國立高雄大學應用經濟學系
碩士論文
台灣實質匯率與所得不均關係之探討
An Investigation on the Relationship between
Real Exchange Rate and Income Inequality in Taiwan
研究生:楊宗翰 撰
指導教授:翁銘章 博士
謝誌
轉眼間,隨著告一段落的論文,兩年的碩士生涯就這樣劃下句點了。回想起 這兩年的生活,我只能說時而快樂,時而痛苦,當然前者的情緒無庸置疑是比較 常發生的。在這兩年裡,真的學到了許多東西使得我獲益良多,也非常感謝各位 老師們以及同學們的幫助使得我能順利解決許多問題。 首先要感謝我的指導教授 翁銘章博士,真的非常謝謝翁老師各方面的教導, 不管是課業上的問題抑或是生活中的經驗分享,都是讓我們受用無窮的瑰寶。 當然,也感謝口試委員,柯秀欣老師和李慶男老師,謝謝兩位老師口試時對 於本論文的賜教,並提供了寶貴的意見及想法,使得本論文能更加完善。 接著,謝謝系上每位老師及系辦助理姿宇姐對我們的悉心照顧與教導,我們 知道老師們對我們的期望都很高,而我們也一定不會辜負老師們的期待,一定會 走出屬於自己,精彩的路。 另外,當然要感謝這一路上互相扶持的同學們,我來點個名:志禎、辰宇、 子慶、豐鍵、楷欣,儘管每個人的個性及優缺點都不同,謝謝大家總是會互相包 容體諒,跟大家相處的時光會是我最美好的回憶之一。還有,當然也要謝謝學長 姐及各個學弟妹的照顧。在高雄大學的日子裡,真心讓我覺得,不枉此生啊! 最後的最後,最要感謝的就是我的家人,謝謝他們一路上對我無條件的支持 與鼓勵,謝謝他們無怨無悔的付出,千言萬語只有一句,爸、媽,我愛你們。 在此,僅以本文獻給父親 楊瑋泰先生與母親 林佩靜女士 楊宗翰 僅誌於 國立高雄大學應用經濟學系碩士班 中華民國 105 年 6 月台灣實質匯率與所得不均關係之探討
指導教授:翁銘章 博士 國立高雄大學應用經濟系 學生:楊宗翰 國立高雄大學應用經濟系摘要
本研究探討台灣中央銀行的匯率政策,是否會與所得分配不均的狀況有關。 樣本資料期間為台灣 1981 年至 2015 年的年資料,本文採用的實證迴歸模型主要 引用自徐美、莊奕琦、陳晏羚(2015)探討造成所得不均之原因的理論模型,並 將其加進匯率此一變數來分析之。 實證結果發現,在研究期間的台灣實質有效匯率之波動的落後期會顯著地負 向影響當年的所得分配狀況。換句話說,若台灣實質匯率繼續保持較為趨貶的狀 態,用來估計所得分配不均的指標─吉尼係數及五等分位所得差距倍數則會越來 越高,亦即表示弱勢的新台幣實質匯率會造成所得分配不均的狀況益加嚴重;反 之亦然。 關鍵字:實質有效匯率、吉尼係數、五等分位所得差距倍數An Investigation on the Relationship between
Real Exchange Rate and Income Inequality in Taiwan
Advisor Name: Dr Ming-Jang Weng
Department of Applied Economics, National University of Kaohsiung
Student Name: Tsung-Han Yang
Department of Applied Economics, National University of Kaohsiung
Abstract
This study explores whether there exists the relationship between exchange rates and income inequality in Taiwan. We utilized the regression model of income inequality in Hsu et al. (2015) by adding the variable of exchange rate to analyze the annual data of Taiwan from 1981 to 2015.
It is found that there exists negatively lagged effect of current real effective exchange rate fluctuation on the speed of income inequality in Taiwan over the investigated period. In other words, if Taiwan’s real exchange rates keep depreciating, the Gini coefficient, as well as the quintile income difference ratio, will be worse, and vice versa.
