第二章 理論基礎與文獻探討
第一節 知識管理相關理論的探討
一、知識的定義
在界定知識管理時,對於何謂知識?及真正涵義為何?都要先將以澄清。「知 識」常與「資料」、「資訊」及「智慧」相混淆。以下就資料、資訊、知識與智慧 四者的涵義整理如表2-1。
表2-1 資料、資訊、知識與智慧四者的涵義
類別 說明
資料(data)
1.
有關於各種事件的簡單、明確、客觀的事實,易於結構化、取 得、溝通、並且容易傳達給他人。(吳清山、黃旭鈞 2000)2.
初始的文字、數字(raw verbal information or number)。(計惠卿 2001) 資訊
(information)
1.將資料加以分析並賦予意義,可能同時結合兩個以上的事實而 產生另一新的事實。(吳清山、黃旭鈞 2000)
2.把有資料作脈絡的處理(data-contextual treatment)。(計惠卿 2001)
知識
(knowledge)
1.資訊的累積並無法變成知識。所謂的知識意指由人根據實際的 情境所作的判斷。(吳清山、黃旭鈞 2000)
2.把資訊加上學習經驗及價值認知(information + experience)。資 訊要經過學習的認知、技能與情意的經驗方能形成知識。(計惠 卿 2001)
3. 戴文波特 (Thomas H. Davenport) 說 :「知識是一種流動性質 的綜合體;其中包括結構化的經驗、價值、以及經過文字化的 資訊。此外,也包含專家獨特的見解,為新經驗的評估、整合
與資訊等提供架構」(Thomas H Davenport & Laurence Prusak 1999)。
智慧(wisdom) 1.指在許多地方實踐多次之後累積而成。(吳清山、黃旭鈞 2000) 2.直覺的知識(intuitive knowledge),能有效率且有效果地把知識
應用出來(計惠卿 2001)
有關「知識」常與「資料」、「資訊」及「智慧」四者關係如圖2-1,由圖中 可知道知識管理中所要管理的是價值性較高的知識和智慧。雖然資料與資訊可能 構成知識和智慧的基礎,但對雜亂無章的大量資料與較不需專業判斷的資訊,則 並非知識管理所強調的重點。(吳清山、黃旭鈞 2000)
圖2-1 知識分類的階層(Helfer, J,1998)
二、實施知識管理的策略
知識管理著重於將資料轉成資訊再轉為知識的轉換過程。知識管理的策略可 分為隱性策略與顯性策略,如表2-2。
表2-2 隱性策略與顯性策略比較表(整理自陳樹祿 2000)
項目 隱性策略 顯性策略
知識分類 無法用文字描述的「經驗性」知 識,不容易文件化與標準化的「獨 特性」知識,而必須經由人際互
可以文件化、標準化、系統化的知 識,亦可以透過報告、分析、手冊、
說明書、實踐、電子郵件、軟體程 資料
資訊
知識
智慧
價值
動才能產生共識的「組織式」知 識。
式等方式來表達知識。
策略重點 如何將隱性知識的創造過程效率 化。比較強調人際溝通的方式,
提昇知識創新的效果。
將隱性知識迅速轉化為顯性知識,
並提昇顯性知識知識流通與擴散的 效率。
策略方式 1. 形成一致性的企業文化與共 識、開放性的組織氣芬。
2. 運用多媒體網路增加人際溝 通的效率、專家型的團隊管 理、良好的教育訓練與學習機 制及更完善的周邊配套,來用 以提昇組織隱性知識創造過 程的效率。
1. 有計劃的發展組織知識庫、引用 移轉外部知識。
2. 設置專責的知識管理部門來從 事知識的收集、整理、分析與使 用。
3. 運用網際網路來流通知識、發展 標準作業流程、開發專家系統與 決策支援系統。
成本 高 低
可重複性 低 高
三、資料庫知識發現流程
資料庫知識發現的流程包含下列幾個步驟(Fayyad, 1996):
1.資料的選取(data selection):了解應用領域以及使用者的需求,並且應用 相關的先前知識,由資料庫選取與探索目標相關的資料,以建立目標資料 集來選擇出目標的相關資料。
2.資料的先前處理(data pre-processing):過濾資料雜質、處理缺漏資料、
定義資料型態與綱要等。
3.資料轉換(data transformation):資料範圍縮小與資料投射,包含對於目標 及任務找出有用的代表資料,並利用多維度法或資料轉換法來減少變數或
找出不變的資料代表。
5.資料採擷(data mining):將轉換後的資料,根據問題的種類來進行資料採 擷。
