自我回饋方式與休息時間對動態決策與情境覺察之影響
111
0
0
全文
(2) 自我回饋方式與休息時間對動態決策與情境覺察之影響 The Effects of Self-feedback Aids and Resting Time on Dynamic Decision Making and Situation Awareness 研 究 生:林承儀. Student:Cheng-Yi Lin. 指導教授:洪瑞雲. Advisor:Dr. Ruey-Yun Horng. 國 立 交 通 大 學 工業工程與管理學系 碩 士 論 文 A Thesis Submitted to Department of Industrial Engineering and Management College of Management National Chiao Tung University In Partial Fulfillment of the Requirements for the Degree of Master of Science In Industrial Engineering July 2012 Hsinchu, Taiwan, Republic of China. 中華民國一○一年七月.
(3) 自我回饋方式與休息時間對動態決策與情境覺察之影響 學生:林承儀. 指導教授:洪瑞雲博士. 國立交通大學工業工程與管理學系碩士班 摘要 本研究的目的在探討自我回饋方式與休息時間長短對動態決策的影響。實驗 中以電腦遊戲模擬淨水槽排水系統的動態決策作業,共有 180 位研究所或大學生 被隨機分派至 3(手寫筆記方式進行自我回饋、放聲思考方式進行自我回饋、無 自我回饋) × 2(0.5 分鐘休息時間、2 分鐘休息時間)的六組實驗情境中,請 他們在五回合的遊戲中盡力得到較好的表現。結果發現,兩種自我回饋方式與較 長的休息時間都有助於動態決策績效的進步,且二者有交互作用。在決策間有休 息 2 分鐘的情況下,放聲思考自我回饋方式的學習效果在第三回合即出現,但後 續持續進步的現象比手寫筆記的自我回饋方式小。在決策間有休息 2 分鐘時,手 寫筆記自我回饋組的效果在第四回合才出現,但持續進步,在第五回合時成為所 有組別中表現最好的一組。但就動態決策情境模式的覺察而言,自我回饋與休息 卻沒產生明顯的影響。. 關鍵字:動態決策、自我回饋、休息時間、情境覺察. I.
(4) The Effects of Self-feedback Aids and Resting Time on Dynamic Decision Making and Situation Awareness. Student:Cheng-Yi Lin. Advisor:Dr. Ruey-Yun Horng. Department of Industrial and Management National Chiao Tung University Abstract This study investigated the effect of self-feedback aids and resting time on dynamic decision making (DDS) performance and situation awareness. The DDS task was simulated by a computer game “Water Purification Plant.” A total of 180 college and graduate students were assigned to the 3 (self-feedback aids:write notes, think aloud, no self-feedback) × 2 (0.5-min or 2-min resting time) experimental conditions and were asked to do their best in the task. Results showed that self-feedback aids and longer resting time might improve DDS performance but only with longer resting time. With 2-min resting time, participants in the “think aloud” self-feedback condition outperformed the no-feedback group at the 3rd practice trial and performance stabilized thereafter. With 2-min resting time, participants in the “write notes” self-feedback condition outperformed the no-feedback condition at the fourth practice trial and they also outperformed the “think aloud” condition at the fifth trial. II.
(5) However, with only 5 practice trials, there was no sign that participants’ situation awareness improved with the aids of self-feedback or rest.. Keywords:dynamic decision making, self-feedback aids, rest, situation awareness.. III.
(6) 誌. 謝. 在交大念研究所三年,我終於要畢業了。與大學時最大的不同,就是我滿載 而歸的畢業,這三年裡我養成了很多大學時打混摸魚下無法建立的人生觀點與做 學問的態度,也發現所有成長的首要條件都是自己要先懂得抓住機會,抓住機會 獲得知識、表現自己、挑戰成規,做學問的過程中會遇到好多走錯路的挫敗,但 這些挫敗都是鍛鍊自身看法與態度的好機會,非常感謝交大給我很多表現與發現 自己的機會。 感謝論文過程中參加我實驗的參與者,你們的參與都是我珍貴且的重要資產, 沒有你們的實驗資料我的假設將無以驗證,感謝你們在實驗中盡力的表現。 感謝我的指導教授洪瑞雲博士,讓我很深刻的瞭解做學問嚴謹的程度。選擇 洪老師指導碩士論文是一件很棒的事情,透過每次討論你都可以更了解作研究實 事求是的精神與態度,我雖無法完全學到老師的精隨,但光是碩士生涯對唸書與 論文的訓練就足夠我一生受用,謝謝洪老師。 再來要謝謝一路陪伴我的實驗室夥伴們,人數眾多我就不逐一點名了,雖然 你們非常期待我寫一篇很不一樣的誌謝,不過我想,跟你們的糾葛不是三言兩語 就能算清楚,與你們一起走過的酸甜苦辣我還是私下感謝就好(其實是我想要留 空間謝謝我自己)。期待未來的生活我也能有機會支持你們完成碩士學業,無論 是實質上的幫助或精神上的支持。 感謝我自己,在當兵的時候還提起精神打拼考上研究所、上了研究所後認真 經營碩士生涯、努力學習並勇於朝自己不熟悉的領域去了解新知,讓我現在有一 個圓滿的結束,以下是我的論文,是我努力過後的果實,到底有何種特別的發現, 觀迎您繼續看下去…。 林承儀 民國一0一年七月於交通大學. IV.
(7) 目錄 中文摘要............................................................ I 英文摘要........................................................... II 誌謝............................................................... IV 目錄................................................................ V 表目錄............................................................ VII 圖目錄........................................................... VIII 第一章. 導論........................................................ 1. 第二章. 文獻探討................................................... 10. 第三章. 方法....................................................... 36. 第四章. 結果....................................................... 49. 第五章. 結論與討論................................................. 74. 參考文獻........................................................... 81 附錄一. 排水作業各項參數........................................... 85. 附錄二. 實驗指導語................................................. 88. 附錄三. 淨水槽排水作業介面......................................... 90. 附錄四. 自我回饋提示............................................... 92. 附錄五. 問卷....................................................... 98. 附錄六. 排水作業情境模型........................................... 99 V.
(8) 附錄七. 錯誤情境模型.............................................. 100. 附錄八. 實驗參與者發現的可用策略.................................. 101. VI.
(9) 表目錄 表 3–1. 評分者間信度............................................................................................ 44. 表 4–1. 第一回合動態決策作業分數之平均與標準差........................................ 50. 表 4–2. 第一回合動態決策作業表現之變異數分析表........................................ 51. 表 4–3. 五回合動態決策作業分數之平均與標準差............................................ 52. 表 4–4. 五回合動態決策作業分數之變異數分析表............................................ 53. 表 4–5. 練習與自我回饋方式交互作.................................................................... 57. 表 4–6. 練習與休息時間交互作............................................................................ 57. 表 4–7. 自我回饋方式 × 休息時間長短 × 練習敘述統計表............................ 59. 表 4–8. 第 2 ~ 5 回合動態決策作業分數之變異數分析表.............................. 61. 表 4–9. 第 2、3、4、5 回合動態決策作業分數之變異數分析表...................... 63. 表 4–10. 各實驗情境參與者於情境模型中人數分布情形.................................. 68. 表 4–11. 各實驗情境參與者所掌握情境模型之平均得分表現 .......................... 68. 表 4–12. 參與者於情境模型 Basic 1、Basic 2、Detail 5 項填答之變異數分析表. ...................................................................................................................................... 70 表 4–13. 各實驗情境參與者提及的錯誤情境模式之人數分布情形.................. 72. 表 4–14. 各實驗情境參與者所提及可用策略之人數分布情形.......................... 72. VII.
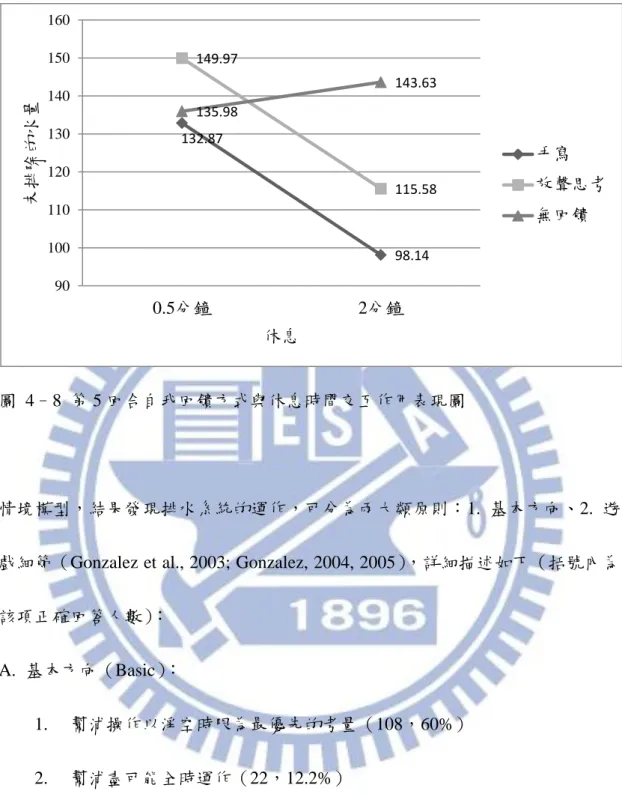
(10) 圖目錄 圖 3–1. 排水作業電腦界面與水槽各層之間路徑圖............................................ 38. 圖 3–2. 水槽編號.................................................................................................... 42. 圖 3–3. 實驗流程圖................................................................................................ 45. 圖 4–1. 排水作業學習曲線.................................................................................... 54. 圖 4–2. 自我回饋方式與休息時間交互作用表現圖............................................ 55. 圖 4–3. 練習與自我回饋方式交互作用................................................................ 56. 圖 4–4. 練習與休息時間長短交互作用................................................................ 56. 圖 4–5. 第 2~5 回合練習與休息時間的交互作用.............................................. 64. 圖 4–6. 第 2~5 回合練習與自我回饋方式交互作用.......................................... 64. 圖 4–7. 第 3 回合自我回饋方式與休息時間交互作用表現圖............................ 65. 圖 4–8. 第 5 回合自我回饋方式與休息時間交互作用表現圖............................ 66. VIII.
