探討合成型抵押擔保債券憑證之評價-非大樣本一致性資產組合 - 政大學術集成
51
0
0
全文
(2) 謝辭 記得當初進入研究所,還是個懵懂無知的大學畢業生,雖然現下也不是學識 淵博的研究生,但經過這兩年的時間,學習到研究學問的本質,不同於大學,老 師於台上授課,學生於台下仔細聆聽,作為一個單方面接受的角色,培養獨立思 考的能力;而作為碩士研究生,我學習到獨立挖掘問題,不管是論文方面,統計 學相關的研究,或者是前些日子炒得沸沸揚揚的太陽花學運…等等社會議題,經 由研究所思考上的訓練,現在更能站在一個問題的核心之上,去質疑、去反省、. 政 治 大 感謝我的指導教授劉惠美老師,謝謝老師不厭其煩地給我建議,在論文的研 立. 以及去找尋問題背後的答案,研究所生活教會我的就是追求真理的能力吧。. ‧ 國. 學. 究過程中,不斷地遭遇困難,老師屢屢鼓勵我,激勵我,並且在沒進到職場之前, 給我們未來職涯的方向,非常感謝老師,我很高興當初做了一個明智的決定,遇. ‧. 到劉老師,也感謝洪明欽以及劉家頤老師,在論文內容給予寶貴的意見。感謝我. sit. y. Nat. 的同學信源和柏魁,他們倆在我學業上跟不上進度的時候,教導我,以及志旻,. al. er. io. 我最好的朋友,時常在心情不好之際,提供餵食,還有煒融,我次好的朋友,我. v. n. 們倆在垃圾話的領域進行深度的交流,得到精進,抒發彼此的心情。最後,是我. Ch. engchi. i n U. 的日文所室友豆腐,在和政大還不熟的時候,有政大地頭蛇的介紹,讓我快速地 熟悉政大。 在政大的日子,認識不少有趣的人們,可愛的人們,希望未來可以多聚聚, 最後要感謝的人太多了,那就謝天吧! 謹以此文獻給我最愛的家人。. i.
(3) 摘要 在評價合成型抵押擔保債券憑證時,需考慮多個標的資產間之違約相關性。 根據過去評價合成型抵押擔保債券的文獻研究,發展高斯分配等單因子關聯結構 模型,在給定LHP假設之下,執行各分券評價時,僅有在權益分券(equity tranche) 得到好的配適結果,還會造成相關性微笑曲線(correlation smile)等問題。文獻研 究,單因子關聯結構模型若能加入厚尾度或偏斜性能夠改善以上問題,且對於分 券評價時也會有較好的效果,像是Kalemanova et al. (2007)提出應用LHP假設之. 政 治 大 模型,來評價抵押擔保債權憑證。進一步發現,全世界主要的信用違約指數的標 立 單因子NIG關聯結構模型,或是Dezhong et al. (2006)提供之單因子關聯結構延伸. ‧ 國. 學. 的資產個數不一,最少有14個標的資產(CDX.EM),最多有125個標的資產(iTraxx Europe),事實上標的資產個數均不多,而過去文獻常建立在大樣本假設下進行. ‧. 抵押擔保債券之評價,本文研究目的在於,針對單因子高斯關聯結構模型,建立. sit. y. Nat. 單因子高斯關聯結構延伸模型,假設在非大樣本性質下,評價合成型抵押擔保債. al. er. io. 券憑證,嘗試觀察是否有較佳的估計結果,改善相關性微笑曲線的現象。本文將. v. n. 利用常態分配、NIG分配以及非大樣本之常態分配作為不同的單因子關聯結. Ch. engchi. i n U. 構模型,藉由絕對誤差極小化方法,針對不同商品結構的合成型抵押擔保債券評 價,並進行模型比較分析。實證結果顯示,非大樣本之常態分配關聯結構模型與 LHP假設下的單因子高斯關聯結構模型有類似的評價結果,但在近兩年(2012年、 2013年)的實證分析結果顯示,非大樣本之常態分配關聯結構模型於前四分券評 價結果上符合同質性假設,即各個資產對共同因子的相關性近乎相同。. 關鍵字:合成型抵押擔保債券憑證、單因子關聯結構模型、常態分配、NIG分配、 Large Homogeneous Portfolio ii.
(4) 目錄 謝辭 ................................................................................................................................ i 摘要 ............................................................................................................................... ii 表目錄 .......................................................................................................................... iv 圖目錄 ........................................................................................................................... v 第一章 緒論 ................................................................................................................. 1 第一節. 研究背景與動機.................................................................................... 1. 第二節 研究目的................................................................................................ 2. 政 治 大 信用違約交換(Credit 立 Default Swaps ,CDS)......................................... 5. 第三節 抵押擔保債券(Collateralized Debt Obligation, CDO) ......................... 3 第五節. ‧ 國. 學. 第六節 信用違約指數(Credit Default Indexes) ................................................ 6 第七節 本文架構.................................................................................................. 8. ‧. 第二章 文獻回顧 ....................................................................................................... 9. sit. y. Nat. 第一節 關聯結構模型(Copula Model)............................................................... 9. al. er. io. 第二節 單因子關聯結構模型(One Factor Copula Model) ............................... 10. v. n. 第三節 Normal Inverse Gaussian Distribution (NIG) ........................................ 13. Ch. engchi. i n U. 第三章 合成型 CDO 之評價方法與單因子關聯結構模型 ..................................... 13 第一節 合成型抵押擔保債券憑證之評價方法................................................ 14 第二節 應用 LHP 假設之單因子高斯關聯結構模型 ...................................... 17 第三節 非大樣本假設下的單因子高斯關聯結構模型.................................... 22 第四章 實證分析:評價 DJ iTraxx .......................................................................... 26 第一節 比較各模型在不同時期 DJ iTraxx 之分券評價 ................................. 28 第二節 觀察各模型在不同時期 DJ iTraxx 之隱含相關性 ............................. 32 第五章 結論與建議 ................................................................................................... 40 參考文獻 ..................................................................................................................... 44 iii.
(5) 表目錄 表 1. 1 目前全世界主要的信用違約指數名稱............................................................ 7 表 1. 2 信用違約指數及分券市場報價(2004.8.4),資料來源 Dezhong (2006) ...... 8 表 4. 1 各時期市場報價.............................................................................................. 28 表 4. 2 市場報價及不同模型配適結果(2006 年 4 月 12 日) .................................. 30 表 4. 3 市場報價及不同模型配適結果(2009 年 3 月 31 日) .................................. 31. 政 治 大. 表 4. 4 市場報價及不同模型配適結果(2010 年 3 月 31 日) .................................. 31. 立. 表 4. 5 市場報價及不同模型配適結果(2011 年 9 月 30 日) .................................. 31. ‧ 國. 學. 表 4. 6 市場報價及不同模型配適結果(2012 年 1 月 31 日) .................................. 32 表 4. 7 市場報價及不同模型配適結果(2013 年 3 月 28 日) .................................. 32. ‧. 表 1 不同模型在 2006 年 4 月 12 日之各分券隱含相關值..................................... 34. y. Nat. sit. 表 2 不同模型在 2009 年 3 月 31 日之各分券隱含相關值..................................... 35. n. al. er. io. 表 3 不同模型在 2010 年 3 月 31 日之各分券隱含相關值..................................... 36. i n U. v. 表 4 不同模型在 2011 年 9 月 30 日之各分券隱含相關值 ..................................... 37. Ch. engchi. 表 5 不同模型在 2012 年 1 月 31 日之各分券隱含相關值..................................... 38 表 6 不同模型在 2013 年 3 月 28 日之各分券隱含相關值..................................... 39. iv.
(6) 圖目錄 圖 1. 1 抵押擔保債券架構流程.................................................................................... 4 圖 1. 2 合成型抵押擔保債券架構流程........................................................................ 5 圖 1. 3 信用違約交換架構流程.................................................................................... 6 圖 1 不同模型在 2006 年 4 月 12 日之各分券隱含相關曲線................................. 34 圖 2 不同模型在 2009 年 3 月 31 日之各分券隱含相關曲線................................. 35 圖 3 不同模型在 2010 年 3 月 31 日之各分券隱含相關曲線................................. 36. 政 治 大 圖 5 不同模型在 2012 年立 1 月 31 日之各分券隱含相關曲線................................. 38 圖 4 不同模型在 2011 年 9 月 30 日之各分券隱含相關曲線 ................................. 37. ‧. ‧ 國. 學. 圖 6 不同模型在 2013 年 3 月 28 日之各分券隱含相關曲線................................. 39. n. er. io. sit. y. Nat. al. Ch. engchi. v. i n U. v.
(7) 第一章 緒論 本章說明研究背景與動機以及研究目的,接著介紹本文中的主要評價商品 (合成型抵押擔保債券)與其相關商品。. 第一節 研究背景與動機 衍生性金融商品是一種涉及買賣的金融工具,這種買賣工具的報酬率是根據. 政 治 大 物價指數)等。這些要素的表現情況會決定衍生工具的報酬率。而信用衍生性商 立. 金融要素衍生出來的,例如資產、利率、匯率或者各種指數(股價指數、消費者. ‧ 國. 學. 品(Credit Derivatives)是衍生性金融商品的一種,指買賣雙方,一方繳付權利金, 將信用風險轉讓另一方。而金融風險的價差則為後者獲利的金額。自 1990 年左. ‧. 右開始,以管理標的資產的信用風險的信用衍生性金融商品漸漸成為金融交易市. sit. y. Nat. 場中的大宗。隨著金融市場的演變,金融機構所面臨的信用風險已從單一標的資. al. er. io. 產轉變為多標的資產的組合信用風險。如何控管資產組合的信用風險儼然成為一. v. n. 項重要議題,而金融機構漸漸重視以信用衍生性金融商品為基礎所創新而成的商. Ch. engchi. i n U. 品,如一籃子信用違約交換(Basket Credit Default Swaps)、抵押擔保債券 (Collateralized Debt Obligation, CDOs)以及合成型抵押擔保債券憑證(Synthetic Collateralized Debt Obligation, Synthetic CDOs),以上三種管理信用風險的商品將 於下面小節介紹,其中抵押擔保債券商品還具有固定收益的功能。為了增加信用 衍生性商品的流動性及交易透明度,金融市場更進一步訂定標準化契約之信用違 約交換指數(Credit Default Swaps Index),此指數提供了金融機構以較便宜的交易 成本達到一籃子信用違約交換避險效果。目前市場上主要有兩大類信用違約交換 指數:iTraxx 指數及 CDX 指數。. 1.
