國 立 臺 中 教 育 大 學 教 育 測 驗 統 計 研 究 所
國民小學教師在職進修教學碩士學位班碩士論文
指導教授:郭伯臣 博士
廖晨惠 博士
兒童文本語詞重複指標
分析系統建置與應用
研究生:黃勇媜 撰
中
華
民
國
一
○
二
年
六
月
謝辭
研究的日子終於告一段落了。 感謝郭伯臣教授悉心的教導使我得以探求兒童文本語詞重複指標領域的深 奥;感謝廖晨惠教授不時的討論並指點我正確的方向,解惑並審視進度,使論文 能按進度往前推展;感謝楊裕貿教授在中文指標定義及試題編製上提供強而有力 的專業見解,讓研究的內容得以充實。 感謝口試委員王瓊珠教授,在百忙中撥空評閱論文,不吝指出研究上的不足, 提供寶貴意見,更加完善。感謝鎧誌學長不厭其煩的指導我撰寫程式,並全日機 動的協助,才能成就 Coh-Metrix 的基本研究。還要感謝堅持到底的研究團隊戰 友們:建宏、筱倩、亞韋、文蘭,在研究的日子裡,互相協助與鼓勵,分析資料、 挑燈夜戰,努力不懈,這段日子當難以忘懷。 感謝晉源主任引領我進測統所,在學習的路上給予真切的鼓勵;感謝政隆主 任及同事靜子老師、美娥老師的體諒,協助職場上不甚完善之處。這兩年的求學 生涯,忙碌而疏忽了家庭,讓我覺得對家人感到抱歉。謝謝我的先生閎基、我的 寶貝兒子泯均、祐陞及婆家、娘家的親友團們無悔的支持,讓我無後顧之憂全心 投入研究學業。 謝謝這兩年曾經關心過我、幫助過我的人,在此獻上最誠摯的感謝。 黃勇媜 謹致 102.6.19摘要
本研究目的為建置兒童文本語詞重複指標分析系統,並探討國小學童教科書 -國語科、社會科、自然科,語詞重複出現 (動詞、名詞及實詞)的趨勢及共同參 照凝聚力的影響,並根據國外的線上文本分析器 Coh-Metrix 發展文本自動化分析 指標及線上文本自動化分析系統,運用建置指標發展預測文本年級公式,進而探 討語詞重複對閱讀理解之關連性。研究結果如下: 一、本研究根據廖晨惠(2010)國科會「閱讀研究議題八:以 LSA 為基礎之電 腦化閱讀認知測驗及 AutoTuto 建置」計畫(編號:NSC 100-2420-H-142- 001-MY3) 所建置的國小語料庫,發展動詞相鄰重複詞指標、名詞相鄰重複詞指標、實詞相 鄰重複詞指標、名詞整體重複詞指標、動詞整體重複詞指標、實詞整體重複詞指 標。 二、根據本研究結果顯示,語詞重複趨勢顯示出,因年級升高語詞重複現象 逐漸下降。語詞重複分數越高,適合低閱讀能力者閱讀,語詞重複分數越低,則 適合高閱讀能力者閱讀。六項指標有效預測文本年級達 11.9%。 三、本研究結果顯示,直接提取閱讀理解層次為對低分組為最具預測變項; 檢驗評估閱讀理解層次對高分組為最具解釋力的預測變項。 關鍵詞:語詞重複、Coh-Metrix、PIRLS 閱讀理解層次、語料庫。ABSTRACT
This study is to establish an index system of text overlap in children literature, and to explore the trends of overlaps in verb, noun and contend word and the influence of co-reference cohesion.
Utilizing Coh-Metrix, an on-line text analyzer, analytical indices as well as an on-line automatic text analysis system have been developed. By using the established indices and grade level formula, the relationship between text overlap reading comprehension has been explored. The result is as follows.
1.This study is based on the corpus of elementary level derived from the Effectiveness of Automated Chinese Sentence Scoring with Latent Semantic Analysis and Auto Tutor Development (NSC 100-2420-H-142-001-MY3) by Chen-Huei Liao of National Science Council. This corpus provides indices of verb overlap-local, noun overlap-local, content word overlap-local, noun overlap-global, verb overlap-global and content word overlap-global.
2.As a result of this study, overlap trend shows that overlap phenomenon decrease as the grade is higher. Text of high overlap index suits those of lower reading capability, the lower the overlap index of a text, the better for those of high reading capability. The effectiveness of the 6 indices to achieve correct grade level prediction is 11.9%. 3.This study indicates, Retrieve Explicity Stated Information is the most significant
variable for the low score group, Examine and Evaluate Content is the most significant variable for the high score group.
目 錄
謝辭 ... II 摘要 ... III ABSTRACT ...IV 目 錄 ... I 表目錄 ... III 圖目錄 ... V 第一章 緒論 ... 1 第一節 研究動機 ... 1 第二節 研究目的 ... 3 第三節 名詞解釋 ... 3 第二章 文獻探討 ... 5 第一節 線上文本分析系統 Coh-Metrix ... 5 第二節 中文詞彙特性 ... 9 第三節 閱讀理解 ... 14 第三章 研究方法 ... 21 第一節 研究流程 ... 21 第二節 發展語詞重複指標 ... 23 第三節 研究工具 ... 25 第四節 線上文本自動化分析系統... 31 第五節 研究對象與限制 ... 34 第六節 資料處理與分析 ... 35 第四章 研究結果與討論 ... 37 第一節 兒童語料庫文本語詞重複出現趨勢分析 ... 37第二節 指標分數預測文本適讀年級 ... 42 第三節 題本通過率與指標分數分析 ... 45 第四節 閱讀理解與受試學生能力、語詞重複指標之相關分析 ... 47 第五章 結論與建議 ... 58 第一節 結論 ... 58 第二節 建議 ... 59 參考文獻 ... 61 中文參考文獻 ... 61 英文文獻 ... 64
表目錄
表 1-1-1 中文可讀性相關研究 ... 2 表 2-1-1 Coh-Metrix 3.0 類別與指標 ... 5 表 2-2-1 各家詞類定義 ... 11 表 2-3-1 PIRLS 閱讀理解歷程說明 ... 19 表 3-2-1 共同參照凝聚力文本矩陣 ... 23 表 3-2-2 共同參照凝聚力文本矩陣 ... 24 表 3-3-1 二次斷詞規則表 ... 26 表 4-1-1 各年級各科動詞相鄰重複詞指標數值 ... 37 表 4-1-2 各年級各科名詞相鄰重複詞指標數值 ... 38 表 4-1-3 各年級各科實詞相鄰重複詞指標數值 ... 39 表 4-1-4 各年級各科動詞整體重複詞指標數值 ... 39 表 4-1-5 各年級各科名詞整體重複詞指標數值 ... 40 表 4-1-6 各年級各科實詞整體重複詞指標數值 ... 41 表 4-2-1 指標分數與文本年級描述性統計摘要表 ... 42 表 4-2-2 指標分數與文本年級之間的相關係數矩陣表 ... 43 表 4-2-3 指標變項預測文本年級模式迴歸分析摘要表 ... 43 表 4-2-4 指標變項預測文本年級模式逐步迴歸分析摘要表 ... 44 表 4-3-1 指標分數與受試學生文本理解測驗通過率相關係數摘要表 ... 46 表 4-4-1 指標與直接提取層次之相關 ... 48 表 4-4-2 指標與直接推論層次之相關 ... 50 表 4-4-3 指標與詮釋整合層次之相關 ... 51 表 4-4-4 指標與檢驗評估層次之相關 ... 52 表 4-4-5 指標與閱讀層次之相關 ... 53圖目錄