6.說明與評估(interpretation/ evaluation):根據資料採擷後所得出的模型,
對結果解釋與評估與決定結果呈現方式。
第二節 中文斷詞
針對中文的試題而言,進行分類之前,必須先要可以對中文進行斷詞的 工作,以便於了解每一種類型的試題中所包含的關鍵字詞有哪些。然而在 斷詞方面,中文比起印歐文字要困難許多。
中文字與印歐文字的差別,主要在於斷詞的方式(Nie 1996)。以印歐語系而 言,主要的特色是:
1. 一個字 (word) 是由字母組成,字與字之間使用空白隔開。
2. 一個英文字所代表的意義如果翻譯成中文,通常是數個中文字所構 成的字詞。
以中文字而言,主要的特色在於:
1. 字與字之間緊密相連。
2. 有意義的詞中所包含的文字與介詞或副詞可能重複使用。
中文文件大致上有下列四種斷詞法,分別是:詞庫式斷詞法(Chen.K.J and S.H Kiu 1992)、統計式斷詞法 (Sproat 1990) 、混合式斷詞法 (Nie 1996) 及基因演算法(John Holland 1975),以下將分別對這些斷詞法作說明:
1. 詞庫式斷詞法
為目前普遍使用的斷詞方法,其演算法相當直覺且實作容易。然而,斷詞 的品質與詞庫大小有相當的關係。所以,必須時常對詞庫的內容加以維 護,另外其他學者將詞庫斷詞法,輔以一些詞性的結構,發展出規則式斷
詞法(陳克健 1996),提昇斷詞的品質。
2. 統計式斷詞法
統計式斷詞法(Sproat 1990)乃參考一大型語料庫(corpus)上的統計資 訊,單純以鄰近字元同時出現頻率高低作為斷詞的依據。由於語料庫屬於 領域相關(domain dependent),不同語料庫間的統計資訊不適合互用(Nie 1996)。再者,統計式斷詞常受限於一接馬可夫模式(first-order Markov Models)(Li 1991),進一步擴充此模式會提高演算法的時間複雜度(Nie 1996),所以大多只針對二字詞進行處理,三字詞如:「大賣場」、四字詞 如「小額投資」等就無法有效擷取。
3. 混合式斷詞法
將詞庫斷詞法及統計斷詞法整合。(Nie 1996)利用詞庫斷出不同組合的詞 彙,然後利用詞彙的統計資訊,找出最佳的斷詞組合。此法乃需要大型的 語料庫提供統計資訊。
4. 基因演算斷詞法
基因演算法(genetic algorithms)是在 1975 年由 John Holland 提出,其理 論是基於達爾文物競天擇、適者生存,不適者淘汰的為基礎,所發展出來 的最佳化搜尋演算法。在一個群體中,會因為環境的限制,適應力較好的 個體會存活,而延續下一代,經由數代的演化,而逐步的得到許多可能解,
甚至是最佳解。
在使用基因演算法來作中文斷詞的處理上 (謝佳倫 1999),假設使用 者輸入的文字有n 個字,則染色體長度為 n-1,若基因之為 1,則該基因 所對應到字詞以下將作間隔。反之為0 則不做間隔,以「強調將堅決支 持」七個字為例:
C1 C2 C3 C4 C5 C6 C7 強 調 將 堅 決 支 持
1 0 0 1 1 0 Å 染色體
斷開的關鍵字C1,用 W(C1)代表,第二組斷開的關鍵字為 C2,C3,C4,
用W(C2,C3,C4)代表,以此類推第三及第四組的關鍵字分別為,W(C5)、
W(C6,C7),則適應性函數 F 為:
[ ]
∑
=×
= n
i
i
i LW
W T F
1
)2
( ) (
(2-1) T(Wi):關鍵字 Wi 在詞庫中出現的機率
L(Wi):關鍵字 Wi 的長度 0<I<y,I 為整數
IF L(Wi)>N THEN T(WI)=-1 IF Wi Cant’t find THEN T(WI)=1
經由數代的複製、交配、突變之後,得到最佳的的斷詞如下:
C1 C2 C3 C4 C5 C6 C7 強 調 將 堅 決 支 持
0 1 1 0 1 0 Å 染色體 (引用自張育銘、黃國禎 2001)
第三節 文件分類(Text Categorization)
試題分類的概念將嘗試由文件分類的概念移植過來,因此以下將針對文件分 類作說明。
文件分類通常所指的是由一群專家,針對一類群的文件進行分類的工作,然 而隨著文件的增加,這樣的工作將會變得十分的困難,而且無法持續的進行這類 的工作,因此自動化文件分類在智慧型的資訊系統中,是很重要的技術(M.