(8) 以抵押擔保債券為主的信用衍生性商品發行量在 2000-2006 年間迅速成長。 在這段期間,由於抵押擔保債券所帶來的龐大效益,市場參與者積極鼓勵貸放機 構嘗試不同種類貸款類型。貸放機構也對於借款者的貸款限制逐漸放寬,本身屬 於信用品質較差的借款者也能夠獲得大量貸款,即為次級貸款。這群次級貸款借 款者使得信用市場違約率大幅度提高,也成為了 2007 年美國「次級房貸」 (subprime-mortgage)風暴的導火線,此次事件也連帶影響到整個國際金融情勢, 像是歐洲的「歐債危機」。由於這幾件國際重大經濟事件,對於全球的抵押擔保 債券價格及發行量帶來了相當大的衝擊,影響了抵押擔保債券之商品結構,使其. 治 政 大 2008 年之後的不同 擔保債券價格時,商品結構皆為同一種型式,因此本文將對 立. 逐漸產生變化。自 2008 年起,商品結構開始出現變化,而以往評價合成型抵押. 商品型式之合成型抵押擔保債券價格進行評價,以了解近年來商品發展趨勢與未. Nat. er. io. sit. 第二節 研究目的. y. ‧. ‧ 國. 學. 來改善之道。. al. n. v i n 在評價合成型抵押擔保債券憑證時,需考慮多個標的資產間之違約相關性。 Ch engchi U. 最早描述違約相關性的模型,出現在 Li (2000)的關聯結構模型(Copula Model),. 然而,必須透過大量模擬來取得各資產的違約時間,在大樣本的標的資產組合下 會提高運算過程中的困難度。此後更進一步延伸為高斯分配等單因子關聯結構模 型,其在執行各分券評價時,僅有在權益分券得到好的配適結果,此外,還會造 成相關性微笑曲線等問題。Dezhong et al. (2006) 則提供了單因子關聯結構延伸 模型,希望藉由具有厚尾性質的函數來改善舊有的單因子關聯結構模型。但是, 由於 t 分配沒有穩定的摺積性(convolution),必須使用數值積分的方式求解違約 門檻值,會增加計算所需的時間。Kalemanova et al. (2007) 提出應用 LHP 假設. 2.
(9) 之單因子 NIG 關聯結構模型,其評價結果遠優於常態分配,但其高估了中間順 位層級以上的分券。邱嬿燁(2007)使用 CSN 分配(Closed skew normal)取代 NIG 分配來做抵押擔保債權憑證分券的評價,但與單因子常態關聯結構模型相同,單 因子 CSN 關聯結構模型仍無法估計的很準確,只有在最高等級分券(senior tranches)的評價上有明顯的改進。邱嬿燁(2007)嘗試使用 NIG 及 CSN 複合分配 MIX 分配之單因子關聯結構模型評價抵押擔保債權憑證,而在實證分析中此模型得到 極佳的評價結果。林聖航(2012)使用不同的單因子關聯結構模型,針對不同商品 結構的合成型抵押擔保債券評價,觀察以上的模型是否能應用在新型的合成型抵. 治 政 大 構模型會是最佳的評價模型。本文研究目的在於,針對單因子高斯關聯結構模型 , 立 押擔保債券,並對各種商品型式進行模型比較分析,得知單因子 NIG(2)關聯結. 建立單因子高斯關聯結構延伸模型,假設在非大樣本性質下,評價合成型抵押擔. ‧ 國. 學. 保債券憑證,嘗試觀察是否有較佳的估計結果,改善相關性微笑曲線的現象。. ‧. Nat. n. al. er. io. sit. y. 第三節 抵押擔保債券(Collateralized Debt Obligation,. Ch. CDO). engchi. i n U. v. 抵押擔保債券屬於資產擔保證券 (asset-backed securities)的衍生性商品。其 證券化過程為有一個金融機構持有一大筆債權的資產群組,金融機構將其資產群 組轉售給特殊目的機構(SPV),而特殊目的機構將其切割和重新包裝後,以私募 或公開發行方式賣出固定收益證券或受益憑證給投資人,整個架構流程如圖 1.1。 抵押擔保債券較為特別的部分是將受益憑證分層級,以吸引不同風險偏好 的投資人,其架構為債務人每月定期償還本金和利息給服務機構,服務機構扣除 服務費用後移交給特殊目的機構,特殊目的機構扣除信託費用後交給投資人,首. 3.
(10) 先由優先順位層級(Senior Tranche)投資人先收到利息,等到優先順位投資人收 到足額利息後,中間順位層級(Mezzanine Tranche)投資人才開始收到利息,等 到中間順位投資人收到足額利息後,次順位(Junior Tranche)投資人才開始收到 利息,本金的償還也以此方式進行。付清三個層級後,剩餘現金才支付給權益層 級(Equity Tranche)投資人。 此外,發生損失時,則由權益層級的投資人先承擔損失,之後由次順位層級 的投資人承擔損失,依此類推,最後由優先順位的投資人承擔損失。因此權益層 級投資人所承擔的風險最大,但其報酬率最高,而優先順位投資人所承擔的風險 最小,其報酬率也是最小。 現金. ‧ 國. 特殊目的機構(SPV). 現金. 出售. 發行收益證券. ‧. 資產群組. 投資人. 學. 金融機構. 立. 政 治 大. er. io. sit. y. Nat. n. al. i n C 圖 1. 1h抵押擔保債券架構流程 engchi U. v. 優先順位 中間順位 次 順 位 權益層級. 第四節 合成型抵押擔保債券(Synthetic CDOs). 合成型抵押擔保債券的商品結構大抵上與抵押擔保債券相同,最大的不同在 於,在合成型抵押擔保債券中,金融機構與特殊目的機構會簽訂信用違約交換 (Credit Default Swaps)合約,將債權群組可能會發生的違約風險移轉給特殊目 的機構,由特殊目的機構承擔風險,而金融機構會定期地給予特殊目的機構權利 金,作為其承擔風險的代價。 4.
(11) 因此,整個過程資產群組並沒有被真實移轉,仍然保留在金融機構中。而特 殊目的機構則會在期初會先收到由投資人所投入的大筆金額,且並不需要付任何 費用給予金融機構。特殊目的機構就能藉由此筆金額去購買穩定的收益商品,以 便準備發生違約事件有能力支付現金給金融機構。而特殊目的機構可將從金融機 構定期收到的費用移轉給投資人作為定期投資收益,其中合成型 CDO 架構流程 如圖 1.2。 違約事件發生時 支付現金 CDS S 定期支付 權利金. 立. 資產群組. 特殊目的機構(SPV). 投資人. 政 治 大. 優先順位. 政府公債. ‧ 國. 學. 中間順位 次 順 位 權益層級. y. ‧ 圖 1. 2 合成型抵押擔保債券架構流程. io. er. Nat. al. v i n Ch 信用違約交換(Credit Default Swaps ,CDS) engchi U n. 第五節. 發行收益證券. sit. 金融機構. 現金. 信用違約交換是信用衍生性商品的一種,主要目的是持有資產的一方本身不 願承受或無能力承受違約風險所簽訂的一種合約,CDS 的內容是保護買 (pr-otection buyer)為了規避信用風險與保護賣方(protection seller)簽訂合約,在約 定時間內將資產的信用風險移轉給保護賣方並定期支付權利金給予對方,由對方 承擔資產信用風險的代價,當標的資產違約事件時,保護賣方必須給付一筆金額 給保護買方當作資產違約的損失,所以實際上承擔違約風險的為保護賣方,保護 買方則透過信用風險的移轉使投資的風險降低,其中信用違約交換架構如圖 1.3。 5.
(12) 定期支付權利金 保護買方. 保護賣方 違約事件發生時. 方. 補償保護買方的損失. 標的資產 圖 1. 3 信用違約交換架構流程. 在信用違約交換中,若保護買方考慮的是多個標的資產,則該類型的信用違. 政 治 大 N 個或 N 個以上發生違 違約交換,即買賣雙方約定當所標的的資產組合中,有 立 約交換合約稱為一籃子信用違約交換。最常見的一籃子信用違約交換為第 N 個. ‧. ‧ 國. 學. 約時,保護賣方必須立即支付保護買方因資產違約而造成的損失。. 第六節 信用違約指數(Credit Default Indexes). y. Nat. er. io. sit. 信用違約指數是信用衍生性商品之一種,該商品增加了信用商品的流動性及 減少買賣價差。信用違約指數的運作方式為選擇市場上流動性較高公司的信用違. al. n. v i n 約交換作為一籃子資產,然後將這群資產以平均加權(Equal Weight)的方式計算其 Ch engchi U 權利金。信用違約指數等同於購買許多單一的信用違約交換合約,且其能減少交. 易成本,但在權利金支付方面則有些許不同,以信用違約指數來說,發生違約事 件時,保護買方立即停止支付權利金給保護賣方。每隔六個月信用違約指數會定 期地依照標準調整其指數成員,若指數的標的資產都沒有發生違約情況,則該指 數的成員維持不變,而發生違約或信用等級下降的標的資產則從指數成員中移出。 因此在合約期間發生數個標的公司違約情況,使需要被保護的資產個數減少,連 帶地降低了本金金額,所以保護買方定期支付的權利金金額會與剩餘的本金金額 成比例。. 6.
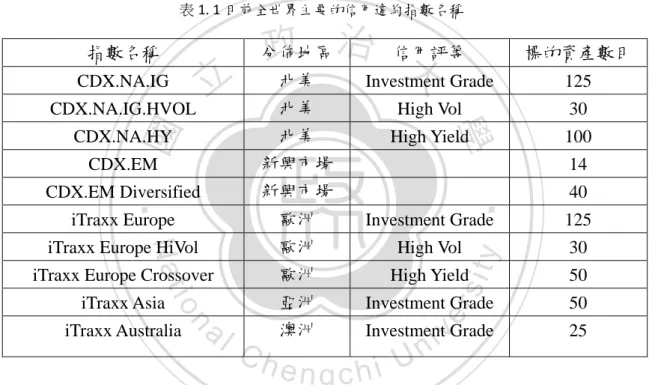
(13) CDX 指數與 iTraxx 指數是目前市場的兩個主要信用違約指數。前者的涵蓋 範圍為北美和新興市場的企業,由 CDS 指數公司(CDS Index Company)所管理並 由 Markit 集團有限公司(Markit Group Limited)發行;後者則涵蓋了其他地區,由 國際指數公司(International Index Company, IIC)所管理並由 Markit 集團有限公司 (Markit Group Limited)發行。目前全世界主要的信用違約指數如表 1.1,各信用 違約指數根據三大信用評等公司(S&P、Moody's 以及 Fitch rating)的評等結果可 分為投資級(Investment Grade)、高風險(High Vol)以及高收益(High Yield)。 表 1. 1 目前全世界主要的信用違約指數名稱. 指數名稱. 政 治 信用評等 大 北美 Investment Grade. 分佈地區. 立 CDX.NA.IG.HVOL. High Vol. CDX.NA.HY. 北美. High Yield. CDX.EM. 新興市場. CDX.EM Diversified. 新興市場. iTraxx Europe. 歐洲. Investment Grade. ‧. 125. iTraxx Europe HiVol. 歐洲. High Vol. 30. iTraxx Europe Crossover. 歐洲. High Yield. 50. 亞洲. Investment Grade. 50. 澳洲. Investment Grade. io. al. n. iTraxx Australia. Ch. 100 14. er. Nat. iTraxx Asia. 30. 學. ‧ 國. 北美. y. 125. sit. CDX.NA.IG. 標的資產數目. engchi. i n U. v. 40. 25. 隨著信用違約指數的發展,合成型抵押擔保債券商品的概念也被導入信用違 約指數中,亦即將指數分割成不同層級的標準化分券型式以吸引不同風險偏好的 投資者。而之前提到的兩大信用違約指數−CDX 指數和 iTraxx 指數被分為五個 分券,分別是權益分券、次順位分券、中間層級分券、優先層級分券和最高層級 分券。CDX 指數的標準化分券架構為 0-3%、3-7%、7-10%、10-15%以及 15-30%;iTraxx 指數的標準化分券架構為 0-3%、3-6%、6-9%、9-12%以及 12-22%。 投資人在各分券中可得到的投資報酬分為兩大類,第一類的投資人在訂立契約的 期初,會收到一筆等同市場報價的預付費用(upfront payment),並可在每一期拿 7.