圖 2-1-1 Coh-Metrix3.0 介面 ... 6 圖 3-4-1 系統登入介面... 32 圖 3-4-2 文本輸入與指標勾選介面 ... 33 圖 3-4-3 文本自動化分析結果 ... 34 圖 4-1-1 各年級各科動詞相鄰重複詞指標趨勢圖 ... 38 圖 4-1-2 各年級各科名詞相鄰重複詞指標趨勢圖 ... 38 圖 4-1-3 各年級各科實詞相鄰重複詞指標趨勢圖 ... 39 圖 4-1-4 各年級各科動詞相鄰重複詞指標趨勢圖 ... 40 圖 4-1-5 各年級各科名詞相鄰重複詞指標趨勢圖 ... 40 圖 4-1-6 各年級各科實詞相鄰重複詞指標趨勢圖 ... 41第一章 緒論
本研究根據中文特性,發展中文語詞重複指標分析系統,以協助學童挑選 適讀文章。分析兒童語料庫,探究文本內容凝聚力在一~六年級間的趨勢,並運 用建置指標發展預測文本年級公式。其第一節說明研究背景動機,第二節說明 研究目的,第三節為本研究重要名詞釋義。第一節 研究動機
近年台灣教育政策與國際接軌,利用各種閱讀策略指導學生閱讀,提升學 生的閱讀力及興趣是教師現行指導學生的要務。在國中小積極辦理規劃精進閱 讀教學計畫,各種閱讀策略因應而生,舉凡晨間閱讀,讀報,數位閱讀推展活 動等多元豋場。針對多元活動,教育部連年補助購買閱讀書籍經費,無論城鄉, 都能選擇適合自己學校學生閱讀的實體書或電子書。選擇多元的閱讀材料,能 提高學生閱讀興趣,並增加學生的閱讀理解能力,同時提升學生閱讀的質與量, 方能增進閱讀素養。然而,閱讀內容有難易之分,依據學習者的需求提供適合 其程度的閱讀文本,便可減少學習者花太多的時間去搜尋或嘗試閱讀不適合自 己能力的文本。透過分析文章的結構,能夠促使閱讀者在閱讀中主動尋找文章 的重要內容,快速抓住文章的架構和脈絡(閱讀理解策略教學手冊,2012)。 宋曜廷(2013)表示,只要提供適合讀者的可讀文本,便可能改善理解的表現, 而影響篇章理解的因素裡,文本因素相對於讀者因素容易著力也更具備教育意 義:只要提供適合讀者的高可讀文本,便可能有助改善理解的表現。 影響文章難度的因素有很多,譬如字頻、詞頻、文章長度、學生的先備知識、 文章的架構…等等,早在二十世紀初,英文系統就已有學者提出數十種不同的公 式來加以判斷文章的難度(例如:Dale & Chall, 1948; McLaughlin, 1969; Fry, 1977…等等),這些計算文章難度的公式稱之為可讀性公式(readabilityformula) 。
Gregory(2001)指出所謂的可讀性係指用來測量一篇文章在閱讀上之難易 程度。Yang(1971)提出所謂的可讀性公式即為測量文章難度的工具。Pikulski (2005)在其「可讀性」一文中也指出可讀性分數是經常被用來判斷文章難度 的一個指標。不過,也有許多研究質疑其統計假設基礎薄弱,對概念的測量, 以及效度驗證方式,值得商榷(Bruce,Rubin, & Starr, 1981; Schriver, 2000; Selzer,
1981)。無法整合多特徵、無法深究深層篇章理解歷程,是其主要限制(Graesser,
McNamara, Louwerse, & Cai,2004; Klare, 1984; McNamara et al., 2010)
中文以文本可讀性分析計量的研究相當有限。就所蒐集到之文獻而言,在中 文系統中,相關研究者及研究內容如表1-1-1: 表 1-1-1 中文可讀性相關研究 研究者 年代 可讀性相關研究內容及公式 楊孝濚 1971 影響中文可讀性語言因素的分析 年級 = .1788 × 筆劃數超過10劃百分比 + .1432 × 平均句長 + .6375 × 難字百分比 學期 = 14.95961 + 39.07746 × 詞彙數 - 2.48491 × 平均筆劃 數 + 1.11506 × 句數 荊溪昱 1992 延引拼音文字系統採用的可讀性指標:句子長度、課文長度、 常用字比率等為預測變項;以國編版教科書的學期值與年級 值為效標變項,發展一系列的可讀性公式 年級 = 5.43035627 + .00657347 × 課文長度 + .02443016 × 平均句長 - 5.56746245 × 常用字比率+ 1.38315091 × 詩歌體 - 1.07299966 × 對白文體 劉學濂 1996 擬定五個預測變項—非常用字比率,非常用詞比率,字筆畫 數,每句平均字數,每句平均詞數。 但此可讀性公式並未廣泛被使用,因為在中文和英文發音原理及造字原理並 不相同,所以直接套用英文的可讀性公式並不適合。再者,研究所包含的向度並 不一致、其所包含的文章樣本數代表性不夠,以及其在變項的定義上並不清楚; 而且,前兩項中文可讀性研究皆為較早期年代研究結果,其中用詞及語法與現代
中文有較大差異,期望再研發出適用目前現代中文語法的可讀性公式,以供現代 中文研究參考。 2002年美國曼菲斯大學(University of Memphis)研發一套測量美國學生閱讀教 材中語篇連貫性的關係Coh-Metrix線上文本分析系統,有別於過去可讀性公式只 研究多將文本表面特徵代入線性公式求得一個難易度的分數(黃幀祥,2011),而 能明確的計算出文本的凝聚力,與讀者對文本內容心理表徵的連貫性。其研究包 含11個類別,106個指標。目前國內鮮少有類似Coh-Metrix之中文線上文本分析系 統相關研究,因其中所使用語料庫及公式及各項定義皆不同於英文,研究內容龐 大,非一人可獨立完成,本研究組成研究團隊,共同發展中文適配指標。本研究 針對語詞重複指標,分析現行教科書以了解語詞重複趨勢,並探討其與閱讀理解 的關係。
第二節 研究目的
根據上述研究動機,研究目的為: 一、建置兒童文本分析系統之語詞重複指標。 二、檢視現行國語、社會、自然教科書語詞重複情形。 三、探討語詞重複指標與閱讀理解的關係。第三節 名詞解釋
針對本篇論文常見的名詞,詳細說明如下:壹、重複語詞
本研究中,無論相鄰句或段落所有句子,出現詞性相同的相同名詞、動詞 或實詞,即可稱為重複語詞。語詞的重複出現可增加文章間的凝聚力,使文章 容易閱讀與理解。貳、相鄰句
相鄰的句子是指一段文字中,連續句子的位置關係。例如,如果某一文字 段有 4 個句子,相鄰的句子指的是將句子 1-2,2-3 和 3-4。
參、重複得分
在序列上的文字單位,分類後以重複的得分計算。這個是相鄰序列中的單 位且在同一類別中的比例分數。如果有 N 個單元序列中,有(N-1)個相鄰對。 在同一類別中的相鄰對的數目是 N-1,其得分為分類序列重複數除以(N-1)個 相鄰對。例如,我們已計算出的重複序列的得分為 A,B 和 C 類: 分類序列: A B B B C A A C C B B B B A C C 相鄰重複:0 1 1 0 0 1 0 1 0 1 1 1 0 0 1 此序列分數 : 8 / 15.肆、閱讀理解
本 研 究 探 討 之 閱 讀 理 解 是 指 國 際 教 育 成 就 評 鑑 協 會 ( International Association for the Evaluation of Educational Achievement,簡稱 IEA)主導的促 進國際閱讀素養研究(Progress in International Reading Literacy Study,簡稱 PIRLS)中,將閱讀理解分為「文本理解」和「深度理解」兩部分。「文本理 解」指的是文章表面意義的理解,包括「提取訊息」和「推論訊息」;「深度 理解」指的是超越對文章本身的了解,對文章重組、解釋、延伸、批判上都有 進一步的理解,並且以批判的方式檢視文章的特性。包括「詮釋整合」和「比 較評估」。第二章 文獻探討
本研究主要目的是建置中文語詞重複分析自動化指標,並參考 Coh-Metrix 研究自動化計分系統,藉以了解現行教科書語詞重複趨勢,並研究指標在兒童 閱讀理解上的關聯。因此本研究針對 Coh-Metrix 概述、中文詞彙的特性、閱讀 理解之相關探討。第一節 線上文本分析系統 Coh-Metrix
壹、Coh-Metrix 的發展
Coh-Metrix 是從 2002 年開始發展的一種網路智慧型文本分析工具,由美國 曼菲斯大學(University of Memphis)所研發。美國教科書編寫長期以來依賴字 長及詞長指標,而造成縮短字長、詞長來遷就對應年級,以致造成文句破碎, 增加閱讀理解之困難(McNamara, Louwerse, & Graesser, 2002) 。Coh-Metrix 其 設計目的是改善教科書的寫作方式,在系統中加入詞彙、句法結構、潛在語意 分析及凝聚性等影響文章難易度的指標,提供文字和論述的語言數據索引 (Graesser et al 2004), 這些值可以用許多不同的方式,明確的評估文本的凝聚 力(cohesion)與讀者對文本內容心理表徵的連貫性(cohesiveness),進而評估讀 者對文本深層認知理解程度,其總體目標希望能提供更多測量文本複雜性的運 算指標。 Coh-Metrix 依據版本和工具,評估特定的指標,目前發展至 3.0 版本,指 標共計 11 個類別,106 個指標(Coh-Metrix3.0): 表 2-1-1 Coh-Metrix 3.0 類別與指標 1 描述性(Descriptive)-11 個 6 關聯詞(Connectives)-8 個 2 參照凝聚力-10 個 (Referential Cohesion) 7 情境模型(Situation Model)-8 個 3 潛在語意分析(LSA)-8 個 8 語法複雜度-7 個 (Syntactic Complexity)4 詞彙多樣性-4 個 (Lexial Diversity)