(11) 第一章 導論 研究背景與動機 人的一生中隨時都在做大大小小的決策,有些決策只是為了解決一時的問題, 有的決策則左右了未來人生方向。除了個人需要面臨決策之外,眾人組成的團體 也會面臨達成共同目標需要多項決策,這可能會經過很多細部的決策過程,每一 個細部決策就像是大結構的螺絲釘,大結構是否可以維持良好營運或者完成特定 目標,便取決於保持良好的決策品質,現今社會上大規模的公司團體與組織就是 需要良好細部決策品質所建立起來的大結構。雖然人們無時不刻處於需要做決策 的生活情境之中,卻未必此因而善於決策,反倒是為了如何做出好的決策而困擾 不已。 生活中常見的決策例子,其中一種即為使用交通工具到達目的地的行為,從 發動交通工具上路的開始就是一連串判斷路況後下決策的過程,但層出不窮的交 通事故也顯示人在交通方面的決策並不因為天天使用交通工具而有完美的決策 品質,交通事故的發生除了法規需要持續的修正與改進之外,人對於交通環境的 知識不夠完整可能也是主要原因之一。 人為了達成目標而從多個可能的行為中選取最適當的選項來行動稱之為決 策,若決策作業中的情境線索是固定不變或不會被其他因素所干擾,決策與決策 之間也無影響關係的單一決策過程,被稱為單一決策或靜態決策(Kanehman & Tversky, 1979)。但生活中所要面臨的決策通常並不單純,某些目標的達成可能 1.
(12) 需要很多步驟,絕不僅止於參考固定情境就可達成,因為情境通常都是隨時間演 進而有變化,且達成目標的過程中,每一個被決定的行為在未來都會形成後果, 這個後果會成為下一個決策的參考基準而持續循環直到目標達成,這種持續觀察 上一次行為後果來衡量下次行為直到達成目標的決策,被稱為動態決策。 動態決策的研究在許多領域中被討論,從不同的面向探討人在動態決策中的 表現。例如認知領域中,有學者致力於分析人在動態決策中的認知機制或心理歷 程;又如學習行為的領域裡,有學者試圖架構人們動態決策中學習行為的模型, 並透過學習行為的模型探究增進學習效率的方法。本研究的目的即為由學習的觀 點來檢視動態決策中影響人們認知過程的相關因素。 在動態環境中做決策,人必須從動態環境中篩選出決策所需要參考的情境線 索,再將這些線索整理出足以成為決策參考依據的有用訊息,這樣的過程需要用 到認知資源中的注意力、工作記憶與長期記憶理的知識,透過這些認知資源我們 才能將情境線索解讀成有用的訊息,這樣的認知歷程稱作情境評估(situation assessment) ,人經過對環境的情境評估後,便可將了解的現況配合決策並對未來 情境做預測,Endsley(1995)將此動態決策的認知歷程稱為情境覺察(situation awareness) ,情境覺察分成三個階段:知覺、理解、預測。其中知覺即為抓取外 在系統環境中的情境刺激,篩選出決策需要使用的線索。當決策需要使用的線索 已經篩選出來之後,人就要將這些訊息加以解讀與整理以了解外在系統運作的樣 貌,這就是理解最主要的認知活動。預測即是當人對於外在系統的現況掌握了, 2.
(13) 就有有能力推估在此情境下可能的決策行為與後果,並從眾多可能的行為中選取 最適合的方案。這三階段並非逐一進行,甚至可能是同時進行的,只是三階段之 間有互相影響的情況,前一階段處理的好壞會影響後一階段的效果,雖然先前階 段處理的好並不代表最後的動態決策績效表現就會很好,但若先前階段處理得不 好則最後動態決策績效卻很難有好的表現。 Osman(2010)經由文獻歸納提出動態系統的監視與控制架構(Monitoring & control(MC)framework)來解釋人在動態系統中做決策時的認知歷程。在 MC 架構下的動態決策行為包括:監視、控制、追蹤。其中監視是指人觀察動態情境 運作歷程,目的在於了解外在情境現況;控制是利用監視歷程所得到的資訊來判 斷下一步行為;追蹤則是決策者持續觀察自己前一個決策行為所產生的後果,也 稱為自我監控,並將控制與監督串起形成遞迴的循環。Osman 認為人對環境的不 確定感受是影響這個架構最主要的因素,若人對情境的不確定感較高表示對於環 境不熟悉,則花費在監控上的認知資源比重將會擴大,較無餘力整理訊息或對情 境線索解讀不深入,若人對情境的不確定感較低表示對環境熟悉,對於情境上的 辨認較不占認知資源,則人較有餘裕解讀情境線索並判別較佳的決策行為。 從 Osman(2010)的 MC 架構中可發現與 Endsley(1995)的情境覺察相似 之處,也就是人在動態系統中對情境的認識,對決策績效有很大的影響,而人對 情境辨認是否正確,則取決於決策者是否能透過學習階段來建立該動態系統完整 的知識架構。 3.
(14) 人在動態系統中掌握情境模式的認知歷程,可由實例學習、假設驗證、自我 回饋等三個角度來探討(Osman, 2010)。 實例學習的觀點將動態決策作業視為以實例為基礎去掌握法則的一種學習, 認為人處於不熟悉的決策情境時會不斷嘗試錯誤,並且依賴眾多嘗試中成功的例 子當作學習參考,再從這些成功的例子歸納出可能的法則。Gonzalez 等人(2003) 以淨化水槽排水作業系統(water purification plant)的動態決策作業,紀錄實驗 參與者為期三天(一天 6 回合)的學習曲線,並藉由電腦程式調整識別 (recognition) 、判斷(judgment) 、選擇(choice) 、回饋(feedback)等四個機制 來模擬人在以成功案例為學習典範的學習中所表現的學習機制。他們發現決策回 饋的有無對於程式模擬人的學習曲線影響最明顯,電腦程式在有回饋的控制下學 習曲線快速進步並達到一個穩定階段,但當電腦程式設定在無回饋的情況下反而 與人的學習曲線最接近,顯示人在執行動態決策作業的過程中鮮少利用自我回饋 的方式來幫助自己學習。因此本研究預測若在動態決策作業中提醒參與者進行自 我回饋能提升學習效果,且動態決策作業的績效比沒有被提醒進行自我回饋的參 與者要好。 由假設驗證的觀點而言動態決策被視為一連串假設驗證的行為,人在動態系 統中會觀察現況與假設未來狀態並做出行動,行動後所造成的後果可用於驗證先 前行為是否正確,並再次做出行為來修正未來情境,此過程持續循環直到達成目 標。然而 Sweller(1988)由他的認知負荷理論推測,問題解決的學習即是一種 4.
(15) 目標導向的假設驗證行為,人進行假設驗證的行為需耗費認知資源,會妨礙學習 的成果。Sweller 透過重複反思數學解題方法的實驗,發現學生在學習解題(假 設驗證)時若加入額外的認知負荷(如,指派特定目標)比沒有加入額外認知負 荷的學習效果要差。這是因為在認知負荷高的情況下人沒有餘力探究解題情境線 索,因此也無法將重要的情境線索組織成完整的知識架構,導致解題的效率下降。 Burns & Vollmeyer(2002)也發現人在動態決策作業中的學習階段若沒有指派特 定目標而能自由探索情境時,會使用較多的假設驗證技巧來探究解題的架構,並 且能在學習過後較有能力完整描述情境架構,動態決策作業績效也比較好。本研 究中對回饋所提供的提示因此將會設定在非指派特定目標,讓參與者在動態決策 作業下透過提示能有較多探索情境的行為。透過 Sweller(1988)與 Burns & Vollmeyer(2002)的研究,顯示在人學習動態決策作業階段若給予適度的探索 而不指派特定目標,有助於人建立該動態決策的知識架構,進而有好的決策品質。 本研究採執行動態決策作業時不指派特定目標方式的提示設計,參與者將不被特 定目標所限制,而預期有較多探索情境的行為。 然而在動態決策作業中進行自我回饋時,有無適當的輔助工具以減輕認知負 荷,或有無足夠的休息時間讓人的認知系統可以整理相關的經驗可能也是決定回 饋是否有效的因素。Beach & Mitchell (1978)用四種特徵來調整決策作業的問 題的難度(如,熟悉程度、問題明確程度、複雜度、穩定程度)並操弄自我回饋 的程度,他提供三種自我回饋的決策策略給參與者在面對不同難度的問題時自由 5.
