財務危機預警模型之研究-以台灣地區上市公司為例
98
0
0
全文
(2) 財務危機預警模型之研究-以台灣地區上市公司為例 A Study of Financial Distress Prediction Models -The Case of Companies Listed on TSE 研 究 生:魏曉琴 指導教授:李正福 教授 林建榮 教授. Student : Hsiao-Chin Wei Advisors : Dr. Cheng-Few Lee Dr. Jian-Rung Lin. 國 立 交 通 大 學 財 務 金 融 研 究 所 碩 士 論 文. A Thesis Submitted to Institute of Finance College of Management National Chiao Tung University in partial Fulfillment of the Requirements for the Degree of Master of Science in Finance May 2004 Hsinchu, Taiwan, Republic of China. 中華民國九十三年五月.
(3) 財務危機預警模型之研究-以台灣地區上市公司為例 學生:魏曉琴. 指導教授:李正福教授 林建榮教授 國立交通大學財務金融研究所 摘. 要. 長久以來許多經濟及財務學家僅使用公司一期之觀察資料來預測公司發生財務危 機之機率,例如 Altman (1968) 使用多變量區別分析、Ohlson (1980) 使用 Logit 模型 及 Zmijewski (1984) 使用 Probit 模型等,Shumway (2001) 將這些模型稱之為靜態模 型。有別於靜態模型,Shumway 提出一個離散型倖存模型,該模型之優點係能夠有效 地使用公司所有之歷史資料來分析,所以可預測取樣公司在樣本期間內每一個時間點發 生財務危機之機率;再者,其參數估計式具有一致性及不偏性之性質,且無靜態模型中 所存在之樣本選擇偏誤之問題,因此 Shumway 推論出離散型倖存模型其參數之估計與 樣本外時間點公司發生財務危機之預測能力,均較靜態模型有較佳之表現。 Shumway 在其實證研究中係將離散型倖存模型定義為多期 Logit 模型,然而,其 所定義之多期 Logit 模型之概似函數忽略了樣本公司在ti時仍存活之機率,因此本研究 將其概似函數加以修正,進一步使修正後之離散型倖存模型之概似函數完全考慮所有取 樣公司在t < ti及t = ti時之存活機率與發生財務危機之機率,故對修正後之離散型倖存模 型、 Logit 模型、Probit 模型及多變量區別分析進行實證研究,採用二組解釋變數組合, 分別係 Altman 變數組合及 Zmijewski 變數組合,以比較各模型對公司發生財務危機之 預測能力,並研究在何種模型下,使用何種解釋變數組合可以得到公司發生財務危機之 最佳預測效果。 實證結果顯示,公司年齡取自然對數後,其參數值之檢定結果在各模型中均不顯 著,顯示出公司之存續期間與公司是否發生財務危機之關聯性很小,在 Altman 變數組 合中,僅有 RE/TA 變數其參數值之檢定結果在四種模型中均係顯著,表示公司累積獲 利之能力愈強,愈不易發生財務危機;至於在 Zmijewski 變數組合中,僅有 NI/TA 變 數其參數值之檢定結果在四種模型中均係顯著,表示公司之總資產報酬率愈高,獲利能 力愈強,愈不易發生財務危機。 在 Altman 與 Zmijewski 變數組合之解釋能力方面,給定樣本外型 II 誤差率,四 種模型分別使用 Altman 變數組合比使用 Zmijewski 變數組合可得到較大之樣本外檢 定力函數值,因而採用 Altman 變數組合作為解釋變數來進行公司發生財務危機之預 測,其正確率會高於使用 Zmijewski 變數組合。 雖然理論上離散型倖存模型會比 Logit 模型、Probit 模型及多變量區別分析有較佳 之表現,然而實證結果卻與理論有些出入,但是若排除多變量區別分析,僅比較離散型 倖存模型、Logit 模型及 Probit 模型,則結果係使用離散型倖存模型,再搭配 Altman 變 數組合,其預測公司發生財務危機之準確率最高。 i.
(4) A Study of Financial Distress Prediction Models -The Case of Companies Listed on TSE Student : Hsiao-Chin Wei. Advisors : Dr. Cheng-Few Lee Dr. Jian-Rung Lin. Institute of Finance National Chiao Tung University ABSTRACT For a long time many economists and accountants have been forecasting bankruptcy by single-period classification models, one set of independent variables for each firm, which Shumway (2001) refers to as static models, with multiple-period bankruptcy data. Shumway develops a discrete-time survival model that uses all available information to produce bankruptcy probability estimates for all firms at each point in time. By using all the available data, it avoids the selection biases inherent in static models. While static models produce biased and inconsistent bankruptcy probability estimates, the discrete-time survival model proposed here is consistent in general and unbiased in some cases. Shumway interprets it outperforms static models in out-of-sample forecasts. Shumway estimates a multi-period logit models that can be interpreted as discrete-time survival model. A logit estimation program can be used to calculate maximum likelihood estimates. I modify the discrete-time survival model’s likelihood function because it ignores the probability of surviving at time t. This idea completely considers the probability of failure at time t, surviving up to and at time t for all firms. I estimate discrete-time survival model, logit model, probit model, and multivariate discriminant analysis with two different sets of independent variables that incorporate Altman’s (1968) 5 variables and Zmijewski’s (1984) 3 variables, as well as Shumway’s (2001) variable of the log of firm age. I find that the log of firm age is not statistically significant in the all models. There appears to be little duration dependence in bankruptcy probability. According to the set of Altman’s variables, the only statistically significant variable is RE/TA. While according to the set of Zmijewski’s variables only NI/TA is excellent bankruptcy predictor. Both of them represent the higher the (cumulative) profitability the lower the financial distress. Because all models use the set of Altman’s variables can get larger power given the type II error rate out-of-sample, so the out-of-sample accuracy of the set of Altman’s variables is higher than the set of Zmijewski’s variables. Although discrete-time survival model is preferable to static models theoretically, empirical result produces contradictory. If I exclude MDA, combining the discrete-time survival model with the set of Altman’s variables, then I estimate it is quite accurate in out-of-sample test. ii.
(5) 誌. 謝. 時光荏苒,來到交大的兩年轉眼間就這麼悠悠晃晃地過去了。戴上方帽那一刻,腦 海中接連浮現的,是研一那段焚膏繼晷地討論報告、為了期末考和課本與咖啡一起看日 出之歲月;以及研二時大家為了寫論文,同學間互相砥礪與扶持,都使我這兩年之研究 所生涯,充實而感動。. 在長達一年之論文研究過程中,最要感謝的是指導教授 授。尤其是. 李正福所長及. 林建榮教. 李正福所長,就像我研究所生涯裡之一盞明燈,以其浩瀚之學識涵養,不. 厭其煩地指引著我們學習及處事之方向,且在論文撰寫期間不辭辛勞地給予悉心指導與 協助,使我從中獲益良多。師恩浩蕩,學生銘記於心。再者,亦要感謝清華大學計量財 務金融系. 楊屯山教授及政治大學會計系 張清福教授,於口試期間費心詳閱本文,給. 予許多建議與指導,使本論文之論述更加嚴謹與完備。另外,博士班瑞卿學姐在論文觀 念及資料實證部分之不吝指導,以及同班同學曉芸、玫伶和衍龍在寫作上之討論,都是 完成此份論文不可或缺之助力。. 在即將踏出校園之際,更要感激的是在長達二十年之求學生涯中,一路支持我、陪 伴我之家人,特別感謝含辛茹苦教養我之父母,家人的愛和支持,是我得以完成學業之 最大力量。另外,也要感謝男友永哲所給予我的包容和溫暖,每當我在人生、學業或論 文上遇到挫折時,總是鼓勵著我,給予我力量,讓我有勇氣闖過層層之關卡,因為有您 們之陪伴與鼓勵,才有今日的我。僅將此篇論文,獻給我親愛之父母,以及所有關心我 的朋友。. 魏曉琴. 謹識. 於交大財務金融所 中華民國九十三年五月 iii.