9 句型密度-8 個
(Syntatic Pattern Density)
5 文本適讀性分數-16 個
(Text Easability Principle Component Score)
10 詞彙訊息-22 個 (Word Information)
11 可讀性指標(Readability)-3 個
資料來源:McNamara, Graesser, McCarthy & Cai(未出版)
目前,英文線上文本分析系統建置了 Coh-Metrix 3.0 線上版,為分析各個 文本提供了 600-1000 個指數,但未全數開放使用。目前開發了供讀者使用 Coh-Metrix 3.0,網址:http://cohmetrix.memphis.edu/cohmetrixpr/index.html 介面 如下。 圖 2-1-1 Coh-Metrix3.0 介面
貳、Coh-Metrix 的重要性
過去,可讀性最常用來估計文本的難度,在過去百年中,已經有數百種檢 測方式被開發。一般可讀性僅僅依靠字長和句子的長度來評估,其實句子長度 和字長只能預測閱讀時間 (Haberlandt & Graesser, 1985; Just & Carpenter, 1987; Rayner, 2003) ,再者可讀性研究只預測讀者對於字和詞的理解,驗證文本理解 也只限於填空格字,評估詞與句子的關聯(Shanahan, Kamil, & Tobin, 1982),而不是閱讀理解能力的研究。早在 1980 年代,估計超過 200 種文本可讀性的演算 規則系統產生,同時更有 1000 篇以上的相關研究發表(Graesser et al 2004)。 在傳統難易度測驗方法簡易,僅限於字、句和文本,但對學生閱讀能力的 提升無實質的幫助。因此,若能針對學生個別差異,發展對文本進行分類,選 擇適合學生閱讀文本的分析工具那就相當重要了,Coh-Metrix 正好符合這個特 點。況且可讀性評估方法上常忽略文本中凝聚力及連貫性所扮演的角色,而 Coh-Metrix 改善了這個缺點,在一前後相接段落的成對句型中,文字、概念或 想法重疊於期間,便可以形成銜接多個句子的連結。(McNamara et al., 2007)。 它可以找出心理語言學、計算語言學教育和閱讀素養之間凝聚力的線索,提供 有關文本的可讀性及相關理解(McNamara, Graesser, Cai, & Kulikowich, 2011)。
在 Coh-Metrix 中,凝聚力是重要的核心假設,其透過自動化分析計算系統, 分析詞、句子、段落和篇章的文本多層次凝聚特性與文章難度的關係〈宋曜廷, 2012〉,而凝聚力是文章的組成特性,它連結文字間想傳達的結果和概念,也 可結合文章中詞和句子關係,更可聯繫句子、文本和讀者的想法。在文章裡給 讀者明確的暗示,可幫助讀者加快理解程序,或推論這些關係,產生深層的理 解(Lehnert & Ringle, 1982)。
具有高凝聚力的文本,不僅在句子間,也在全文間形成明確的線索,可幫 助讀者加快理解或推論文本間的關係。然而凝聚力較低之文本,若讀者先備知 識夠多,則可以刺激讀者產生推論極更多的解釋,反之,會因缺乏線索,較難 連接文本與讀者的想法(Halliday & Hasan, 1976)。
参、Coh-Metrix 的分析指標
在 Coh-Metrix 指標類別中,參照凝聚力(Referential Cohesion)、潛在語意分 析(LSA)及關聯詞(Connectives)皆為研究文本凝聚力之指標類別。其中,參照凝
聚 力 在 中 文 語 法 中 鮮 少 有 相 關 闡 述 , 本 研 究 則 針 對 共 同 參 照 凝 聚 力 (co-reference cohesion)對中文文本產生之凝聚性影響加以分析探討。 在早期,兩個句子裡,有一個共同的參數(如:名詞,動詞..等),這兩個 句子就具有共同參照凝聚力。參照(referential)和語意的重複(semantic overlap) 是明確有力的凝聚力來源,其出現在相鄰句中,段落中或相鄰段落中的句子裡。 句中的詞、概念或想法重複,構成了句子之間的聯繫。當文字、概念或想法重 複於句型中時,便可以形成銜接多個句子的連結,形成高凝聚力。若凝聚力指 數過低則會出現理解斷層或增加閱讀時間(Graesser et al, 2004)。 共同參照指數關係著文章中語意是否連接的一個重要指標(Halliday & Hasan, 1976; McNamara & Kintsch, 1996),已被廣泛研究在文字語言學和論述流 程的領域裡。詞彙參照已被證明可以幫助文本的理解和閱讀速度(Kintsch & van Dijk 1978)。
共同參照凝聚力相同特點如下:
1 研究指標包含兩兩相鄰的局部句凝聚力指標(local sentences)與段落 間總體凝聚力指標(global sentences)。
2 共同參照模式含括以下幾類:
(1)實詞重複指標(content word overlap):句子間相同實詞重複出 現比例的研究。 (2)名詞重複指標(noun overlap):句子間相同名詞重複出現比例的 研究。 (3)動詞重複指標(verb overlap):句子間相同動詞重複出現比例的 研究。 (4)參數重複指標(argument overlap):句子間相同名詞或代詞重複 出現比例的研究。(e.g., table/table, he/he, or table/tables)
(5)詞幹重複指標(stem overlap):名詞在任何語法範疇中的其他任 何詞中有一個共同的語義單元。(e.g., the noun photograph and the verb photographed).
因以上所述共同參照指標項目皆以英文文本研究發展而成,其中參數重複 指標(argument overlap)和詞幹重複指標(stem overlap)不能完全適用於中文 語法文本分析,因此本研究以探討實詞重複指標(content word overlap)、動詞 重複指標(verb overlap)、名詞重複指標(noun overlap)為主要研究指標。
目前參考中文語法發展的線上文本分析系統研究並不多,國內以國立台灣 師範大學宋曜廷等人(2010)所開發之文本可讀性指標自動化分析系統(Chinese Readability Index Explorer, CRIE),能夠自動分析文本多項特徵,為實用的文本
分析工具。但 CRIE 對於語詞重複所產生的文本凝聚力研究鮮少著墨,本研究 則針對此類指標進行探討與建置。
第二節 中文詞彙特性
自從黎錦熙 1933 年在「國語文法」有意用漢語的「詞」 對等表示英語的 「word」以後,「字」和「詞」兩個述語在漢語中逐漸分工(彭澤潤,2005)。 中文「字」是形體單位,未經過處理的原始中文句子是以字(character)的序列 模式存在的。「詞」是意義的基本單位,詞(word)與字相比是一種更直接和便 捷的單位。中文分詞(Chinese word segmentation)的目的就是將文本的句子切分 成詞,使其成為慈序列的形式。文章中的「詞」是意義單位,從句子中可以整 理出詞類,我們把詞類教給學生,就是讓他們能夠很順利地將詞類回歸到句子 (鄧守信,2009)。 中文裡所說的「字」並不等同於英文的 「字」,在功能上,中文的「字」 比較接近英文的「詞素(morpheme)」,而中文詞則略等於英文的「word」(鄭 昭明,1978;羅肇錦,1993)。漢語的詞是由語素構成。語素是最小的語音與語義結合體,是最小的語言單位 (胡裕樹,1992) 。把一個語言片段,切分到不能 再分的最小單位,就是語素。例如: 要│遵│守│交│通│安│全│生│命│才│有│保│障 這十三個字已經不能再分了,每個單位都是一個音節,並且有一定的意義, 是語音語義結合的最小單位,這就是漢語的語素了。漢語語素多為單音節,寫 出來就是一個漢字,也有雙音節或者多音節的,寫出來就是兩個或兩個以上的 漢字。 詞是比語素高一級的語言單位。有的語素可以單獨成詞,也可以與其他語 素組合成詞;有的語素不可以單獨成詞,一定要與其他語素結合方能成詞。語 素構成詞後,才能充當句法成分。將詞分類,可以用不同的標準,取決於分詞 的意義。例如:為了編輯的目的,可以將詞的意義分為動物類、植物類、藝術 類等;為了研究詞彙,可以按照詞的來源分為古語詞、外來詞及方言詞等。詞 的數量非常龐大,可使用詞性(part-of-speech)來概括一個詞在一個句子中所展 現的句法功能和意義,詞性標註(part-of-speech tagging)的目標就是在產生中文 分詞的詞序列時,給每個產生的詞標註一個詞性。(張開旭,2012)。