(16) 選用:1.提供紙筆讓參與者針對題目所提到的資訊做筆記。2.不提供紙筆用讓參 與者有時間思考題目所給的資料。3.沒有任何輔助直接做決策。他們發現,人會 考量自身對決策情境掌握的程度來選擇輔助策略,愈能掌握狀況的題目人會傾向 使用紙筆針對題目所提到的資訊做筆記的方法來確保正確答題。Hey & Knoll (2011)的動態決策研究透過 26 的決策樹作業要求參與者使用策略來得到最佳 報酬,實驗中提供所有參與者記下備忘錄以供後續回合的參考。Hey 等人發現備 忘錄提供了實驗參與者回顧先前決策經驗的機會,也幫助參與者透過自我回饋來 釐清問題架構。因此在本研究中我們將「有無自我回饋」分為三個水準,一為使 用紙筆進行手寫筆記自我回饋,另一為放聲思考進行自我回饋,最後則是無自我 回饋等三個水準,探討自我回饋類型對於動態決策績效的影響。 休息對於學習的功效已有相當多的證據,例如學習階段過後的休息時間內, 大腦會持續進行經驗的消化吸收。Gonzalez et., al.(2003)的淨水槽排水作業研 究也發現,同一批實驗參與者經過一天時間的休息後再次操作相同動態決策作業 時,決策績效比第一天的起始回合表現要好很多,甚至只比前一天最後一回合的 績效略差,說明除了當天的大量動態決策作業練習出現了學習效果以外,休息也 讓大腦認知負荷休息並重新整理知識,因此隔天新一回合的決策做業績效比前一 天第一回合要來的好。黃富源、洪瑞雲、廖家寧、呂柏輝(2007)的研究透過電 腦模擬的方式探討牧場管理動態決策作業中的決策績效受休息的影響,他們讓 164 位大學生經營牧場管理系統,透過控制每年欲畜養牧群的數量來推測牧草與 6.
(17) 牧群之間的關係。研究中操弄有無自我回饋、是否休息(1 分鐘)、輔助資訊對 動態決策績效的影響。結果發現,休息與自我回饋間有交互作用,自我回饋的效 果只有在有休息的情況中出現,顯示人在自我回饋時的認知負荷藉由休息得以緩 和與消化吸收,並在休息過後產生學習效果,表現在往後的動態決策作業績效 上。 Tambini & Davachi(2010)的研究則由認知神經的角度探討休息對大腦運作 的影響,他們在實驗過程中隨時偵測參與者腦部血氧濃度的變化,發現參與者在 接受各種圖片配對的記憶訓練之後的休息時間(8.4 分鐘) ,他們腦中處理經驗記 憶的海馬迴與休息前圖片配對所引發相關腦部區域的血氧濃度消長繼續維持高 度相關,這個高度相關的區域在後來的記憶測驗(圖片配對的再認作業)中有較 佳的績效,證明休息時大腦仍然持續對先前經驗消化吸收,並且有助於學習的表 現。由於黃富源等人(2007)的研究顯示休息對於學習是有幫助的,因此本研究 進一步將探討休息時間長短對於動態決策作業績效的影響。 研究問題與假設 本研究的目的,在於探討人在進行動態決策作業時,自我回饋的輔助方式與 休息。透過前述討論發現,人的學習傾向不做自我回饋,但自我回饋在電腦系統 的模擬上出現很大的效益,並且不同程度的自我回饋效果也不一樣,因此本研究 欲探討決策者自我回饋程度對於動態決策作業績效的影響。決策與決策之間的休 息會促進大腦對經驗的消化吸收,休息過後所出現的學習效果對決策績效的進步 7.
(18) 也有幫助,且自我回饋後的休息更能幫助人增進學習成效。然而休息時間長短對 於學習效果是否有影響則仍待驗證,因此本研究另一項議題欲進一步探討休息時 間的長短對於動態決策作業績效的影響。 本研究的問題與假設如下列敘述: 問題一:有無自我回饋是否會影響人們在動態決策時的決策績效? 假設一:有自我回饋會提升人們在動態決策時的決策績效。 問題二:休息時間的長短是否會影響人們在動態決策時的決策績效? 假設二:休息時間長會提升人們在動態決策時的決策績效。 問題三:有無自我回饋、休息時間長短間的交互作用是否會影響人在動態決策時 的決策品質? 假設三:有無自我回饋、休息時間長短間的交互作用會影響人在動態決策時的決 策品質。 變項定義 自變項: 有無自我回饋:指實驗參與者在動態決策作業中進行 5 回合的遊戲後是否能掌握 此作業的情境架構(2 分鐘 × 4 次)。 分成三種情境: 情境一:提供紙筆輔助回顧先前決策經驗,且先前的紙筆整理可同時參考。 情境二:不提供紙筆輔助回顧先前決策經驗,以放聲思考方式回顧先前決策經 8.
(19) 驗。 情境三:無回顧先前決策經驗,相同時間實驗參與者需從事與原本動態決策無關 的認知作業。 休息時間的長短:指實驗參與者進行 5 回合的決策作業過程中給予 0.5 分鐘或 2 分鐘的休息時間(0.5 分鐘 × 4 次,或 2 分鐘 × 4 次)。 分成兩種情境: 情境一:實驗參與者進行五回合的動態決策過程中有 0.5 分鐘休息可不需進行任 何認知作業。 情境二:實驗參與者進行五回合的動態決策過程中有 2 分鐘休息可不需進行任何 認知作業。 依變項: 實驗參與者在動態決策作業中的決策品質,由以下方式評估: 動態決策作業績效: 計算時限內未排出的水量為績效表現,累積水量愈多則代表動態決策作業績效愈 差。 問卷: 了解參與者對此動態決策作業的決策參數與決策情境掌握程度。. 9.
(20) 第二章 文獻探討 動態環境中決策所需的認知作業 人為了達成目標,要從多個可能的行為選項中選取最適當的行動,這樣的選 取行為稱為決策。動態決策則是指決策行為所產生的後果,會造成狀態的改變, 形成新的決策情境,且隨時間有不斷的改變,決策者需要不斷的對這些新的情境 再做決策。動態決策中,影響決策後果的決策因素間的因果關係可能是隱晦不清 的,人必須在線索不足或對情境知識不完整的情況下做決策,並處理每一決策之 後所產生的情境的變動(Endsley, 1995)。 生活中的決策大都是動態的,每一個決策都會產生情境中的變化,而形成新 的決策狀態,例如電腦模擬的生態控制系統中,決策者的作業為控制非洲自然景 觀,調整動植物的生存條件,目標在使原生物種數量得以提升。他們所做的每一 個決定都朝向同一個目標(使原生物種數量提升),但並非每一個決策都可得到 立即回饋,且決策之後的情境可能不是當初所預期的,因此為了繼續朝目標邁進, 決策者必須對生態系統的資源再做調整。這類動態的控制系統牽涉複雜的回饋歷 程,如:正負回饋歷程(原生物種的立即增減)、延遲回饋(經過一段時間後原 生物種的增減趨勢)等,決策者必須根據回饋修正他的下一個決策行為,使未來 的決策結果更接近目標。 在動態環境中做決策,首先必須了解由環境線索中所透露的訊息,從眾多的 外在環境訊息中整理出決策所需要的元素。這樣的過程中須要運用到人的認知資 10.
(21) 源中的注意力、工作記憶與長期記憶中的知識,這幾種腦中的認知資源幫助我們 掌握外在環境中的規則性,進一步推測影響決策表現的相關因素,這樣的認知歷 程稱做情境評估(situation assessment)。 Endsley(1995)以情境覺察理論來說 明人與動態環境互動時的認知歷程。情境覺察的定義是察覺時間與空間中的環境 細節,了解它們的意義(即情境評估),並將知覺到的現況去預測不久的將來, 以作為決策的依據。決策情境中的「情境線索」與「時空」是外在條件,觀察者 需要偵查並了解那些環境細節是需要被注意的。另外,人對情境的理解並不是瞬 間獲得,須對環境有一段時間的觀察來整合事件前後的關係,因此時間變動下的 空間相對位置也是幫助人了解情境重要的一環。情境覺察包含知覺、理解、預測 三個階段,而這三階段所需注意的情境線索與時空知識並不相同。 Endsley(1995) 提出的情境覺察三個階段解釋如下:. 第一階段:知覺。對情境中線索的知覺過程而言,注意力是一個重要的因素, 環境中的一些知覺刺激,在前注意力階段即可能開始運作,抓取人的注意力,如 空間相近性、顏色、外型特徵、移動等,提供線索給注意力以進行知覺辨識。但 並不是所有注意力自動抓取到的線索都需要被進一步處理,因此動態決策中情境 察覺第一階段知覺的工作便是篩選資訊。. 第二階段:理解。人的認知系統透過長期記憶中的知識將知覺的資訊加以整 合的過程稱為理解。動態決策作業中,對於情境的理解程度高低決定了決策者對 決策作業整體運作模式的掌握程度。對情境理解程度高,則較易判斷事件的前因 11.