(6) 目 中文摘要 英文摘要 誌謝 目錄 表目錄 圖目錄 一、 1.1 1.2 1.3 二、 2.1 2.1.1 2.1.2 2.2 2.2.1 2.2.2 2.3 2.4 2.5 2.6 三、 3.1 3.2 3.3 3.4 3.5 3.6 四、 4.1 4.1.1 4.1.2 4.1.3 4.1.4 4.2 4.3 4.3.1 4.3.2 五、 5.1 5.2 5.3. 錄. ………………………………………………………………………… ………………………………………………………………………… ………………………………………………………………………… ………………………………………………………………………… ………………………………………………………………………… ………………………………………………………………………… 緒論…………………………………………………………………… 研究背景與動機……………………………………………………… 研究目的……………………………………………………………… 研究架構……………………………………………………………… 財務預警統計模型暨文獻探討……………………………………… 單變量與多變量模型………………………………………………… 單變量分析…………………………………………………………… 多變量區別分析……………………………………………………… 迴歸分析模型………………………………………………………… 線性機率模型………………………………………………………… 定性選擇模型………………………………………………………… 迴覆分割演算………………………………………………………… 類神經網路…………………………………………………………… 倖存分析……………………………………………………………… 多變量累積總和模型………………………………………………… 研究方法……………………………………………………………… Logit 模型……………………………………………………………… Probit 模型…………………………………………………………… 離散型倖存模型……………………………………………………… 多變量區別分析……………………………………………………… 最適分界點…………………………………………………………… 驗證效度……………………………………………………………… 研究設計……………………………………………………………… 財務危機之定義……………………………………………………… 國外研究對財務危機之定義………………………………………… 國內研究對財務危機之定義………………………………………… 我國法律規定………………………………………………………… 台灣經濟新報………………………………………………………… 研究樣本與資料來源………………………………………………… 研究變數……………………………………………………………… 因變數………………………………………………………………… 解釋變數……………………………………………………………… 實證結果與分析……………………………………………………… Altman 變數組合之預測結果與分析……………………………… Zmijewski 變數組合之預測結果與分析…………………………… Altman 變數組合與 Zmijewski 變數組合之比較………………… iv. i ii iii iv vi vii 1 1 2 3 5 5 5 6 11 11 11 17 18 21 26 31 32 33 34 38 43 45 47 47 47 50 51 52 53 57 57 57 59 59 67 74.
(7) 六、 6.1 6.2 參考文獻 附錄一. 結論與建議…………………………………………………………… 結論…………………………………………………………………… 建議…………………………………………………………………… ………………………………………………………………………… …………………………………………………………………………. v. 76 76 79 80 86.
(8) 表目錄 表1 表2 表3 表4 表5 表6 表7 表8 表9 表 10 表 11 表 12 表 13 表 14 表 15 表 16 表 17 表 18 表 19 表 20 表 21 表 22 表 23 表 24 表 25. 財務預警模型之統計方法比較………………………………………………… 取樣期間內財務危機公司之產業別家數分佈表……………………………… 取樣期間內財務危機公司彙總表……………………………………………… 取樣期間內正常公司之產業別家數分佈表…………………………………… 樣本外期間財務危機公司之產業別家數分佈表……………………………… 樣本外期間財務危機公司彙總表……………………………………………… 解釋變數之敘述統計…………………………………………………………… 離散型倖存模型之參數估計值 (Altman 變數組合)…………………………… Logit 模型之參數估計值 (Altman 變數組合) ………………………………… Probit 模型之參數估計值 (Altman 變數組合)………………………………… 檢定多變量區別分析之假設條件 (Altman 變數組合)………………………… 多變量區別分析之參數估計值 (Altman 變數組合)…………………………… 四種模型之參數估計值 (Altman 變數組合)…………………………………… 四種模型之最適分界點 (Altman 變數組合)…………………………………… 四種模型樣本外誤差率之比較 (Altman 變數組合)…………………………… 四種模型之樣本外檢定力函數值 (Altman 變數組合)…………………………… 離散型倖存模型之參數估計值 (Zmijewski 變數組合)……………………… Logit 模型之參數估計值 (Zmijewski 變數組合)…………………………… Probit 模型之參數估計值 (Zmijewski 變數組合)…………………………… 檢定多變量區別分析之假設條件 (Zmijewski 變數組合)…………………… 多變量區別分析之參數估計值 (Zmijewski 變數組合)……………………… 四種模型之參數估計值 (Zmijewski 變數組合)……………………………… 四種模型之最適分界點 (Zmijewski 變數組合)……………………………… 四種模型樣本外誤差率之比較 (Zmijewski 變數組合)……………………… 四種模型之樣本外檢定力函數值 (Zmijewski 變數組合)……………………. vi. 28 53 54 55 55 56 58 60 60 60 61 61 61 64 65 66 67 67 68 68 68 68 71 71 73.
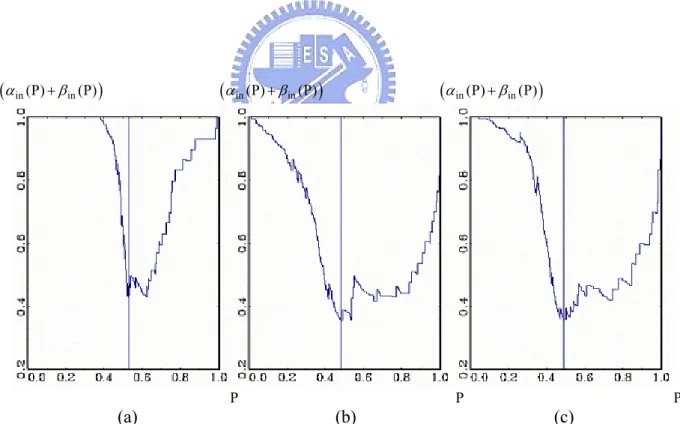
(9) 圖目錄 圖1 圖2 圖3 圖4 圖5 圖6 圖7 圖8 圖9. 研究流程………………………………………………………………………… 兩群體線性區別函數規則圖…………………………………………………… 離散型倖存模型、Logit 模型及 Probit 模型之最適分界點 (Altman 變數組 合)………………………………………………………………………………… 多變量區別分析之最適分界點 (Altman 變數組合)…………………………… 四種模型之檢定力曲線 (Altman 變數組合)…………………………………… 離散型倖存模型、Logit 模型及 Probit 模型之最適分界點 (Zmijewski 變數 組合)……………………………………………………………………………… 多變量區別分析之最適分界點 (Zmijewski 變數組合)……………………… 四種模型之檢定力曲線 (Zmijewski 變數組合)……………………………… 四種模型下 Altman 變數組合與 Zmijewski 變數組合之檢定力曲線…………. vii. 4 38 63 64 65 70 71 72 75.
(10) 一、緒論. 1.1 研究背景與動機 有鑑於 1997 年亞洲金融風暴及 2000 年網路科技泡沬化之後,世界各國陸續傳出地 雷股之消息,企業紛紛發生財務危機而宣布倒閉,連帶地使各國之金融機構和世界各地 之投資人遭受不同程度之波及,各國政府也付出相當嚴重之代價。例如美國財星五百大 (Fortune 500) 公司之第七大企業安隆公司 (Enron) 於 2001 年 12 月 2 日向美國聯邦破產 法院聲請美國金融史上最為龐大之破產重整保護,成為美國有史以來最大之破產案,嚴 重衝擊美國之資本及金融市場。如日中天之 Enron 忽然聲請破產,爆炸之威力相當驚人, 造成全球之債權人、投資人及退休基金收益人損失慘重,無辜之員工也賠進了終生之退 休金。Enron 事件對金融、社會、歷史、政治及經濟秩序所造成之輿論,其影響如同擁 有二百二十三年歷史之美國霸菱商業銀行 (Barings PLC) 於 1995 年 2 月遽然宣佈倒閉 所造成之衝擊相同,一個龐大企業體受創之深度與傾圮之速度,皆是令人難以想像。 就台灣而言,亦難以倖免,尤其過去幾年陸續有國產汽車、國揚實業、東隆五金、 廣三集團、東帝士集團等企業從事非常規關係人交易之利益輸送、借殼上市護盤、掏空 或挪用公司資產等手法間接引發財務問題,而九津實業更在民國九十二年三月六日因為 資金一時調度不及,導致爆發巨額股票違約交割,金額逾新台幣廿億元。這些財務危機 事件使得各家金融機構為求自保,對於企業之借款愈來愈小心謹慎,但在銀行緊縮銀根 後,亦會導致企業資金週轉困難,落入財務危機之窘境。 由於發生財務危機之公司並非是一朝一夕所形成,在爆發財務危機之前均會顯露出 一些癥兆,因此本研究期望能提供給金融機構作為授信業務時之輔助工具,加強風險管 理之機制;另一方面提早讓管理當局及相關證券主管機關有所防範,能在事發前處理或 預防公司發生財務危機,穩定金融之安定性,逹到健全經濟體質之目標;最後亦希望能 提供機構投資者或一般投資大眾從事投資組合之參考依據,亦即如何在企業發生財務危 機之前,即時且正確地區分財務危機與營運正常之公司,避免踩到地雷股,以提高投資 組合之報酬率。. 1.