從自然語言的處理 (Natural language Processing)應用和理解的角度來看, 中文分詞的詞性標註是許多應用的基礎。包含句法分析、信息提取、機器翻譯 等,這些都可以從好的中文分詞詞性標註模型中獲得較正確的結果。(侯呈風, 2011;張開旭,2012)。而以自然語言理解(Natural language understanding)的 角度看來,中文分詞詞性的標註是中文理解的基礎步驟。 語法上區分詞類的目的是為了指明詞的外部結構關係,說明語言的組織規 律,因此,分類的基本根據是詞的語法功能。中文的詞彙可分為「實詞」及「虛 詞」兩大類,能單獨成為句子成分的為實詞,不能單獨成為句子成分的為虛詞, 虛詞能幫實詞成為句子或表達語氣,所以又稱功能詞。然而詞類的分類各有特 色。本研究將各家詞類分類如下表:
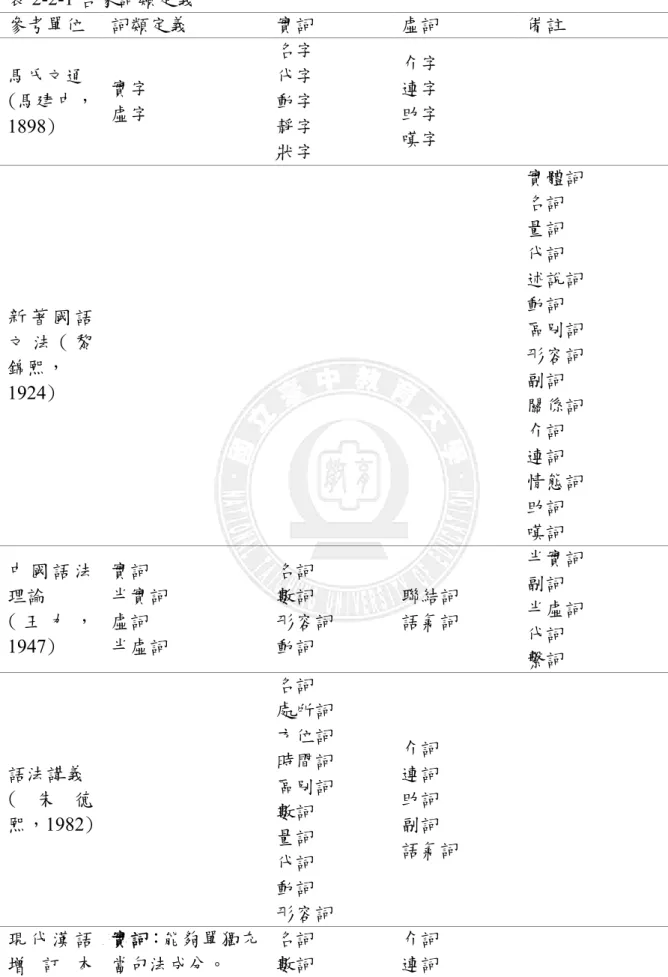
表 2-2-1 各家詞類定義 參考單位 詞類定義 實詞 虛詞 備註 馬氏文通 (馬建中, 1898) 實字 虛字 名字 代字 動字 靜字 狀字 介字 連字 助字 嘆字 新 著 國 語 文 法 ( 黎 錦熙, 1924) 實體詞 名詞 量詞 代詞 述說詞 動詞 區別詞 形容詞 副詞 關係詞 介詞 連詞 情態詞 助詞 嘆詞 中 國 語 法 理論 ( 王 力 , 1947) 實詞 半實詞 虛詞 半虛詞 名詞 數詞 形容詞 動詞 聯結詞 語氣詞 半實詞 副詞 半虛詞 代詞 繫詞 語法講義 ( 朱 德 熙,1982) 名詞 處所詞 方位詞 時間詞 區別詞 數詞 量詞 代詞 動詞 形容詞 介詞 連詞 助詞 副詞 語氣詞 現 代 漢 語 增 訂 本 實詞:能夠單獨充 當句法成分。 名詞 數詞 介詞 連詞
(胡裕樹, 1992) 虛詞:不能夠單獨 充當句法成分。 量詞 代詞 動詞 形容詞 副詞 助詞 象聲詞 歎詞 語氣詞 現 代 漢 語 配 價 語 法 研究 ( 郭 銳 , 2002) 名詞 處所詞 方位詞 時間詞 區別詞 數詞 量詞 數量詞 指示詞 副詞 擬聲詞 動詞 形容詞 狀態詞 介詞 連詞 助詞 語氣詞 嘆詞為獨立詞 簡 明 漢 語 語 法 ( 郭 振華 ,2003) 實詞:有實在的意 義,在句中的位置 自由,屬於開放性 的。 虛詞:沒有實在的 意義,在句中的位 置固定,屬於封閉 性的。 名詞 數詞 量詞 代詞 動詞 形容詞 副詞 介詞 連詞 助詞 象聲詞 歎詞 歎詞、象聲詞一 般歸入虛詞,可 是 他 們 能 單 說,不同於其他 類虛詞。 李 麗 綺 (2003) 實詞:能單獨成為 句子成分 虛詞:不能單獨成 為句子成分 名詞 數詞 量詞 代詞 動詞 形容詞 副詞 助動詞 介詞 連詞 助詞 狀聲詞 歎詞 資料來源:整理自高子晴(2000)現代漢語詞類界定 本研究所需詞彙分類如下,其依胡裕樹(1992) 現代漢語增訂本所載,作為 分類標準,以下所述,皆依上述實詞分類進行探討。實詞、虛詞分類如下:
一、實詞(content words): (一)名詞(noun):凡實物的名稱,叫做名詞。在句子中常做主語和賓 語。可分為普通名詞、專有名詞和抽象名詞。 (二)動詞(verbs):凡詞指稱行為或事件者,稱為動詞。在句子中常常 當做謂語。 (三)量詞(quantifier):表示人、事物、動作或行為單位的詞。量詞是 漢語特色之一,其他語言鮮少使用。 (四)形容詞(adjectives):凡詞表示實務德性者。用來形容名詞,詞彙前 面可以加程度副詞。 (五)代詞(pronouns):具替代、指示作用的詞。可分為疑問代詞、指 示代詞及人稱代詞。 (六)數詞(numeral):表示數目的詞,通常可分成基數詞漢序數詞兩類。 (七)副詞(adverb):能表示程度、範圍、時間、可能性、否定作用等, 不能單獨指稱實物,也不會單獨出現在句子中。 二、 虛詞(function words) (一)介詞(preposition):在名詞、代詞或名詞性詞組的前面,用來修飾 動詞或形容詞,通常是用動詞虛化而來的。 (二)連詞(conjunction):連接詞、詞組、分句和句子,並表示它們之 間的相互關係詞彙。 (三)助詞(particle):附在詞、詞組或句子後面,具輔助作用的詞彙。 (四)嘆詞(interjection):表示感嘆、呼喚和應答,不跟別的詞彙發生 結構關係。 類型學家 Baker(2003)與 Croft(2001)認為動詞、名詞和形容詞為具 有語言共性之詞類,稱為實詞,為開放性詞類,容易有新的詞語加入其中;而 虛詞為封閉性詞類。開放性詞類遠超過封閉性詞類,使用頻率亦相對提高,此
三大詞類中,形容詞在中文與英文領域上結構差異較大(高子晴,2010)。本 研究將先針對名詞、動詞及實詞重複趨勢與閱讀之相關進行探討。
第三節 閱讀理解
閱讀最終目的是理解,也就是從文章中獲得意義(柯華葳,1993)。它是複 雜的心理運作,也是許多認知歷程的組合。以下就閱讀理解的定義、歷程及模 式加以探討。壹、閱讀理解的定義
閱讀理解的相關研究將近百年,以下整理中外釋義,以作研究參考: 表 2-3-1 中外閱讀理解定義 學者或 研究者 年代 定 義 Robinson McCollum 1934 定義閱讀理解能力是指閱讀的速度和理解的正確率,從書面文章 建構意義的過程。 美 國 國 家 教育學會 1985 將閱讀定義為建構文章意義及內容的過程,閱讀過程進行中,最 終透過閱讀,可以獲得資訊、增進知識、解決問題。 Swaby 1989 理解就是一種將句法、語法、詞彙知識運用於短文閱讀情境的閱 讀技能,讀者只要具備應有的技能,閱讀理解便自動發生。 Kintsch 1998 以建構整合理論來解釋閱讀理解,內文基礎用到字義理解和文章 事實理解,在建構情境模型過程中,要用到推論理解;若將此情 境模型有效遷移至其他情境,協助解決問題,則是有意義的文章 學習。 Mcncil 1992 認為閱讀理解是指個人利用現存的知識來解釋所閱讀的文字,以 便建構閱讀意義的歷程。 Pressley 2000 將閱讀理解分為兩個層次:一為字彙層次的理解,屬較低層次的 理解,強調字彙的解碼和數量;另一為文章層次的理解,為較高 層次的歷程,強調在句子和句子之間,段落和段落之間即整篇文 章的理解。柯華葳 李俊仁 1999 閱讀是一種從書面文字建構意義的歷程和行為,閱讀成分包含認字 (word recognition)和理解(comprehension)兩部分。 董宜俐 2003 所謂的閱讀能力包含了字義理解、文本裡解、推論理解乃至於使用策 略去監督理解、協助問題解決的能力。 李慧慧 2006 閱讀最終目的是理解,也就是讀者可以明白文章中所欲闡述的意 義。 李佳靜 2009 閱讀歷程是一連串的過程,是讀者與文本互動、主動建構內化知 識、運用策略有效獲取知識的歷程。 劉育君 2012 認為閱讀就是將所看到的視覺文字和訊息,轉譯成自己所能獲得 意義的過程。 資料來源:整理自黃堯香(2007) 國小四年級學童中文閱讀理解測驗編製與其相關研究 早期行為學派心理學者把閱讀看成是待精熟的技巧,初學者只要經熟的建 立理解能力的技巧,即可成為閱讀專家;認知學派則認為,閱讀理解是透過讀 者與文章的交互作用,建構文章意義的過程。在實際閱讀時,可應用策略知識 及後設認知知識來達到閱讀理解(李麗綺,2003)。以下就閱讀歷程階段、閱讀 歷程模式及 PIRLS 的閱讀歷程作介紹。
貳、閱讀歷程的階段
Gagn’e(1985)將閱讀歷程區分為四階段,此四階段為解碼(decoding)、文 意理解(literal comprehension)、推論理解(inferential comprehension)與理解監控 (comprehension monitoring)四階段。其中解碼屬於認字層次,指對於字彙的理解 能力。其餘三項則屬於理解層次。解碼分為字型字義的直接比對與藉由語音的間接解碼兩種。字型字義的直 接比對是指讀者在閱讀文章時,以已知的字詞型態和看到的書面字詞相比對, 不需經過發音歷程,即可從長期記憶中檢索出對應的意義。藉由語音的間接解 碼是讀者藉由讀出字音,然後再檢索出字詞的意義。 二、文意理解(literal comprehension) 文意理解是從文句中找出文字的意義,包括詞彙接觸(lexical acess)和剖析 語法(parsing)兩個歷程。詞彙接觸是運用解碼出的文字來確認及選擇合適的文 意。剖析語法是指分析句子的構成規則,將文章中有意義的文字連結在一起, 以了解句子的意義。閱讀歷程至此能了解文意,但只能對句子表象理解。 三、推論理解(inferential comprehension) 能更深入了解文章背後的涵義,因此超越了字面理解的階段。推論理解包 含有統整(integration)、摘要(summarization)和引申(elaboration)。統整是覺察句 子間所傳達概念之相關性,將兩個以上的概念相結合,形成較複雜的觀念。摘 要則是讀完一小段文章後,找出此段文章的重點、大意或大架構,表達出文章 的概念,或從文章段落中判斷訊息的重要性並歸納出重要的概念。引申是藉由 提供先備知識,結合新閱讀的訊息整合產生新的詮釋。 四、理解監控(comprehension monitoring) 檢視自己在閱讀活動中是否完全理解文意,察覺以及改進本身的認知歷 程 。 理 解 監 控 包 含 設 定 閱 讀 目 標 (goal setting) 、 選 擇 閱 讀 策 略 (strategy selection)、檢核目標 (goal checking)、採取補救方案(remediation)。閱讀開始時, 先設定目標,且選擇一個閱讀策略來達到此目標,同時透過目標檢核來確定目 標達成與否,如果未達成,則針對欲達成的目標來進行補救。由於理解監控屬 於最高階的閱讀層次,故又被稱為後設認知(邱上真、洪碧霞、胡永崇,1996; 徐芳立,1998)。