(14) 到信用價差(running spread),而第二類的投資人只會定期地在每一期拿到信用價 差。在 2008 年以前,只有權益分券為第一類報酬方式,其餘分券則為第二類報 酬方式,如表 1.2。而 2007 年美國發生「次級房貸」以後,一連串的金融危機事 件使得較高層級分券的違約率增加,連帶地讓以信用違約指數為標的的合成型抵 押擔保債券商品在商品結構上產生了變化,在次順位分券以上,投資人得到報酬 的方式漸漸趨向第一類,到了現今,各分券的報酬方式皆為第一類,且不同分券 會有不同的期初市場報價及信用價差價格。本文將評價以 iTraxx 指數為標的之 不同商品結構的合成型抵押擔保債券。. 政 治 大. 表 1. 2 信用違約指數及分券市場報價(2004.8.4),資料來源 Dezhong (2006). 立. 3-7%. 70bp. 7-10%. 43bp. 10-15%. io 20bp. al. 分券. 15-30%. n. 12-22%. 168bp. y. 9-12%. 0-3%. Nat. 6-9%. 27.6%. Ch. 63.25bp 市場報價 48.1% 347bp 135.5bp. sit. 3-6%. 信用違約指數. 47.5bp. er. 0-3%. ‧ 國. 分券. 42bp 市場報價. ‧. 信用違約指數. CDX.NA.IG(5 年). 學. iTraxx Europe(5 年). n U engchi. iv. 14.5bp. 第七節 本文架構 本文架構如下:第二章回顧單因子關聯結構模型相關文獻;第三章介紹合 成型抵押擔保債券憑證之評價方法及應用 LHP 假設之單因子關聯結構模型,並 且介紹非大樣本性質之高斯關聯結構模型;第四章評價不同年度的 DJ iTraxx Europe 分券,以四個不同單因子模型進行模型比較分析,模型包含 Gaussian、 Gaussian(125) 、NIG(1)、NIG(2)。第五章為結論與建議。. 8.
(15) 第二章. 文獻回顧. 在評價合成型抵押擔保債券憑證時,需考慮多個標的資產間之違約相關性。 最早描述違約相關性的模型,出現在 Li (2000)的關聯結構模型(Copula model), 此後更進一步延伸為單因子關聯結構模型(one factor copula model),本文也將以 此模型進行模擬實證並分析結果。本章節將針對單因子關聯結構模型,一一詳述 相關文獻的模型觀念及應用方法。. 治 政 第一節 關聯結構模型(Copula 大 Model) 立 ‧ 國. 學. ,或稱作各個標的資產 Li (2000)首先介紹一個隨機變數「time-until-default」 自合約開始至違約事件發生時的總存活時間,並定義各個標的資產之間具有違約. ‧. 相關性(default correlation)。Li 使用關聯結構函數(Copula function)連結數個邊際. sit. y. Nat. 密度函數而成聯合密度函數,即為資產組合違約時間的聯合密度函數。Sklar. n. al. er. io. (1959)提出定理,獲得資產組合違約時間的聯合密度函數如下:. i n U. v. F(t1 , t 2 , … , t n ) = C(F1 (t1 ), F2 (t 2 ), … , Fn (t n )),. Ch. engchi. Fi (t i ) 為第 i 個資產的邊際違約機率,Li 更進一步透過高斯關聯結構函數 (Gaussian Copula)改寫為: F(t1 , t 2 , … , t n ) = Φn (Φ−1 (F1 (t1 )), Φ−1 (F2 (t 2 )), … , Φ−1 (Fn (t n )); Σ), Φ𝑛 (∙; Σ) 為 n 維度的多變量常態分配,Σ 為其相關係數矩陣。Φ−1 (F1 (t1 )) , Φ−1 (F2 (t 2 )) , …, Φ−1 (Fn (t n )) 為此模型的資產報酬,經由此設定,就能以各個 標的資產報酬的相關性取代各個標的資產的違約時間之相關性。因此能以蒙地卡 羅模擬方法模擬各資產的違約時間。然而,蒙地卡羅方法必須透過大量模擬來取 得各資產的違約時間,在大樣本的標的資產組合下會提高運算過程中的困難度。 9.
(16) 第二節 單因子關聯結構模型(One Factor Copula Model). 即使關聯結構模型能以各標的資產報酬的相關性取代違約時間之相關性,但 如前一小節所提及,關聯結構模型需要以蒙地卡羅方法模擬各資產的違約時間, 在大樣本的資產組合情況下會提高運算過程中的困難度以及計算過程較為費時。 為了解決此一問題,單因子關聯結構模型因此而興起,其想法為多個標的資產給 定相同的因子(市場因子)情形下,各個標的資產報酬會相互獨立。此方法不僅能. 政 治 大. 夠簡單且迅速地計算不同時間下的違約損失分配,而且可以改善蒙地卡羅模擬方. 立. 法計算費時的缺點。. ‧ 國. 學. 單因子關聯結構模型概念最早由 O’Kane and Schlö gl (2001)提出,主要是介 紹多個標的資產如何建立信用風險模型(credit model),能夠在資產違約的同時,. ‧. 即時洞察發現,並在無套利(arbitrage-free)之下保持評價的一致性,而本文主要介. sit. y. Nat. 紹單因子高斯關聯結構模型(one factor Gaussian copula model),此一模型因為其. al. er. io. 簡單好計算的特性目前被廣泛使用。O’Kane and Schlö gl (2001)首次提及單因子. v. n. 結構模型,假設標的資產組合具有共同的市場因子X(t),則各標的資產從契約開. Ch. 始至時間 t 的資產報酬Ai (t)為:. engchi. i n U. Ai (t) = √ρi X(t) + √1 − ρi εi (t), i = 1, … , N, 其中X(t)為共同市場因子,εi (t)為資產本身因子,X(t)與εi (t)為獨立且相同的隨 機變數,並假設X(t)與εi (t)皆服從標準常態分配,此即單因子高斯關聯結構模型。 由於Ai (t)為X(t)與εi (t)的線性組合,由常態分配性質可知,Ai (t)仍然服從標準常 態分配。如此假設的優點是給定共同市場因子X(t)條件下,各資產報酬Ai (t)相互 獨立,增加大樣本一致性資產組合(Large Homogeneous Portfolio)假設下,各個資 產視為同質性資產(homogeneous assets),在增加此一假設後,能夠快速且容易計 10.
(17) 算不同違約時間下的資產損失函數,且避免蒙地卡羅方法的耗時性。有了以上的 優點,單因子結構模型遂成為目前市場上廣泛使用的主要方法,之後更有許多文 獻延伸出不同的單因子關聯結構模型。. Hull and White (2004)提出了兩種評價合成型抵押擔保債券與直至第n個資 產違約的信用違約交換(Credit Default Swap)的方法,此兩種方法都建立單子關聯 結構模型,並且取代 Laurent, J-P and J.Gregory (2003)所提出的快速傅立葉轉換法 (fast Fourier transforms)。第一種方法利用遞迴關係去計算在時間t之前,K個違約. 治 政 大,去計算在時間t之前的總 方法允許各個標的資產擁有不同的名目本金與回覆率 立. 資產的損失分配。第二種方法利用機率杓斗法(probability bucketing method),此. 損失分配。本文末評價 iTraxx 及 CDX 指數的市場分券資料,顯示單因子常態關. ‧ 國. 學. 聯結構及雙 t 分配關聯結構(Double t distribution)兩者之中,具有厚尾(heavy tails). ‧. 性質的雙 t 分配關聯結構會得到較佳的配適結果。相反地,單因子常態關聯結構. y. Nat. 模型因為缺乏厚尾性質,在計算各分券的隱含相關(implied correlations)及基底隱. er. io. sit. 含相關(base implied correlations)時,會有相關性微笑曲線與隱含相關偏斜(implied correlation skew)的現象。雖然雙 t 分配關聯結構擁有改善此現象的優點,但是 t. al. n. v i n 分配不如常態分配具有封閉性,必須透過數值積分的方式計算損失分配,因此計 Ch engchi U 算過程相當耗時。. Andersen and Sidenius (2005)本文提出了新的單因子高斯關聯結構,具有回 復率隨機化(randomized recovery)以及因子負荷項隨機化(randomized factor loadings),前者假設共同市場因子及資產本身因子兩因子和回復率相關,後者假設因 子負荷項只和共同市場因子相關,後者模型擁有因子負荷項隨機化的性質,使得 計算總資產損失分配時,不同於單因子關聯結構模型,具有厚尾性質,在實證分 析結果時,有較佳的評價結果,但會有和高斯關聯結構類似的相關偏斜現象。. 11.