(11) 1.2 研究目的 長久以來許多經濟及財務學家僅使用公司一期之觀察資料來預測公司發生財務危 機 之 機 率 , 例 如 Altman (1968) 使 用 多 變 量 區 別 分 析 (multivariate discriminant analysis)、Ohlson (1980) 使用 Logit 模型及 Zmijewski (1984) 使用 Probit 模型等, Shumway (2001) 將這些模型稱為靜態模型 (static model)。有別於靜態模型,Shumway 提出一個離散型倖存模型 (discrete-time survival model),該模型之優點在於納入了隨時 間變化之解釋變數向量 (time-varing covariates),能夠有效地使用公司所有之歷史資料來 分析,因此可預測取樣公司在樣本期間內每一個時間點發生財務危機之機率。 Shumway 也指出離散型倖存模型之參數估計式具有一致性 (consistency) 及不偏 性 (unbiasedness) 之性質,另外,離散型倖存模型並無靜態模型中所存在之樣本選擇偏 誤 (sample selection biases) 之問題,亦即靜態模型忽略了營運正常之公司也有可能會發 生財務危機之狀況,且靜態模型之研究樣本僅納入具有完整資料之公司,但實際上許多 公司無法具有完整之資料,所以 Shumway 推論出離散型倖存模型其參數之估計與樣本 外時間點公司發生財務危機之預測能力,均較靜態模型有較佳之表現。 由於離散型倖存模型中最感興趣之變數係公司年齡,因而採用 Shumway (2001) 所 定義之公司年齡 (取對數) 作為解釋變數之一;再者,也以 Altman (1968) 與 Zmijewski (1984) 所採用之解釋變數作為財務比率變數之代表,因此本研究使用了兩組解釋變數, 第一組解釋變數包含了 Altman (1968) 所採用之 5 項財務比率和 Shumway (2001) 之公 司年齡變數 (取對數),簡稱為 Altman 變數組合;第二組解釋變數則包含了 Zmijewski (1984) 所採用之 3 項財務比率和 Shumway 之公司年齡變數 (取對數) ,簡稱為 Zmijewski 變數組合。 Shumway 在其實證研究中係將離散型倖存模型定義為多期 Logit 模型,然而, Shumway 所定義之多期 Logit 模型之概似函數忽略了樣本公司在 ti 時仍存活之機率, 因此本研究欲將其概似函數加以修正,進一步使修正後之離散型倖存模型之概似函數完 全考慮所有取樣公司在 t < ti 及 t = ti 時之存活機率與發生財務危機之機率,故本研究對修 正後之離散型倖存模型、 Logit 模型、 Probit 模型及多變量區別分析進行實證研究, 比較各模型對公司發生財務危機之預測能力,以及研究在何種模型下,使用何種解釋變 數組合可以得到公司發生財務危機之最佳預測效果。 2.
(12) 1.3 研究架構 本研究共分為六個章節,各章節之內容簡述如下:. 第一章為緒論,本章說明研究主題形成原由與目的,並概述整體之輪廓。第二章列 舉財務預警統計模型及其相關之文獻探討,在本章中,除了介紹本研究所使用之離散型 倖存模型、Logit 模型、Probit 模型及多變量區別分析之設計與涵意外,亦整理其他財 務預警統計分析,並說明各模型之假設條件、優缺點及歷年實證結果。第三章為研究方 法,本章首先分別介紹離散型倖存模型、Logit 模型、Probit 模型及多變量區別分析之 建構方法;其次決定公司發生財務危機之最適分界點,建立公司發生財務危機之預警模 型;最後則探討如何衡量各模型對樣本外時間點公司發生財務危機之預測能力。 第四章為研究設計,本章包括財務危機之定義,乃針對國內、外學者、我國法律規 定及國內研究機構四部分來說明,另外也描述研究樣本之選取標準、實證資料之搜集來 源及因變數與解釋變數之定義。第五章為實證結果與分析,本研究使用兩組解釋變數組 合,亦即在 Altman 變數組合與 Zmijewski 變數組合下,比較離散型倖存模型、Logit 模 型、Probit 模型及多變量區別分析對公司發生財務危機之預測能力,並且研究在何種模 型下,使用何種解釋變數組合可以得到公司發生財務危機之最佳預測效果。第六章為結 論與建議,本章先依據本研究之實證結果作出結論,其次則針對本研究不足之處對後續 研究者提出相關之建議。. 針對上述各章節之研究內容,經整理歸納後,本研究之研究流程如圖 1 所示。. 3.
(13) 研究動機與目的. 財務預警統計模型暨文獻探討. 研究方法. 樣本選取. 離散型倖存模型. 資料搜集. Logit 模型. 決定變數. Probit 模型. 進行實證分析. 結論與建議. 圖1. 研究流程. 4. 多變量區別分析.
(14) 二、財務預警統計模型暨文獻探討. 財務預警之研究可謂是不勝枚舉,引起財務金融方面之學者廣泛之探討,研究重點 主要在於相關計量模型之開發與改進以及投入變數之決定兩大範疇。財務預警模型之變 革亦隨著時代之演進而有陸續之發展,目前之研究除了大量使用各種多變量統計分析 外,還引進了資訊管理、生物醫療等常用之計量技術來處理,使得預警模型更趨於複雜 化與多樣化。在本章中,除了介紹本研究所使用之離散型倖存模型、Logit 模型、Probit 模型及多變量區別分析之設計與涵意外,亦整理其他財務預警統計分析,並說明各模型 之假設條件、優缺點及主要相關文獻。. 2.1 單變量與多變量模型 2.1.1 單變量分析 (univariate analysis) 1932年文獻上第一個用來區別失敗與否之統計分析為單變量模型。單變量分析是以 單一自變數來作為分析之指標。一般採用單變數分析之步驟如下: 1.確定發生財務危機之企業。 2.根據該企業找出相同產業、規模大小類似之正常企業作為配對樣本(matching sample)。 3.搜集財務危機企業與正常企業之相關財務比率資料。 4.利用二分類檢定法(dichotomous classification test)將財務比率資料依不同之年度 按照大小次序排列,從中找出一個使分類誤差率最小之分割點,而分類誤差率最 小之財務比率即為最佳之預測變數。 5.利用最佳預測變數當做標準對樣本外期間進行預測。. 雖然已有相關文獻使用單變量模型,但是興起財務預警風氣之學者首推 Beaver (1966)。Beaver 首先以二分類檢定及配對選樣發展出企業失敗預測模型,而成為單變量 5.
(15) 分析方法之主流。Beaver 在其研究中隨機抽取1954至1964年間,共計79家營運狀況遭 到失敗之公司,並在同業當中選取資產規模相近之正常公司進行1:1配對檢定,共計79 家正常公司。研究中以企業失敗前5年之30項財務比率資料作為自變數,萃取出6項能顯 著區分正常與失敗公司之財務比率,並以此作為預測之因子,分別是「現金流量/總負 債」、「淨利/總資產」、「總負債/總資產」、「營運資金/總資產」、「流動資產/流動 負債」與「信用期間」。最後則將不同年度,各組之財務比率按照大小排列,並應用無 母數統計方法 Mann-Whitney-Wilcoxon 檢定法,找出使分類錯誤百分比最低之分界 點。研究結果顯示,以「現金流量/總負債」所代表之融資決策最具有區別能力,其次為 「淨利/總資產」。Beaver 認為,由於市場效率之不完全,因此最符合現實之模式最有 效,也就是簡單模型可能比較好,其實證結果中財務危機發生前3至1年之預測能力分別 為77%、79%及87%。 Beaver 之研究對於日後相關研究之影響有下列5點,分別為:1.界定失敗之定義。 2.首創配對之抽樣方法。3.增加新的財務比率。4.利用驗證樣本來評估區別能力。5.以分 類檢定法求取最佳之分類點。. 單變量統計方法雖然簡易,且分析所求得之數值易於解釋,但是以單一因子作為失 敗與否之判定卻飽受許多學者批評,一般普遍均認為企業發生失敗之原因,應該是多項 因素在同一時間爆發所致,用單一財務比率難以表達整個公司之體質,且有可能某一財 務比率單獨考慮時區別效果不顯著,但與其他財務比率一併考慮時卻發生極大解釋能力 之現象;另外,單變量分析只考慮到變數之集中趨勢,並未考慮到其離散程度,故後續 採用多變量分析方法來彌補單變量分析之弱點。. 2.1.2 多變量區別分析 (multivariate discriminant analysis, 簡稱MDA) 多變量區別分析之目的係自兩群或多群樣本中,尋找出最能夠有效區分群體間差異 之變數組合。在進行多變量區別分析之前,須先確認模型中之解釋變數資料符合多變量 常態分配 (multivariate normality) 及各群體之共變數矩陣相等 (equality of covariance matrices) 之假設。分析步驟為,先找出解釋變數之線性組合,依據此線性區別函數做群 體區分,使區分後之群體其群體間變異 (between-group dispersion) 相對於群體內變異 6.