參、閱讀歷程模式
以 上 模 式 可 以 歸 納 為 三 個 主 要 類 別 , 分 為 由 下 而 上 模 式 (bottom-up model)、由上而下模式(top-down model)、交互模式(Interactive model)。此外 Just & Carpener 主張閱讀理解是一個循環模式(recycling model),Kintsch(1998) 以認知的觀點,提出「建構統整模式」(construction-integration model,簡稱 CI model)(陳密桃,1992;簡麗貴,2012),以下分別敘述之。 一、由下而上的理解模式(Bottom-up Model) Gough 將閱讀的歷程分為肖像表徵、字母的辨識、詞的認知、詞在句中的 加工、短時記憶五個階段(張必隱,1992)。亦稱為資料驅動模式(data-driven models)或以閱讀材料為主的內文本位模式(text-based model)。是一種直線式的 閱讀歷程,是由具體到抽象的訊息處理歷程,這種模式偏向型為主義模式論點, 強調對字彙或文字本身的低層次認知結構處理,遺漏了預測、推理等高層次認 知歷程(Hayes,1991)。 二、由上而下理解模式(Top-Model) 以 Goodman 為代表,是一種概念導向的模式,此模式也稱為概念主導歷程 (concept-driven processing)或重視閱讀時,讀者運用個人現有知識的讀者本位模 式(reader-based models),此模式認為閱讀的歷程是讀者以較高層次的知識來處 理較低層次的訊息。Goodman 強調讀者的知識背景在閱讀過程中有重要的作 用。McCormick(1995)認為閱讀是經由讀者先備知識作為閱讀理解的來源,依據 本身的舊經驗對閱讀中文章進行推理、預測、整合等認知歷程,建構出文章的 意義(劉育君,2012)。文中意義越生活化、越符合情境,越能讓讀者了解全 文(廖凰伶,2000)。張必隱(1992)對此提供不同意見,認為讀者本身的文 字知識與句法等閱讀能力低落,雖具相關背景知識,也無法理解相關文字訊息。 三、交互模式(Interactive Model)
以 Rumelhart 為代表,主張讀者在理解文章閱讀歷程,會交錯運用「由下 而上」與「由上而下」兩種模式。讀者必須依賴先備知識提供線索,與文字解 碼後得到訊息結合,才能對文章產生正確的預測與推論,是同時兼顧低層次思 考與高層次思考的歷程模式(劉育君,2012)。
四、循環模式(recycling model)
循環模式強調閱讀是一個循環而不是直線運作過程, (Just. & Carpenter, 1980)發現讀者每看一個字,對此字立即產生解釋。柯華葳(1993)進一步指出, 除了對文字立即產生解釋外,並對下一個字產生期望,接而產生段落意思,若 期望與訊息相異,則尋找另一解釋。因此,閱讀理解就成一個循環歷程。
五、建構統整模式(Construction-Integration Model)
Kintsch(1998)以認知的觀點,提出建構統整模式理論。其模式可分為二: 「文本模式」(textbase model)、「情境模式」(situation model)。文本模式認為讀 者只是單純閱讀文章內容,並沒有運用先備知識統整文章;讀者閱讀完文章後, 能將文本內容和自己得先備知識和經驗結合,形成「情境模式」,代表讀者可 以有效的理解文章的意義(連啟舜,2002)。
肆、PIRLS 的閱讀理解歷程
「促進國際閱讀素養研究」( Progress in International Reading Literacy Study,簡稱 PIRLS )起源 2001 年,每五年一輪施測閱讀理解趨勢研究。是由 國 際 教 育 成 就 調 查 委 員 會 ( International Association for the Evaluation of Educational Achievement; IEA) 主辦之國際測驗,這項計畫主要的目的在研究不 同國家教育政策、教學方法下四年級兒童的閱讀能力。PIRLS 在 2006 年的閱讀 評量中,以文學類故事體及資訊類說明文共 10 篇,測出提取訊息、推論訊息、 詮釋整合、比較評估的四個閱讀歷程。其研究將閱讀理解分為「文本理解」和 「深度理解」兩部分。「文本理解」指的是文章表面意義的理解,包括「提取
訊息」和「推論訊息」;「深度理解」指的是超越對文章本身的了解,對文章 重組、解釋、延伸、批判上都有進一步的理解,並且以批判的方式檢視文章的 特性。包括「詮釋整合」和「比較評估」,本研究根據根據 PIRLS 的閱讀理解 歷程,編製閱讀理解測驗題型。以下針對這 4 個細項進行說明(柯華葳、詹益 綾、張建妤、游婷雅,2008): 表 2-3-1 PIRLS 閱讀理解歷程說明 閱讀歷程細項 說明 評估要點 直接提取(focus on and retrieve explicitly stated information ) 讀者找出文 中清楚寫出 的訊息 1.找出與閱讀目標有關的訊息 2.找出特定觀點 3.搜尋字詞或句子的定義 4.指出故事的場景(例如時間、地點) 5.(當文章明顯陳述出來時)找到主題句或 主旨 直接推論 (make straightforward inference) 讀者需要連 結文中兩項 以上訊息 1.推論出某事件所導致的另一事件 2.在一串的論點後,歸納出重點 3.找出代名詞與主詞的關係 4.歸納文章的主旨 5.描述人物間的關係 詮釋、整合觀點和訊息 (interpret and
integrate ideas and information) 讀者需要提 取自己的知 識以便連結 文中未明顯 表達的訊息 1.清楚分辨出文章整體訊息或主題 2.考慮文中人物可選擇的其他行動 3.比較及對照文章訊息 4.推測故事中的情緒或氣氛 5.詮釋文中訊息在真實世界的適用性 檢驗、評估內容、語言 和文章的元素 (examine and evaluate content, language, and textual elements) 讀者需批判 性考量文章 中的訊息 1.評估文章所描述事件實際發生的可能性 2.揣測作者如何想出讓人出乎意料的 3.評斷文章中訊息的完整性 4.找出作者的觀點 資料來源:柯華葳、詹益綾、張建妤、游婷雅(2008)
本研究所採用之中高年級文本理解測驗技術報告則以 Gagn’e 主張之閱讀 歷程、Kintsch 提出閱讀模式理論為理論基礎,並參考 PIRLS 的閱讀理解歷程命 題模式編製而成。
第三章 研究方法
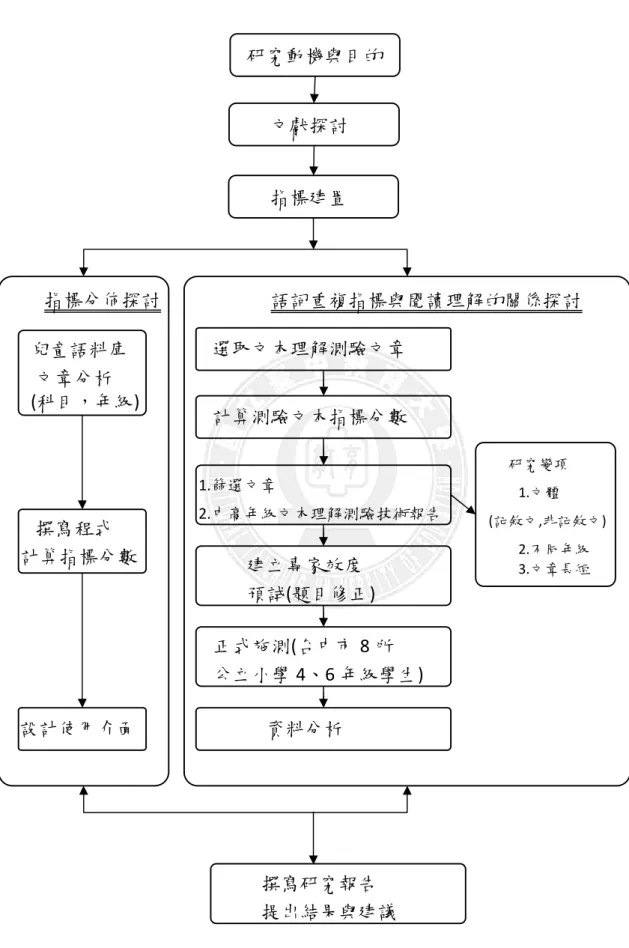
本章節共分為六節,依次說明為研究流程、發展語詞重複指標、研究工具、 線上文本自動化分析系統、研究對象與限制、資料處理與分析。第一節 研究流程
本研究之研究流程圖如圖 3-1-1 所示,本研究先搜集中文詞彙特性、 Coh-Metrix 與閱讀理解相關文獻之探討。接著建置文本語詞重複出現自動化分 析指標,進行自動化文本特徵分析,進而探討國小學童教科書-國語科、社會領 域、自然領域中(兒童語料庫),語詞重複出現(動詞、名詞及實詞)分數及分布 趨勢,發展指標於文章中相鄰句與整篇文章凝聚力自動化計分模式。 選取民國七十八年國立編譯館出版國語科四、六年級教科書,利用指標分 數分析,根據文體,年級,選取其中 8 篇作為中高年級閱讀題本文章。國立編 譯館出版之國語教科書,編寫嚴謹,且現今小學生均未接觸此類文章,適合作 為測試題本。 預試後,刪除文本鑑別度不佳題目,並正式施測。經由迴歸、T 檢定等資 料分析,找出指標與閱讀文本的相關,並檢視指標對文章的預測度,最後撰寫 研究報告並提出研究成果與建議。圖 3-1-1 研究流程 研究動機與目的 文獻探討 指標建置 指標分佈探討 兒童語料庫 文章分析 (科目,年級) 撰寫程式 計算指標分數 設計使用介面 語詞重複指標與閱讀理解的關係探討 選取文本理解測驗文章 計算測驗文本指標分數 1.篩選文章 2.中高年級文本理解測驗技術報告 建立專家效度 預試(題目修正) 正式施測(台中市 8 所 公立小學 4、6 年級學生) 資料分析 撰寫研究報告 提出結果與建議 研究變項 1.文體 (記敘文,非記敘文) 2.不同年級 3.文章長短