(18) Dezhong et al. (2006) 則提供了二種單因子關聯結構延伸模型,希望藉由具 有厚尾性質的函數來改善舊有的單因子關聯結構模型:第一種是 t 與高斯分配混 合的關聯結構(a double mixture distribution of t and Gaussian distributions copula); 第二種是自由度為非整數的雙 t 分配關聯結構(a double t distribution with fractional degrees of freedom copula),與 Hull and White (2004)提出的自由度為整數的雙 t 分配關聯結構比較,上述兩種關聯結構在實證分析上得到較好的評價結果。但是, t 與高斯分配混合的關聯結構和自由度為非整數的雙 t 分配關聯結構仍然有雙 t 分配關聯結構的缺點,t 分配沒有穩定的摺積性,必須使用數值積分的方式求解. 政 治 大. 違約門檻值,會增加計算所需的時間。. 立. Kalemanova et al. (2007) 在大樣本一致性資產組合假設下,提出以 NIG 分配. ‧ 國. 學. 取代 t 分配作為擔保債券憑證分券的評價。NIG 分配擁有許多良好的性質。首先,. ‧. 相較單因子高斯關聯結構,NIG 分配具有尾點相依性(tail dependence)的性質;其. y. Nat. 次,NIG 分配具有穩定的摺積性;再者,單因子 NIG 關聯結構模型能夠簡單且快. er. io. sit. 速地計算各資產的違約門檻值;並且,因為其擁有多個參數可以在建立投資組合 的相關性結構上有更多的彈性。文末進行實證分析,和雙 t 分配關聯結構類似,. al. n. v i n 兩者皆在前兩個分券 0~3%及C 3~6%得到好的配適結果,但卻高估了 6~9%以上的 hengchi U 分券。. 邱嬿燁(2007)使用 CSN 分配(Closed Skew Normal)來做抵押擔保債權憑證分券 的評價,其動機在於 CSN 分配具有常態分配的性質且具有封閉性,同時具有較 多的參數可控制分配的峰態與偏態。但與單因子常態關聯結構模型相同,單因子 CSN 關聯結構模型仍無法估計的很準確,只有在最高等級分券的評價上有明顯 的改進。 林聖航(2012)使用如同 Dezhong(2006)的混合分配方法,給定期望值為零且. 12.
(19) 變異數為一之 NIG 及 CSN 分配,將兩者混合成新分配 MIX,以此關聯結構模型 評價抵押擔保債券憑證,在單因子混合關聯結構模型中,資產因子和市場因子的 厚尾度會由 NIG 及 CSN 分配的參數及兩者的權重 p 決定。作者建議兩種 MIX 模型參數估計方式使其絕對誤差極小化:先固定 NIG 分配參數,再估計比例 p 及 相關係數 ρ ;另一種方法,固定比例 p ,估計 NIG 分配參數,以兩種方法交互 運作計算最適參數估計值使絕對誤差極小化。整體而言,MIX 的評價結果介在 NIG 與 CSN 之間,比 CSN 關聯結構模型評價結果準確,但比 NIG 關聯結構模 型不準確。. 政 治 大. 第三節 Normal立 Inverse Gaussian Distribution (NIG). ‧ 國. 學. Ole Barndorff-Nielsen (1977)最早提出 NIG 分配,NIG 分配為廣義雙曲分配. ‧. (generalized hyperbolic distribution)的一個特殊例子,由於其擁有的性質,目前漸. y. Nat. 漸應用在金融及經濟方面。NIG 分配之所以能夠廣泛應用在金融及經濟方面,. er. io. sit. 最主要的性質是其為擁有四個參數的分配,能夠在同時間產生厚尾性質及偏斜性 質,以及能夠穩定摺積的特性。而且,NIG 分配之機率密度函數、分配函數、反. n. al. Ch. 函數也可以快速地計算得到。. engchi. i n U. v. 第三章 合成型 CDO 之評價方法與單因子關聯 結構模型. 本文詳細介紹合成型抵押擔保債券憑證(Synthetic CDOs)之評價方法,以及. 13.
(20) 給定 LHP 假設條件下,單因子高斯關聯結構模型評價合成型 CDOs 分券的推導 過程,另外,提出放寬 LHP 假設,假設總資產個數是有限的情形下,高斯關聯 結構模型的計算方法。. 第一節 合成型抵押擔保債券憑證之評價方法 考慮一個合成型 CDO 分券包含信用違約交換的資產組合,合成型 CDO 分 券的持有者或保護賣方(protection seller)每季會收到一筆由合成型 CDO 分券的發. 治 政 大 總違約損失超過分券的面額(notionals),保護賣方必須付給保護買方一筆補償分 立 行者或保護買方(protection buyer)所支付的信用價差費用。如果標的資產組合的. 券損失的費用。. ‧ 國. 學. 基本上,標的資產的合成型 CDO 的K1 ~K 2 分券(0 ≤ K1 < K 2 ≤ 1)的評價方. io. y. sit. t1 < t 2 < ⋯ < t n = T:為信用價差的付費日,T為合成型 CDO 的到期日,而. er. 1.. Nat. 符號:. ‧. 法與信用違約交換(credit default swap)大致相同。我們先定義評價過程會使用的. t 0 (t 0 < t1 )為評價日。. n. al. Ch. i n U. v. 2.. s: 每期的信用價差。. 3.. L(K1 ,K2 ) (t): 合成型 CDO 的K1 ~K 2 分券在時間 t 的損失百分比。. 4.. r(t): 為無風險短期利率,並且假設此利率與分券損失獨立。. 5.. EQ [L(K1,K2) (t)]: 合成型 CDO 的K1 ~K 2 分券的期望分券損失,其中Q為風險. engchi. 中立測度(the risk-neutral measure Q),假定整個評價過程都是此測度,因此 EQ [L(K1,K2) (t)]也可以表示為E[L(K1 ,K2 ) (t)]。 6.. B(t 0 , t i ) = EQ [e. t 0. − ∫t i r(u)du. ]: 為折現因子,在t i 時間的 1 元經過每期無風險短. 期利率r(t)折現到評價日t 0 的現值。. 14.
(21) 為了評價合成型 CDO 各分券之公平信用價差價格,必須假設在風險中立測 度下額外收入(Premium leg)的預期現值與違約給付金額(Protection leg)的預 期現值為相等,來計算此分券的信用價差。 分券的額外收入為分券的持有者在未來可預期收到來自分券的發行者的所 有信用價差的現值: n. re i. e = ∑ t i ∙ s ∙ EQ [(1 − L(K1,K2) (t i ))e. t 0. − ∫t i r(u)du. ]. i 1 n. = ∑ t i ∙ s ∙ (1 − E[L(K1 ,K2) (t i )]) ∙ B(t 0 , t i ), 其中, t i = t i − t i−1 。. (3.1). 政 治 大. i 1. 立. 簡單假設在時間t i 的信用價差費用會與在此時間的剩餘本金百分比成比例。. ‧ 國. 學. 另外,分券的額外收入還有另外可能一種型式,保護賣方除了在每一期收到來自. ‧. 保護買方的信用價差,並且在契約訂立期初時會收到一筆等同於K1 ~K 2 分券市場. y. Nat. 報價(market quote)的預付費用。. i 1. er. e = ∑ t i ∙ s ∙ (1 − E[L(K1 ,K2 ) (t i )]) ∙ B(t 0 , t i ) +. io. re i. sit. n. al. q,. (3.2). n. v i n 其中,mq為期初由分券的發行者給予持有者的一筆預付費用。 Ch engchi U. 違約給付金額為當未來發生違約事件時,保護賣方必須給予保護買方的補償金額 現值: rote tion e = EQ [∫ e. t 0. − ∫t i r(u)du. L(K1 ,K2) (t i )]. 0. n. = ∑ EQ [ e. t 0. − ∫t i r(u)du. (L(K1,K2) (t i ) − L(K1,K2) (t i−1 )). i 1 n. = ∑(E[ L(K1,K2) (t i )] − E[L(K1 ,K2 ) (t i−1 )])B(t 0 , t i ) , i 1. 15. (3.3).
(22) 違約給付金額應該在違約時間發生的同時給付,但為了簡化表示,假設在t i−1 ~t i 時間內的違約金額僅在時間t i 給付。. 接著假設在風險中立測度下,額外收入與違約給付金額相等以計算出合成型 CDO分券的公平信用價差。. s=. ∑ni 1(E[L(K1,K2 ) (t i )] − E[L(K1,K2) (t i−1 )]) ∙ B(t 0 , t i ) ∑ni 1 t i ∙ (1 − E[L(K1,K2 (t i )]) ∙ B(t 0 , t i ). ~K 分券之損失百分比可 政 治(t ),則K 大. 假設標的資產組合在時間t i 之損失為L. 立. 以表示為 r. (t i ), K 2 ) − K1 ) K 2 − K1 i. i. i. 1. 2. , 0 ≤ L(K1,K2) (t i ) ≤ 1 ,. (3. ). ‧. ‧ 國. ( in(L. r. 學. L(K1 ,K2 ) (t i ) =. (3. ). ,. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 假設已知一個連續型標的資產損失分配函數F(t, ),則合成型CDO之K1 ~K 2 分券 的期望損失百分比可以寫成: E[L(K1,K2) (t)] = = = = =. 1 1 ∙ ∫ ( in( , K 2 ) − K1 ) F(t, ) K 2 − K 1 K1. K2 1 1 ∙ [∫ ( − K1 ) F(t, ) + ∫ (K 2 − K1 ) F(t, )] K 2 − K1 K1 K2. 1 1 1 1 ∙ [∫ ( − K1 ) F(t, ) − ∫ ( − K1 ) F(t, ) + ∫ (K 2 − K1 ) F(t, )] K 2 − K1 K1 K2 K2. 1 1 1 ∙ [∫ ( − K1 ) F(t, ) − ∫ ( − K1 − K 2 + K1 ) F(t, )] K 2 − K1 K1 K2 1 1 1 ∙ [∫ ( − K1 ) F(t, ) − ∫ ( − K 2 ) F(t, )] , K 2 − K1 K2 K1. 16. (3. ).
(23) 以上的式子可以簡化成: 1 1 1 E[L(K1 ,K2 ) (t)] = (∫ ( − K1 ) F(t, ) − ∫ ( − K 2 ) F(t, )) , K 2 − K 1 K1 K2. (3. ). 因此,如何求得標的資產組合的損失函數是評價合成型CDO分券的一大關鍵。 在下一小節,我們介紹如何使用單因子關聯結構計算標的資產的損失函數以及分 券的期望損失。. 政 治 大. 立 假設之單因子高斯關聯結構模型 第二節 應用 LHP. ‧ 國. 學. 考慮標的資產個數夠多的情形下,則假設此信用資產組合為大樣本一致性資. ‧. 產組合,即假定資產組合中的各資產具有同質性(有相同的權重比例、違約機率、. y. sit. io. n. al. er. 價。. Nat. 復原率,和對共同因子的相關性),經由此假設,能夠去預測真實分券的市場報. Ch. engchi. i n U. v. 考慮一個標的資產個數為 的信用資產組合,則第 i 個資產從契約開始到第t時間 的資產報酬Ai (t)可以寫成: Ai (t) = √ρi X(t) + √1 − ρi εi (t),i = 1, … ,. (3.8). ,. 其中,X(t)為共同市場因子,εi (t)為資產本身因子,X(t)與εi (t)為獨立且相同隨 機變數。假定其服從標準常態分配 X(t). iid. N(0,1) , εi (t) → N(0,1) , X(t). 17. εi (t).