(16) (within-group dispersion) 之比值為最大,接著再檢定各群體之重心是否有差異,進一步 找出哪些解釋變數具有最佳之區別能力,最後則利用此線性區別函數求得所有樣本在區 別軸上之分數,由各樣本之區別分數 (discriminant score),將該樣本歸類到某一群體中。 MDA 之優點係同時考慮多項解釋變數,不僅在整體績效衡量上比單變量分析來得 周詳,亦可瞭解哪些自變數最具區別能力。. Altman (1968) 是第一位將多變量區別分析應用於企業破產預測之學者,因而成為 後續構建企業失敗預測模型之重要基礎。Altman 選取1946至1965年間按美國破產法第 十章規定申請破產處分之33家製造業公司作為失敗樣本,並按產業別及公司規模隨機抽 取33家於1966年仍然營運正常之公司作為配對樣本,選取22項財務比率後先以因素分析 法 (factor analysis) 萃 取 出 5 個 因 素 , 分 別 為 : 1. 流 動 性 (liquidity) 。 2. 獲 利 能 力 (probability)。3.槓桿 (leverage)。4.償債能力 (solvency)。5.活動能力 (activity),再利用 逐步 (stepwise) 區別分析,萃取出5項相互獨立且最具有共同預測能力之財務比率,將 此5項財務比率建構一條類似迴歸方程式之區別函數,形成一區別分數,用以區分失敗 企業與正常企業,此過程稱之為 Z-score 分析法,其 Z-score model 表示如下. Z = 1.2 X1 +1.4 X2 + 3.3 X3 + 0.6 X4 + 0.999 X5, 其中,Z :區別分數, X1:營運資金/資產總額 (working capital/total assets), X2:保留盈餘/資產總額 (retained earnings/total assets), X3:稅前息前盈餘/資產總額 (earnings before interest and taxes/total assets), X4:股東權益(優先股及普通股)市值/總負債帳面價值 (market value equity/book value of total debt), X5:銷貨收入/資產總額 (sales/total assets)。 根據二分類檢定法,以區別分數 Z = 2.675 做為判斷企業體質良好與否之分界點 (cut-off point),當 Z > 2.675 則歸類為正常公司;反之,Z ≤ 2.675 則歸類為財務危機公司。 對原始樣本區別能力之檢定結果發現,此模式對企業破產之預測在破產前1、2年具顯著 性,正確區別率分別為94%與72%,然而隨著時間愈長,模型之預測準確性有逐漸下降 之趨勢,前3年至前5年分別為48%、29%、36%,故 Altman 認為區別分析對企業失敗 7.
(17) 之預測僅限於短期有效,超過2年以上則不適用。 Altman 另外選取樣本外25家破產公司用以驗證區別能力,結果顯示其正確區別率 高達96%;但若是忽略公司資產大小,而改以2項標準 (屬於製造業公司以及1958和1961 年淨利出現赤字) 重新選取出66家正常公司,則其正確區別率為79%。. Deakin (1972) 結合 Beaver 與 Altman 兩位學者之研究,建立二次式區別函數模型 (quadratic function),藉以改善區別效果,其實證結果發現區別效果在前3年之正確率達 80%,但是自第4年起則逐年下降,顯示其區別能力並不理想。. Blum (1974) 以1954至1968年為研究期間,選取115家發生財務危機公司,並依行業 別、銷貨淨額、員工人數及會計年度另外選取115家正常公司作為配對樣本。與過去學 者不同的是, Blum 視企業為流動性資產之貯水槽,認為當水槽容量變小、流入量減少、 流出量增加或流出入之變異增加等均會使企業失敗之機率上升,因此 Blum 以現金流量 (cash flow) 為架構,用流動性、獲利性及變異性三類共12項解釋變數來建立模型,搜集 危機發生前8年之財務資料。實證結果發現,以現金流入量/負債、淨值/負債及速動資產 淨額/存貨具有顯著之解釋能力;該模型在財務危機發生前1年之正確區別率高達90%, 前2年為80%,前3年至5年均為70%,比 Altman 模型下之正確區別率高,但超過5年以 上其正確率則逐年下降。. Sinkey (1975) 以1972和1973年為研究期間,選取出110家問題銀行,其中,1972年 選出90家、1973年選出20家;每家銀行再依市場所在、存款總額、聯邦準備之會員地位、 營業單位數目等4項標準,選出110家健全銀行作為配對樣本,並以「現金+美國政府債 券/資產」、「放款總額/資產」、「放款備抵呆帳損失/營業費用」、「放款總額/資本+ 準備項目」、「營業費用/營業收入」、「放款收入/收入總額」、「美國地方政府債券/ 收入總額」、「州及地方政府債券/收入總額」、「存款利息支出/收入總額」、「其他 費用支出/收入總額」等10項財務比率作為研究變數。研究方法係利用 F 檢定、條件剔 除、加權係數、逐步向前選取及逐步向後選取等五種方法,依邊際貢獻之多寡找出能區 別問題銀行與健全銀行之財務比率。實證結果發現,問題銀行在流動性、資本適足性與 收入來源三方面係低於健全銀行;然而,存放比重、放款品質和收入用途三方面則係高 於健全銀行。 8.
(18) Altman, Haldeman, and Naraynana (1977) 鑑於經濟條件隨著時間而改變,原有之 Z-score 模型已經無法解釋財務危機之現象,因此 Altman 等人改用二次式函數之 MDA 對原有 Z-score 模型加以擴充修改。研究樣本為1962至1975年共計53家製造業及 零售業之破產公司,其中包含了5家非自願性破產 (政府援助、重整及銀行接管),並與 58家正常公司進行配對檢定,納入了6項重要之會計調整項目後,以27項財務比率作為 解釋變數,其中有形資產及利息保障倍數以對數之型態表示,以符合常態分配之特性, 再以因素分析法萃取出7項顯著之變數,分別為「稅前息前盈餘/總資產」、「總資產額」、 「稅前息前盈餘/利息費用」、「保留盈餘/總資產」、「流動比率」、「權益市價/總資 本帳面價值」及過去十年「稅前息前盈餘/總資產」之穩定性,此模型即為知名之「ZETA 模型」。實證結果發現,ZETA 模型在失敗前1年之預測能力高達96%,而失敗前5年亦 有70%之準確性。. 國內研究方面,陳肇榮 (民國七十二年) 係以民國六十七至七十一年間發生財務危 機之48家企業,以及依行業別及公司規模配對之48家正常公司作為研究樣本,將全體樣 本劃分為三組:第一組為原始樣本,係民國六十七至六十九年間發生財務危機及其對應 之正常企業共計40家,用以建立區別模式;第二組為保留樣本,仍為上述期間但不同於 原始樣本另外選取20家企業,用以檢定區別能力;第三組為後期樣本,係民國七十至七 十一年間發生財務危機及其對應之正常企業共計36家,用以驗證預測能力。其模型先利 用主成份法 (principal component method) 對32種財務比率進行因素分析,萃取出9個因 素後,再分別依單變量及多變量區別模型建構台灣中、大型企業之財務危機預警模型。 在單變量模型中,以營運資金淨額占總資產比率最具有預測能力;而在多變量區別模型 中,則以速動比率、營運資金占總資產比率、固定資產佔淨值比率、應收帳款收帳天數 及現金流入量占現金流出量比率等5項財務比率具有較佳之預測效果。研究結果顯示, 企業之財務屬性確實能有效建立台灣中大型企業財務危機之區別模型;在單變量與多變 量模型之比較中,兩者之預測能力並無顯著地差異。. 路奎琛 (民國七十八年) 選取民國七十一至七十四年間,失敗與正常公司共21對42 家公司作為研究樣本,解釋變數則選取7項財務比率及3項現金流量比率 (營運活動現金 流量淨額/總資產、營運活動現金流量淨額/總負債、營運活動現金流量淨額/流動負債), 分別建構企業失敗之單變量與多變量區別模型。實證結果顯示,在單變量分析中,營運 9.