第二節 發展語詞重複指標
本研究主要目的為發展自動化文本重複性指標,其指標說明如下:實詞重 複指標(content word overlap),動詞重複指標(verb overlap),名詞重複指 標(noun overlap)。其指標計算方式皆包含相鄰句凝聚力指標計算(公式 1)與 文章整體凝聚力指標計算(公式 2)。其公式說明如下。
壹、相鄰句凝聚力(local cohesion)
相鄰句之文本凝聚力計算是利用運用重複得分(repetition score)計算,假若 相鄰兩句中有相同詞彙出現,則有共同參數,表示值為 1,否則為 0,此為測量 相鄰兩句之間的共同參照凝聚力。文本中相鄰句的比對方式為:第 1 句 v.s.第 2 句,第 2 句 v.s.第 3 句..至文本結束。其範例如下,S1~ S4為文本中的句子。 S1今天是個晴天, S2老師喜歡利用晴天的日子帶我到操場玩, S3通常會踢球、盪鞦韆,還能捉迷藏 S4我愛晴天 其名詞的共同參照凝聚力矩陣詳見表 3-2-1,S1與 S2有相同的名詞詞彙, 得分為 1,S2與 S3無相同的詞彙,得分為 0。 表 3-2-1 共同參照凝聚力文本矩陣 S1 S2 S3 S4 S1 - 1 - - S2 - - 0 - S3 - - - 0 S4 - - - -相鄰句之文本凝聚力計算公式 1 如下,其值越大,凝聚力高,值越小,凝 聚力低: 1 local cohesion reference -Co 1 1 1 ,
n R n i i i 〈公式 1〉 n=句子數 ,i 為文章中欲比對的句子貳、整篇文章凝聚力(global cohesion)
本研究使用矩陣來描述文本段落之間的重複。n×n 矩陣中,共同參照凝聚 力被稱為 R。文本中有 n 個句子,定義為 S1,S2,….Sn,兩個句子用 Si和 Sj 表示, Rij 為二者的參照凝聚力。如果兩個句子至少有一個共同參照的關係, 表示值是 1,否則為 0。 文本中文章整體凝聚力的比對方式為:第 1 句 v.s.第 2 句,第 1 句 v.s. 第 3 句.. 第 1 句 v.s.第 11 句;第 2 句 v.s.第 3 句..以此類推至文本結束。 文章整體凝聚力考慮文章中每一句對文章整體的凝聚力的影響程度,兩個 句子的遠近將影響凝聚力的高低。距離近,兩句子之間的凝聚力關係緊密,則 權重考量較高;反之,距離遠,兩句子之間的凝聚力關係較疏遠,則權重考量 較小,因此以兩句子之間的距離的倒數做為加權依據,如表 4。文本中兩句的 距離為 1,2,3, . . . , k, 其距離倒數則為 1, 1/2, 1/3, . . . , 1/k,.若兩句有語詞重複, 則加權分數為句子距離的倒數,例如:S1與 S4有名詞重複,距離為 4-1=3,加 權分數為 1/3;S2與 S4有重複,距離為 4-2=2,加權分數為 1/2。 表 3-2-2 共同參照凝聚力文本矩陣 S1 S2 S3 S4 S1 1 1 0 1/3 S2 1 1 0 1/2 S3 0 0 1 0 S4 1/3 1/2 0 1其計算文本整體凝聚力是將比對值帶入 global 公式,如公式 2,其值越大,凝 聚力高,值越小,凝聚力低。 2 1 n n j i R n i n i j ij
1 , global cohesion reference -Co 〈公式 2〉 其中 n=句子數,i、j 分別為文章中欲比對的句子。第三節 研究工具
壹、 兒童語料庫
本研究使用之文本資料來源為廖晨惠(2010)國科會「閱讀研究議題八:以 LSA 為 基 礎 之 電 腦 化 閱 讀 認 知 測 驗 及 AutoTutor 建 置 」 計 畫 ( 編 號 : NSC 100-2420-H-142-001-MY3)所建置的國小語料庫,共收錄 945 篇國語日報及國小 各版本各領域之課文文本。本研究挑選國小一至六年級課文中國語、自然與社 會科目共 787 篇,以比較不同科別、年級之詞彙,分析文本重複語詞與凝聚力 的趨勢。貳、 斷詞系統
本研究使用中央研究院數位典藏國家型科技計畫建置之中文斷詞系統 (http://ckipsvr.iis.sinica.edu.tw/),完成兒童語料庫文本初步斷詞。中央研究院中 文斷系統可以自動抽取新詞建立領域用詞或線上即時分詞功能,為一具有新詞 辨識能力並附加詞類標記的選擇性功能之斷詞系統。此一系統包含一個約 10 萬詞的詞彙庫及附加詞類、詞頻、詞類頻率、雙連詞類頻率等資料。檢視初步 斷詞結果發現部分詞類標記與現代漢語詞類標記不相符合,修改部分斷詞規則 進行二次斷詞。表 3-3-1 二次斷詞規則表為節錄於二次斷詞之範例。表 3-3-1 二次斷詞規則表 編號 中文斷詞系統 詞性標記 修改後詞性標記 中研院斷詞系統 完成斷詞 修改斷詞規則後 斷詞 1 (ADV)(Vi)(M) (N) (ADV)(ADJ)(M) (N) 一(ADV)小(Vi) 根(M)鐵絲(N) 一(ADV)小(ADJ) 根(M)鐵絲(N) 2 (ADV)(Vi)(Vt) (Vi) (ADV)(ADJ)(Vt) (N) 很(ADV)容易(Vi) 發生(Vt)危險(Vi) 很(ADV)容易 (ADJ)發生(Vt) 危險(N) 3 (ADV)(Vi)(T) (Vi) (ADV)(ADJ)(N) 很(ADV)大(Vi)的 (T)方便(Vi) 很(ADV)大的 (ADJ)方便(N) 4 (ADV) (Vi) (T) (N) (ADV) (ADJ) (N) 很(ADV)好(Vi) 的(T)傳達者(N) 很(ADV)好的 (ADJ)傳達者(N)
5 (ADV) (Vi) (T) (ADV) (ADJ) (T) 最(ADV)忠實(Vi)的 (T) 最(ADV)忠實(ADJ) 的(T) 6 (Vi) (N) (T) (N) (ADJ) (N) (T) (N) 傳統(Vi)造形(N) 的(T)布袋戲偶 (N) 傳統(ADJ)造形 (N)的(T)布袋戲 偶(N) 7 (Vi) (Vt) (T) (N) (ADJ)(ADJ)(T) (N) 熱鬧(Vi)喧譁 (Vi)的(T)北管曲 (N) 熱鬧(ADJ)喧譁 (ADJ)的(T)北管 曲(N) 8 (Vi) (T) (N) (ADJ) (N) 快樂(Vi)的(T)
成長(N)
快樂的(ADJ)成長 (N)
9 (Vi) (T) (N) (Vi) (ADJ) (N) (ADJ)
正派(Vi) 的(T) 腳色(N) 眉清目 秀(Vi) 正派的(ADJ) 腳 色(N) 眉清目秀 (ADJ)
10 (Vi) (T) (Vt) (ADV) (Vt) 穿針引線(Vi)的 (T)繡(Vt)
穿針引線的(ADV) 繡(Vt)
参、中高年級文本理解測驗
收集國立編譯館民國 78 年出版國小四、六年級國語科教科書文本,依建 置之語詞重複指標分析文章及文體類別(記敘文、非記敘文)、文章長短及年 級篩選所欲測驗文本共 8 篇,編製中高年級文本理解測驗題本。測驗時間為 40 分鐘,合計 44 題四選一單選題,適用對象為國小四年級和六年級的一般 生,其目的在於評量學生閱讀能力與文章重複語詞指標的關聯性及測出不同 能力受試學生在各類型題目中的答題情形。其答題情形,待後續分析探討。 此篇數過少,並無考慮到文本的多樣性,結果無法達顯著,因此測驗分數不 足以作推論性的解釋。 一、本研究所使用之中高年級文本理解測驗題本採專家效度。延請三位國立 台中教育大學教授,七位年資達 10 年以上資深現職國小教師共同編審,編製 嚴謹,因此有良好的表面效度與內容效度。Cronbach α 值為.85,信度高,具 穩定性及一致性,測驗題本具有較佳之內部一致性,測驗難度適中,具有相 當好的鑑別度。詳細數值參閱郭伯臣等(2013)研發之中高年級文本理解測驗 技術報告,陳建宏(2013)。 二、測驗理論:以解釋測驗分數意義的理論學說,可以分成兩大學派:一為 「古典測驗理論」(classical test theory,簡稱 CTT)(Allen & Yen,1979), 另一為「試題反應理論」(item response theory 簡稱 IRT)(Crocker & Algina, 1986; McDonald, 2000; McClure, & Suen, 1994)。(一)古典測驗理論
古典測驗理論主要是以整份測驗(或試卷)的觀點,來解釋測驗分數的涵 義。因此,它對學生或受試者的測驗分數的看法,是以各試題得分加總之後的 總分做為代表,缺乏理論基礎,須發展參照標準才能解釋分數。所以,它提出 下列的數學假說,以作為其主要的理論學說依據(公式 3)。