Iwayama 1994)。
文 件 分 類 的 方 法 很 多 , 大 致 上 分 成 決 策 規 則 (decision rule)、知識庫 (knowledge base)及文件相識度(text similarity)等等。
大部分的文件分類研究,都將文件的類型鎖定新聞內容,因為新聞內容在產 生之初,都已經根據報社預先規劃進行分類,因此新聞內容及其分類的結果,是 最容易取得而且客觀的研究素材。在教育領域中,試題也都會依據課程大綱或能 力項目來出題並且分類,因此這樣的素材也是具有客觀標準。以下將針對文件分 類做介紹:
一、最早的文件分類文獻
英文的文件分類, 是由 Maron 於 1961 年提出 (Maron 1961),其文件分類 的方法,是由文件中所萃取出一些關鍵字當作線索。並假設電腦可以從文件中自 動萃取出這些關鍵字,那便可以自動分類。其實驗採用 405 篇文章的摘要當作 描述樣本,並使用206 篇當作訓練資料,145 篇當作測試資料,結果得到 3263 個詞,去掉出現頻率最高,及只出現過一兩次的詞,留下 1088 個詞。再藉由 Entropy 公式
M(C)=-P +log2P +-P -log2P – (2-2)
P + 代表被歸類為”+”類的機率 P -代表被歸類為”-”類的機率
了解關鍵字分佈的情形,將分佈平均者去掉,保留分佈不平均者,因為不平 均者才有分類的價值。最後只留下90 個詞的關鍵字。
二、路透社Reuters-21578
在英文的文件分類領域中,由 CONSTRUE 及 Hayes 採用 Reuters-22173 為路透社建立的規則式 (rule based)的文件分類系統,這套系統在人工與機器的 分類上所得結果的一致性相當高。而在1996 年 ACM SIGIR 研討會上,與會專 家為了讓Reuters-22173 有更高的標準。因此 Steven Finch 與 David D. Lewis
更著手刪除重覆的文件 595 篇,並減少了拼字上的錯誤,而使文件總數降為 21578 篇,並訂為 Reuters-21578。此外他們也為每一份文件訂上了統一的文件 格式,如分別為文章的起始與結尾標上<REUTERS> </REUTERS>的標籤 (Tag),讓文件分類研究者有一套統一的實驗資料標準(蔡文憲 1998)。
三、字詞權重函數 (term weighting)
字詞權重在文件分類的領域十分重要,其目的是要藉由權重,來得知哪些字 詞可以成為分類的特徵字詞 (feature word),而 Term Frequency 及 Inverse Document Frequency 在字詞權重是最基礎的理論,說明如下:
(一)字詞出現頻率(Term Frequency, TF):
關鍵字出現率指的是某一關鍵字在某類文件中的出現次數,在文件d 中關鍵字t 的權重可定義為:
W(d,t)=TF(d,t) (2-3)
TF(d,t) :文件 d 中出現關鍵字 t 的權重
TF 值已經可以的到很高的回歸率(recall rate),但並不精密。主要是 因為如果有一個關鍵字,經常出現在各個文件當中的話,這些關鍵字作 為某種分類的特徵並不明顯。因此最好可以將出現在所有文件中頻率高 的關鍵字在關鍵字集(term collection)中移除。因此必須找出各文件關鍵 字出現率最佳的容忍限度,以提高回歸率。
(二)逆文件頻率(Inverse Document Frequency, IDF):
出現某一關鍵字的文件數量稱之為逆文件頻率。逆文件頻率所表達
的概念是,關鍵字是否普遍的出現在各個文件當中,如果普遍出現的 比例越高,則越無法突顯分類的特徵﹔相對的越低,最好是集中出現 在同一個分類之中,則越容易突顯。假設關鍵字為 t,則IDF 定義如下:
IDF(t) = N/df(t) (2-4)
N:代表文件的總數
df(t):代表含有關鍵字 t 的文件總數
如果使用IDF 來表達關鍵字的特徵(term specificity),則將可以提高 回歸率(Salton and Buckley, 1988)。
(三)TF × IDF
而根據Salton 建議,如果使用 TF×IDF 當作加權數的話,則將會 有更好的執行效率。
W(d,t)=TF(d,t) .IDF(t) (2-5)
W(d,t):關鍵字 t 在 d 文件類別的權數 TF(d,t): 關鍵字出現率(Term Frequency)
IDF(t):逆文件頻率(Inverse Document Frequency) 藉由上述的公式,可以很明顯的提高回歸率及精密度。
(四)WIDF(Weighted Inverse Document Frequency)(M. Iwayama,1994):
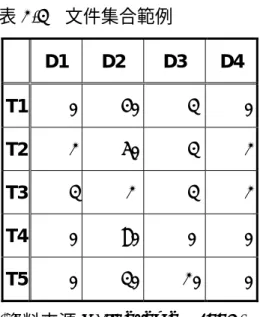
依據 IDF 的定義,關鍵字出現於各類文件的次數而言,不論各類 文件出現該關鍵字的次數,只論出現各關鍵字詞的文件類別數,將會 出現特徵分佈不合理問題。以行來代表文件分類 di,以列代表關鍵字 tj,其出現頻率如表2-3:
表2-3 文件集合範例
D1 D2 D3 D4
T1 0 40 3 0
T2 2 50 3 2
T3 3 2 3 2
T4 0 80 0 0
T5 0 30 20 0
(資料來源 M. Iwayama,1994)
以T1、T4 及 T5 的關鍵字而言,其分佈在 D1~D4 的頻率並不平 均,因此可以很容易的辨別其分類。T2 的分佈也不平均,在 D2 有 50 的權重,而T3 可以清楚的看出權重分佈平均,而計算得到:
1/df(T2)=1/(1+1+1+1)=1/4 1/df(T3)=1/(1+1+1+1)=1/4
都是是1/4,結果所得到到 IDF 值都是 1,顯然並不合理。
應該將其在該類文件中的出現頻率表現出來,所以如果可以改成 50/(2+50+3+2),將會更加合理。因此使用 WIDF,在文件 d 中含有 t 關鍵字的定義如下:
∑
∈
=
D i
t i TF
t d t TF
d
WIDF ( , )
) , ) (
, (
(2-6)
TF(d,t):代表關鍵字在 d 文件類別中出現的頻率
∑
∈D i
t i TF(, )
:i 代表 D 的文件集合的範圍內的各類文件。
因為 TF(d,t)已經包含在分子了,所以不需要再另外乘上 TF(d,t)。因此可將 W(d,t)定義為﹔
W(d,t)=WIDF(d,t) (2-7)
由M. Iwayama 的實驗中,可以得知,其回歸率確實比 TF×
IDF 提高了4.4%,而最高的回歸率也達到 96% (該實驗以英文為
主)。
(五)採用取平方的 IDF
由上述的內容得之,使用log ( ) t df
N
會降低詞的特殊性,所以 分類效果不甚理想,為了拉大特殊詞與常用詞之間的差距,可以
採用
2
) (
t df
N
作為 IDF (林頌華 1999)。則權重定義可調整成:
2
) ) (
, ( ) ,
(
⋅
= df t t N d TF t d W
(2-8)
在林頌華的研究用於處理中文新聞分類,採用二、三字詞為 基本單位來處理太一新聞資料庫,在5376 筆測試資料中對 53767 筆資料作計算,則以原始類別來說,可得到 78.89%的正確率,
而第三高分則可高達93.43% (該實驗以中文為主)。
以上所探討的文件分類關鍵字權重函數,可以發現大部份都是在逆文 件頻率 IDF 上作調整,以達到最佳的分類效果,主要是因為太過於普遍出