(22) 後果,較能有多餘的認知資源投注在決策行為的判斷,甚至有餘裕可以對每個行 動的後果進行評估。所以將知覺到的環境訊息篩選與整合,試圖了解外在系統運 作的樣貌,就是動態決策中情境覺察中第二階段-理解。. 第三階段:預測。了解系統運作狀況之後,決策者會將注意力放在推估可能 的決策行為,決定採取何種行為能夠滿足決策者所設定的目標。因此情境覺察的 第三階段為預測,根據已經了解的系統現況搜尋可以達成目標的決策方案,並根 據方案推估執行後的可能結果,而後選取眾多方案中的最佳可行解。影響預測階 段的因素有很多種,但通常都和人的認知資源有限有關,如壓力、短期記憶容量、 工作負荷等(Endsley, 1995)。 Endsley 指出在動態決策中,知覺、理解、預測這三階段並不一定逐步執行, 也就是決策者不一定要知覺充分後才進行情境理解,也不一定是在充分理解情境 後才做預測與評估。這是因為人的認知系統在資訊不足的情況下仍可能提供一些 參考線索,例如長期記憶中的心智模型,可幫助決策者透過局部特徵比對來猜測 了解情境,以便執行反應。這些心智模型的建立是決策者經驗累積出的特定規則 與架構,存在長期記憶中以供取用比對。這樣的認知機制的好處是能讓類似的決 策速度加快,在高度熟悉的環境下可得到不錯的決策品質;缺點就是當情境陌生 或情境線索極為不足時,心智模型比對便很容易出問題,所做的決策可能無法因 應該情境,而產生了偏誤。此外,過於熟悉的環境也可能因為太快完成情境與心 智模型的比對,導致忽略了某些特殊的細節而造成決策失敗。 12.
(23) 由 Endsley(1995)的情境覺察模式可推知在動態決策作業中,決策錯誤的 原因分別為: 在第一階段的知覺歷程中,錯誤來源為漏掉了某些重要的情境線索(或接收 不完整) ,也就是Sweller (1988)認知負荷理論中所提及人在接收過多訊息的情 形下導致無法處理與利用所有資訊,造成遺漏重要訊息而誤判情境。另外,人本 身也會對訊息辨識錯誤,辨識錯誤通常出現在人由上(長期記憶的知識)而下(情 境線索)的辨認歷程時,將情境線索作錯誤辨識的情況,可能把沒有出現的訊息 誤認為有出現,或把已經出現的訊息遺漏掉。以Wickens(1984)提出訊號偵測 理論(signal detection theory)來解釋,辨識訊息上出現遺漏,誤判時會產生誤 警(false alarm)的情況,誤警指的是人將沒有出現的刺激訊息判斷為有出現而 做出不正確的回應。遺漏重要情境線索與訊息解讀錯誤的兩種情況,都是造成第 一階段知覺歷程中發生錯誤的原因。 在第二階段的理解歷程中,對訊息意義的解讀錯誤主要來自長期記憶中是否 有相關的知識能對情境加以詮釋。缺乏知識的新手對情境線索沒有足夠的知識去 整合心智模型,導致情境覺察能力降低(如, Fischer, Orasanu, and Montalvo, 1993)。但老手也可能犯錯,因為他們在過去為單一情境發展出一個心智模型, 若未來情境更新,將使此心智模型不完全適用。決策者若不察,仍依照情境線索 中某關鍵訊息而從記憶中選擇了一個不適當的模式來解釋此情境,將會導致錯誤 (如,Mosier and Chidester, 1991) 。此外,即使決策者選對了因應的心智模型, 13.
(24) 還是有可能出現決策錯誤,例如同時收到兩種警告訊息時,決策者雖可能處理了 其中一個問題,但仍可能因認知資源有限,無法理解兩種警告訊息同時發出的背 後含意,而使用錯誤的策略去解決問題。另一種錯誤來自過度依賴心智模型,情 境模式是被認知者簡化後的一種心理表徵,並非所有相似的情境線索都適用某個 情境模式,因此決策者須具備辨認情境線索是否適用該模式的能力。 第三階段的預測歷程,即使是專家也都會先預估未來將發生什麼情況,才能 著手規劃決策行動。預測歷程與情境的心智模型健全程度有關,即使決策者對情 境中資訊的解讀與了解皆完整,但若沒有據以建立完整的心智模型,則很難做到 對現況與決策行為做預測。專家與新手的差異在於他們對決策環境熟悉程度的高 低不同,因此對此情境所擁有的心智模型成熟度上有差異,決策績效也因而不 同。 由Endsley(1995)的觀點可了解對特定情境心智模型的完整程度,會影響 認知資源在該動態決策作業中的注意力分配情形。人若是心智模型較完整,便能 夠減少辨認外在環境狀態上所需要的注意力,也就是有較多的能力可以做決策、 推理運算;若對動態決策作業情境的心智模型不完整或缺乏,那麼決策者就必須 運用較多的注意力在辨別環境中的因子,以確認現在的狀態以及環境所表達出來 的意義,用於決策、推理運算的認知資源就會減少。因此,建立對動態決策作業 情境較完整的心智模型,使認知資源有多餘能力做運算,在需要大量認知資源的 動態決策作業中,是很重要的。另外,過度依賴心智模型所造成的決策錯誤,是 14.
(25) 因為誤用了心智模型的代表性,認為該情境適用某種決策處理方式,因此除了建 立健全的模型之外,決策者也應具備調整模型彈性的能力,來修正模型以正確描 述外在真實系統,避免誤用的情形。因此,動態決策作業中心智模型的健全程度, 決定了決策者在面對動態決策作業時,對動態系統的觀察、了解、預測評估的完 整性,只有在對情境因素有完整的了解,才能有效控制動態系統,作業績效也才 會提升。 Osman(2010)回顧動態決策相關研究後指出,認知學者對動態決策作業中 情境模式建立的認知歷程有五種不同的(complex dynamic control task)理論:實 例學習、假設驗證、自我調適、專家決策、運算: 1. 實例學習(examplar-instance-learning accounts) 動態決策的作業可視為以實例為基礎去掌握通則的一種學習,也就是目 標導向的學習。剛開始面對一模糊不清的情境時,人會不斷的嘗試錯誤,並 且依賴成功案例當作參考,從成功案例中找出決策相關的情境屬性與回應方 式。成功的例子會被放入長期記憶裡並且加以歸類,形成像查表一樣的心理 分類或知識結構以方便日後抓取。但案例學習通常是在意識以下所形成的隱 性(implicit)學習,學習者無法從記住的範例中提出明確的規則(Berry & Broadbent, 1984, 1987, 1988)。 Gonzalez 等人(2003)以 Simon and Langley(1981)的實例學習理論 (Instance - Based Learning Theory),進一步探討人以實例學習來解釋動態決 15.
(26) 策成功案例的學習機制,他們發展一淨化水槽排水的電腦模擬作業系統 (water purification plant)作為動態決策作業,請 14 位實驗參與者進行 18 回 合動態決策作業,每天連續執行 6 回合(中間無休息)共三天,依據他們的 表現建立參與者在此動態決策作業中的學習曲線。他們另以使用電腦程式規 定運算條件來執行此排水作業,目的是讓電腦模擬 14 個人各執行 18 回合的 排水作業,使經過編寫執行的決策結果與 14 為參與者在淨水槽排水作業系統 中的學習曲線盡可能符合。電腦程式的運算條件可調整 IBLT 中的四個步驟: 識別(recognition)、判斷(judgment)、選擇(choice)、回饋(feedback), 研究發現當電腦程式運算條件控制在 A、識別:前兩回合作業採用隨機挑選 水槽進行排水,第三回合後改從離排水時限點最近的水槽進行排水。B、判 斷:從先前決策中找相似的決策情境。C、選擇:系統會提供前 60 分鐘內的 決策情境可供比對。D、回饋:無決策後回饋,在這些限制條件下,電腦的 表現最接近人的學習曲線,顯示人處於動態決策情境時,剛開始時因記憶中 無相關資訊可參考,決策者會採取隨機決策,等到決策者了解運作機制後(有 經驗了),便會找離時間點最近的決策成功線索當作決策參考,而當有限的 記憶裡可被搜尋的決策經驗與目前決策情境相似度愈高者,便愈容易被提取 做為決策依據,且當人的內心形成一個可依循的成功案例後便不會再考量決 策後果來修改內心已經設定好的成功案例(如,電腦程式若設定為無回饋系 統表現會比系統中含有回饋,其表現更接近決策者的學習曲線,甚至系統在 16.