Key words:Real effective exchange rate, Gini coefficient, Quintile income difference ratio
I
目錄
圖目錄... III 表目錄...IV 第一章 緒論... 1 1.1 研究動機與目的 ... 1 1.2 研究架構 ... 2 第二章 文獻回顧... 3 2.1 台灣匯率政策之研究 ... 3 2.2 台灣所得分配不均之研究 ... 4 第三章 理論模型與實證方法... 7 3.1 理論模型 ... 73.2 單根檢定(Unit root test) ... 8
3.2.1 Augmented Dickey-Fuller 單根檢定 ... 9 3.2.2 Phillips-Perron 單根檢定 ... 10 3.2.3 Kwiatkowski-Phillips-Schmidt-Shin 單根檢定 ... 11 3.3 共整合檢定 ... 12 3.3.1 Engle-Granger 共整合檢定 ... 13 3.3.2 Johansen 共整合檢定... 14 3.4 殘差診斷性分析 ... 16 3.4.1 序列相關檢定 ... 16 3.4.2 條件異質變異檢定 ... 17 3.4.3 常態分配檢定 ... 19 第四章 實證結果分析... 20 4.1 資料說明 ... 20 4.2 單根檢定結果 ... 28
II 4.3 共整合檢定結果 ... 46 4.4 迴歸模型分析結果 ... 47 4.5 殘差診斷性分析結果 ... 54 第五章 結論與建議... 56 5.1 結論 ... 56 5.2 建議 ... 57 參考文獻... 59 中文參考文獻 ... 59 英文參考文獻 ... 60
III
圖目錄
圖一 吉尼係數 23 圖二 五等分位所得差距倍數 23 圖三 實質有效匯率指數 24 圖四 每人平均國內生產毛額 24 圖五 失業率 25 圖六 女性就業人數占總就業人數之比例 25 圖七 工業生產毛額占 GDP 之比例 26 圖八 服務業生產毛額占 GDP 之比例 26IV
表目錄
4-1 所有變數資料之敘述性統計表 27 4-2 吉尼係數(GINI)之單根檢定結果 29 4-3 五等分位所得差距倍數(FIVE)之單根檢定結果 30 4-4 實質有效匯率指數(LNREER)之單根檢定結果 31 4-5 每人平均國內生產毛額(LNGDP)之單根檢定結果 32 4-6 失業率(UER)之單根檢定結果 33 4-7 女性工作者占總工作者人數之比例(FEMALE)之單根檢定結果 34 4-8 工業占總 GDP 之比例(INDUSTRY)之單根檢定結果 35 4-9 服務業占總 GDP 之比例(SERVICE)之單根檢定結果 36 4-10 吉尼係數一階差分(DLNGINI)之單根檢定結果 38 4-11 五等分位所得差距倍數一階差分(DLNFIVE)之單根檢定結果 39 4-12 實質有效匯率指數一階差分(DLNREER)之單根檢定結果 40 4-13 每人平均國內生產毛額一階差分(DLNGDP)之單根檢定結果 41 4-14 失業率一階差分(DUER)之單根檢定結果 42 4-15 女性工作者占總人數比例一階差分(DFEMALE)之單根檢定結果 43 4-16 工業占總 GDP 之比例一階差分(DINDUSTRY)之單根檢定結果 44 4-17 服務業占總 GDP 之比例一階差分(DSERVICE)之單根檢定結果 45 4-18 Johansen 共整合檢定結果 46 4-19 吉尼係數(DLNGINI)迴歸分析結果 48 4-20 五等分位所得差距倍數(DLNFIVE)迴歸分析結果 49 4-21 吉尼係數迴歸模型之殘差診斷性分析結果 54 4-22 五等分位所得差距倍數迴歸模型之殘差診斷性分析結果 551
第一章 緒論
1.1 研究動機與目的
近三十年來,台灣國內生產毛額(Gross Domestic Product, GDP) 名目上的 數值雖然是持續地穩定成長中,但 GDP 的「成長率」卻是逐年下降,或許某些 年的成長率會突然飆高,但那是由於前一年之經濟狀況可能較差,基期之 GDP 較小而導致的原因。話又說回來,GDP 代表著一國經濟發展的重要指標之一, 而 GDP 的成長停滯,造成工作機會的縮減以及薪資的凍漲,自然會使許多民眾 覺得現在的經濟是不景氣的。 根據行政院主計處調查發現,我國 2015 年的每人平均 GDP 為 2.2 萬美元, 匯率為 32.3,約相當於 71 萬台幣。每人每年賺 71 萬台幣,這數字乍看之下好像 還好,但其實這是每個人都該有的金額,換言之,家中較無經濟能力的小孩、學 生及老人每個人也都是每年賺 71 萬台幣,那就會是一筆不小的所得。