(24) 則給定共同因子X(t)的條件下,因為εi (t)之間相互獨立,所以資產報酬Ai (t)之間 也相互獨立。. 在此關聯結構模型中,由於常態分配的線性組合仍服從常態分配,則總資產 報酬Ai (t)服從標準常態分配。 Ai (t) = √ρi X(t) + √1 − ρi εi (t). N(0,1). 總資產報酬Ai (t)對應於第 i 個標的資產的違約時間t i ,則可以運用百分比轉. 政 治 大 (t ≤ t) = (A (t) ≤ C (t)) 立. 換(percentile-to-percentile transformation):. i. i. 學. ‧ 國. i. 定義資產在時間t之前違約的機率為. ‧. qi (t) = (t i ≤ t). y. ,復原率為當第 i 個資產違約時,可以拿回的補償金額比例。. io. 1−復原率. sit. 平均 d 價差. n. al. er. 約強度 =. Nat. 假設各個資產的違約時間為指數分配,此違約機率為qi (t) = 1 − e− 。其中,違. Ch. 則能夠求得違約門檻值Ci (t)為. engchi. i n U. v. Ci (t) = Φ−1 (qi (t)) Φ為標準常態分配的累積密度函數。. 由第(3.8)式知,第 i 個標的資產在時間 t 之前發生違約事件的條件為 εi (t) ≤. Ci (t) − √ρi X(t) √1 − ρi. 18.
(25) 則給定共同因子X(t)之下,第 i 個標的資產在時間 t 之前發生違約事件的機率為 i ((t|X). Ci (t) − √ρi X(t). = Φ(. √1 − ρi. ). 給定LHP的假設下,所有標的資產擁有相同的違約門檻值 C(t),以及相同的本金 與復原率,且資產之間的相關係數會是相同的(. = )。. C(t) − √ρX(t). (t|X) = Φ(. √1 − ρ. ). 政 治 大 發生 k 個標的資產違約之資產組合損失百分比L(t) = 立 ( )−√. (L(t) =. (). √1−. )). |X) = ( ) [Φ (. C(t) − √ρX(t) C(t) − √ρX(t) )] [1 − Φ ( )] √1 − ρ √1 − ρ. ‧. ‧ 國. ,Φ(. 學. 分配Bin(. 的違約機率為二項式. Nat. sit. y. −. n. al. er. io. 為了求得非條件下的資產組合損失百分比,必須要對共同因子X(t)積分 ( )−√. (). C √h1− engchi. (L(t) = ) = ∫− ( ) [Φ (. i v ( ))] n U √1−. )] [1 − Φ (. ( )−√. −. [0,1]. 則能夠計算資產組合損失百分比的累積機率,考慮其不會大於 [. Φ( ). ]. F (t, ) = ∑. (L(t) =. ). 0 [. ]. C(t) − √ρX(t) C(t) − √ρX(t) = ∑ ∫ ( ) [Φ ( )] [1 − Φ ( )] √1 − ρ √1 − ρ 0 −. −. Φ( ) , (3. ). Vasicek (2002)提出簡單且有效的方法,計算損失百分比的機率分配。考慮此信. 19.
(26) 用資產組合為大樣本一致性資產組合,資產個數夠多的情況下, 則(3.9)式分配 能夠近似常態分配。 (). ( )−√. 且將s = Φ (. √1−. ) 替換(3.9)式: ] 1 0 ∫0 (. [ F (t, ) = ∑. )(s) (1 − s). −. Φ(. ( )−√1−. 1(. √. ). ),. 接著考慮標的資產個數無限多的條件下,計算資產組合損失百分比的累積機率, [0,1]:. 考慮其不會大於 [. F (t, ) =. i. ]. 1. Φ( 政 治 大 √ρ. ∑ ∫ ( ) (s) (1 − s) 0 0. C(t) − √1 − ρΦ−1 (s). −. 立. ),. (3.10). [. ]. ∑ ( ) (s) (1 − s). i. −. 學. ‧ 國. 其中K ~ Bin( , s),則由於. io. ] − s + 0. ) s(1 − s). y. [. sit. Nat. ( <. ]). er. (K ≤ [. = i. ‧. 0. n. a=l {1 , s v i 0, <s n Ch engchi U. (3.10)式無限資產組合損失百分比的累積機率,考慮其不會大於 F (t, ) = ∫. [0,1]:. C(t) − √1 − ρΦ−1 (s). Φ(. ). √ρ. 0. C(t) − √1 − ρΦ−1 ( ) = 1 − Φ( ) √ρ = Φ(. √1 − ρΦ−1 ( ) − C(t) √ρ. ),. 為了計算K1 ~K 2 的期望分券損失,我們使用(3.7)式,並將它改寫成 20. (3.11).
(27) E[L(K1,K2) (t)] = = = =. 1 1 ∙ ∫ ( in( , K 2 ) − K1 ) F (t, ) K 2 − K 1 K1. K2 1 1 ∙ [∫ ( − K1 ) F (t, ) + ∫ (K 2 − K1 ) F (t, )] K 2 − K1 K1 K2. K2 1 ∙ [∫ ( − K1 ) F (t, ) + (K 2 − K1 ) ∙ (1 − F (t, K 2 ))] K 2 − K1 K1. K2 1 ∙ ∫ ( − K1 ) F (t, ) + (1 − F (t, K 2 )), K 2 − K 1 K1. (3.12). 為了計算此積分,必須求得無限資產組合損失百分比的機率密度函數. F (t, ) =. (t, ). =. √1 − ρ √ρ. 立. 代入(3.12)式. √1 − ρΦ−1 ( ) − C(t) ( ) √ρ. 政 治 (Φ ( ))大. ∙. (3.13). K2 1 √1 − ρ ∙ ∫ ( − K1 ) ∙ K 2 − K 1 K1 √ρ. (. √1 − ρΦ−1 ( ) − C(t) ) √ρ. ‧. ‧ 國. 學. E[L(K1,K2 ) (t)] =. ,. −1. (Φ−1 ( )). y. Nat. (3.1 ). n. er. io. al. sit. + (1 − F (t, K 2 )),. Ch. engchi. i n U. v. 以上為假設復原率為零之K1 ~K 2 期望分券損失推導過程及結果,若我們假設資 產的復原率並不為零的情形下,K1 ~K 2 的期望分券損失可以寫成一個關係式:. E[L(K1,K2 ) ] = E [L(. 1. 1. (t)] , ,1 2 ). (3.15). L(K1 ,K2 ) 即為假設復原率不為零的分券損失百分比,而以上的關係式在接下來的關 聯結構中一樣適用。. 21.
(28) 第三節 非大樣本假設下的單因子高斯關聯結構模型 前一小節,給定信用資產組合為大樣本一致性資產組合的條件下,計算單因 子高斯關聯結構模型下的K1 ~K 2 期望分券損失。但目前分券市場上,標的資產的 個數並不是無限多,例如:DJ iTraxx Europe 包含125種相同權重比例之信用交 換契約標的資產組合,因此本節將探討非大樣本假設下,標的資產個數有限,如 何計算K1 ~K 2 期望分券損失。. 治 政 大 性資產組合(homogeneous portfolio ; HP),即屏除原假設中的大樣本性質,但資產 立 考慮一個標的資產個數有限的信用資產組合,則假設此信用資產組合為一致. 組合中的各資產仍具有同質性(有相同的權重比例、違約機率、復原率,和對共. ‧ 國. 學. 同因子的相關性),經由此假設,能夠去預測真實分券的市場報價。. ‧. (3.16). n. er. io. al. ,. sit. Nat. Ai (t) = √ρi X(t) + √1 − ρi εi (t) ,i = 1, … ,. y. 同前一小節所述,第 i 個資產從契約開始到第t時間的資產報酬Ai (t)可以寫成:. i n U. v. 其中,X(t)為共同市場因子,εi (t)為資產本身因子,X(t)與εi (t)為獨立且相同隨. Ch. engchi. 機變數。假定其服從標準常態分配 X(t). iid. N(0,1) , εi (t) → N(0,1) , X(t). εi (t). 則給定共同因子X(t)的條件下,因為εi (t)之間相互獨立,所以資產報酬Ai (t)之間 也相互獨立。. 22.
(29) 在此關聯結構模型中,由於常態分配的線性組合仍服從常態分配,則總資產報酬 Ai (t)服從標準常態分配。 Ai (t) = √ρi X(t) + √1 − ρi εi (t). N(0,1). 總資產報酬Ai (t)對應於第 i 個標的資產的違約時間t i ,則可以運用百分比轉 換: (t i ≤ t) = (Ai (t) ≤ Ci (t)). 政 治 大 q (t) = (t ≤ t). 定義標的資產在時間t之前違約的機率為. 立. i. i. ‧ 國. 學. 假設各個資產的違約時間為指數分配,此違約機率為qi (t) = 1 − e− 。其中,違 平均 d 價差 1−復原率. ,復原率為當第 i 個資產違約時,可以拿回的補償金額比例。. ‧. 約強度 =. sit. y. Nat. n. al. Ci (t) = Φ−1 (qi (t)). Ch. engchi. Φ為標準常態分配的累積密度函數。. er. io. 則能夠求得違約門檻值Ci (t)為. i n U. v. 由第(3.16)式知,第 i 個標的資產在時間 t 之前發生違約事件的條件為 εi (t) ≤. Ci (t) − √ρi X(t) √1 − ρi. 則給定共同因子X(t)之下,第 i 個標的資產在時間 t 之前發生違約事件的機率為 i (t|X). Ci (t) − √ρi X(t). = Φ(. √1 − ρi 23. ).
(30) 給定同質性的假設下,即所有標的資產擁有相同的違約門檻值 C(t),以及相 同的本金與復原率,且資產之間的相關係數會是相同的(ρi = ρ)。 C(t) − √ρX(t). (t|X) = Φ(. √1 − ρ. ). 發生k個標的資產違約之資產組合損失百分比L(t) = 配Bin(. ,Φ(. (). ( )−√ √1−. (L(t) =. 的違約機率為二項式分. )). |X) = ( ) [Φ (. 立. C(t) − √ρX(t) C(t) − √ρX(t) )] [1 − Φ ( )] √1 − ρ √1 − ρ. 政 治 大. −. ‧ 國. 學. 為了求得非條件下的資產組合損失百分比,必須要對共同因子X(t)積分 ( )−√. (). √1−. )] [1 − Φ (. ( )−√. (). √1−. )]. −. Nat. y. ‧. (L(t) = ) = ∫− ( ) [Φ (. [0,1]:. er. io. sit. 則能夠計算資產組合損失百分比的累積機率,考慮其不會大於. al. n [. ]. F (t, ) = ∑. (L(t) =. Φ( ). ). Ch. engchi. i n U. v. 0 [. ]. = ∑ ∫ ( ) [Φ (. C(t) − √ρX(t). C(t) − √ρX(t). √1 − ρ. √1 − ρ. 0 − (). ( )−√. 且將s = Φ (. √1− [. ]. 1. )] [1 − Φ (. )]. Φ( ) (3.1 ). ) 替換(3.17)式:. F (t, ) = ∑ ∫ ( ) (s) (1 − s) 0 0. −. −. C(t) − √1 − ρΦ−1 (s) Φ( ), √ρ. (3.1 ). 此時,標的資產個數有限,即標的資產個數為m,不能使用大樣本性質,故無法 將二項式分配近似常態分配,求得F (t, )的封閉型式(closed form)。 24.