(27) 有回饋的情況時績效表現竟可達到最完美的境界)。另外,該研究中的參與 者第二天與第三天的第一回合績效皆高於前一天的第一回合,意味參與者當 天的動態決策作業結束至隔天執行下一回合之間的休息有助於學習,這個現 象顯示休息對於學習是有幫助的,且參與者每天執行不休息的六回合皆有績 效提升,顯示人在動態決策作業中即使處於沒有休息的情況,雖無法進行有 意識的認知整合,但成功案例的學習仍在嘗試錯誤中得到歸納,這也顯示案 例學習是隱性學習的一種。本研究的目的即在進一步以實例學習的方式,探 討有無自我回饋與休息對動態決策的影響。 2. 驗證假設(hypothesis-testing account) 動態決策也可視為是一連串假設驗證的行為,例如開車到某個目的地, 駕駛者必須隨時觀察路況,做出對路況的回應。這過程便包含觀察現況與假 設未來狀態並做出行動,行動過後所造成的新路況可用於驗證先前駕駛行為 是否正確,並再次做出行為來修正未來情境,這樣的問題解決過程持續循環 直到駕駛者到達目的地才算完成目標。 驗證假設的運算需耗費認知資源,動態決策作業在完成目標之前的持續 驗證假設過程,其認知負荷的累積更是龐大。如此,有經驗的人能將眾多訊 息有技巧的整合來減低運算的負擔,沒有經驗的人則可能被眾多不熟悉的動 態系統訊息佔用了大部分的心思而無法有效執行動態決策作業。. 17.
(28) Sweller’s(1988, 2002, 2005)的認知負荷理論指出,問題解決是一種目 標導向的認知活動,目的在決定達成目標所需的動作,行動是為了要縮短現 況與目標之間的距離。而動態決策就是一連串的問題解決,人必須不斷的比 對與驗證每一行為後所產生的新情境與目標之間的差距。亦即,標導向的行 為是經由一連串的假設與驗證,排除不成功的行為,保留成功的路徑。但 Sweller發現,人在驗證假設的過程中若認知負荷增加,學習較佳解決策略的 效果將會下降,且學習者也比較無法有系統的將知識做整理。Sweller(1988) 為了探討解決問題時增加認知負荷的程度對於人學習問題解決策略的影響, 他請24位15-16歲的學生學習解答三角函數問題,在實驗參與者了解基本三 角函數概念後,便請他們解答六個利用三角函數求得邊長的問題,若五分鐘 內無法求得解答則公布該題正確解法。每位參與者在第二題到第六題的開始 之前皆被要求試著將上一題重新以更好的方式解答(即第一題到第五題需重 新求解),且不限時間可以仔細思考直到認為自己無法提出更好的解法(前 一題不會回答者在進入下一題之前會提供最佳解法,因此跳過此步驟),這 個步驟的用意在使參與者透過程序的操弄持續進行現況與目標的評估並做決 策來拉近兩者之間的距離。實驗中他將24位學生分成兩個組別,一組是需要 求出特定邊長的組別,另一組則沒有特殊目標而只是告訴它們盡可能求出所 有邊長。所有人皆不需計算只需列出算法即可。 Sweller 發現,所有參與者 的解題時間、計算錯誤次數、重新求得較佳解的解題時間皆隨題數下降,完 18.
(29) 成題目的人也隨題數上升,有學習效果,但從參與者在全部題目中所犯的各 種錯誤裡,發現無特殊目標組別的錯誤都比特定目標組少,顯示無特殊目標 組別的參與者在連續六題的解題過程中所建立的解題知識架構比特定目標組 要來的完整。同一個研究中Sweller 利用二次解題的操弄來引導參與者利用驗 證假設來學習解題,他發現認知負荷較輕者(無特殊目標組別)比認知負荷 較重者(有特定目標組別)更能有餘力建立較完整的解題架構,顯示認知負 荷較重者注意力集中在特定目標而疏於觀察解題環境中觀察其他線索,而這 些被忽略的線索當中可能有成為解題架構須具備的知識。 而 Burns & Vollmeyer(2002)引用 Klahr &. Dunbar(1988)的dual -. space(hypothesis space and experiment space)理論,將動態決策作業分成兩 個向度,一為在規則空間(rule - space)中搜尋,找出決策中情境的因素以 建立決策規則。另一為在案例空間(instance - space),應用法則去產生新的 案例,以測試法則的正確性。 Burns & Vollmeyer(2002)以兩個實驗探究學習階段沒有被指派完成特 定目標的人,是否會在動態決策作業中傾向使用驗證假設的技巧來探索情境, 並且在學習過後較有能力完整描述情境架構。 Burns 等人在第一個實驗中操 弄解題目標的明確程度(特定目標、非特定目標)與知識(有相關知識、無 相關知識),預測在決策作業的學習階段沒有被指派特定目標的參與者(視 為人處於較有能力探索規則的規則空間),進入解決問題階段時的表現績效 19.
(30) 應該比學習階段就指派特定目標(視為人處於以成功案例當作學習典範的案 例空間)的參與者要好。動態決策作業為控制鹽、碳、石灰等三種元素來調 整水中含氧量、氯濃度、溫度等三個指標。實驗一有三個階段共四回合(第 一階段兩回合,其餘階段各一回合),每一回合有六次試驗,每次試驗的三 個指標起始值皆相同,第一階段為學習階段共有兩回合,特定目標的31位參 與者在此兩回合被要求達成特定水中含氧量、綠濃度、溫度,非特定目標的 32位參與者在此兩回合則是隨意探索各元素與水中含氧量、氯濃度、溫度間 的消長關係。所有參與者在兩回合結束後皆須畫出三種元素與三個指標之間 的消長關係連結。第二階段為一回合的測驗,所有參與者皆須透過三種元素 將水中三個指標的含量控制至規定數值;第三階段為一回合的測驗,參與者 須將三個指標調整至新給定的數值。實驗一的三個階段的依變項評分方式為: 第一階段的依變項為「結構分數」,將參與者對三元素與三指標之間消長關 係所畫的鏈結評分,計算正確連結的正分與錯誤連結的負分,最高上限為3.0 分,用以評量參與者對元素與水質指標變化的架構;第二階段的依變項為「錯 誤分數」,將每次試驗中參與者調整各元素輸入值後的水質變化與目標之間 的差距作評分,分數愈低表示表現愈好;第三階段為「目標轉換時的錯誤分 數」。實驗一發現學習階段沒有特殊目標需要完成的參與者組別,在第二階 段解題表現較學習階段有特殊目標需完成的組別績效要好,所犯錯誤分數也 較少,當實驗進入最後一階段的轉換指定目標,非特定目標組參與者績效仍 20.
(31) 然持續進步,錯誤分數也持續下降,特定目標組別的參與者反而有些微退步 的跡象。此結果顯示非特定目標組別的參與者在學習階段因不受限制自由探 索,藉此得知較多水質控制的相關細節與整體結構,而特定目標組別的參與 者在練習階段因指派達成特定目標,而使他們的注意力著重於成功控制水質 的案例,因認知負荷較重而較無多餘心力觀察其他細節。當兩組參與者練習 過後接受特定目標需達成時,練習階段能自由探索的非特定目標組別便能有 較好的表現。 Burns 等人的第二個實驗在驗證非特定目標的組別在決策作業中所使用 的驗證假設的情況是否較特定目標的組別來的多,實驗中操弄目標的明確程 度(特定目標、非特定目標)與提供的輔助資訊類別(提供正確元素與指標 之間關聯但錯誤消長數據、提供正確元素與指標之間關聯但無提供消長數據), 請80位大學生在實驗過程被要求使用放聲思考(think aloud),並全程錄音以 供事後分析。 Burns 發現實驗二的學習階段,非特定目標組比特定目標組別 對待解問題的架構了解較完整(與實驗一結果相同),且非特定目標組在只 有提供元素與指標之間關聯而無提供消長數據的情況下表現比提供錯誤資訊 表現要好。另外, Burns 將參與者的放聲思考區分為兩個向度:一為達成目 標,另一為學習決策作業,其中決策作業又區分為驗證假設(例,我想確定 降低石灰質含量是否會提升含氧量)與不預期未來狀態的驗證(例,我想知 道隨意改變鹽分會造成什麼結果)。從參與者的放聲思考中發現非特定目標 21.
(32) 組別的驗證假設使用情況比特定目標組別要來的頻繁,且非特定目標組別在 學習的一開始傾向使用較多「不預期未來狀態」的驗證,而學習的後段傾向 使用較多驗證假設。由Burns 的兩個實驗顯示人在決策學習階段若無指定完 成特定目標,並能夠自由探索決策環境,將比被指定完成特定目標的人在探 索環境時使用更多的假設驗證來了解情境,且較能夠建立決策問題的知識架 構。 以動態決策來說,從學習知識架構到解決問題皆可視為一連串驗證假設 的行為,好的決策品質取決於對決策情境架構的了解,才能夠在一連串的決 策行為中發現決策後果間的變化,而決定下一步行為,所以建立對決策情境 完整的架構,在學習階段就需要下功夫。透過 Sweller(1988)與 Burns & Vollmeyer(2002)的研究可以發現,決策的學習階段給予學習者一段時間自 由探索並且不限制達成特定目標,有助於學習者建立較完整的決策情境架構, 且此架構是透過持續對情境驗證假設而來。因此本研究中的回饋操作將以不 指定特定目標的方式來設計。 3. 自我調適(self-regulatory accounts) Bandura & Locke(2003)與 Vancouver, More & Yoder's(2008)自我效 能(self-efficacy)的調整與目標導向的驗證來看待動態決策中的學習。 目標導向的行為使人著重在行為的質(自我效能)跟量(時間、影響等 等) ,用以評估行為與目標之間的關係,衡量預期中的狀況跟現在情況的差異, 22.