根據行政 院主計處統計 2015 年之每戶平均人數為 3.5 人,也就是說平均起來每戶每年的 收入應該要達到約台幣 250 萬的水準,也就是每戶平均每月要有超過 20 萬元的 所得,這與現今我們所認知的實際社會現象似乎有相當大的差異。 此情況之合理的推斷即所得分配不均的情況可能越來越嚴重。通常用來衡量 所得不均的指標為吉尼係數,吉尼係數數值介於 0 到 1 之間,數值越高則表示所 得分配越不均,反之,數值越低則表示所得分配越平均。而吉尼係數這幾年來的 數值越來越高,從三十年前的 0.278 到現在升高到 0.336。造成所得分配不均情
2 況惡化的可能原因有很多,包括許多經濟指標,例如:GDP、人口、…等等,都 有可能影響所得不均的程度,而近來亦有報章媒體指出央行的匯率政策是造成台 灣低工資的重要因素之一(今週刊 902 期, 2014 年 4 月)。近十年來,台灣接單 海外生產,是許多出口廠商慣用的生產策略,以至於台灣的勞動力供過於求,造 成實質薪資倒退回十幾年前之水準,再加上 90 年代末期以來,央行弱勢新台幣 的匯率政策,其實是犧牲了全民的購買力,來成就出口廠商的價格競爭力,那麼 我們不禁要懷疑央行的匯率政策,是否也可能因此造成台灣近年來貧富不均持續 惡化的主要原因之一。因此本文想要探討台灣中央銀行的匯率政策,是否會造成 所得分配不均惡化的情況。 本文主要引用自徐美、莊奕琦、陳晏羚(2015)探討造成所得不均之原因理 論模型,將其加進匯率此一變數,並且除了吉尼係數,多採用一種衡量所得分配 不均程度之指標─五等分位所得差距倍數。接著分析欲探討變數之當期及落後期 是否會對被解釋變數有顯著影響。
1.2 研究架構
本研究之架構主要分為五個章節,第一章為緒論,說明本文之研究動機與目 的及研究架構;第二章為文獻回顧,說明本研究參考之相關文獻與理論發展的過 程;第三章為理論模型與實證方法,包括本研究所依循相關研究之理論模型與實 證之計量方法;第四章為實證結果分析,說明將資料帶進實證迴歸模型之後所得 到之結果,並以經濟理論分析;第五章為結論,總結本文的研究發現與未來的研 究方向。3
第二章 文獻回顧
2.1 台灣匯率政策之研究
台灣的中央銀行,依據中央銀行法的規定,其經營目標有四點,包括「促進 金融穩定」、「健全銀行業務」、「維持對內及對外幣值之穩定」,以及「於上述目 標範圍之內,協助經濟之發展」等四點。其中,「對內幣值之穩定」指的是使國 內的物價穩定,而「對外幣值之穩定」即是「匯率穩定」,而匯率又是影響出口 與經濟成長的重要因素,因此匯率政策成為央行為了達成這些經營目標的重要政 策工具之一。 為了探討台灣央行是否真的為了達到「維持對內及對外幣值之穩定」此一目 標,而大動作介入匯率市場進而影響匯率,楊雅惠、許嘉棟(2005)分析了央行 的干預行為,將三種分別表示央行三項干預目標之變數引入傳統的新台幣匯率方 程式,並以 1987 年 7 月至 2002 年 9 月的月資料進行實證模型分析。此實證模型 分析研究的結果顯示,表示央行三項干預目標的三種變數對新台幣匯率都有顯著 的影響,亦即當經濟景氣不佳時,央行會藉由干預引導新台幣貶值;而當國內物 價開始通貨膨脹時,央行則干預引導新台幣升值;另外結果也顯示央行的確有藉 由買賣外匯來調整匯率的變動,緩和匯率波動幅度。 吳致寧等人(2012)利用了 Balassa-Samuelson 效果之貨幣學派模型,分析 了台灣 1980 年以來的匯率政策,是否有助於穩定匯率及經濟成長。實證結果指 出台灣在 1980 年至 1987 年是採用阻升新台幣的政策,而後的 1988 年至 1997 年則採用阻貶新台幣的政策,之後 1998 至 2010 由於亞洲金融風暴危機期間,所4 以採取維持匯率均衡穩定之政策。此外,結果也顯示阻升新台幣之政策是有助於 經濟成長的。由於確定台灣中央銀行是會對匯率進行干預的,陳旭昇(2013)檢 視了台灣中央銀行是否在外匯市場執行了不對稱的干預政策,他先以結構性自我 向量迴歸模型,分析了外生的結構性匯率衝擊,然後將其細分為升值和貶值的衝 擊,接著進一步探討央行在外匯市場中是否採用了不對稱的匯率干預政策,資料 時間為 1989 年至 2012 年的月資料。實證結果發現,央行在 1989 年至 1997 年之 前對於外匯市場的干預較不明顯;反之,在 1998 年到 2012 年,央行對於實質匯 率及名目匯率均有顯著的「阻升不阻貶」之行為。 由此我們可以推斷,台灣央行的匯率政策的確可能是保持處於較弱勢的新台 幣,且確實有實證證據顯示這樣是有助於經濟發展的,但是會不會使得所得分配 不均之狀況惡化呢?