(19) 活動現金流量淨額比率可單獨作為一項預測指標,區別正確率在失敗前1年為66.7%、前 2年為72.3%、前3年為77.8%;在多變量區別分析中,由於加入營運活動現金流量淨額比 率於模型中並無法增加其區別能力,故其並不具邊際預測效果。. 王俊傑 (民國八十九年) 選取民國八十七至八十八年間本業經營不善、過度財務擴 張與人謀不臧之企業,共有20家財務危機公司。嘗試以12季之傳統財務比率及現金流量 財務比率共31項作為解釋變數,取代過去以年為期間、傳統財務比率當作解釋變數之作 法。其解釋變數可區別為八大類:財務結構、償債能力、經營能力、獲利能力、現金流 量槓桿、利潤品質能力、現金流量結構及資產運用現金流量比率等。該研究採用1:1配對 方式,依據公司規模、產業性質及業務內容選取正常公司。分析步驟為,先將上述之31 項解釋變數經由因素分析簡化為10個因素,然後再利用逐步區別分析,以瞭解各個因素 對於總預測結果之重要性排序,最後以區別分析之正確率作為驗證此模型之預測能力。 實證結果如下:1.根據逐步區別分析,最重要之前3項因素分別為安全力、現金安全 邊際及收益率指標因素。2.以現金流量指標為核心所代表之現金安全邊際及營業現金效 率因素對於區別能力之解釋較強,且超越許多傳統比率之區別能力。3.二次式區別函數 之正確區別率分別為84%,73%,70%,高於一次式之75%,70%,74%。4.前3季之正 確區別率分別為80%,83%,88%,正確區別率並未隨著財務危機發生之季節到來而隨 之上升。5.根據前3年之總正確區別率,家具、五金、電子及食品等行業之型 I 誤差率 皆超過20%,代表投資人與債權人運用此模型進行預測須特別注意可能之損失。6.就管 理層面而言,正確區別率皆無法達到100%,因此管理當局仍須借重內部之量化與非量 化資訊,以達成控制與規劃之目的。. 隨著眾多學者之研究顯示,現實事件中財務資料大多不符合 MDA 之假設,MDA 也有許多缺點,如對虛擬變數無法有效地處理、模型所得之結果為分數,除了表明全部 樣本之排列順序外其本身不具意義、模型設立只適用線性模型,無法處理非線性情況, 以及樣本選擇偏差對模式之分類能力有很大之影響等。雖然 MDA 有如上之缺點,但 是卻提供了一個簡易分類失敗與否之方法,可作為後續研究一個重要之基石。. 10.
(20) 2.2 迴歸分析模型 2.2.1 線性機率模型 (linear probability model, 簡稱LPM) 最早之迴歸模型為線性機率模型。因為模型使用之因變數為離散型 (discrete) 之虛 擬變數 (dummy variable),假設因變數為 1 (事件發生) 和 0 (事件不發生) 。由於因變數 係二項分配性質,因此其誤差項亦會是二項分配性質,與古典廻歸之常態假設不同,所 以無法利用普通最小平方法 (ordinary least squares method, 簡稱 OLS) 來處理,而必須 採用一般化最小平方法 (general least squares method, 簡稱 GLS) 求得參數估計量。 由於 LPM 使用上亦相當簡易,早期有許多文獻以此模型來分析財務預警。Mayer and Pifer (1970) 首先將 LPM 運用於銀行倒閉預測,以 39 家倒閉銀行為樣本,同時選 取同一地區、設立年數相近之正常營運銀行作為比較。結果顯示,可以成功預測到失敗 前 2 年之倒閉事件,其正確區別率達 80%。 線性機率模型之優點為:1.可解決區別分析中解釋變數非常態之問題。2.模型使用 簡單,解釋變數不須標準化亦不須透過機率分配轉換,即可求得事件發生之機率值。但 最大之缺點為得到之機率值往往會落在 (0,1) 之外,不符合機率假設之前題,有學者認 為這是模型設定之問題,為了使所有觀察值出現之機率值均落在 (0,1) 之間,改用累積 機率函數 (cumulative probability function) 來取代線性機率函數。. 2.2.2 定性選擇模型 (models of qualitative choice) 定性選擇模型主要適用於迴歸模型之因變數為非連續性,且可能具兩種或兩種以上 之定性選擇,例如:判定企業係正常企業或危機企業以及銀行係問題銀行或非問題銀行 之二元選擇 (binary choice)。 依據假設之不同,定性選擇模型可分為 Logit、Probit 及 Probabilistic 三種模型, 適用於非線性情況,三者均係屬質分析方法,其因變數均為離散型型態,即因變數為 1 (事件發生)或 0(事件不發生)。 Probit 模型係假設事件發生之機率符合標準常態分配,Logit 模型係假設事件發生. 11.
(21) 之機率符合 Logistic 分配, Probabilistic 模型則係使用 Cauchy 累積分配函數,其中, 以 Logit 與 Probit 模型最常被使用,此兩種模型之優點係其非線性機率累積函數型式 可以解決線性機率模型中機率值落在(0,1)以外之問題,使得求出之機率值易於解釋, 且符合機率假設之前題;再者,於統計處理之過程中係將事件是否會發生之模型轉換成 以機率之形式表示,並進一步求出事件發生之機率,不像多變量區別分析係直接判斷事 件是否會發生;最後,兩種模型之解釋變數不須像多變量區別分析須符合常態分配之假 設,其模型之參數估計係採用最大概似估計法(maximum likelihood estimation method, 簡稱MLE),所以可以處理非常態性之資料分類。在實證上,由於 Logit 模型其資料處 理較容易、成本較低,故大多數之學者採用 Logit 模型來建立財務危機預警模型。. Ohlson (1980) 是第一位運用 Logit 模型發展企業財務危機預測模式。認為在一般 線性迴歸或區別分析係假設誤差項需符合常態分配,而 Logit model 之優點在於不論自 變數或母體為離散、連續或混合均可分析,並且當自變數母體為未知或非常態時,使用 Logit model 處理區別問題較為可靠。 Ohlson 以1970至1976年間在 NYSE 或 AMEX 上市及上櫃 (over-the-counter) 之 製造業為研究樣本,選擇105家破產公司,並以隨機取樣之方式,選取出2,058家正常公 司作為配對樣本,另選取9項財務比率,分別是公司規模 (總資產除以 GNP 價格指數 後之值再取對數)、負債比率、營運資金比率、流動比率倒數、破產虛擬變數值(總負 債大於總資產設定為1,否則為0)、資產報酬率、損益虛擬變數值(最後2年虧損設定 為1,否則為0)及純益變動率等。 Ohlson 建立3個模型加以分析,模型1:預測1年內 會破產。模型2:預測2年內會破產。模型3:預測1年或2年內會破產。實證結果發現, 模型1之預測能力較佳,且所有係數之符號皆與預期假設相同,除了營運資金比率、流 動比率倒數、損益虛擬變數值不具統計上之顯著性外,其餘變數均具統計上之顯著性, 尤其以公司規模為最重要之變數;另一方面,若以0.5為分界點,則模型1至模型3之正確 區別率分別為96.12%、95.55% 和92.84%。. Zmijewski (1984) 係最早利用 Probit 模型來建構財務危機預警模型,選取1972至 1978年間76家破產公司以及3,880家正常公司進行分析,分別使用未加權 Probit 模型、 加權最大概似法 Probit 模型及雙變量 Probit 模型。Zmijewski 認為財務危機研究大多 會產生兩個問題:1.選擇性基礎偏誤 (choice-based biases):大多數之研究均抽取相同數 12.