現的關鍵字,會干擾到分類的效果;相反的關鍵字越集中在單一的類別之 中,則其效果越好。以下就分別依各種字詞權重函數(TWF)之優劣分析於表 2-4:
表2-4 各種字詞權重函數 (TWF) 比較表
TWF 公式 分析
TF W(d,t)=TF(d,t)
z 可 以 表 現 出 一 個 關 鍵 字 在 某 文 件 類 別 上 重 要的程度。
z 無 法 辨 識 出 關 鍵 字 是 否 普 遍 出 現 在 各 文 件 類別之中
IDF IDF(t) = N/df(t)
z 可 以 表 現 是 一 個 關 鍵 字 普 遍 存 在 於 各 文 件 類別的程度
z 無 法 突 顯 關 鍵 字 在 單 一文件類別的重要性
TF×IDF W(d,t)=TF(d,t) .IDF(t)
z 可 以 表 現 是 一 個 關 鍵 字 普 遍 存 在 於 各 文 件 類別的程度,也可以了 解 關 鍵 字 是 否 普 遍 的 出 現 在 各 種 文 件 類 別 的程度。
z 會 減 弱 普 遍 存 在 於 各 文件類別,但卻有高出 現率的的關鍵字特徵。
TWF 公式 分析
WIDF
∑
∈
=
D i
t i TF
t d t TF
d
WIDF ( , )
) , ) (
, (
z 可 以 表 現 是 一 個 關 鍵 字 普 遍 存 在 於 各 文 件 類別的程度,也可以了 解 關 鍵 字 是 否 普 遍 的 出 現 在 各 種 文 件 類 別 的程度。
z 可 以 表 現 出 普 遍 存 在 於各文件類別,但卻有 高 出 現 率 的 關 鍵 字 特 徵。
TF×IDF2
2
) ) (
, ( ) ,
(
⋅
= df t t N d TF t d W
z 可 以 表 現 是 一 個 關 鍵 字 普 遍 存 在 於 各 文 件 類別的程度,也可以了 解 關 鍵 字 是 否 普 遍 的 出 現 在 各 種 文 件 類 別 的程度。
z 可 以 讓 集 中 在 某 一 文 件類別的關鍵字,其特 徵更加突顯。
第四節 文件相似度(Text Similarity)
早期 Maron 提出若想要對文件作分類,可以從文件中某些重要詞中找出稱 為關鍵字(keywords)分類的依據。並可利用關鍵字於類別中的分佈情形,結合機
率達成文件自動分類的目的。近年來文件分類的研究加入了統計分析、專家系 統、自然語言處理和類神經網路…等技術,以提高分類的正確性。
一、機率模式
藉由機率的理論所計算出文件 d 在 Ci類別出現的機率為 P(Ci|d),則:
∑
=
t i
i d P C t d P t d
C
P( | ) ( | , ) ( | )
(2-9) 關鍵字t 的範圍超過 Ci 及 d 的向量元素,假設 Ci 及 d 的條件彼此獨立,則 P(Ci|t,d)=P(Ci|t),則可以求得公式如下:
∑
=
t i
i d P C t P t d
C
P( | ) ( | ) ( | )
(2-10) 使用Bayes rule,則最後可以得到,公式如下:
∑
=
t
i i
i P t
d t P C t C P
P d C
P ( )
)
| ( )
| ) (
( )
| (
(2-11) 關鍵字 t 隨機於 Ci類別取出,則其機率為 P(t|Ci) ;關鍵字 t 若隨機於文件 d 中取出,則其機率為P(t|d) ,P(t)及 P(Ci)分別代表關鍵字及文件類別的機率,
而所有的機率都是由訓練資料集所評估出來的。當一個文件d 被歸類到類別 Ci 之後,則會得到P(Ci|d)的最高機率。
二、向量模式
文件向量可以用每一個包含在文件中的關鍵字權重來構成,以用於區別文件 之間的差別定義如下:
Vd=(w1,w2,……,wn) (2-12) wi:1<=i<=n,代表每一個關鍵字的權重
Vd:文件類別 d 的向量
衡量向量間差異的方法有很多,以Jaccard 函數來說,其定義如下:
∑ ∑
∑
∑
=
=
=
⋅
− +
⋅
= n
k
jk ik jk
n
k ik
n
k
jk ik j
i
w w w
w
w w V
V Sim
1 1
1
) (
) , (
(2-13)
三、倒傳遞類神經網路
類神經網路模式可分成四大類:
(一)、監督式學習網路
(二)、無監督式學習網路
(三)、聯想式學習網路
(四)、最適化應用網路
其中「監督式學習」網路是目前應用最普遍的頹神經網路,應用範圜 十分廣泛(約佔現有應用 95%)。較常用的監督式學習網路為:
(一)、倒傳遞類神經網路(Back-propagation Network,BPN)
(二)、多層函數連結網路(Multilayer Functional-Link Network-MFLN)
(三)、通用迴歸網路(General Regression Neural Network,GRNN)
(四)、學習向量化網路(Learning Vector Quantization Network,LVQ)
(五)、半徑式函數網路(Radial Basis Function Network,RBFN)
其中倒傳遞類神經網路模式是目前類神經網路學習模式中最具代表
性、應用最普遍的模式。已發表的應用至少在數千個以上,不勝枚舉。倒傳 遞類神經網路基本原理是利用最陡坡降法 (Gradient Steepest Descent Method)的觀念將誤差函數予以最小化。其網路架構如圖 2-2 所示,包括
(一)、輸入層:用以表現網路的輸入變數,其處理單元數目依問題而 定。使用線性轉換函數,即 f(x)= x。
(二)、隱藏層:用以表現輸入處理單元間的交互影響,其處理單元數 目並無標準方法可以決定,經常需以試驗方式決定其 最佳數目。使用非線性轉換函數。網路可以不只一層 隱藏層,也可以沒有隱藏層。
(三)、輸出層:用以表現網路的輸出變數,其處理單元數目依問題而 定。使用非線性轉換函數。
圖2-2 倒傳遞類神經網路 X1
X2
Xn
Y1 Y2
Yn
輸入層 隱藏層 輸出層
在文件分類上,輸入層為特徵關鍵詞、輸出層為類別,而隱藏層則表關 鍵詞和類別互相影響的關係。在學習過程中,可將輸出層的錯誤值逐層倒傳
(feedback)回來,用以修正各層間的網路連結加權值。此網路的優點為學 習精確度高,缺點為學習數度慢,有區間最小值(local minimal)的問題。
第五節 Ontology-based 的知識分類與發掘
一、ontology-based 的知識分類
學者 Chandrasekaran 等指出 ontologies 是一個特定知識領域中關於物件 的排序(sorts)、特性(properties)與物件之間關係(relations between objects)的內 容原理(content theories)。並指出其重要性為:
1. 透過本體論的分析可以釐清知識的結構,特別是其表現出一個特定領域 的知識核心。
2. ontologies 可以促成知識的分享,包括提供在特定知識領域上分析、概 念化的達成及呈現出其代表性的項目等。
學者 Czejdo (2000)針對特定領域的本體論來定義概念與相似的關係來 作為資訊探勘的技術。其方法包含下列三個文件處理的步驟:
1. 根據已建立的 domain-specific ontology 作為定義文件分類概念的依 據與註解的概念。
2. 運用語法規則定義文件並註解其關係。
3. 適當的轉譯文件註解,以便將其劃分到適當的類別。
二、ontology-based 的知識發掘
學者Braga、Mattoso、Werner(2000)提出以本體論格式組成的領域 知識(domain knowledge)為基礎的資訊檢索技術 Odyssey,其中的