2.2 台灣所得分配不均之研究
探討所得分配不均的研究有很多,根據國內外現有文獻之結論,說明了有相 當多的因素會影響所得分配,包括經濟成長、金融市場、勞動市場、貿易開放程 度、家庭結構及產業結構等等。 首先從經濟成長及金融市場的面向來分析,曹添旺(1996)利用吉尼係數和 大島係數的方式,研究 1980 年至 1993 年台灣家庭所得分配不均的原因,該研究 發現相對於低所得之家庭,高所得之家庭有充足的資訊及資本得以在證券市場謀 取利潤,擴大所得不均的程度。Hu(2001)建立了一個兩種投資資產的模型欲 證明證券市場的存在會影響所得分配的狀況,並加進實質人均 GDP 及其平方項 這兩個變數用以驗證 Kuznets 的倒 U 型理論,亦即探討實質人均 GDP 對貧富不5 均的影響,而 Hu 利用 1986 年至 1990 年 52 個國家的數據進行跨國實證研究。 實證結果顯示當資訊不對稱存在時,證券市場的存在會顯著地惡化所得分配不均 的情況,而資訊不對稱會顯著正向影響吉尼係數,亦即所得分配不均差距變更大。 至於實質人均 GDP 及其平方項這兩種變數之係數,前者為正號,後者為負號, 亦即當實質人均 GDP 開始增加時,也就是國家開始發展時,會使得所得不均之 情況惡化,但等到發展至一定水準後,隨著 GDP 的成長,反而會使得所的不均 的情況改善,此一結果也與 Kuznets 的倒 U 型理論相符。
從勞動市場的面向來分析,Bstson and van der Gaag(1984)利用美國 1968 年至 1980 年的資料進行分析,結果發現女性工作所得會使家戶所得分配趨於平 均化。劉鶯釧(1992)以 1988 年台灣地區婦女之生活狀況調查,探討夫妻均有 工作的家庭中妻子的勞動所得對所得分配之影響,研究結果顯示妻子的勞動所得 越高會使所得分配趨於平均化。Daly and Valletta(2006)研究美國 1969 年至 1989 年家戶所得不均度上升的原因,而結果指出婦女之勞動參與率提高會使得家戶所 得不均之情況改善。
而從貿易開放程度的面向來分析,Stolper and Samuelson(1941)用理論指 出自由貿易會使一國較豐富之生產要素的實質報酬上升,因而有利於該要素所得 者;反之,該國教稀少之生產要素的實質報酬會下降,所以導致所得分配不均之 情況惡化。而發現相同結論的有 Robbins(1994),Meller and Tokman(1996)與 Beyer et al.(1999),他們實證結果均發現貿易開放會導致需要專業技術與非技術 勞工之間的薪資差距擴大,進而使得貧富差距更擴大。莊希豐、陳亞為(2011) 利用門檻回歸法分析了 1960 年至 2005 年 62 個國家的資料作橫斷面分析,估計 貿易自由化對高、低所得國家之所得分配的影響,而實證結果指出貿易自由化在
6 低所得國家會惡化所得分配之情況;而貿易自由化在高所得國家則無顯著影響國 內的所得分配情況。 從家庭結構的面向來分析,吳慧瑛(1998)利用分解後的吉尼係數與迴歸模 型的方法研究台灣家戶人口變動對於所得分配的影響,其採用 1976 至 1995 年家 庭收支調查之資料,而結果顯示家戶人口規模分配的不均會對家戶總所得分配不 均有顯著正向影響,亦即使得所得分配不均之狀況惡化。莊文寬(2006)也採用 台灣家庭收支調查之資料,分析台灣歷年來經濟發展在改變社會型態後,影響家 庭結構與所得差距的效果,而其結果顯示家庭人口減少、高齡化及教育程度低是 使得低所得家庭所得收入更減少的主因,進而造成貧富差距更大。 從產業結構的面向來分析,Levernier et al.(1998)採用美國 1990 年的調查 資料觀察約 3000 個城市家戶所得不均度的情況,而其結果顯示大城市相對於小 城市,其家戶所得不均度顯著較大,亦即大城市之所得分配情況較不平均,除此 之外,其研究中也發現了產業結構性的變動是造成所得不均度提高的重要原因之 一。Clarke et al.