X=t+e (公式3) 即χ為測驗分數,t為真實分數(即代表該測驗所欲測得學生的真正能力或潛 在 特質的部分),e為誤差分數(即代表該測驗無法測得學生的真正能力或潛在 特質的部分)。古典測驗理論中的難度(item difficulty),即代表該題的通過率,也 就是所有受試者中答對該題的百分比,以數學式(公式4)表示: N n P i i (公式 4) 其中 Pi是答對題項 i 的百分比,N 是所有受測人數,ni是答對該題的人數。 通過率值愈大表示愈多人答對該題,即該題愈簡單。 而古典測驗理論中的鑑別度(item discrimination)中,一個有鑑別度的試題應 該與整個測驗的走向是一致的,也就是說測驗分數高的受試者要比測驗分數低 的受試者答對較多試題,否則此題目並不能反應出受試者的實力,以數學式表 示試題鑑別度如下: D = PH-PL (公式 5) PH:高分組受試者在個別試題上通過人數的百分比 PL:低分組受試者在個別試題上通過人數的百分比 基本上 D 值愈大,表示試題愈能鑑別出高、低分組的受試者,並且個別試 題與測驗總分的一致性愈高 (余民寧,2009) 。D 值介於-1.00 到+1.00 之間, D 值愈大,表示鑑別度愈大; D 值愈小,表示鑑別度愈小; D 值為 0,表示沒 有鑑別度,可能是因為試題太容易或太艱難,使得所有人均答對或均答錯,或 是題目不清; 若 D 值為負的,表示低分組學生答對百分比高於高分組,具有反 向作用,該試題應淘汰。 其原因可能是因為能力低的學生胡亂猜測,結果碰巧 猜對;能力高的學生看不懂題目、會錯意、粗心大意。一般而言,鑑別度以 0.25 以上為標準,高於 0.4 為優良試題。 CTT 中,接受同一測驗的所有受試者測量信度都相同。其優點模式易理解, 能力與試題參數容易計算;缺點則為測量標準誤假設不合理,受試者程度受題
目特性影響,題目參數受受試者特性影響。在古典測驗理論學說的看法下,我 們必須使用一堆試題(通常即是一整份試卷),才能測得(或估計)學生的真 正能力或潛在特質,單獨一道試題是做不到的。 (二)試題反應理論 試題反應理論主要是以個別試題的觀點,來解釋測驗分數的涵義。它認為 學生在某一試題上的表現情形,與其背後的某種潛在特質(即能力)之間具有 某種關係存在,該關係可以透過一條連續性遞增的數學函數來加以表示和詮 釋。測量精確度(訊息量)隨著受試者能力以及所接受的題目特性而不同。 試題反應理論的優點為具受試者能力估計不變性、題目參數估計不變性、測 量精準度的概念較合理,然而數學假說則是嚴謹、深奧、難懂、不易受大眾的瞭 解和接受、雖適合大樣本情境下的測驗使用、但學習者卻需要具備雄厚的數學與 電腦的背景知識。IRT模式包含三個試題參數,分別為:鑑別度參數(item discrimination parameter),表示該試題能否區別出學生能力高低的程度;難度參 數(item difficulty parameter),表示該試題是否困難或容易作答的程度;猜測度 參數(pseudo-chance parameter),表示該試題被低能力學生隨機猜題而猜中的程 度。茲舉一個典型的『三參數對數型試題反應模式』(three-parameter logistic model,簡稱3PL)為例,說明學生的能力與試題特徵曲線之間的關係如下: ) ( ) ( 1 ) 1 ( i j i i j i b a b a i i ij e e c c P , (公式 6) 其中j為考生j的能力,bi是試題i的難度,而Pij是受測者答對某個題目的機率。 其中ai是試題i的鑑別度,其中ci是試題i的猜測率,這裡要特別注意的是此猜對率 是指能力極低者猜對該題的機率,隨著能力的提高,答對該題的機率仍然會提 升,但可以提升的機率範圍僅有1ci。一般而言,鑑別度值a介於0~2之間為多, 而以.8~1.25之間最為有效;難度b大部分介於 -3~3之間,值愈高難度愈難;猜測
度c則宜為0≦C< 1選項數(王寶墉,1995)。相對於古典測驗理論,試題反應理 論應具有:(1)能力估計不變性;(2)具有題目參數估計不變性,以及(3) 測量精準度較合理;(4)應用層面較廣等優點(余民寧,2009)。
(三) CTT 與 IRT 之難度(item difficulty)的差異:
1. CTT 的 item difficulty 是樣本依賴 (sample dependent),因此不同受測 者樣本的 item difficulty 會有所不同。而 IRT 不受樣本特性的影響,對 任何受測者而言,項目越容易作答,即表示項目難度越低。 2. CTT 的項目難度是看 p 值,p 值越大表示試題越簡單,p 值越小表示 試題越困難,這概念與常理的想法相反。但 IRT 的項目難度是看 b 值,b 值越大表示試題越困難,b 值越小表示試題越簡單,這概念與常理的想 法符合。 本研究皆以古典測驗理論(CTT)及試題反應理論〈IRT〉方式,解釋測驗 分數意義。
肆、受試者能力分析
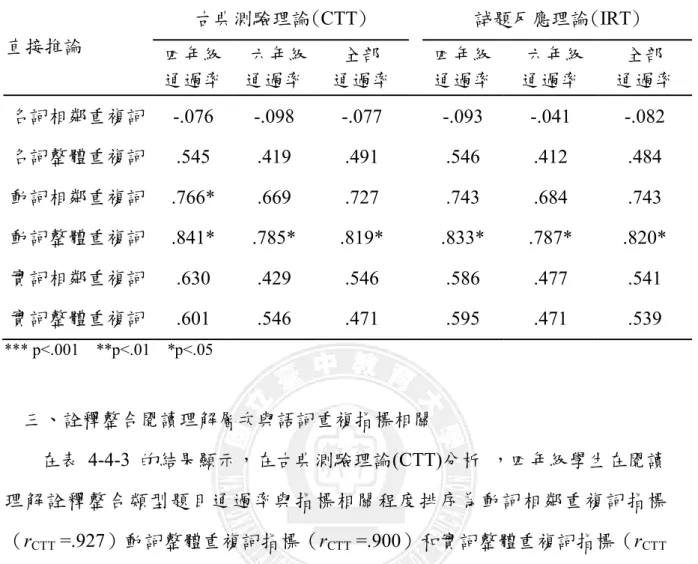
一、受試者閱讀理解能力分析 在受試學生能力分析中,將中高年級文本理解測驗題本 8 篇文章,依年級 分成四年級文本 4 篇群組、六年級文本 4 篇群組及全部 8 篇文本群組,並分別 在 CTT、IRT 的計分方式下,以獨立樣本 t 檢定檢視四、六年級的受試學生在 不同年級文本測驗之通過率是否達顯著差異。研究結果顯示六年級受試學生在 文本理解能力上優於四年級受試學生,符合錡寶香(1999)研究發現,國小四年 級和六年級學童的語意能力可以預測解釋學童的閱讀理解能力達 63%,李俊仁 (2011)表示,閱讀能力隨年紀漸增。詳細數值見陳建宏(2013)。 二、受試者通過率與閱讀理解層次題型之相關 在受試者與直接提取、直接推論、詮釋整合及檢驗評估閱讀四層次的相關 研究中,結果可知,直接提取、直接推論、詮釋整合及檢驗評估閱讀四層次皆與受試者的通過率達高度相關,亦即四年級學生通過率高的閱讀層次題型,六 年級通過率亦高,全部學生對此型題目通過率亦相對提高,結果具一致性。
肆、電腦工具
研究資料使用 MATLAB 撰寫程式、SPSS for window 軟體發展指標分數及 分析資料。 一、MATLAB 程式撰寫工具 本研究使用 MATLAB 程式撰寫工具建置重複語詞指標,並發展指標於文 章中相鄰句及整篇文章凝聚力自動化計分模式。 二、SPSS 統計套裝軟體 本研究量化資料採用 SPSS 統計套裝軟體進行分析,統計方法包括描述性 統計、積差相關與迴歸分析,及 T 檢定。
第四節 線上文本自動化分析系統
本研究發展文本自動化分析語詞重複性指標,並發展線上文本自動化分析 系統,本研究參考 Coh-Metrix 分析建置的指標應用於中文領域,結合中文詞彙 與文章之特性,使用者可以透過系統進行文本自動化分析以了解文本的重複性 指標,幫助讀者或使用者估計評估文本難易度,並幫助讀者選擇適合程度的文 本,進行閱讀,以對讀者閱讀理解能力有所增進,同時對國內整體閱讀能力的 提升有所助益。壹、文本自動化分析系統介面介紹
圖 3-4-1 為文本自動化分析系統登入介面,使用前須先申請帳號、密碼, 方能進入系統使用。
貳、線上文本自動化分析系統-文本輸入與指標勾選介面
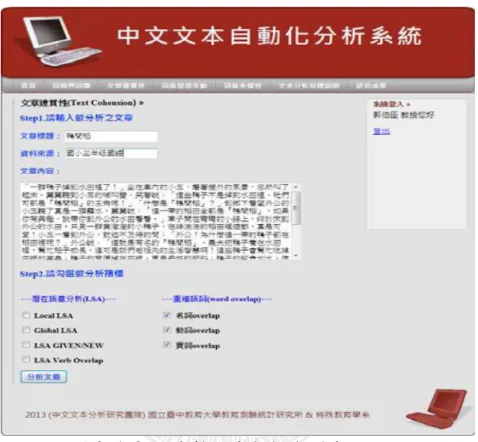
在線上文本自動化分析系統-文本輸入與指標勾選介面中圖 3-4-2,操作步 驟一:輸入欲分析文章基本資料,操作步驟二:輸入欲分析文章內容(不含標 題),操作步驟三:選擇欲分析的衡量指標,操作步驟四:分析指標。
参、線上文本自動化分析系統-文本自動化分析結果
文本自動化分析結果見圖 3-4-3,本研究頁面範例文章為「鴨間稻」, 經系統分析後其文章連貫性各指標結果如下:名詞相鄰重複詞:0.0000,動詞 相鄰重複詞:0.0488、實詞相鄰重複詞:0.1220、名詞整體重複詞:0.0157、動 詞整體重複詞:0.0064、實詞整體重複詞:0.0242。 圖 3-4-3 文本自動化分析結果第五節 研究對象與限制
本研究於文本理解測驗方式採紙筆測驗。選取之對象為大台中地區四年級 和六年級的學童。 一、第一次預試對象及樣本:施測對象為臺中市某國小四年級學生 30 人,六 年級學生 30 人。預試施測閱讀理解測驗題本為 8 篇 53 題,刪除鑑別度不良 題目後,剩下 44 題。二、正式施測對象:受試樣本取自臺中市 8 所學校 33 班學生,有效樣本為四 年級學生 371 人、六年級學生 425 人,共計 796 人。現今學校採 S 型編班, 顧學童的先備知識與學習能力成常態。 三、受試對象為常態學習學生,排除智能障礙及情緒障礙特殊生,當日請假 學生不予補測。 本研究採用立意及便利抽樣,以研究者方便實施測驗之台中市六年級及四 年級兒童作為受試對象,由於取樣並非隨機抽樣,受限於單一地區,因此研究 結果並不適合推論到其他地區兒童身上。
第六節 資料處理與分析
本研究資料使用 SPSS for Window 軟體發展指標分數及分析資料。壹、SPSS for Window 軟體
本研究量化資料採用 Spss for Window 進行分析,統計方法包括描述性統 計、積差相關與階層式迴歸,各資料處理分析說明如下。 一、描述性統計 描述指標分數與文本間,以及閱讀理解測驗之結果,如平均值、標準差。 二、皮爾遜積差相關(Pearson product-moment correlation)本研究主旨在探討重複語詞指標與閱讀理解的相關、閱讀理解層次與學生 閱讀力的相關、重複語詞指標與文本年級間的相關,相關性越高,表示成效越 好。本研究探討項目如下: (一)指標分數與文本年級之間的相關 (二)受試學生在中高年級閱讀理解測驗通過率相關 (三)指標分數與受試學生在中高年級閱讀理解測驗通過率相關 (四)檢視指標與閱讀理解層次之相關程度 三、一般迴歸分析