(33) 並偵測錯誤的地方在那裡,再用行為去回應,此歷程與動態決策在驗證現況 與目標之間的差距是一樣的 Bandura & Locke(2003)。 Bandura 的社會學 習理論(Bandura & Walters, 1963)主張觀察學習(observational learning)與 替代學習(vicarious learning)是人在社會情境中獲得學習的機制。觀察學習 是以旁觀者的身分觀察別人的行為表現所得到的學習,替代學習則是從觀察 別人行為的後果而學得新的學習。這兩種學習都是從觀察生活中的案例為出 發點的學習,這和動態決策作業中,從觀察成功案例所得到的學習是相似的。 Vancouver, More & Yoder's (2008)的自我效能研究,讓實驗參與者進 行電腦施測的滑鼠追點目標遊戲,參與者使用滑鼠游標追點在螢幕中隨機變 換位置的方塊,他們在實驗的練習階段過後進行四次正式試驗,每次正式試 驗前會將參與者需要追點的方塊大小公布在螢幕上,並要求參與者按照先前 的操作經驗來評估這次追點目標所需的時間,用以衡量參與者自我效能與遊 戲過程動機的增減。他們發現,若參與者評估追點方塊所需時間與自身實際 表現相當或游刃有餘則自我效能(自信)與動機提升,參與者會在下次試驗 中追求進步;相反的若參與者實際表現達不到自身評估追點方塊所需的時間 則會尋求其他方法來使自己進步,若在各種方法都無效的情況下則參與者自 信與追求進步的動機都會下降。動態決策作業的認知過程與自我效能認知運 作相仿,一連串的決策過程會因結果的良莠而引起動機增減,並做行為的取 捨-抑制錯誤決策行為及增強正確決策的行為。 23.
(34) 4. 專家決策(expert adaptive decision making) 動態決策中人對問題的掌握是來自他對決策情境的辨認,而辨認的技巧 與績效好壞取決於當事人對情境熟悉的程度,就這部分而言,熟練的動態決 策認知運作和專家決策是相似的。專家是一群對特殊情境有高度知識與經驗 的人,其記憶中所擁有的問題解也較多。專家在特定情境的熟練程度使他們 對於決策情境中的問題較能辨識與整合,如此可大幅減少工作記憶的負荷, 增加可用的認知資源面對等待解決的問題,因此專家在特定領域上比新手表 現要好得多。由此觀點來看,動態決策作業中影響決策績效的主要因素之一 即是相關情境的解題經驗。 動態環境中,決策者若是對相關情境的認識不足,便無法確定哪些情境 線索需被採納與參考,因此人對環境不確定感的高低便影響了動態決策的品 質。Lipshitz & Strauss(1997)的研究由 1960 年到 1990 年之間的 14 篇描述 人對所處情境感到不確定的定義的文獻,整理出對不確定性的 16 種類別,要 求來自以色列國防大學教職員 102(官階分部由將軍至中校)名詳細描述自 己所遇過的不確定戰略情境,並請他們評量自己的描述與前述 16 項不確定性 中的何者較為接近以及應對方式為何。Lipshitz 等人由參與者的評量反應整理 出人對情境的不確定區分成三種類型:認識不足、訊息不完整、無法區別差 異,並發現以將軍至中校官階的高低當作分級專家與新手的依據,則官階愈. 24.
(35) 高的參與者在解決戰略問題時的分析策略較有經驗,較能將情境做重點式的 分析,找出解決戰略情境的關鍵因素。 Kirlik 等人 (1993) 以 Human - environment interaction model ,主張 動態決策作業中人與環境的互動是循環與動態的,但對於環境解讀的程度則 關乎個人的能力限制 (工作負荷、經驗、工作記憶容量、最佳決策)。他的 動態決策作業為飛行員完成指定攻擊與載貨任務,操弄兩個變項,一為一人 一組或兩人一組,另一為從事 20 次訓練或 100 次訓練。研究發現兩人一組的 飛行員從事 20 次的攻擊與載貨任務訓練的最佳成績高於一人一組從事 20 次 訓練的飛行員,但兩人一組從事 20 次訓練的最高成績仍然低於一人一組從事 100 次訓練的最高成績,且兩人一組從事 100 次訓練的最高成績僅略高於一 人一組從事 100 次訓練的最高成績。 Kirlik 等人認為這個現象可能是因為兩 人一組執行同一項作業時,每人負擔的注意力資源減少,同樣 20 次的練習, 績效進步的情況較一人時高,也就是兩人一組有較多的能力處理此作業,不 過兩人一組最高的分數還是低於一人一組經過 100 次訓練的最高成績,表示 訓練的次數增加讓參與者更能了解情境結構,且練習次數多會幫助參與者建 立此動態決策作業的心智模型,使參與者的表現能達到一定的熟練程度。 5. 運算(computational accounts) 目前有些學者嘗試以神經元運作模式,探討人在動態決策作業中的學習 歷程。例如 Gibson(2007)發現動態決策中的行為結果與目標之間的比對作 25.
(36) 業,以及自我驗證的行為,與神經網路訊號輸入輸出的回饋相似。Gibson從 神經網路的輸入與輸出的模型中提出兩個有關決策的歷程,一為行為(action) 模式,一為前向推理(forward)模式。行為模式指人會參考環境現況的輸入 資訊做出行為決策,而前向推理模式指經由推理找出行為的可能後果,再與 實際決策後所得結果做比對,產生對與錯的回饋訊號,用於修正下次決策, 這一連串步驟都是重複且循環的遞迴過程。此兩歷程與動態決策認知運作- 觀察前一個行為決策後果與情境線索現況來進行當下決策,並重複此過程直 到完成目標-是相似的。 動態決策作業的參與者做出行為決策之前也會考量事件發生機率,而決 策後果也會修改事件發生機率而成為下次決策的參考依據,發生機率愈高的 事件案例就愈常被決策者採納,此過程類似神經元路徑的活化。Busemeyer J. R., & Townsend, J. T.(1993, 2006)指出人會考量行為後果發生的機率當作決 策依據,由於不同時間點的決策可能產生不同後果,因此決策者在這樣的決 策場合中必須考量後果與風險的發生機率,並且將決策產生的後果用於修正 先前對發生機率的看法,且反覆這樣的過程來完成目標。 Osman(2010)由上述五類對動態決策的觀點中歸納出動態環境中影響決策 的兩個因素:監視、控制。他以「動態系統的監視與控制架構(Monitoring & control (MC)framework)」來解釋人在動態系統中做決策時的認知歷程。在MC架構下, 動態決策行為包括:監視、控制、持續追蹤決策行為與環境變化之間的關係。監 26.
(37) 視(M)所指的是決策者觀察自己在動態情境中的運作歷程,並且追蹤自己為了 完成目標所做的決策與決策所得後果,用以建立對情境的理解,以提供後續決策 的參考依據;而控制(C)所指的則是利用「監視」所得到對情境理解,應用過 去與現況的訊息來判斷當下該做的決定,並且執行此決定;持續追蹤則將控制與 監視串起,做為修正下一次決策的參考,形成動態決策完成目標前所需的循環。 持續追蹤的標的是監視自己與控制決策的後果與目標間的差距,所以這部分也叫 做自我監控(self-monitoring) 。因此監視、控制、自我監控等三要素組成了動態 決策架構的主軸,處理動態決策中情境線索的不確定性。本研究認為動態決策中 透過監視(M)清楚理解決策相關的情境線索,是影響決策績效的重要關鍵,因 此本研究將從監視的角度探討影響動態決策情境理解的因素。 動態決策作業的困難之處在於情境因素中的不確定性影響監督與控制甚鉅, Osman將不確定性定義為「對環境的可預測性」與「對控制的可預測性」的高低 程度。動態決策情境中不確定的程度高低會影響決策行為,高度不確定性的環境 需要當事人對情境持續性的監視,低度不確定的情境僅需定期監視。監視情境的 變化與人的控制決策行為是互相影響的。若人經驗到情境中的高度不確定性,他 因對環境感到無法預測或不穩定,會導致其降低目標導向的行為而增加探索 (explore)行為,以試圖了解環境的運作機制;低度的不確定性表示環境是可預 測且穩定的,因此在情境突然有所變動時,決策者便還有餘裕判別好的策略來達 成目標。 27.