(22) 目之正常公司與失敗公司,但實際上,失敗公司只占少數,其結果將使失敗公司之正確 區別率高估,唯有樣本比率越接近母體中失敗公司所占之比例時,此偏誤才會縮小。2. 樣本選擇偏誤 (sample selection biases):具有完整資料才能納入樣本中,但實際上有許 多企業無法具有完整之資料,因此所採用之樣本較難代表母體。Zmijewski 解釋上述兩 種偏差所造成之結果,強調非隨機抽樣方法所造成之偏誤,對於模型整體之區別 (overall classification) 與預測能力並無顯著地改變,在統計之推論上,其解釋也與隨機抽樣並無 不同,差別在於對個別群體之分類與預測會有顯著地影響,而在考慮成本效益後,非隨 機抽樣仍然有其存在之價值。. Genetry, Newbold and Whitford(1985)選取1970至1980年間33家破產公司,另外依 規模及產業別選出33家正常公司作為配對樣本,以8項淨資金流量所組成之因素建立模 型(2項資金來源:來自營業之資金、融資;6項資金用途:營運資金、固定費用支出、 資本支出、股息、其他資產負債流量及現金與有價證券之變動,其中營運資金、現金與 有價證券之變動可能為流入或流出),再將每個資金流量成分除以淨資金流量總額,決 定出個別變數對淨資金流量總額所貢獻之百分比,並對相關變數進行統計檢定,統計方 法有 MDA、Probit 模型及 Logit 模型。檢定結果為資金流量變數對公司失敗預測之能 力以 Logit 模型為最佳,其分類正確率界於77%至83%之間;而在所有解釋變數中,以 股息最為顯著,合理之解釋應是當公司資金流量趨於短缺時,會減少股息發放,隱含著 股利發放愈少,則公司失敗之機率愈大。. Platt and Platt (1990) 認為公司財務比率之資料會隨時間經過而產生不穩定之情 形,不穩定之情形是由經濟循環、企業生命週期、通貨膨脹與利率水準等因素所造成。 這些不穩定之情形會導致估計期間和預測期間不同之分類結果。此外,作者也認為在進 行財務危機之研究時,從不同產業中所抽出之樣本會由於產業間產品之生命週期、競爭 結構、生產因素與行銷方式之不同而造成各產業間財務比率有很大之差異,因此採用 Logit 模型,試圖以產業相對財務比率來降低財務比率之不穩定性。研究結果顯示,採 用原始財務比率之模型,其對失敗企業分類之正確區別率為78%;採用產業相對財務比 率,正確區別率達90%,預測能力比前者較佳。. Hwang, Lee and Liaw (1997) 利用 Logit 模型,對1985到1988年間美國 FDIC 13.
(23) (Federal Deposit Insurance Corporation) annual income and call report 上之銀行進行預測 倒閉模型研究,選取48項財務比率以 Logit 逐步迴歸進行分析,萃取出18項顯著之財務 變數指標,再以全部之財務變數與逐步迴歸後所得之18項財務變數進行比較;同時,也 以本期之實證模型,對下一期進行倒閉預測之研究,並說明若 FDIC 已知銀行之清算成 本,則可依據倒閉預測模型計算出公平之存款保險費率。. Kane, Patricia and Richardson (1998) 主要探討經濟不景氣對公司失敗預警模型預測 能力之影響,樣本取自1968至1990年,選取128家符合失敗企業定義且有完整資料之公 司,並以隨機之方式選取2,000家非失敗公司。該研究以經濟不景氣為解釋變數建立3個 模型,並以 Logit 分析法來比較是否加入不景氣之解釋變數能提高預測之正確率。實證 結果顯示,加入了不景氣之解釋變數確實能提高預測之正確率;再者,該研究提出在經 濟衰退階段,淨利/總資產及現金/總資產兩項解釋變數在失敗預測模型中相當地顯著。. 國內研究方面,陳明賢 (民國七十五年) 為國內最先將 Logit 與 Probit 模型應用於 企業失敗預測。財務危機公司之樣本選自民國七十三至七十四年間,11家發生全額交割 之上市公司,並以 Altman 等學者所提之配對方法,選擇:1.相同產業 (甚至相同的產 品市場、相同的銷貨額)。2.相同規模大小 (固定資產及員工人數)。3.設立公司年數相同, 方能成為配對標準,因此共選取19家相對應之正常企業。在解釋變數方面,依照 Foster (1978) 之分類,選取5大類共計22項財務比率,搜集樣本公司民國六十八至七十二年之 財務報表資料,利用 VISICALC 套裝軟體計算財務比率,再利用 Beaver, Gupta 所提 倡之二分類區分法,即以型 I 加型 II 錯誤率最小為目標,觀察單變數之區別效果,最 後選擇區別能力最佳之9項變數進入第二階段之多變量分析。 在多變量分析中,利用七十二年之財務資料,採取逐步之方式,將各變數陸續代入 Probit 和 Logit 模型,在係數之 t 值檢定以及模型之概似比 (likelihood ratio) 檢定雙重 選擇標準下,發現有3項變數符合標準,分別是流動比率(取對數)、營運資金對總負債之 相對強度及固定資產對淨值比率(取對數)。求出適合之模型後,選擇讓模型中歸類錯誤 率總和最低之一點,令其為模式歸類之分界點,另外再將民國六十八至七十一年 (危機 前2年至前5年) 之資料分別代入 Probit 和 Logit 模型中,求取各年度之預測能力。實 證結果發現,不論是 Probit 或 Logit 模型,前5年之正確區別率皆在80%以上,兩者分 析方法無顯著差異。 14.
(24) 潘玉葉 (民國七十九年) 首先針對台灣之財務比率進行常態性檢定,發現並不符合 常態分配,故並不適合以區別分析作為模型建立之方法,因此改用 Logit 模型分析,以 全額交割日期發生在民國七十一至七十六年間之18家股票上市企業為財務危機公司,並 以產品性質及股本相近之32家企業為正常公司配對樣本,搜集財務危機前5年之資料, 選取20項財務比率作為解釋變數。先用因素分析法逐年萃取因素負荷量 (factor loading) 較大之財務因素,並以各年度之財務共同因素逐年建構財務危機預警模式。實證結果發 現:1.相較於健全公司,危機企業具有低變現性、高財務槓桿及低獲利性之特性。2.危 機前5年中,最後2年以財務槓桿因素最具解釋能力,前3年則以獲利因素之解釋效果為 最佳。3.危機前5年之正確區別率分別為80%、76%、76%、56.25%、72.72%。此外,作 者認為危機發生前4年正確率偏低之原因,在於總體經濟變動之影響,因此若考慮了總 體經濟因素或許會增加模型之穩定性。. 儲蕙文 (民國八十五年) 以民國七十四至七十五年間被列為全額交割股之公司視為 財務危機公司,捨棄1:1配對方式,採用隨機抽樣之方式,以近似母體財務困難及正常公 司分佈之比率抽取樣本,並且將樣本分為原始樣本和期後樣本兩類。採用 Altman 分類 財務變數之方式,搜集財務危機前4年之資料,並將22項財務變數減少為18項,以因素 分析、區別分析和 Logit 模型進行實證研究,實證結果顯示:1.企業失敗為一階段性過 程。2.失敗過程可以用財務比率有效地解釋,且每一階段具重大顯著性之財務因素都不 盡相同。3.針對發生財務困難前4個年度以因素分析法萃取出主要之財務因素,其中因素 負荷量較大者為股東權益報酬率、流動資產百分比、負債比率、應收帳款週轉率、銷貨 成長率、收益率、總資產報酬率等。4.就企業失敗過程而言,在財務困難前3、4年,大 部分之公司可從負債比率之惡化看出端倪,而在財務困難前1、2年,總資產報酬率明顯 地下降。5.以期後樣本對區別函數之穩定性進行驗證,結果顯示該模式之預測能力在失 敗前3個年度均達82%以上。. 林宓穎 (民國九十一年) 針對民國八十八年至民國九十一年一月間,國內非金融業 發生財務危機之上市公司共計32家,以1:2之比率配對同一年度、同一產業且資產規模 相近之正常公司共計60家,採用股票變更交易方式為全額交割股或未經變更交易方式逕 行終止上市作為財務危機發生之時點,而以「盈餘管理」 (earning management) 、「公 司資本結構」 (capital structure) 、「風險控制」 (risk control) 三方面之觀點來建構財 15.