(2003)利用 1960 年至 1995 年日本追蹤資料,觀察各產業部門 的發展與所得分配不均之關係,而其實證估計結果顯示經濟體系各產業的發展的 確會顯著影響所得分配不均,原因為某些產業中高階層員工與基層員工之薪水差 異甚大,導致所得分配不均的狀況惡化。徐美等人(2015)採用台灣行政院主計 處人力運用與家庭收支調查資料,分析台灣家戶所得不均度之各種原因,研究發 現產業結構性的變動對於所得分配不均有顯著的影響效果,此外,女性相對男性 之就業比例提高也使得對所得不均有顯著的影響,而人口高齡化以及失業率的增 加也會造成所得分配不均之情況惡化。
7
第三章 理論模型與實證方法
3.1 理論模型
本文關於所得不均的理論模型主要引用自徐美、莊奕琦、陳晏羚(2015)的 模型,將其加進匯率之變數,所得不均的實證模型設定如下: 𝑖𝑛𝑒𝑞𝑢𝑎𝑙𝑖𝑡𝑦𝑡= 𝑓(𝑒𝑥𝑡 , 𝐸𝑐𝑜𝑛𝐷𝑒𝑣𝑒𝑙𝑜𝑝𝑡 , 𝑖𝑛𝑑𝑢𝑠𝑡𝑟𝑦𝑡 , 𝑙𝑎𝑏𝑜𝑟𝑚𝑎𝑟𝑘𝑒𝑡𝑡 ) + 𝜀𝑡 (1) 其中,t 代表時間,被解釋變數 𝑖𝑛𝑒𝑞𝑢𝑎𝑙𝑖𝑡𝑦𝑡 為所得不均度,本文採用兩個指標 來估計所得分配不均之程度,分別為「台灣家庭所得吉尼係數(GINI)」以及「五 等分位所得差距倍數(FIVE)」,使用此兩項變數分別做為衡量所得不均程度之 指標;𝑒𝑥𝑡 為匯率變數,為要探討之主要解釋變數,此處使用之資料為「實質有 效匯率(REER)」,並且預測其落後期也會有顯著影響;𝐸𝑐𝑜𝑛𝐷𝑒𝑣𝑒𝑙𝑜𝑝𝑡 為總體經 濟發展變數,包括「每人平均國內生產毛額(GDP)」及「失業率(UER)」此兩 項變數來做為指標;𝑙𝑎𝑏𝑜𝑟𝑚𝑎𝑟𝑘𝑒𝑡𝑡 為勞動市場變數,此為「女性就業之比例 (FEMALE)」。𝑖𝑛𝑑𝑢𝑠𝑡𝑟𝑦𝑡 為產業變數,是用來描述國內近年來產業結構之轉型 情況,包含「工業(INDUSTRY)及服務業(SERVICE)分別的生產毛額占 GDP 的比重」。 將上述寫成迴歸模型,其模型有兩個,分別為: 𝐺𝐼𝑁𝐼𝑡 = 𝛼0+ 𝛼1𝑙𝑛𝑅𝐸𝐸𝑅𝑡+ 𝛼2𝑙𝑛𝐺𝐷𝑃𝑡+ 𝛼3𝑈𝐸𝑅𝑡+ 𝛼4𝐹𝐸𝑀𝐴𝐿𝐸𝑡 + 𝛼5𝐼𝑁𝐷𝑈𝑆𝑇𝑅𝑌𝑡+ 𝛼6𝑆𝐸𝑅𝑉𝐼𝐶𝐸𝑡+ 𝜀𝑡 (2)8 𝐹𝐼𝑉𝐸𝑡 = 𝛽0+ 𝛽1𝑙𝑛𝑅𝐸𝐸𝑅𝑡+ 𝛽2𝑙𝑛𝐺𝐷𝑃𝑡+ 𝛽3𝑈𝐸𝑅𝑡+ 𝛽4𝐹𝐸𝑀𝐴𝐿𝐸𝑡 + 𝛽5𝐼𝑁𝐷𝑈𝑆𝑇𝑅𝑌𝑡+ 𝛽6𝑆𝐸𝑅𝑉𝐼𝐶𝐸𝑡+ 𝜀𝑡 (3) 由於本文的目的主要是探討台灣的實質匯率對於所得不均情況的影響,所以 建構以上兩個實證迴歸模型,其中式(2)的被解釋變數為吉尼係數,而式(3) 的被解釋變數為五等分位所得差距倍數,此兩個指標在這裡均為用來衡量所得分 配不均之程度。
3.2 單根檢定(Unit root test)
單根(unit root)的概念,首先是由 Fuller (1976)及 Dickey and Fuller (1979) 所提出的。假設給定 AR(p)模型: 𝛽(𝐿)y𝑡= 𝛽0 + 𝜀𝑡 (4) 如果多項方程式 𝛽(𝑧) = 1 - 𝛽1𝑧 - 𝛽2𝑧2- … - 𝛽𝑝𝑧𝑝 = 0 (5) 有一個根為 1,則此 AR(p)即為一具有單根之序列。 如果一時間序列具有單根,則其時間序列具有隨機趨勢(stochastic trend), 隨機趨勢是指時間序列資料持續且長期性的隨機移動,以總體經濟學的觀點來說, 這種情況就是經濟體系中的外生衝擊(exogenous shocks),外生衝擊通常是指政
9
策或者環境的變化,因此隨機的外生衝擊對於總體經濟的影響為持續且恆久。
Nelson and Plosser (1982)發現了大多數的總體經濟時間序列資料均具有 隨機趨勢,若未消除時間序列資料的隨機趨勢,那麼在分析上將有可能產生三種 問題,分別為自我迴歸係數有小樣本的向下偏誤、t-統計量的極限分配不為標準 常態分配以及會產生虛假迴歸等之情況。以下介紹三種不同的單根檢定。
3.2.1 Augmented Dickey-Fuller 單根檢定