(38) 根據 Osman 的 MC 模式,人在動態環境中遭遇不同程度的情境不確定因素 時,會有不同的監控行為: 監督作業與不確定性。動態決策情境含高度不確定時,人會依賴先前經驗做 決策,或者使用過去成功案例解決問題,但這些方式難免有些偏誤,並且影響對 於正確解決方式的學習;低度不確定的時候,因為與決策作業相關的訊息足以反 映真實的情境,人會較少使用上述可能有誤的決策方法,但在低度不確定而高度 熟悉的情境,人仍然可能出現過度依賴先前經驗的偏誤,此時將容易導致對於決 策情境的誤判,或錯估失敗後果的嚴重性。 自我監控。在動態決策作業中,人必須隨時監控「行為-後果」的關聯是否 出現異常,在高度不確定的情況下,人較無法成功分析行為-結果的關聯,而偏 向記住成功的行為-結果的配對,但卻沒有找出規則,這樣決策者將無法知道何 種決策情境適用此成功案例,一旦遇到成功案例以外的突發情境因素便容易導致 失敗。 監督與控制的關聯。高度不確定的情況下,人在動態決策作業中會對回饋有 較高的警覺與注意力,但卻無法順利推論行為與後果間的相關因素,因而在行為 與回饋不一致的時候無法提出合理解釋,讓現況與目標之間的差距判斷出現問題。 在低度不確定的動態決策情境下人對於行為與回饋的關注會下降很多,可能只有 定期或不定期監督。但定期監督很容易錯失短暫出現的訊息而造成漏掉關鍵線索, 進而可能產生錯誤決策。 28.
(39) 本研究將從Osman(2010)MC 架構中的監視(M)角度探討影響動態決策 情境理解的因素,一為回饋的方式,另一為休息。本研究欲探討動態決策作業績 效與情境模式的理解,是否會因為不同的回饋方式與休息時間的長短而有影響, 並試圖找出兩者之間的關係。 動態決策與回饋 由 instance-based learning theory 的角度來看,動態決策中SA(情境覺察) 能力的建立有賴人從所達成的案例中學習,學習的效果來自回饋--是否達成目標 的資訊,回饋的目的是讓學習變得有結構,透過不斷自我驗證假設的方式將情境 因素歸納,使其進入長期記憶與已知知識連結並建立基模或者心智模型,Sweller (1988)的假設驗證即為連續考量回饋而決定下一步行為的決策,因此在動態決 策情境中透過回饋來促進學習並形成較完整的SA,是許多研究的重點。 Beach & Mitchell (1978)假設對決策情境資訊與自身能力(自己是否有能 力處理此問題)愈能充分掌握的人,愈能夠在決策時深入推理來掌握成功解題的 機會,若資訊嚴重不足的情況則愈傾向較少的或不推理。他操弄四種特徵來調整 決策作業的問題的難度(如,熟悉程度、問題明確程度、複雜度、穩定程度), 並提供三種不同程度的回饋輔助以供參與者面對不同困難度的決策問題時採用: 1.提供紙筆讓參與者針對題目所提到的資料做筆記。2.不提供紙筆整理計算而讓 參與者有時間思考題目所給的資料。3.沒有任何輔助直接做決策。Beach 等人從 參與者的行為中發現,愈能理解情境(情境線索與自身能力)的人偏好採用紙筆 29.
(40) 針對題目所提到的資料做筆記的方法幫助自己解決問題的回饋輔助方式,當參與 者較無法理解情境時偏好採用心算思考題目所給資料的回饋輔助方式,若參與者 完全無法理解情境時則傾向使用不思考直接做決策。透過Beach等人的研究我們 得知當人對決策情境熟悉時則有能力對問題做深入推理,本研究因此預測在人面 對不熟悉的動態決策情境時給予回饋輔助,有助於人進一步了解不熟悉的環境, 提升人對此動態情境的學習績效。 Hey & Knoll (2011)的動態決策研究要求參與者進行四回合26(六層)的 決策樹作業,每一回合的第1、3、5個決策點由參與者做決策,第2、4、6個決策 點由電腦做決策(每條路徑分派出現機率相等),所有決策點都只有兩種選項, 參與者需觀察電腦決策後的走向當成下次決策的依據,經過六次決策點之後會來 到結束點並得到該點的報酬數字,另外此程式提供記事本軟體輔助實驗參與者做 紀錄、備忘,參與者可在1、3、5決策點輸入備忘以供未來剩餘回合自我回饋之 用。 Hey 等人於實驗過後將參與者的備忘錄所記下的決策過程與結果進行分類 討論,發現參與者使用的決策策略有4種:1.最小化負擔或忽略某些資訊。2.前推 式推理(forward)。3.後推式推理(backward)。4.混合使用前述三種策略。最小 化認知負擔或者忽略重要訊的決策方式,指決策者沒有嘗試去理解現況或其他相 關的資訊。而前推式推理是沿著決策路徑往後續走向推演的方式,是最快也最不 花費認知資源的處理方法。此策略在四種決策類型中不會導致最差的表現,但無 法求得最佳解。後推式推理的決策類型是從最後結果往前回溯來推得可能的決策 30.
(41) 路徑,後推式推理又分為三種策略:1.依賴過去經驗做全盤運算。2.但決策參數 中含有不相關資訊以理性決策過程來篩選。3.簡化問題來降低所需了解的資訊。 混合使用前述策略的決策者沒有固定的決策模式,可能是發現目前處理方法無法 解決問題就馬上換策略,或者對於自己正在使用的策略失去信心。在92位參與實 驗的決策者裡,最小化認知負荷類型的人占了24%(22人) ,前推式占了34%(31 人) ,後推式占了31%(29人) ,使用多種策略占了11%(15人) 。 Hey 等人從實 驗參與者的備忘記錄中發現所有參與者在愈後面的回合所記錄下的備忘資料愈 能描述決策架構,表示先前經驗對於了解決策架構是很重要的。 Beach & Mitchell(1978)的研究發現人在解決問題時若對解題情境愈熟悉, 愈能對問題做深入推理(選用較能深入推理的輔助回饋策略); Hey & Knoll (2011)的研究則提供所有決策者記下備忘錄於後續回合提供參考,使決策者有 回顧先前經驗的機會,且備忘錄也幫助決策者透過自我回饋來釐清問題架構。但 Gonzalez(2003)以電腦模擬人類執行動態決策作業的研究中則發現,人在學習 動態決策作業時並不會自我回饋來使自己更進步,且模擬人類學習曲線的電腦程 式中若加入回饋功能則讓動態決策作業績效持續進步。由這些研究發現可知,人 並不會把先前經驗進行自我回饋來建立較完整的決策情境架構,只有在動機或能 力足夠的情況下,決策者才會透過回饋回顧過去的解題經驗。本研究因此預測若 在動態決策作業中提醒參與者對自己過去的決策行回進行回饋,將可提升對動態 決策情境的理解,進而提升動態決策的績效。 31.
(42) 另外,黃富源、洪瑞雲、廖家寧、呂柏輝(2007)的研究探討影響動態決策 績效因素之中,發現回饋的效果只出現在有休息的情況之中,表示回饋所帶來的 學習效果需要輔以休息才能將知識構築,因此本研究的另一探討因素即為休息時 間長短對動態決策績效的影響。 動態決策與休息 動態決策作業是持續一段時間的連續決策過程,在真實情境中可能持續數天 數月或數年之久,在實驗室中動態決策作業的參與者通常要在1~2個小時之間進 行數百次相同情境的決策,如Gonzalez(2003)的淨水槽排水動態決策作業研究, 參與者在如此大量的重複練習下得到學習效果使績效進步,但更明顯的績效進步 出現在第二天,同一批實驗參與者經過一段時間的休息後再次操作相同排水動態 決策作業時,決策績效比第一天的起始回合表現要好很多,甚至只比前一天最後 一回合的績效略差。黃富源、洪瑞雲、廖家寧、呂柏輝(2007)的研究以電腦模 擬的方式探討動態決策作業中的決策績效受休息的影響。實驗中164位大學生的 工作是經營一個牧場管理系統,透過控制每年欲畜養牧群的數量來推測牧草與牧 群之間的關係。由於牧草與牧群的數量會互相消長,因此參與動態決策作業的大 學生必須找出牧草與牧群消長的平衡關係並將牧群最大化。實驗參與者在系統中 必須於每一年年初決定當年欲畜養的牧群數量,並觀察此設定下的牧草消耗情況, 作為下一年年初考量畜牧數量的依據。實驗以20年為一個回合(即每回合有20 次決策),進行10回合的重複練習,並在每一回合結束後操弄自我回饋的有無、 32.