(25) 務危機發生當季與發生前11季之財務危機預警模式。實證模型為二元 Logit 迴歸模型, 經模型驗證得知,模型整體對於是否發生財務危機之預測正確率介於73%至82%之間, 顯示該研究所建立之財務危機預警模式尚足以區別正常公司與財務危機公司。若分別探 討上述三方面之觀點,依據實證之結果,「盈餘管理:若企業進行過度盈餘管理,則易 產生財務危機,其中依我國上市公司特性應收帳款與存貨可能係盈餘管理中最主要項 目。」及「公司資本結構:公司應使用長期資金來源支應長期資產,短期資金來源支應 流動資產」對於判斷是否為財務危機公司之預測並不顯著,不過「風險控制:風險越高 之公司,越易成為財務危機公司」對於判斷是否為財務危機公司之預測呈現顯著之關 係,而且實證結果也顯示,負債比率與發生財務危機之可能性呈現顯著之正向關係;公 司整體之資產規模與發生財務危機之可能性呈現顯著之負向關係;董監事持股質押比例 (the rate of trustees’ mortgaging shares) 與發生財務危機之可能性呈現顯著之正向關係。. 許伯彥 (民國九十二年) 係以公司財務、營運及公司治理 (corporate governance) 變 數建立模型,探討公司財務因素、公司治理因素與財務報表舞弊之關係。以民國八十四 年至九十年間,因為1.重大錯誤依證期會要求公司重編財務報表;2.簽證會計師因簽證 不實受懲戒或控訴;3.公司負責人或經理人因財報不實受控訴等因素作為選取財務危機 公司之標準,共選取41家公司,再依產業別分為鋼鐵、食品、電子、機電及營建業,另 選取與財務危機公司同一年度、行業別相同及發生財務報表舞弊前1年度其資產總額最 接近之同類公司作為對照樣本,採1家問題公司配對5家正常公司,故共選取了201家正 常公司,運用財務報表舞弊前1年或前2年公司財務、營運及公司治理變數進行 Logit 分 析,並提出了7種假說推論。實證結果顯示,7種模型分析中以資產報酬率、負債比率、 來自營運之現金對銷貨比率及董監事持股質押比率等變數與財務報表舞弊有顯著關 聯;當模型中無來自營運之現金對銷貨比率變數時,以董監事持股質押比率與財務報表 舞弊有較顯著關聯,若加入來自營運之現金對銷貨比率變數時,則上述顯著變數將產生 變化,除了來自營運之現金對銷貨比率變數本身具顯著關聯外,亦促使資產報酬率具顯 著關聯,但董監事持股質押比率則為不顯著之變數。. 由於 Logit 和 Probit 兩種模型必須經過轉換方能求得機率值,所以兩者之計算程 序較為複雜,且模型中分界點之決定往往會影響模型之預測能力,因此為其主要之缺點。. 16.
(26) 2.3 迴覆分割演算 (recursive partitioning algorithm, 簡稱 RPA) 迴覆分割演算係一種非參數之分類技術,其所使用之分類法則係對解釋變數作二分 類分割,所以為一種無母數分析方法,因此無解釋變數分配假設之限制,其模型主要之 目的係使整體錯誤分類之成本降至最低。 PRA 之區別過程類似向前逐步迴歸之變數選取方式,其流程圖近似於決策樹 (decision tree) 之形狀,在每一個決策節點 (node) 上,PRA 選擇一解釋變數,同時定義 一個分割值 (critical value) (相當於單變量區法過程),將每一個到達此節點之次樣本 (sub-sample) 分割成二個較小之樣本,亦即形成二個分枝 (branches) (相當於多變量區法 過程),所以 PRA 相當於結合了單變量與多變量區別法。在每一個步驟上,RPA 選擇之 解釋變數係依據最能減少分類行為所產生之期望歸類錯誤成本,並將其分割,此一過程 不斷地重覆,直到期望歸類錯誤成本無法減少為止。. Frydman, Altman, and Kao (1985) 以 1971 至 1981 年間隨機抽取 58 家財務危機公司 與 142 家正常公司,利用 RPA 法來分析,實證結果顯示其正確區別率達 85%至 94%之 間。. 此模型對使用者而言頗具方便性,然而缺點係分類工作繁複、分割點建立不易、模 型穩定性和統計特性未健全及不同公司或不同產業間之相對績效表現無法用此模型來 加以評估,因此實用性上成效並不佳。. 17.
(27) 2.4 類神經網路 (artificial neural networks, 簡稱 ANN) Logit 或 Probit 模型中分界點之決定,往往會影響模式之預測能力,而且需要對變 數做先驗假設,故有學者提出類神經網路模型來解決此問題;另一方面,隨著電腦運算 能力之增強,財務預警系統開始引入了人工智慧 (artificial intelligence) 之概念,此技術 源於意圖模擬人類之腦部在圖形與語音辨識方面之強大能力,開發出以「類神經」計算 原理為基礎之處理模式。 類神經網路是一種電腦資訊處理技術,其基本架構可分為「輸入層 (input layer)」、 「隱藏層 (hidden layer)」和「輸出層 (output layer)」,每一層均包含若干處理單元之「節 點」。輸入層之節點負責外在資訊之接收,隱藏層之節點則是將接收之訊息予以處理, 並轉化結果至輸出層,而輸出層之節點負責將最終結果之判定輸出,其資料之重要程度 可用「權值」大小來表示。 類 神 經 網 路 模 型 眾 多 , 其 中 運 用 最 廣 的 是 倒 傳 遞 網 路 (back-propagation networks) ,其屬於監督式學習 (supervised learning) 之類神經網路,在學習時會將錯誤 之訊號反饋回來,用以修正神經元連結之權值。應用在財務預警系統領域中,即以輸入、 輸出所組成之資料,經過訓練和學習加以模式化來建立系統模型 (即輸入與輸出之關 係) ,然後藉此推估、預測與診斷企業之經營狀況。由於類神經網路不需符合多變量區 別分析之諸多假設,係一種「資料訓練」之過程,又能處理非量化之變數,其優點為適 應性強、具有高容記憶能力、學習能力、平行運算能力、歸納能力及擁有容錯能力等特 性,故愈來愈多之學者以類神經網路建立財務危機預警模型。. Odom and Sharda (1990) 比較類神經網路和多變量區別分析模型之不同,選取1975 至1982年間65家財務危機公司並與64家正常公司進行配對,將樣本劃分為訓練樣本和保 留樣本,並以 Altman (1968) 所提出之 Z-score 分析中之5項財務比率,擷取公司財務 危機前1年之資料來建立類神經網路與多變量區別分析兩個預警模型。實證結果顯示, 在訓練樣本中,多變量區別分析和類神經網路模型之正確區別率分別為84.86%和 100%;而保留樣本之驗證方面,其正確區別率分別為81.18%和74.28%,整體而言,類 神經網路在企業財務危機之預測上,較區別分析模式佳。. 18.