Augmented Dickey-Fuller 單根檢定(ADF unit root test)為時間序列中最常使 用之單根檢定,而此檢定係由 Dickey-Fuller 單根檢定擴充而來的,於迴歸式右 側加入被解釋變數之落後項,使其殘差方能符合白噪音(white noise)之假設, 其檢定原理為利用最小平方法(OLS)對三種迴歸方程式進行估計,而後再對參 數做假設檢定, ADF 檢定之三種迴歸方程式如下: (1) 含截距項與時間趨勢項: ∆𝑦𝑡 = 𝑎0 + 𝛾𝑦𝑡−1+ 𝑎2𝑡 + ∑ 𝛽𝑖∆𝑦𝑡−𝑖+1+ 𝜀𝑡 𝑝 𝑖=2 (6) (2) 只含截距項: ∆𝑦𝑡 = 𝑎0+ 𝛾𝑦𝑡−1+ ∑ 𝛽𝑖∆𝑦𝑡−𝑖+1+ 𝜀𝑡 𝑝 𝑖=2 (7) (3) 不含截距項與時間趨勢項:
∆yt = γyt−1+ ∑ βi∆yt−i+1+ εt p
i=2
10 其中,𝑎0 為截距項,t 為時間趨勢項,𝜀𝑡~𝑖𝑖𝑑(0, 𝜎2),上述三種型式之 ADF 檢定 的不同之處在於其是否含有截距項𝛼0 或時間趨勢項t 。而其所檢定之虛無假設為 𝐻0:𝛾 = 0 ,若拒絕虛無假設,則表示該時間序列資料沒有單根,意即其資料為 定態;反之,若不能拒絕虛無假設,則表示序列有單根,意即其資料為非定態, 故需要將時間序列資料以差分處理,直到呈現定態。
3.2.2 Phillips-Perron 單根檢定
Phillips-Perron 單根檢定(PP unit root test)是由 Phillips 和 Perron 於 1988 年 所提出的另一種單根檢定,此檢定法同時考量了殘差項存在異質變異及序列自我 相關的情況。PP 檢定是使用了 AR(1)的模型,與 ADF 檢定所使用之 AR(P) 的模型不同,而 PP 檢定之迴歸方程式也有三種,之後對其參數做假設檢定, PP 檢定之三種迴歸方程式如下: (1) 含截距項與時間趨勢項: 𝑦𝑡 = 𝛼 + 𝜌𝑦𝑡−1+ 𝜃 (𝑡 − 1 2𝑇) + 𝑢𝑡 (9) (2) 只含截距項: 𝑦𝑡= 𝛼 + 𝜌𝑦𝑡−1+ 𝑢𝑡 (10) (3) 不含截距項與時間趨勢項: 𝑦𝑡 = 𝜌𝑦𝑡−1+ 𝑢𝑡 (11)
11 其中,α 為截距項,t 為時間趨勢項,T 為樣本的觀察數,𝑢𝑡 的期望值為 0,但 𝑢𝑡 不一定要符合無序列自我相關或者同質性等條件,PP 檢定可以允許殘差項可 以有弱相依性或者異質變異。而其所檢定之虛無假設為 𝐻0:𝜌 = 1 ,若拒絕虛無 假設,則表示該時間序列資料沒有單根,意即其資料為定態;反之,若不能拒絕 虛無假設,則表示序列有單根,意即其資料為非定態,故需要將時間序列資料以 差分處理,直到呈現定態。
3.2.3 Kwiatkowski-Phillips-Schmidt-Shin 單根檢定
除了上述所提到的 ADF 及 PP 單根檢定之外,還有一種常用的檢定方法就 是 Kwiatkowski-Phillips-Schmidt-Shin 單根檢定(KPSS unit root test),此檢定與 前兩者最大不同之處在於其虛無假設,KPSS 檢定之虛無假設為「變數為定態」。KPSS 單根檢定是由定性趨勢、random walk 以及一個定態的白噪音(white noise)所組成,即: 𝑦𝑡 = 𝜉𝑡 + 𝜇𝑡+ 𝜀𝑡 (12) 其中,𝜇𝑡 = 𝜇𝑡−1+ 𝑢𝑡 ,𝑢𝑡 ~ 𝑖𝑖𝑑(0, 𝜎𝑢2),𝜀 𝑡~𝑖𝑖𝑑(0, 𝜎𝜀2)。令 𝜇0 為一常數,則在 𝜎𝑢2 = 0,即 𝑢𝑡 為一常數時,上式即可表示為: 𝑦𝑡= 𝜉𝑡 + ( 𝜇0+ 𝑢0 ) + 𝜀𝑡 (13) 換言之,此時 𝑦𝑡 為一定性趨勢變數,將此變數去掉趨勢之後,即可轉為定態變 數。所以在此條件下可以導出一個 LM 統計量,即:
12 LM = ∑𝑆𝑡 2 𝜎𝜀2 𝑇 𝑡=1 (14) 其中 𝑆𝑡 是指殘差的累積總和,而 𝜎𝜀2 為殘差變異數的估計值。而其所檢定之虛無 假設為 𝐻0:𝜎𝑢2 = 0 (變數為定態),若拒絕虛無假設,則表示該時間序列資料為 非定態,意即其資料有單根;反之,若不能拒絕虛無假設,則表示序列為定態, 意即其資料為沒有單根。
