個葉節點的條件機率 集合,並找出一個該節點的最大機率值。 當然在搜尋的目標上,我們希望可以避免找到狀態空間樹的太多節點,因而 衍生出一個用於建立的函數,對於每個節點,將他的子節點會造成的條件機率影 響,給予一個上界,當在計算節點時,需要計算的為該節點的條件機率值、以及 其子節點的上界可能機率值。利用上界當做一個規範有兩個目的,第一、對於上 界比最佳條件機率值還要小的節點,可以予以忽略不用展開;第二、可以確保下 一個要展開的節點是具有最大的上界值。用此種方法找到的節點都將會是最佳解 的狀態,這樣技術我們稱之為修剪法之廣度優先搜尋之最佳優先演算法。將其界 線的函數做一些定義,以下對此函數所做的一些定義: 其中定義若Y 和 'Y 為測驗目標的兩個欲解釋子集,如測驗中所欲探討的學生 子技能、錯誤類型以及能力指標的有無,則 ) ( ) ' (Y P Y P ≤ 且 ) ( ) ( ) |' ( m P Y P m Y P ≤ 証明:利用貝氏定理予以證明
) ( ) ( ) ( ) ( ) ' | ( ) ( ) ' ( ) ' | ( ) |' ( m P Y P m P Y P Y m P m P Y P Y m P m Y P ≤ ≤ = 因此根據上式定理,可以發現 ) ( ) ( m P Y P 為其子節點的一個上界,在用圖示介紹 之前,先針對一些技巧說明,當發現在給定其子節點計算出的上界值沒有比最佳 解來的好時,則將此節點稱之為不可行節點(nonpromising),其餘的,我們稱之 為可行節點(promising)。展開可行節點,避開不可行節點,依序搜尋直到找到 最佳解,用best來表示當前的最佳解,P(Best|m)將用來表示最佳解的條件機率 值,目標就是要找出最佳best節點其最大條件機率值,並記錄該節點狀態值,將 其作為評估函數中P(Yk)的值。
第三節 實驗設計
本研究欲探討以貝氏網路為基礎的適性測驗,並以此測驗來診斷學生的學習 認知歷程,以及學生的學習盲點所在,針對此目的,本研究嘗試藉由不同的實驗 設計來評估各演算法的實行成效,以及利用實徵資料計算其診斷正確率,並探討 不同變項對於正確率的影響。 一、嘗試比較不同演算法,隨機選題法、以知識結構為基礎之適性測驗選題法、 以貝氏網路為基礎結合亂度之適性測驗選題法、運用MPE改良以貝氏網路為 基礎之適性測驗選題法,試著比較這四種不同選題方法應用於適性選題策略 上,其診斷的正確率變化,藉以用來評估其成效。 二、藉著固定相對精準度的變項,嘗試比較不同相對精準度之診斷正確率和施測 題數的變化,藉此找出較合適的適性測驗停止標準。 本研究方法所採用的四種不同選題策略分別為,隨機選題法、以知識結構為 基礎之適性測驗選題法、以貝氏網路為基礎結合亂度之適性測驗選題法、運用 MPE改良以貝氏網路為基礎之適性測驗選題法,這四種方法的研究方法分述如 下: 一、隨機選題法 隨機選題法是在給定受試者第一題作答題時採隨機的方式選入,做過的題目 將不在重覆給予受試者作答的情況下,然後第二題施測時在隨機的給予下一題, 如次重複數次,直到達到適性測驗的停止標準為止,之後羅列資料時我們將用 random表示。二、以知識結構為基礎之適性測驗選題法 以知識結構為基礎之適性測驗選題法其選題依據為該能力指標的知識結構, 從其最上位試題開始作答,若答對上位試題,則我們會判下位試題也是答對,若 上位試題做錯,則在給予其下位試題做施測,依序直到全部試題做完或者所有試 題皆被判斷完畢為止,由於在本研究當中,想要比較不同施測題數的正確率變 化,故在以知識結構為基礎之適性測驗選題法上,有稍做改變,以圖3-4示並附加 說明來表示之。之後羅列資料時我們將用OT表示以知識結構為基礎之適性測驗。 圖 3-4 以知識結構為基礎之適性測驗選題法示意圖 以知識結構為基礎之適性測驗選題法,若學生答對上位試題,則我們會判斷 他下位試題也是答對的,如上圖所示,學生答對第一題,那我們則會判斷他第二 到第八題也都是答對的,但由於我們需要比較不同答題數情形下的正確率變化, 故我們將OT原有的策略稍做改變,當學生答對第一題時,我們仍然判斷他第二到 第八題是答對的,以此作為學生作答一題的反應類型矩陣,但是當判斷作答題數 為兩題時,會將第二題給學生作答,並依據其作答情形更新其反應矩陣,並加以 推斷,如此重覆得到學生作答所有題目的反應類型,以便與其他演算法做比較。 1 2 3 4 5 6 7 8