(28) Tam and Kiang (1992) 首次利用類神經網路、多變量區別分析、 Logit 模型、決策 樹等多種分析方法來建構財務預警模式,研究樣本為1985至1987年共59家危機銀行,並 採取1:1之配對方式,產生59家正常銀行,另選用19項財務指標,以財務危機前2年之資 料建立預警模型。實證結果發現,財務危機前1年以類神經網路之正確區別率為最高, 達到85.2%,而失敗前2年之正確區別率則以 Logit 模型為最高。. Coats and Fant (1993) 採用 Altman (1968) 所提出之 Z-score 分析中之5項財務比 率作為研究變數,研究範圍係1970至1989年間自 Standard & Poor’s Compustat 之財務資 料隨機抽取94家財務危機公司及188家正常公司作為研究樣本,分別以多變量區別分析 及類神經網路 (瀑布關聯網路) 建立財務危機預警模型,並比較兩個模型之預測能力。 實證結果顯示,類神經網路模型之預測能力較佳,對危機公司之正確區別率達91%,對 正常公司之正確區別率達96%;而多變量區別分析對危機公司之正確區別率為72%,對 正常公司之正確區別率為89%。. Zhang, G., et al. (1999) 利用類神經網路及 Logit 模型建立企業破產預測模型,並透 過5種不同組合樣本交叉驗證分析法 (cross-validation analysis) 來比較兩模型之優劣。實 證中以1980至1991年間美國製造業110家破產公司配對220家健全公司作為研究對象,採 用6項財務比率建立模型。研究結果顯示,類神經網路模型之正確區別率為88.18%,高 於 Logit 模型78.64%之正確區別率。. 國內研究方面,郭瓊宜 (民國八十三年) 是第一篇以類神經網路建立財務危機預警 模型之研究,研究範圍是民國七十至八十二年間列為全額交割股之23家上市公司,並選 取相同產業、規模相近之44家正常公司與之配對,另外依財務結構、經營效能、獲利能 力、變現性、與成長性等5大財務構面擷取出20項財務比率作為研究之解釋變數。分析 步驟係先以因素分析法萃取出具有代表性之財務比率作為類神經網路之輸入變數,再運 用模擬、比較之方式決定最佳模型,最後則以保留樣本驗證模型之預測能力;另一方面, 也利用上述之資料建立 Logit 模型,作為與類神經網路模型對照比較之用。研究結果發 現,在類神經網路中,以財務危機發生前2年之正確區別率最高,原始樣本達高98.08%, 且型 I 誤差率係零,保留樣本也有89.44%之正確率;而在 Logit 模型中,則以危機發 生前1年之模型最好,原始樣本之正確區別率為83.5%,保留樣本為74.51%,但 Logit 模 19.
(29) 型之型 I 誤差率偏高,值得注意。總體而言,類神經網路在區別正常與危機公司方面 之表現,大多優於 Logit 模型。. 卓怡如 (民國八十四年) 以民國六十六至八十三年間27家上市危機公司配對60家正 常公司及27家未上市危機公司配對58家未上市正常公司作為研究對象,該研究採用財務 比率、產業相對比率、財務比率變動及產業相對財務比率變動四類財務變數,分別建立 Logit 模型與倒傳遞類神經網路。研究結果顯示,在原始樣本方面,類神經網路之正確 區別率高達95%以上,較 Logit 模型所得到之80%正確區別率來得高;而保留樣本方 面,兩模型之正確區別率差不多,總括來說,類神經網路為較佳之預警模型,而在四類 變數中,係以產業相對財務比率之正確區別率為最佳。. 池千駒 (民國八十八年) 研究範圍係民國七十至八十七年十二月底被證交所列為 全額交割股或下市或主動向財政部申請暫停交易之44家上市公司,將樣本分為兩類進行 實證研究,第一類樣本組以列為全額交割股和暫停交易之公司作為財務困難公司,共計 40家;第二類樣本組僅以列為全額交割股之公司作為財務困難公司,共計30家。配對樣 本方面,以資產規模、產業別相似之正常公司與之配對。該研究將解釋變數分為4類: 1.財務比率。2.財務比率趨勢。3.非財務變數。4.總體經濟變數。其中,財務比率趨勢乃 係針對財務困難發生前5年之財務比率,以年度為 x 軸,財務比率為 y 軸,利用 OLS 計算斜率來衡量其趨勢。所使用之方法學為 Logit 模型及倒傳遞類神經網路,實證結果 發現:1.將 OLS 所計算之財務比率趨勢納入 Logit 模型中,可增加模型之正確區別 率。2.非財務變數中會計師之變動,能增加模型之正確區別率,亦即非財務變數係公司 發生財務困難之徵兆。3.由於財務困難公司與正常公司之樣本比例為1:1,因此總體經 濟變數無法在模型中看出其解釋能力,若想要顯示出總體經濟之影響,則可能要設計其 他樣本配對方式。4.倒傳遞類神經網路之區別正確率優於 Logit 模型。. 雖然類神經網路無須任何機率分配假設,也擁有適應性強、具有學習能力、平行運 算能力、歸納能力、容錯能力及高容記憶能力等特性,並可作多層等級判斷問題等優點, 但是由於較缺乏嚴謹之統計理論基礎,且在樣本數不多之情況下,必須減少輸入向量數 目來簡化網路複雜度,另外也可能會產生模型不易收斂之問題,故此方法學仍有待改善 之處。 20.
(30) 2.5 倖存分析 (survival analysis) 隨著統計方法之進步,財務預警模型不斷之改善,區別能力已大幅提高,然而既有 之預測模型大多把研究焦點放在失敗與正常企業之正確區別率,所提供之資訊都僅限於 「診斷」失敗之發生,對於正常企業轉變為失敗企業之時點,皆無法做預測,故參考 Cox (1972) 提出之「存續時間」(duration) 觀念,以此概念所發展之模型即為倖存分析。 倖存分析模型在過去一直被廣泛地應用在生物醫療之研究上,近幾年來才開始引入 到金融管理領域。主要係分析當生存資料受其他變數影響下之存活函數 (survival function) 及危險函數 (hazard function)。根據 Cox 之方法,可以藉由觀察樣本之存續時 間來預估個體之危險比率 (hazard rate) 與進行存續時間之預測,增強了模型所提供之資 訊價值,故倖存分析又可稱之為「危險模型」(hazard model) 或「Cox 模型」。 倖存分析模型可分為無參數模型 (nonparametric model)、半參數模型 (semiparametric model) 及參數模型 (parametric model) 等三大類別,在應用方面,二種模型較為普遍,其. 一為「加速失敗時間模型」 (accelerated failure time model),係強調停留狀態下之時間 與存活函數之關係;其二為「比率危險模型」(proportional hazard model, 簡稱PHM),係 強調個體間之危險函數係呈現比率關係。倖存分析之優點為該模型納入了隨時間變化之 解釋變數向量,能夠有效地使用公司所有之歷史資料來分析,所以可預測取樣公司在樣 本期間內每一個時間點發生財務危機之機率;再者,倖存分析模型之參數估計式具有一 致性及不偏性之性質,因而可得到較佳之統計推論;最後,該模型避免了其他財務預警 模型中普遍存在之樣本選擇偏誤之問題,因此所採用之樣本近似於母體。. Lane, Looney, and Wansley (1986) 係第一篇將生物醫學界常用之 Cox 比例危機模 型應用於財務金融之領域,其研究目的係應用 Cox 模型進行金融機構倒閉之預測,樣 本之研究期間為 1979 至 1983 年,選取 130 家失敗銀行並以 334 家正常營運銀行作為配 對樣本,利用 21 項財務比率進行分析,建立金融機構倒閉預警模型,並將 Cox 比例危 險模型與區別分析模型做比較。實證結果發現,兩種分析方法在總分類之正確率上無顯 著差異,但是 Cox 模型卻有較低之型 I 誤差率。該研究發現利用失敗前 1 年之資料, Cox 模型可得到 4 項顯著之變數,分別為 log (工商業貸款/總貸款)、總貸款/總存款、log (總資本/總資產)及 log (總營業費用/總營業收入);利用失敗前 2 年之資料,Cox 模型可 得到 6 項顯著之變數,分別為 log (內部擔保/總資產)、總貸款/總資產、log (工商業貸款 21.
數據




+7





相關文件
The study explore the relation between ownership structure, board characteristics and financial distress by Logistic regression analysis.. Overall, this paper
– 某人因為與上市公司有關連,即內幕人士 (如公司董事、職員或公司的 核數師等)
專門服務 處理危機 及早識別 支援家庭 宣傳教育 預防問題... •人們利用本身與兒童之間權力差異的特殊 地位 (如年齡、身分、知識、組織形式)
在軟體的使用方面,使用 Simulink 來進行。Simulink 是一種分析與模擬動態
圖 2-13 顯示本天線反射損耗 Return Loss 的實際測量與模擬圖,使用安捷倫公司 E5071B 網路分析儀來測量。因為模擬時並無加入 SMA
住宅選擇模型一般較長應用 Probit 和多項 Logit 兩種模型來估計,其中以 後者最常被使用,因其理論完善且模型參數之估計較為簡便。不過,多項
若股票標的公司的財務體質不健全,或公 司管理階層刻意隱瞞經營危機事實,導致
1970 年代末期至 1995 年:許多農業生技公司開始投入研發以迄 1995 年第 一個產品上市。Monsanto 為此時期最早的投資者,且為第一個將農業生技產 品上市的公司,其他如 Syngenta 與