(43) 輔助資訊的有無、休息(1分鐘)的有無。研究結果顯示,參與者隨練習次數增 加而出現了明顯的學習曲線。此外,階段 × 休息的主效果在每回合決策作業的 後面階段才較明顯,有休息的組別偏離最佳決策的程度顯著比無休息的組別要低, 可能是因為有休息的參與者累積的疲累有舒緩,因此在此回合的學習效果較佳, 沒有休息的參與者則在每回合的後段感到疲倦而導致學習無法持續。自我回饋與 休息間有交互作用,在動態決策作業中自我回饋對動態決策績效的效果只有在休 息的情境中才出現,能舒緩認知負荷而減輕大量重複練習所帶來的疲累感,讓自 我回饋的知識消化過程更有效。 休息在學習的效果已有許多的研究,最近認知神經學的研究也提供了休息時 大腦會自動處理最近經驗的證據。 Tambini & Davachi(2010)使用fMRI儀器檢 測腦中特定皮質區域與海馬迴的血氧濃度(BOLD),觀察人在接受記憶訓練的 全部過程中,海馬迴與特定皮質間腦波活躍程度的相關性。記憶作業的材料是圖 片配對,實驗流程的第一個步驟要求參與者休息8.4分鐘,隨後讓參與者觀看第 一次圖片配對的記憶材料(物體+人臉)21分鐘,回憶作業後休息8.4分鐘,第 一次休息過後再進行第二次圖片配對的記憶作業(人臉+場景)21分鐘,最後再 休息8.4分鐘後進行回憶測驗,回憶測驗後實驗結束。他們全程以 fMRI 紀錄參 與者實驗過程中大腦特定區域的腦波(海馬迴、腦皮質人臉辨識區、腦皮質情境 辨認區、腦皮質枕葉物體辨認區)。研究發現,人在最初尚未從事圖片配對記憶 作業的8.4分鐘休息期間所測出來四個區域的血氧濃度變化均無相關性或規則性。 33.
(44) 參與者在從事第一次圖片配對記憶作業(人臉+物體的配對圖片)時,可從 fMRI 分析中發現參與者此段時間的腦皮質物體辨認區、海馬迴的血氧濃度有同步消長 的情形,第一次圖片配對記憶作業結束後的8.4分鐘休息時間仍可發現腦中這兩 個區域有高度同步消長情形。在第二次圖片配對記憶作業(人臉+場景的配對圖 片)時,可從 fMRI 分析中發現參與者此段時間腦皮質情境辨認區、海馬迴的 血氧濃度也和第一次圖片配對記憶作業時有同步消長的情形,且第二次圖片配對 記憶作業結束後的8.4分鐘休息時間仍可發現這兩個區域有高的同步消長程度。 Tambini 等人在 fMRI 量測程序都結束後,請參與者進行記憶測驗,辨認眼前的 兩張圖片是否曾經在先前兩階段的任一階段圖片配對中出現過。從記憶測驗結果 發現,參與者答對的測驗內容大多是第二次休息前接觸的記憶項目。他們由休息 期間大腦海馬迴從事整理最近的圖片配對記憶作業的現象(兩階段休息時間皆有 此現象) ,推測記憶測驗答對的題目多數為第二次圖片配對記憶作業內容的原因, 是因為兩階段記憶作業海馬迴皆在8.4分鐘的休息時間將圖片配對內容編碼進入 長期記憶,但第二階段圖片配對記憶作業的時間點較近,海馬迴將記憶編碼進入 長期記憶的時間點也較近所以記憶提取較容易,記憶測驗答對的題數因此較多。 休息是學習中重要的一環,除了減輕學習狀態中的疲累感,也能暫時減輕人 在決策時的認知負荷。無論是利用動態決策作業績效中加入休息的操弄,或者腦 部血氧濃度的數據說明休息的狀態下大腦仍然持續處理先前經驗,都表示休息對 於學習是有幫助的。既然休息能促進學習效果,本研究想進一步探討休息時間的 34.
(45) 長短是否會影響學習進步的空間。 總結 動態決策的困難度在於人必須花費認知資源仔細觀察隨時變化的動態情境 參數,並整理情境參數所代表的意義而下決策。過去對於動態決策績效的研究, 通常在比較各種幫助人們學習的方法對於決策績效的改善,甚至從研究中發現了 人在做決策時雖然會試圖朝最佳解的方向邁進,卻也會設法將自身認知負荷減少 來減輕動態決策時需要考量眾多情境因素的壓力(如,不進行自我回饋),因而 使決策績效進步情況達到某個穩定階段後就停滯不前。從 Osman(2010)對於 動態決策架構-監視與控制的觀點可了解,影響動態決策品質最大的因素在於人 透過監視(M)對決策情境理解的程度,人若對特定動態情境理解程度低表示對 該情境的知識不足,進而影響到後續的控制(C),導致決策績效低落,因此本 研究認為監視並充分理解動態決策情境,是影響動態決策績效的主要因素。以假 設驗證的理論來看,人要從陌生動態決策情境中建立法則,需要透過不斷的自我 假設驗證,建立法則後更要用後續的假設驗證來時時修正法則對於特定動態決策 情境的適配性。若要讓人從陌生動態情境中建立的法則有較好品質,則決策學習 階段時是否有較多自由探索的機會是關鍵的因素。另外,動態決策是一連串決策 作業的執行過程,因此時間一長所累積的疲勞會惡化認知負荷的能力,無法由情 境中的線索來獲得學習。因此我們認為適度的在動態決策作業中設置休息時間對 動態決策情境的理解可能有幫助。 35.
(46) 第三章 方法 實驗參與者 本研究為 3(對先前決策經驗進行手寫筆記自我回饋、對先前決策經驗進行 放聲思考自我回饋、無自我回饋先前決策經驗) × 2(單次休息 0.5 分鐘、單次 休息 2 分鐘)× 5(重複五次)的六種實驗情境,實驗參與者為 190 位新竹地區 研究所與大學生。 但在設定每回合排水作業時間長度時發生一些錯誤,原本一回合的時間為 8 分鐘,在 190 位參與者中有 10 位參與者的每回合排水作業時間被調整為 5 分鐘 因此予以刪除。其餘 180 人在 6 種實驗情境中的人數分別為:手寫筆記對先前經 驗自我回饋且休息 0.5 分鐘的情境有 33 人、手寫筆記對先前經驗自我回饋且休 息 2 分鐘的情境有 30 人、放聲思考對先前經驗自我回饋且休息 0.5 分鐘的情境 有 29 人、放聲思考對先前經驗自我回饋且休息 2 分鐘的情境有 29 人、無自我回 饋且休息 0.5 分鐘的情境有 29 人、無自我回饋且休息 2 分鐘的情境有 30 人。 為了減少組內變異的差距,我們將 180 位參與者的 900 筆數據(180 人 × 5 回合)中的 38 筆離群值(2≧SD)刪除,並且以該情境該回合的平均值為替代。 唯第 1 回合雖然也使用各組情境的兩倍標準差當作篩選依據,但因第 1 回合 180 位參與者並無接受情境操弄,所以採用第 1 回合的整體平均數作為該回合各組情 境離群值的替代值,全部共替代 38 筆數據,佔 900 筆數據中的 2.4%。38 筆數據 中,提供紙筆回顧先前決策經驗且休息 0.5 分鐘的情境佔 6 筆、提供紙筆回顧先 36.
(47) 前決策經驗且休息 2 分鐘的情境佔 9 筆、放聲思考對先前經驗自我回饋且休息 0.5 分鐘的情境佔 7 筆、放聲思考對先前經驗自我回饋且休息 2 分鐘的情境佔 4 筆、無回饋且休息 0.5 分鐘的情境佔 7 筆、無回饋且休息 2 分鐘的情境佔 5 筆。 動態決策作業 本研究所使用的動態決策作業引用 Gonzalez, C., Lerch, F. J., & Lebiere, C. (2003)的淨水槽排水作業系統(Water Purification Plant),此為一電腦程式模 擬的排水作業,實驗參與者擔任排水管理的主控人,作業內容則是將各淨水槽的 水在淨空時限內排出。在這個排水作業最重要的兩項因素是時限與排水路徑,不 同的水槽有不同的淨空時限,實驗參與者要設法在淨空時限內盡可能將水槽內的 水量減至最低或全數排出;而排水路徑也有長短之分,花太多時間在短程的排水 路徑上,則會照顧不到長程的排水路徑而錯失淨空時限,造成過多需排掉的水量 留在淨水槽內的決策失誤。這個模擬系統中,參與者可以自由選擇有水水槽,每 個水槽有兩個排水幫浦,其排水幫浦開啟的時機。系統設定最多可同時開啟五個 排水幫浦,開啟幫浦後,水會引導至後方儲水槽(若後方已無儲水槽則為成功排 出),工作後關閉的幫浦有恢復期(恢復期的長度為 10 分鐘),恢復期過後才可 以再次使用該幫浦或開啟其他幫浦;若後方儲水槽不只一個,則水量會不平均分 布至所有水槽,此為系統決定無法由人工干預。實驗參與者的工作是選擇幫浦開 啟的順序,在水槽淨空時限之前盡可能排出最多的水量。 此淨水槽排水作業中的系統動態部分為欲排除的水量(單位:桶),水量的 37.
數據
相關文件
沒問題,那麼我先 到燒烤場準備,你 們就休息一下吧!..
在第一章我們已瞭解一元一次方程式的意義與解法,而在本章當中,我們將介紹
第四章 直角座標與二元一次方程式.
第四章 直角座標與二元一次方程式.
他們會回到中間,這是打羽毛 球很重要的一環。目標是為了 準備下一球。試想想如果你在
•至最近連續居留港澳或 海外期間之計算,係以 本簡章申請時間截止日 為計算基準日往前回溯 推算6年或8年。但計算 至西元2015年8月31
我們堅信所有學生都有能力學習,而且在智能方面,各有所長 。 因此,擬
由於環保意識抬頭,回收業者從 2018年開始在台南多點設置「自動資源回收