ontologies 乃建構在不同的工程領域流程 (domain engineering process) 上,即使使用者不是某些領域的專家,利用Odyssey 技術仍然可以從該領 域檢索出其特有的資訊。
美國學者Crampes、Ranwez(2000)提出以 ontologies 為背景的代理 人(agents)協助使用者搜尋、組織相關文件,並找出其中可能的連結。其 中提到兩種使用ontology 的概念來尋找全球資訊傳播網上的超本文
(hypertext)與超媒體(hypermedia)文件,分別為:
1. ontology-supported:居於輔助的色,其將 ontologies 作為查詢及 文件連結關係的參考對向。
2. ontology-driven:居於主動的角色,將 ontologies 作為查詢的依據。
第六節 關聯定義及相關名詞
本研究將利用資料採擷分析方法中的Apriori 關聯式演算法,採擷本體 論中概念節點之間的屬性與方法等組成元素,以產生兩個不同概念間關聯的 規則集,因此我們將在本節中探討關聯式法則的相關定義及Apriori 演算法。
目前關聯式法則的相關研究可以說非常的熱門,研究方向也非常的廣。
首先,我們以行銷的角度為例子來介紹關聯式的意義。在購買X 牌香煙的 消費者中,有90%的消費者也同時購買了 Y 牌的酒;這兩者關係的描述就 是一種關聯,而且很清楚的表現出行銷行為所要注目的焦點。目前已有很多 種技術可以尋找出這些關聯式的規則,使決策者將可很輕鬆的從資料庫中,
找出許多的資訊供做參考。
若依照Agrawal and Srikant(1994)所設計的流程,並以技術的觀點 來看關聯式法則的建立,基本上可以分為下列兩個步驟:
一、在資料庫中尋找出所有可能的多數項集合(Large Itemsets),並且這些 多數項集合的支持度(Support Level)要大於所設定的最小支持度 (Minimal Support Level)。
二、利用多數項集合以產生適當的法則。例如,假設找出的多數項集合為 XY,則可能產生一條法則為 X⇒Y,同時我們亦計算當 X 發生時也發生 Y 的機率 Support(X ∩ Y)/Support(X),即所謂的信賴度(Confidence Level);若是算出的信賴度大於所設定的最小信賴度(Minimal
Confidence Level),則此條法則就可以被確立。
Apriori 關聯式演算法是以單一資料項(Item)為搜尋起點,逐漸擴充到 多個資料項的搜尋。此優點可以減少非相關資料項的產生,缺點是效率太 差。以下將根據Han and Kamber(1999)及 Cohen et al.(2000)的定義 方式,介紹關聯法則相關名詞。
令 I ={ i1,i2,i3,…im } ,代表全部資料項(Items)的集合;D 是指全部 交易紀錄T(Transaction)的集合;T 是 I 中任意資料項的集合;若 A 與 B 亦為 I 資料項的子集合,即 A⊆ I、B⊆ I 且 A∩B= φ,則 A⇒B 可視為 一種關聯規則。關聯法則的目標就是要找出A⇒B 的規則中大於最小支持度 和信賴度的集合。支持度可定義為一次交易中包含A、B 的可能性;而信賴 度即為包含A 的交易中也包含 B 的條件機率。
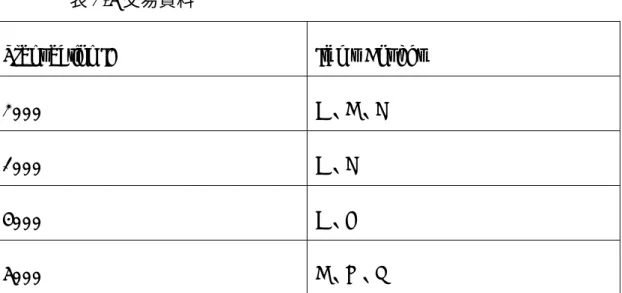
為方便說明,我們以表2-5 的交易資料為例。首先我們將最小支持度設 定為50%,最小信賴度為 50%。在 4 個交易中有 2 個交易同時出現 A、C,
亦即Transaction ID 為 2000 及 1000 的交易,所以我們可計算出 A⇒C 的 支持度為=2/4(50%);同時,在 4 個交易中有 3 個交易有出現 A,亦即 Transaction ID 為 2000、1000 及 4000 的交易,但又出現 C 的則有 2000