3.3 共整合檢定
根據 Engle and Granger (1987),共整合(cointegration)的意思是指多個 非定態的變數之間,若是可以找到一組或多組共整合向量,能夠使得這些變數在 經過線性組合後變為定態變數,即可稱這些變數具有共整合關係。共整合關係之 定義:如果已知 𝑦𝑡、 𝑥𝑡 兩變數都是 k 階整合之非定態變數,k > 0,如果其線性 組合之關係為 I(0),則我們可以將 𝑦𝑡、 𝑥𝑡 兩變數稱之為 k 階 k 次共整合 (cointegration of order k, k),符號則記為 CI(k, k)。
共整合分析主要有兩種方法,第一種方法是由 Engle and Granger 所提出, 他們假設變數之間最多只有一組共整合關係,接著採取兩階段的程序,以第一階 段經過最小平方法的殘差項在第二階段進行共整合關係的檢定。第二種方法是由 Johansen 所提出,此方法允許多組共整合關係存在,並以最大概似法進行檢定與 估計,以下將說明此兩種方法。
13
3.3.1 Engle-Granger 共整合檢定
Engle and Granger (1987) 提出一個簡單的檢驗流程來檢定兩變數的共整 合關係,首先應該先確定這兩個變數的整合階次是否相同,因為在共整合的定義 中,其中一個條件即為變數需要有相同的整合階次才能進行共整合檢定,因此可 先利用 ADF 單根檢定或 PP 單根檢定來檢測是否具有單根,並檢查這些變數是 否為相同的整合階次,若變數之整合階次相同,即可進行下一步驟;若變數之整 合階次不同,則推論其變數之間不具有共整合關係。 第一階段:若是確定 𝑦𝑡、 𝑥𝑡 為相同階次的序列資料之後,即可利用最小平 方法(OLS)來進行估計,並將估計所得到的殘差項保留起來進行下一步驟。其 OLS 估計式可如下表示: 𝑦𝑡 = 𝛽0+ 𝛽1𝑥1+ 𝑒𝑡 (15) 第二階段:將所得到之殘差項 𝑒𝑡 進行單根檢定,以此來檢驗 𝑒𝑡 是否成為定 態變數,若得到的殘差項之序列為定態的序列 I(0),則表示此兩序列 𝑦𝑡 和 𝑥𝑡 具 有共整合關係;反之,若是得到的殘差項之序列為非定態的序列,也就是說其存 在單根時,則表示此兩序列 𝑦𝑡 和 𝑥𝑡 不具有共整合關係。 Engle-Granger 的兩階段共整合檢定法較簡單易懂,其為透過利用 OLS 估計 之後所得到的殘差項來進行單根檢定,若拒絕其有單根之虛無假設則表示殘差項 為定態序列,則可以得到 𝑦𝑡 和 𝑥𝑡 兩序列具有共整合關係之結論;反之,若無法 拒絕虛無假設時則表示殘差項具有單根,意即其殘差項為非定態之序列,表示 𝑦𝑡 和 𝑥𝑡 兩序列不具有共整合關係。
14
3.3.2 Johansen 共整合檢定
Johansen 共整合檢定法與 Engle-Granger 的兩階段共整合檢定法最大之不同 在於其允許多個變數之間可以有多組的共整合向量存在,而且所估計出來的檢定 統計量有良好的分配,也有考慮到資料監所存在的時間序列特性,同時也可以根 據不同的線性模型來做檢定,而 Johansen 使用了向量自我迴歸模型(Vector Autoregression, VAR)來做分析。 假設一落後 p 期的自我迴歸模型如下: 𝑦𝑡 = Φ1𝑦𝑡−1+ Φ2𝑦𝑡−2+ ⋯ + Φ𝑝𝑦𝑡−𝑝+ 𝜀𝑡 (16) 令 𝐷𝑖 = − ∑ Φ𝑠 𝑝 𝑠=𝑖+1 (17) 且 Π = −Φ(1) = −( 𝐼 − Φ1− Φ2− ⋯ − Φ𝑝) (18) 則 VAR(p)可以改寫成 VECM ∆𝑦𝑡 = Π𝑦𝑡−1+ ∑ 𝐷𝑖∆𝑦𝑡−𝑖+ 𝜀𝑡 𝑝−1 𝑖=1 (19)15 給定 𝑦𝑡 的階次最高為一階,此時有三種情形: (1) 如果 𝑟𝑎𝑛𝑘(Π) = 0 ,則表示沒有任何 𝑦𝑡 的線性組合為 I(0),亦即表示不 存在共整合關係。 (2) 如果 𝑟𝑎𝑛𝑘(Π) = 𝑘 ,意指 𝑦𝑡 的所有線性組合均為 I(0),亦即 𝑦𝑡 為一定態 之變數。 (3) 如果 𝑟𝑎𝑛𝑘(Π) = 𝑟 ,且 0 < r < k 則表示 𝑦𝑡 具有 k 組共整合關係。 因此,我們可以用 Π 矩陣來檢驗是否存在著共整合關係,這樣的檢驗方法一般 即稱為 Johansen 檢定(Johansen test)。