(31) 由(3.12)式知,K1 ~K 2 的期望分券損失為 1 1 E[L(K1 ,K2 ) (t)] = ∙ ∫ ( in( , K 2 ) − K1 ) F (t, ) K 2 − K 1 K1. K2 1 1 = ∙ [∫ ( − K1 ) F (t, ) + ∫ (K 2 − K1 ) F (t, )] K 2 − K1 K1 K2 K2 1 = ∙ ∫ ( − K1 ) F (t, ) + (1 − F (t, K 2 )), K 2 − K 1 K1. 由於無法求得F (t, )的封閉型式,因此也無法求得F (t, )的微分型式. (3.1 ). (t, ),. 我們考慮黎曼積分的方式計算K1 ~K 2 的期望分券損失。. 立. 政 治 大 K2 −K1. ‧ 國. 個K1 , K1 +. n. ,則分割的節點有n + 1. 學. 將積分範圍K1 ~K 2 切割成n等分,每一等分長度 為. , K1 + 2 , K1 + 3 , … , K 2 − , K 2,則K1 ~K 2 的期望分券損失等式右. ‧. 邊的第一項,能夠使用梯形法逼近積分值:. sit. y. Nat. K2. er. al. n. K1. io. ∫ ( − K1 ) F (t, ). = {[(K1 − K1 ) + (K1 +. {[(K1 + 2 − K1 ) + (K1 + + {[(K 2 − K1 ) + (K 2 −. i n U. v. 1 − K1 )] ∙ [F (t, K1 + ) − F (t, K1 )] ∙ } + 2. Ch. engchi. 1 − K1 )] ∙ [F (t, K1 + 2 ) − F (t, K1 + )] ∙ } + ⋯ 2 1. − K1 )] ∙ [F (t, K 2 ) − F (t, K 2 − )] ∙ } 2. 1. = ∑ni 1(2i − 1) ∙ [ F (t, K1 + i ) − F (t, K1 + (i − 1) )] 2. 接著將上式代回(3.19)式,即可求得K1 ~K 2 期望分券損失. 25.
(32) n. 1 1 E[L(K1 ,K2) (t)] = { ∑(2i − 1) ∙ [ F (t, K1 + i ) − F (t, K1 + (i − 1) )]} K 2 − K1 2 i 1. + (1 − F (t, K 2 )). 以上為假設復原率為零之K1 ~K 2 期望分券損失推導過程及結果。若我們假設資 產的復原率並不為零的情形下,K1 ~K 2 的期望分券損失可以寫成一個關係式:. K K (t)] (1−1 ,1−2 ). E[L(K1,K2) ] = E[L. 學 ‧. ‧ 國. L(K1 ,K2 ). 政 治 大 即為假設復原率不為零的分券損失百分比。 立. y. Nat. n. al. er. io. sit. 第四章 實證分析:評價 DJ iTraxx. Ch. engchi. i n U. v. 本章節選擇以五年為到期日DJ iTraxx Europe信用違約交換指數為標的之合 成型抵押擔保債券進行實證分析,藉由LHP假設下的單因子關聯結構型:Gaussian、 NIG,以及非大樣本性質下的單因子高斯關聯結構模型進行不同時期2006、2009、 2010、2011、2012、2013年的DJ iTraxx Europe之合成型抵押擔保債券的評價。 並且比較三種模型的數值分析。. 如第一章描述,DJ iTraxx Europe包含125種相同權重比例之信用交換契約的 標的資產組合,其CDO分券被分為五個分券,分別是權益分券、次順位分券、 中間層級分券、優先層級分券和最高層級分券。iTraxx指數的標準化分券架構為 26.
(33) 0-3%、3-6%、6-9%、9-12%以及12-22%。投資人在各分券中可得到的投資報酬 分為兩大類,第一類的投資人在訂立契約的期初,會收到一筆等同市場報價的預 付費用,並可在每一期拿到信用價差,而第二類的投資人只會定期地在每一期拿 到信用價差。本文挑選不同時期的DJ iTraxx Europe series 來分析,分別為 series 5 、 series 9 及 series 15 , 且 其 分 券 的 市 場 報 價 日 為 2006.4.12(series 5) 、 2009.3.31(series 9)、2010.3.31(series 9)、2011.9.30(series 15)、2012.1.31(series 15) 及2013.3.28(series 15),其中各時期市場報價如表 4.1 所示。表 4.1 所呈現的數 值意義解釋如下,若分券報價包含兩個數值,屬於第一類的方式,例:. 治 政 大 分成四期支付,也就是每三個月支付一次信用價差;若分券報價只有一個數值, 立. 23.53%+500bp,23.53%為期初之預付費用,500bp則為每年給予的信用價差金額,. 四期支付,同樣每三個月支付一次信用價差。. 學. ‧ 國. 屬於第二類的方式,例: 62.75bp,62.75bp 則為每年給予的信用價差金額,分成. ‧. y. Nat. 應用單因子關聯結構模型評價合成型CDO分券需要的重要參數:平均CDS. er. io. sit. 價差是由訂立契約開始到發佈市場報價當日的每日的CDS指數平均計算得到,六 個時期的平均CDS價差分別為32bp、127.67bp、115.42bp、124.913bp、144.35bp. al. n. v i n 及122.983bp;資產復原率(R)皆假定為固定的40%;無風險利率(r)選發布分券市 Ch engchi U 場報價當天的Euro LIBOR隔夜拆款利率為基準利率。有了以上參數就能使用固. 定違約強度模型導出不同時點之邊際違約分配。此外,單因子關聯結構模型的參 數估計方面,除了各資產間的相關係數ρ之外,還必須估計關聯結構所具有的參 數像NIG分配的α及β。各個關聯結構之參數估計藉由Kalemanove et al. (2007).所 介紹之方法,也就是將絕對誤差(absolute errors)極小化來估計參數,其中絕對誤 差是指由各個模型所產生的分券評價結果與實際市場報價之差異取絕對值再將 其全部加總之和。. 27.
(34) 表 4. 1 各時期市場報價. DJ iTraxx Europe series 分券. Series 5. Series 9. Series 15. 2006年. 2009年. 2010年. 2011年. 2012年. 2013年. 4月12日. 3月31日. 3月31日. 9月30日. 1月31日. 3月28日. 0-3%. 23.53%+500bp. 66.83%+500bp. 27.03%+500bp. 61.65%+500bp. 56.71% +500bp. 34.81% +500bp. 3-6%. 62.75bp. 31.23%+500bp. -4.18bp+300bp. 27.60%+500bp. 18.98% +500bp. 3% +500bp. 6-9%. 18bp. 11.53%+500bp. 11.44% +300bp. 0.75% +300bp. 9-12%. 9.25bp. 418.8bp. 345.25bp +100bp. 174bp +100bp. 12-22%. 3.75bp. 155bp. 160bp +100bp. 80.5bp +100bp. 立. -3.99bp+300bp 治 19.17%+300bp 政 大 94.01bp+100bp 491.5bp+100bp. ‧. ‧ 國. 243.17bp+100bp. 學. 37.13bp+100bp. sit. y. Nat. 第一節 比較各模型在不同時期 DJ iTraxx 之分券評價. n. al. er. io. 以下將進行不同時期之DJ iTraxx的分券評價,按照其發佈市場報價時間順. i n U. v. 序以逐一表列的方式進行分析評價並解釋各模型配適結果,其中各時期DJ. Ch. engchi. iTraxx之分券市場報價及不同模型所產生的分券評價結果列在表4.2、表4.3、表 4.4、表4.5、表4.6及表4.7。各模型參數估計方面,非大樣本性質之Gaussian模型、 Gaussian模型須估計相關係數ρ;NIG(1)模型限制參數β為零,由最小絕對誤差來 估計參數α及ρ;NIG(2)模型相較於NIG(1)模型,以同樣方法多估計參數β。 觀察表4.2結果,Gaussian模型、Gaussian (125)模型在0%-3%分券得到完全配 適結果,但在其他分券表現上,過度高估3%-6%及6%-9%分券與低估9%-12%及 12%-22%分券。NIG模型相較於Gaussian模型,在3%-6%分券得到較佳的配適結 果,但皆高估其他分券,並觀察發現NIG(1)與NIG(2)整體配適模型效果相近,顯 示NIG模型之第二個參數β並沒有帶來改善的配適模型結果。 28.
(35) 觀察表4.3結果,Gaussian模型與NIG(1)模型的配適模型結果類似,對於 0%-3%分券評價較為準確,而在其他分券上皆為評價低估的情形。Gaussian (125) 模型在3%-6%以及6%-9%相較Gaussian模型接近市場報價,整體而言,較Gaussian 模型準確,絕對誤差和少了201.4985bp。NIG(2)模型相較於前面三者,3%-6%分 券評價結果與市場報價完全一致,同時在6%-9%及9%-12%分券評價結果也提升 了不少,整體的絕對誤差和為Gaussian模型與NIG(1)模型的三分之一倍,較 Gaussian (125)模型少一半。. 治 政 大 (125)模型在6%-9%、 準確外,其餘分券與市場報價是有相當大的差異,且Gaussian 立 觀察表4.4結果,Gaussian模型與Gaussian (125)模型僅在0%-3%分券評價較為. 9%-12%以及12%-22%皆比Gaussian模型高估市場報價。NIG(1)與NIG(2)則能改善. ‧ 國. 學. Gaussian的缺點,能夠得到負值的分券評價結果並在0%~3%及3%~6%之分券評價. ‧. 較為準確,整體的絕對誤差和為Gaussian的四分之一倍。此外,從表5.6還觀察到. y. Nat. 各模型資產間的違約相關性程度相當高(大於60%),由時間點上判斷很有可能受. er. io. sit. 到歐債危機影響。. al. n. v i n 觀察表4.5結果,Gaussian模型與NIG(1)模型的配適模型結果類似,對於 Ch engchi U. 0%-3%及12%-22%分券評價較為準確,在3%-6%及6%-9%分券評價結果皆為低估。 而Gaussian (125)模型在0%-3%、3%-6%及6%-9%分券評價結果比前兩者準確,但 Gaussian (125)模型在12%-22%分券低估市場報價,整體而言,絕對誤差和比前兩 者少約200bp。NIG(2)模型相較於前面三者,3%-6%分券評價結果相當接近市場 報價,同時在6%-9%分券評價結果也提升了不少,在整體的絕對誤差和的表現方 面,比Gaussian模型與NIG(1)模型降低了約400bp(等於NIG(1)模型的四分之一倍), 比Gaussian (125)模型降低了約200bp。同時,此四個模型擁有共同的問題,它們 皆過度地高估9%-12%分券。. 29.