及1000,因此其信賴度=2/3(66.6%)。由於計算出的支持度及信賴度都大 於我們所設定的最小支持度及最小信賴度,所以我們說此條法則A⇒C 可 以被確立。
表2-5 交易資料
Transaction ID Items Bought
2000 A、B、C
1000 A、C
4000 A、D
5000 B、E、F
從以上的定義可以看出在關聯法則中,兩個必須要注意的重要概念 (Agrawal and Srikant,1994):
一、Support Level:代表資料項集合(Data Itemsets)在資料庫中所佔有的比 例,若佔的比例較高,則表示此資料項集合應是一個值得重視的討論要 項。
二、Confidence Level:以條件機率的概念來看,若有一條法則是 A⇒C,
則為P (C ) / P (A ∩C) 即其 Confidence Level。
透過支持度與信賴度兩個參數可判斷該關聯法則是否有意義。若其支持 度與信賴度都滿足使用者所訂定的最小限制,則稱該關聯法則為穩健
(Strong)的關聯法則。
第七節 關聯式Apriori演算法
Apriori 演算法主要包含下列兩個步驟,其說明如下:
(1)反覆地產生候選項目組(Candidate Itemset)和搜尋整個資料庫,直 到找出所有的高頻項目組。
(2)利用步驟(1)所找出的高頻項目組(Frequent Itemset),推導出所有 的關聯法則。
在步驟(1)產生高頻項目組的過程中,Apriori 演算法由單一項目組
(1-itemset)開始,由上而下(Top-Down)且逐層(Level-Wise)去產生 相關項目組(k-itemset,k>1),而此過程亦可分為兩個階段。第一階段為產 生新的候選項目組,若長度為k,則稱為候選 k-項目組(Candidate
k-itemset),記為 C k ;接著第二階段為搜尋資料庫,計算 Ck 的支持度是 否大於或等於使用者所設定的最小支持度(Minimal Support Level)的限 制,符合條件限制的C k 便稱為高頻 k-項目組(Frequent k-itemset)或大 k-項目組(Large k-itemset),記為 Lk ,而不符合條件限制的 Ck 則予以刪 除。
根據以上敘述,再由L k 聯結(Join)以產生下一層級之新的候選項目 組C k+1 ,並再搜尋資料庫以產生 L k+1 。如此不斷的遞迴產生下一層級的候 選項目組,並搜尋資料庫以過濾出高頻項目組,直到所有資料庫中的高頻項 目組皆找出為止。由L k 聯結產生C k+1 的過程中,主要是根據一個重要的 特性,即當一個項目組是高頻時,則其所有子集合必是高頻項目組。因此,
我們僅需對L k 聯結以產生 C k+1 即可。又根據此一特性,若聯結產生的候 選k+1-項目組(Candidate k+1-itemset)中有一個 k-項目組(k-itemset)
的子集合不在L k 中,則此候選 k+1-項目組將被刪除,由此可大大減少非相 關項目組的產生。候選項目組的產生可表示為C k+1 = L k ×L k ={X∪Y |X,Y∈
LK,| X∩Y|=k-1 },產生函式如下所示,其中 p 及 q 分別屬於兩個項目組。
insert into C k
select p.item1 , p.item 2 , …, p.item 1 − k , q.item k-1 from L k-1 p﹐ L k-1 q
where p.item 1 =q.item 1 , …, p.item k-2 =q.item k-2 , p.item k-1 <q.item k-1