本研究使用回歸分析探討項目如下:
(一)指標變項預測文本年級模式回歸分析
(二)不同年級學生在中高年級文本理解測驗通過率分析 (三)不同年級高低分組在閱讀理解層次迴歸分析
第四章 研究結果與討論
本研究成果可分為兒童語料庫文本語詞重複出現趨勢分析、指標分數預測 文本適讀年級、受試學生題本通過率與指標分數分析、閱讀理解層次題型與受 試學生能力之相關、語詞重複指標之相關,茲研究成果分別敘述如下。第一節 兒童語料庫文本語詞重複出現趨勢分析
本研究目的為建置文本語詞重複出現自動化分析指標,以進行自動化文本 特徵分析,並探討國小學童教科書-國語科、社會領域、自然領域中,語詞重複 出現(動詞、名詞及實詞)對文章的共同參照凝聚力的影響。本研究根據國外的 線上文本分析器 Coh-Metrix 發展文本自動化分析指標並發展線上文本自動化分 析系統,其文本自動化分析之研究結果如下:壹、各科相鄰句凝聚力趨勢(local cohesion)
表 4-1-1 為國語、自然、社會不同年級文本凝聚力(重複相鄰句-動詞)之分 數,圖 4-1-1 為其趨勢。其結果顯示在國語文本,一年級動詞重複凝聚力相對 比二年級高,是因為讀者先備知識不足,需要語詞重複出現幫助理解。自然領 域動詞的局部重複凝聚力顯示,一~六年級並無太大差距。社會科文本分析則 呈現隨著年級增高而下降。動詞通常和文本的事件、動作及狀態有顯著的關係, 當動詞重複時,文本更能連貫事件結構。 表 4-1-1 各年級各科動詞相鄰重複詞指標數值 一年級 二年級 三年級 四年級 五年級 六年級 國語指標數值 0.1078 0.0516 0.0328 0.0370 0.0398 0.0349 社會指標數值 0.0361 0.0306 0.0283 0.0201 自然指標數值 0.0598 0.0634 0.0674 0.0680 0.0554 0.06560.0000 0.0200 0.0400 0.0600 0.0800 0.1000 0.1200 一年 級 二年 級 三年 級 四年 級 五年 級 六年 級 國語 社會 自然 圖 4-1-1 各年級各科動詞相鄰重複詞指標趨勢圖 表 4-1-2 為不同年級文本凝聚力(重複相鄰句-名詞)之分數,圖 4-1-2 為趨 勢分析,結果顯示一~二年級中,國語科及自然領域的名詞相鄰句重複凝聚力 下降明顯,顯示一~二年級讀者先備知識較低,所以需要較高重複來幫助理解。 自然領域名詞相鄰句重複凝聚力於三年級稍提升,推論是三年級獨立成自然領 域,讀者對自然方面的先備知識不足,所以需要較高重複來幫助理解。 表 4-1-2 各年級各科名詞相鄰重複詞指標數值 一年級 二年級 三年級 四年級 五年級 六年級 國語指標數值 0.0219 0.0035 0.0025 0.0009 0.0009 0.0005 社會指標數值 0.0028 0.0071 0.0012 0.0004 自然指標數值 0.0042 0.0024 0.0075 0.0065 0.0085 0.0075 0.0000 0.0050 0.0100 0.0150 0.0200 0.0250 一年 級 二年 級 三年 級 四年 級 五年 級 六年 級 國語 社會 自然 圖 4-1-2 各年級各科名詞相鄰重複詞指標趨勢圖 表 4-1-3 為不同年級文本凝聚力(重複相鄰句-實詞)之分數,圖 4-1-3 為趨 勢分析,研究結果顯示實詞的相鄰句凝聚力分數皆高於名詞與動詞的相鄰句凝 聚力。自然領域的相鄰句凝聚性高於社會領域及國語科,顯示出自然領域的學
習藉由實驗操作及結果歸納重複描述,協助學生理解學習。從社會領域的實詞 相鄰句凝聚力中,可看出三、四年級高於五、六年級。 表 4-1-3 各年級各科實詞相鄰重複詞指標數值 一年級 二年級 三年級 四年級 五年級 六年級 國語指標數值 0.2808 0.1760 0.1512 0.1428 0.1469 0.1314 社會指標數值 0.1705 0.1779 0.1487 0.1365 自然指標數值 0.2405 0.2202 0.2595 0.2318 0.2687 0.2672 0.0000 0.0500 0.1000 0.1500 0.2000 0.2500 0.3000 一年 級 二年 級 三年 級 四年 級 五年 級 六年 級 國語 社會 自然 圖 4-1-3 各年級各科實詞相鄰重複詞指標趨勢圖
貳、整篇文章凝聚力分析(global cohesion)
表 4-1-4 是不同年級文本整體凝聚力(動詞)之分數,圖 4-1-4 為趨勢分析, 其結果顯示國語科在一~二年級重複凝聚力下降明顯。自然領域動詞文章整體間 重複凝聚性稍提升,是因為一、二年級自然包含生活領域課程,而三年級獨立 出自然領域,所以需要較多重複語詞形成連貫性來幫助理解。社會科動詞文章 整體間重複凝聚性則隨著年級升高而下降。 表 4-1-4 各年級各科動詞整體重複詞指標數值 一年級 二年級 三年級 四年級 五年級 六年級 國語指標數值 0.0604 0.0129 0.0045 0.0035 0.0025 0.0023 社會指標數值 0.0047 0.0050 0.0026 0.0016 自然指標數值 0.0049 0.0048 0.0160 0.0143 0.0076 0.00760.0000 0.0100 0.0200 0.0300 0.0400 0.0500 0.0600 0.0700 一年 級 二年 級 三年 級 四年 級 五年 級 六年 級 國語 社會 自然 圖 4-1-4 各年級各科動詞相鄰重複詞指標趨勢圖 表 4-1-5 為文本整體凝聚力(名詞)之分數,圖 4-1-5 為趨勢分析,結果顯示 國語科名詞文章整體重複凝聚力隨級別漸高而降低。自然科以三年級名詞文章 整體重複凝聚力相對較高。 表 4-1-5 各年級各科名詞整體重複詞指標數值 一年級 二年級 三年級 四年級 五年級 六年級 國語指標數值 0.0894 0.0241 0.0124 0.0084 0.0061 0.0063 社會指標數值 0.0160 0.0203 0.0075 0.0077 自然指標數值 0.0191 0.0134 0.0566 0.0382 0.0323 0.0218 0.0000 0.0200 0.0400 0.0600 0.0800 0.1000 一年 級 二年 級 三年 級 四年 級 五年 級 六年 級 國語 社會 自然 圖 4-1-5 各年級各科名詞相鄰重複詞指標趨勢圖
表 4-1-6 為文本整體凝聚力實詞指標分析,圖 4-1-6 為趨勢圖,分析結果 顯示實詞的文章整體凝聚力高於名詞與動詞的文章整體凝聚力。 表 4-1-6 各年級各科實詞整體重複詞指標數值 一年級 二年級 三年級 四年級 五年級 六年級 國語指標數值 0.1560 0.0418 0.0213 0.0151 0.0105 0.0105 社會指標數值 0.0247 0.0266 0.0113 0.0105 自然指標數值 0.0255 0.0191 0.0673 0.0493 0.0406 0.0338 0.0000 0.0200 0.0400 0.0600 0.0800 0.1000 0.1200 0.1400 0.1600 0.1800 一年 級 二年 級 三年 級 四年 級 五年 級 六年 級 國語 社會 自然 圖 4-1-6 各年級各科實詞相鄰重複詞指標趨勢圖 綜合討論: 本研究主要目的為建置自動化文本重複性指標,包括實詞重複指標,動詞 重複指標,名詞重複指標,以分析現有國小教科書中,國語科、自然科和社會 科語詞重複現況,了解教科書中凝聚性趨勢。其結論如下: (一)低年級重複凝聚力較高,對先備知識較不足的低年級可以協助理解 閱讀文本。一年級各科凝聚力皆較為突顯,與其課文邊內容簡短且重複語 詞多為主要原因。 (二)三、五年級自然領域,重複凝聚性較高,而九年一貫年段階段中, 三、五年級各為一新階段,重複語詞形成較強的連貫性,可以加強不熟悉 的階段領域課程,以連結舊經驗。
(三)六年級所有科別重複凝聚性皆低,顯示文本連貫性低,因此文本難 度相對較高。然而凝聚力較低之文本,若讀者先備知識夠多,則可以刺激 讀者產生推論極更多的解釋,反之,會因缺乏線索,較難連接文本與讀者 的想法。 (四)在重複語詞指標中,自然指標數值>社會指標數值>國語指標數值,其 與文章在標題或段落前是否有主題句相關(Gernsbacher,1990),再加上中文 教科書中,自然領域編排方式為在每一小節前,加入實驗關鍵字或實驗名 稱,並於實驗流程及圖片中重複單元中之關鍵字,而增加了凝聚力數值。 社會領域則於每篇小單元加入標題,再詳加敘述,亦提升了全篇的凝聚力。 本研究建置電腦自動化文本分析指標,可觀察出現今國小教科書國語、自 然與社會科語詞重複特徵和趨勢,提供學生在課程學習中,掌握凝聚性較低之 閱讀關鍵,加強複習或增加閱讀量,擴充先備知識,以提高學習能力。