(36) 觀察表4.6結果,Gaussian模型與Gaussian (125)模型的配適模型結果類似,對 於0%-3%分券評價較為準確,在其他分券評價結果皆為高估。而Gaussian (125) 模型在3%-6%及6%-9%分券評價結果比前者不準確,絕對誤差和比Gaussian模型 多約200bp。NIG(1)、NIG(2)模型相較於前面兩者,3%-6%、6%-9%分券評價結 果相當接近市場報價,同時在9%-12%分券評價結果也提升了不少,在整體的絕 對誤差和的表現方面,比Gaussian模型與Gaussian (125)模型降低了約1500bp(等 於約二分之一倍)。同時,此四個模型擁有共同的問題,它們皆過度地高估9%-12%、 12%-22%分券。. 治 政 大 (125) 於0%-3%分券評價較為準確,在其他分券評價結果皆為高估。而Gaussian 立 觀察表4.7結果,Gaussian模型與Gaussian (125)模型的配適模型結果類似,對. 模型在3%-6%分券評價結果比Gaussian模型不準確,絕對誤差和比Gaussian模型. ‧ 國. 學. 多約100bp。NIG(1)、NIG(2)模型相較於前面兩者,3%-6%、6-9%分券評價結果. ‧. 相當接近市場報價,同時在9%-12%分券、12%-22%分券評價結果也提升了不少,. y. Nat. 在整體的絕對誤差和的表現方面,比Gaussian模型與Gaussian (125)模型降低了約. er. io. sit. 二分之一倍。而NIG(2)於3%-6%、6-9%分券評價結果上比NIG(1)更為準確,整體 絕對誤差和少了約100bp。同時,此四個模型擁有共同的問題,它們皆過度地高. n. al. 估9%-12%、12%-22%分券。. Ch. engchi. i n U. v. 表 4. 2 市場報價及不同模型配適結果(2006 年 4 月 12 日). 分券. 市場報價. 0-3%. 23.53% (500bp). 23.53%. 3-6%. 62.75bp. 6-9%. NIG(1). NIG(2). 23.53%. 23.53%. 23.53%. 140.81bp. 135.22bp. 62.53bp. 62.73bp. 18bp. 24.35bp. 28.02bp. 27.36bp. 27.42bp. 9-12%. 9.25bp. 4.74bp. 6.81bp. 17.02bp. 17.05bp. 12-22% 絕對誤差. 3.75bp. 0.38bp. 0.72bp. 9.18bp. 9.19bp. 92.30894bp. 87.95bp. 22.68bp. 22.68bp. 0.12471. 0.1578. 0.1571. 0.1575. α. 0.5040. 0.4957. β. 0. 0.0212. ρ. Gaussian (m = 125) Gaussian. 30.
(37) 表 4. 3 市場報價及不同模型配適結果(2009 年 3 月 31 日). 分券. 市場報價. Gaussian (m = 125). Gaussian. NIG(1). NIG(2). 0-3%. 66.83% (500bp). 66.83%. 66.89%. 66.87%. 66.82%. 3-6%. 31.23% (500bp). 29.02%. 27.55%. 27.46%. 31.23%. 6-9%. 11.53% (500bp). 7.31%. 6.71%. 6.62%. 9.13%. 9-12%. 418.8bp. 378.82bp. 380.49bp. 379.41bp. 390.90bp. 12-22% 絕對誤差. 155bp. 130.31bp. 139.12bp. 139.44bp. 116.91bp. 708.5645bp. 910.063bp. 926.84bp. 307.23bp. 0.23. 0.2589. 0.2601. 0.2347. α. 10.0174. 2.9963. β. 0. 1.4850. ρ. 政 治 大 Gaussian (m = 125) Gaussian. 表 4. 4 市場報價及不同模型配適結果(2010 年 3 月 31 日). 立. 分券. 市場報價. 0-3%. 27.03% (500bp). 27.07%. 3-6%. -4.18bp (300bp). 6-9%. 26.98%. 27.04%. 27.04%. 1643.09bp. 1531.84bp. -4.07bp. -3.63bp. -3.99bp (300bp). 906.48bp. 782.61bp. -347.92bp. -358.45bp. 9-12%. 94.01bp (100bp). 1302.96bp. 1215.93bp. 465.36bp. 447.43bp. 12-22% 絕對誤差. 37.13bp (100bp). 727.29bp. 633.83bp. 347.88bp. 324.05bp. 4461.32bp. 4045.99bp. 1026.52bp. 995.99bp. 0.6472. 0.6451. 0.7878. 0.7920. v ni. 0.5017. 1.0360. 0. -0.5310. y. sit. er. n. al. ‧. io. α. Nat. ρ. ‧ 國. NIG(2). 學. NIG(1). β. Ch. engchi U. 表 4. 5 市場報價及不同模型配適結果(2011 年 9 月 30 日). 分券. 市場報價. Gaussian (m = 125). Gaussian. NIG(1). NIG(2). 0-3%. 61.65% (500bp). 61.65%. 61.67%. 61.67%. 61.63%. 3-6%. 27.6% (500bp). 25.48%. 24.15%. 24.11%. 27.66%. 6-9%. 19.17% (300bp). 14.62%. 14.11%. 14.07%. 16.48%. 9-12%. 491.5bp (100bp). 1270.04bp. 1274.9bp. 1272.49bp. 1352.34%. 12-22% 絕對誤差. 243.17bp (100bp). 225.94bp. 260.94bp. 261.24bp. 176.44bp. 1462.76bp. 1653.96bp. 1660.02bp. 1204.5bp. 0.2741. 0.3018. 0.3024. 0.2758. α. 15.2841. 2.9572. β. 0. 1.4886. ρ. 31.
(38) 表 4. 6 市場報價及不同模型配適結果(2012 年 1 月 31 日). 分券. 市場報價. Gaussian (m = 125). Gaussian. NIG(1). NIG(2). 0-3%. 56.71% (500bp). 56.70%. 56.71%. 56.71%. 56.72%. 3-6%. 18.98% (500bp). 25.91%. 24.77%. 18.55%. 18.18%. 6-9%. 11.44% (300bp). 18.25%. 17.63%. 12.16%. 11.62%. 9-12%. 345.25bp (100bp). 1744.42bp. 1721.48bp. 1357.93bp. 1319.18bp. 12-22% 絕對誤差. 160bp (100bp). 670.76bp. 684.26bp. 617.22bp. 609.42bp. 3284.65bp. 3098.653bp. 1584.534bp. 1522.133bp. 0.3803. 0.4024. 0.4871. 0.4937. 1.3587. 1.0672. 0. 0.164. ρ α β. 政 治 大 表 4. 7 市場報價及不同模型配適結果(2013 年 3 月 28 日) 立. 分券. 市場報價. 0-3%. NIG(1). NIG(2). 34.81% (500bp). 34.80%. 34.81%. 34.81%. 34.81%. 3-6%. 3% (500bp). 12.13%. 11.28%. 2.50%. -1.21%. 6-9%. 0.75% (300bp). 10.85%. 10.36%. 3.54%. 1.00%. 9-12%. 174bp (100bp). 1389.89bp. 1367.11bp. 905.38bp. 741.08bp. 12-22% 絕對誤差. 80.5bp (100bp). 680.90bp. 675.22bp. 523.22bp. 460.87bp. 3740.453bp. 3576.96bp. 1502.928bp. 1393.382bp. 0.5694. 0.5824. 0.6893. 0.7218. 1.2381. 0.9478. 0. -0.0594. Ch. engchi U. er. sit. y. ‧. al. n. β. io. α. Nat. ρ. ‧ 國. Gaussian. 學. Gaussian (m = 125). v ni. 第二節 觀察各模型在不同時期 DJ iTraxx 之隱含相關性. 本文所使用的單因子關聯結構模型,如:Gaussian 模型、NIG(1)模型、NIG(2) 模型是給定在LHP假設下,也就是假定DJ iTraxx中各標的資產具有相同的違約機 率、復原率以及違約相關性,另外,在評價合成型CDO分券價格時,假定各分 券與市場的相關性皆為相同。即使是本文發展之非大樣本性質假設下的Gaussian 32.
(39) 模型,仍是假定各標的資產具有相同的違約機率、復原率以及違約相關性。然而, Hull and White (2004)實證上發現單因子常態關聯結構模型會造成中間層級分券 的隱含相關性較低,而低順位及優先順位層級的分券的隱含相關性高的情況,也 就是所謂的相關性微笑曲線現象,此現象違反了LHP假設中的各標的資產具有同 質性。以上所提到的隱含相關,其計算方法為在給定單因子關聯結構模型下,固 定其他模型參數,找到一個最適相關係數值能使得各分券(K1%~K2%)的估計價 格要與分券對應的市場報價相等,此相關係數值即為分券的隱含相關。接下來, 將呈現各模型在不同時期DJ iTraxx 之隱含相關。. 治 政 大 各模型在不同時期DJ iTraxx之各分券隱含相關結果在表1到表6呈現 ,而各表 立. 下面都有附各模型的隱含相關曲線。觀察圖1,可以發現Gaussian、Gaussian (125). ‧ 國. 學. 模型在各分券的隱含相關值會呈現較大幅度震盪,呈現中間分券相關性較低,低. ‧. 順位及優先順位層級的分券的隱含相關性高的微笑曲線現象,NIG(1)、NIG(2). y. Nat. 模型兩者隱含相關性幾乎一致,相對平緩。觀察圖2,四個模型各分券隱含相關. er. io. sit. 性相當接近,但皆在9%-12%分券呈現較高隱含相關性,NIG(2)模型最高, Gaussian (125)模型最低,而其餘分券相關性皆低的近似反微笑曲線現象;觀察圖. al. n. v i n 3,2010年各分券隱含相關曲線震盪幅度最大,上下相關值差距最高將近90%, Ch engchi U 其中最高相關值在3%~6%分券,最低相關值在9%~12%,整體相關值呈現先上升 後下降,再上升的情形。Gaussian (125)模型相對Gaussian模型各分券隱含相關性 偏低。由以上結果來看,明顯地,各分券的隱含相關並不相同,這表示Gaussian、 Gaussian (125) 、NIG(1)、及NIG(2)模型可能違反了LHP 假設中的同質性假設。 觀察圖4,Gaussian、NIG(1)、及NIG(2)模型不同模型間的隱含相關性大概一致, 且在9%-12%分券隱含相關性低估,而Gaussian (125)模型嚴重高估,隱含相關性 約60.25%。觀察圖5,整體而言,各分券隱含相關性曲線振福大,上下相關值差 距最高將近70%,其中最高相關值在6%~9%分券,最低相關值在9%~12%,. 33.
(40) Gaussian、NIG(1) 、NIG(2)模型整體相關值呈現先上升後下降,再上升的情形, 而Gaussian (125) 模型不同於以往呈現反相關性微笑曲線。由以上結果來看,明 顯地,各分券的隱含相關並不相同,這表示Gaussian、Gaussian (125) 、NIG(1)、 及NIG(2)模型可能違反了LHP 假設。觀察圖6,Gaussian (125)模型各分券隱含相 關性皆在60%左右,隱含相關性曲線平緩,Gaussian (125)模型於12~22%分券隱 含相關性偏低,Gaussian模型各分券隱含相關性曲線振福大,其中最高相關值在 6%~9%分券,最低相關值在9%~12%,上下相關值差距最高將近100%,NIG(1) 及 NIG(2)模型卻呈現出相關性微笑曲線特性。. 政 治 大. 表 1 不同模型在 2006 年 4 月 12 日之各分券隱含相關值. 立. 12.47%. 15.78%. 15.71%. 15.74%. 10.00%. 7.79%. 15.86%. 15.75%. 10.68%. 13.00%. 9.46%. 15.60%. 17.34%. 8.91%. 22.93%. 8.39%. 21.62%. io. n. al. 8.95%. y. Nat. 12-22%. 9.49%. sit. 9-12%. NIG(2). ‧. 6-9%. NIG(1). 8.44%. er. 3-6%. Gaussian. 學. 0-3%. Gaussian (m = 125). ‧ 國. 分券. Ch. engchi. i n U. v. 圖 1 不同模型在 2006 年 4 月 12 日之各分券隱含相關曲線 34.
(41) 表 2 不同模型在 2009 年 3 月 31 日之各分券隱含相關值. 分券. Gaussian (m= 125). Gaussian. NIG(1). NIG(2). 0-3%. 23.00%. 25.94%. 26.05%. 23.46%. 3-6%. 19.64%. 20.34%. 20.34%. 23.47%. 6-9%. 18.32%. 20.74%. 9-12%. 35.45%. 12-22%. 27.51%. 21.12% 治 政39.86% 55.52% 大 28.83% 28.92%. 立. 21.19%. 67.27% 29.32%. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 圖 2 不同模型在 2009 年 3 月 31 日之各分券隱含相關曲線. 35.
(42) 表 3 不同模型在 2010 年 3 月 31 日之各分券隱含相關值. 分券. Gaussian (m = 125). Gaussian. NIG(1). NIG(2). 0-3%. 64.80%. 64.45%. 78.78%. 79.21%. 3-6%. 68.37%. 96.81%. 78.78%. 79.22%. 6-9%. 59.37%. 27.29%. 9-12%. 10.00%. 12-22%. 23.35%. 31.62% 治 政7.24% 12.48% 大 24.66% 34.91%. 立. 94.43%. 11.05% 35.77%. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 圖 3 不同模型在 2010 年 3 月 31 日之各分券隱含相關曲線. 36.
(43) 表 4 不同模型在 2011 年 9 月 30 日之各分券隱含相關值. 分券. Gaussian (m = 125). Gaussian. NIG(1). NIG(2). 0-3%. 27.41%. 30.20%. 30.26%. 27.56%. 3-6%. 23.70%. 24.18%. 24.17%. 27.68%. 6-9%. 18.72%. 21.05%. 9-12%. 60.25%. 12-22%. 28.15%. 21.53% 治 政9.43% 9.45% 大 29.41% 29.45%. 立. 21.56%. 10.03% 29.91%. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 圖 4 不同模型在 2011 年 9 月 30 日之各分券隱含相關曲線. 37.
(44) 表 5 不同模型在 2012 年 1 月 31 日之各分券隱含相關值. 分券. Gaussian (m = 125). Gaussian. NIG(1). NIG(2). 0-3%. 38.02%. 40.24%. 48.72%. 49.38%. 3-6%. 51.71%. 51.53%. 47.99%. 48.10%. 6-9%. 66.96%. 50.10%. 9-12%. 61.85%. 12-22%. 17.81%. 51.79% 治 政 4.32% 大4.97% 19.26% 21.13%. 立. 69.21%. ‧ 國. ‧ y. sit. n. al. er. io. 70% 60% 50%. 19.09%. 學. Nat. 80%. 5.39%. Ch. 40%. engchi. i n U. v. Gaussian (N = 125) Gaussian NIG(1). 30%. NIG(2) 20% 10% 0% 0-3%. 3-6%. 6-9%. 9-12%. 12-22%. 圖 5 不同模型在 2012 年 1 月 31 日之各分券隱含相關曲線. 38.
(45) 表 6 不同模型在 2013 年 3 月 28 日之各分券隱含相關值. 分券. Gaussian (m = 125). Gaussian. NIG(1). NIG(2). 0-3%. 56.93%. 58.24%. 68.93%. 72.18%. 3-6%. 68.58%. 77.35%. 67.87%. 63.12%. 6-9%. 60.08%. 2.73%. 9-12%. 59.85%. 12-22%. 22.04%. 2.26% 治 政6.52% 7.40% 大 23.45% 25.73%. 立. 94.54%. ‧ 國. ‧ y. sit er. al. n. 80% 70%. 27.64%. 學. io. 90%. Nat. 100%. 8.04%. 60%. Ch. 50%. engchi. i n U. v. Gaussian (N = 125) Gaussian. 40%. NIG(1). 30%. NIG(2). 20% 10% 0% 0-3%. 3-6%. 6-9%. 9-12%. 12-22%. 圖 6 不同模型在 2013 年 3 月 28 日之各分券隱含相關曲線. 39.
(46) 第五章 結論與建議 本研究應用各種單因子關聯結構模型評價不同時期之DJ iTraxx分券,探討各 模型在不同商品型態的評價以及綜合各模型之比較分析。根據以上各章節研究內 容以及實證分析之結果,提出本研究之結論,並對於評價合成型抵押擔保債券憑 證等相關層面給予適當建議,期許能使此研究更為完善。. 自1992年開始發行信用衍生性商品後,其市場交易量急遽成長,遂成為金融. 政 治 大 的資產轉變為多標的資產的組合信用風險。對金融機構而言,如何控管組合信用 立. 市場上很重要的商品。隨著市場的演變,金融機構所面臨的信用風險已從單一標. ‧ 國. 學. 風險儼然成為一項重要的議題,在這樣的時空背景下,給予了組合信用衍生性商 品發展契機。以抵押擔保債券為主的信用衍生性商品發行量在2000-2006年間迅. ‧. 速成長。而次級貸款借款者使得信用市場違約率大幅度提高,也成為了2007 年. sit. y. Nat. 美國「次級房貸」風暴的導火線,此次事件也連帶影響到整個國際金融情勢,像. al. er. io. 是歐洲的「歐債危機」本文將對2006年之後的不同商品型式之合成型抵押擔保債. v. n. 券價格進行評價,以了解近年來商品發展趨勢與未來改善之道。. Ch. engchi. i n U. 在評價合成型抵押擔保債券憑證時,需考慮多個標的資產間之違約相關性。 最早描述違約相關性的模型,出現在 Li (2000)的關聯結構模型,然而,必須透過 大量模擬來取得各資產的違約時間,在大樣本的標的資產組合下會提高運算過程 中的困難度。此後更進一步延伸為高斯分配等單因子關聯結構模型,其在執行各 分券評價時,僅有在權益分券得到好的配適結果而已,此外,還會造成相關性微 笑曲線等問題。Dezhong et al. (2006) 則提供了單因子關聯結構延伸模型,希望 藉由具有厚尾性質的函數來改善舊有的單因子關聯結構模型。但是,由於 t 分配 沒有穩定的摺積性,必須使用數值積分的方式求解違約門檻值,會增加計算所需 40.
(47) 的時間。Kalemanova et al. (2007) 提出應用 LHP 假設之單因子 NIG 關聯結構模 型,其評價結果遠優於常態分配,但其高估了中間順位層級以上的分券。邱嬿燁 (2007)使用 CSN 分配取代 NIG 分配來做抵押擔保債權憑證分券的評價,但與單 因子常態關聯結構模型相同,單因子 CSN 關聯結構模型仍無法估計的很準確, 只有在最高等級分券的評價上有明顯的改進。邱嬿燁(2007)嘗試使用 NIG 及 CSN 複合分配 MIX 分配之單因子關聯結構模型評價抵押擔保債權憑證,而在實 證分析中此模型得到極佳的評價結果。林聖航(2012)使用不同的單因子關聯結構 模型,針對不同商品結構的合成型抵押擔保債券評價,觀察以上的模型是否能應. 治 政 大 因子 NIG(2)關聯結構模型會是最佳的評價模型。本文研究目的在於,針對單因 立. 用在新型的合成型抵押擔保債券,並對各種商品型式進行模型比較分析,得知單. 子高斯關聯結構模型,建立單因子高斯關聯結構延伸模型,假設在非大樣本性質. ‧ 國. 學. 下,評價合成型抵押擔保債券憑證,嘗試觀察是否有較佳的估計結果,改善相關. ‧. 性微笑曲線的現象。. y. Nat. er. io. sit. 而本文研究目的在於應用以上的單因子關聯結構模型對不同的商品型式的 合成型抵押擔保債券進行評價。本研究選擇了六個時期以 DJ iTraxx Europe 信用. al. n. v i n 違約交換指數為標的之市場報價資料進行實證分析,各模型的參數估計是由絕對 Ch engchi U 誤差極小化方法來計算。另外,也對各模型進行隱含相關性分析以驗證是否符合 LHP 假設。根據以上實證分析結果,提出了本研究結論如下 :. 實證分析結果顯示 NIG(2)模型優於其他模型,更符合市場實際需求, NIG(2) 模型除了維持原本在權益層級及次順位層級分券配適佳的優點外,並在中間順位 層級分券得到極佳的配適效果。反映 NIG(2)比 NIG(1)多一個參數 β 的估計,能 夠有改善的評價結果,此項發現與 Kalemanova et al. (2007) 所結論是有所不同, 主要原因在於所評價為不同商品結構的 DJ iTraxx。. 41.
數據
相關文件
Step 4: : :模擬結果分析 : 模擬結果分析 模擬結果分析(脈寬為 模擬結果分析 脈寬為 脈寬為90%) 脈寬為.
因此在表 5-4 評估次項目中,統計結果顯示政治穩定度、房產政 策、官僚政治以及景氣是接受度最高的,可以顯示政局安定以及當局
表 2.1 停車場經營管理模型之之實證應用相關文獻整理 學者 內容 研究方法 結論
我們分別以兩種不同作法來進行模擬,再將模擬結果分別以圖 3.11 與圖 3.12 來 表示,其中,圖 3.11 之模擬結果是按照 IEEE 802.11a 中正交分頻多工符碼(OFDM symbol)的安排,以
樹、與隨機森林等三種機器學習的分析方法,比較探討模型之預測效果,並獲得以隨機森林
則巢式 Logit 模型可簡化為多項 Logit 模型。在分析時,巢式 Logit 模型及 多項 Logit 模型皆可以分析多方案指標之聯合選擇,唯巢式 Logit
譚志忠 (1999)利用 DEA 模式研究投資組合效率指數-應用
本研究採用的方法是將階層式與非階層式集群法結合。第一步先運用