Johansen 共整合檢定使用最大概似估計法( Maximum Likelihood Estimator, MLE )來估計 VECM 之參數,利用這樣的方式可以使用下列兩種檢定統計量來 進行 Johansen 共整合檢定,兩種檢定如下: (1) 軌跡檢定(Trace test): 𝜆𝑡𝑟𝑎𝑐𝑒(𝑟) = −𝑇 ∑ 𝑙𝑛(1 − 𝜆̂𝑖) 𝑘 𝑖=𝑟+1 (20) 其中 𝜆̂𝑖 表示經過最大概似估計法對 Π 矩陣所推算出來的矩陣中之特性根估計值, T 為序列資料之觀察樣本數,其虛無假設與對立假設分別為: 𝐻0:𝑟𝑎𝑛𝑘(𝛱) = 𝑟 𝐻1:𝑟𝑎𝑛𝑘(𝛱) > 𝑟 若無法拒絕虛無假設,則表示有 𝑟 組的共整合關係存在;反之,如果拒絕虛無假 設,則表示有超過 𝑟 組的共整合關係存在。
16
(2) 最大特性根檢定(Maximum Eigenvalue test) :
𝜆𝑚𝑎𝑥(𝑟, 𝑟 + 1) = −𝑇𝑙𝑛(1 − 𝜆̂𝑟+1) (21) 其中 𝜆̂𝑖 表示經過最大概似估計法對 Π 矩陣所推算出來的矩陣中之特性根估計值, T 為序列資料之觀察樣本數,其虛無假設與對立假設分別為: 𝐻0:𝑟𝑎𝑛𝑘(𝛱) = 𝑟 𝐻1:𝑟𝑎𝑛𝑘(𝛱) = 𝑟 + 1 若無法拒絕虛無假設,則表示有 𝑟 組的共整合關係存在;反之,如果拒絕虛無假 設,則表示有 𝑟 + 1 組的共整合關係存在。
3.4 殘差診斷性分析
在簡單線性迴歸模型的基本假設中有六個假設,而其中跟殘差項有關的假設 有四個,分別為「殘差的期望值為 0」、「殘差的變異數為 𝜎2」、「任意兩殘差 𝑒 𝑖 和 𝑒𝑗 的共變異數為 0」、「殘差為常態分配,亦即 𝑒 ~ 𝑁( 0 , 𝜎2 )」。總結以上條件, 可以得到殘差必須符合「無自我相關」、「同質變異」、「常態分配」三個條件,否 則估計的參數可能不具有「有效性」,所以必須以各種檢定方法來檢驗之。3.4.1 序列相關檢定
序列相關檢定的目的就是為了檢測所估計模型之殘差是否仍然存在「自我相 關」,若其存在自我相關則可能會造成估計結果不具有「有效性」。為了避免此種17 情況,常用來檢測是否存在序列相關的檢定就是 Q 檢定(Q-test),以下說明 Q 統計量的設定:首先假設跑迴歸模型所得到的殘差項數列為 𝜀̂𝑡 ,樣本觀察數為 T 個,則先算出殘差的第 𝑖 階自我相關係數 ρ(𝑖) 如下: ρ(𝑖) = ∑ ε̂tε̂t−i T t=i+1 ∑T ε̂t2 t=1 (22) 接著代入 Q 統計量的計算式: 𝑄(𝑝) = T ∑ 𝜌(𝑖)2 𝑝 𝑖=1 (23) 其中p = 1,2,3,…,也就可以計算出 Q(1),Q(2),Q(3),…,這些 Q(p)統 計量背後的虛無假設為: 𝐻0:此變數從 1 到 p 階都沒有自我相關 若不拒絕虛無假設,則表示此變數沒有自我相關;反之,若拒絕虛無假設,則表 示此變數有自我相關,雖然估計出來之迴歸模型結果仍然有「不偏性」,但可能 不具有「有效性」。
3.4.2 條件異質變異檢定
條件異質變異檢定的目的就是為了檢測所估計模型之殘差是否有符合「同質 變異」,若其為「異質變異」則可能會造成估計結果不具有「有效性」,必須進一 步使用加權最小平方法(weight least squares, WLS)來校正殘差中的異質變異,18 並加以估計。為了避免此種情況,常用來檢測是否存在條件異質變異的檢定就是 ARCH-LM 檢定,以下說明 ARCH-LM 檢定的設定: 𝜀𝑡 = 𝑦𝑡− 𝑥𝑡𝑎 (24) 𝜀𝑡 = 𝑣𝑡𝜎𝑡2 (25) 其中,𝑣𝑡 ~ 𝑁(0,1)。若 ARCH(q)存在時,這個模型的變異數方程式可表示為: 𝜎𝑡2 = 𝛼 0+ 𝛼1𝜀𝑡−12 + 𝛼2𝜀𝑡−22 + ⋯ + 𝛼𝑞𝜀𝑡−𝑞2 (26) 若無 ARCH(q)存在時,則變異數為一常數,不會變動,其實隱含 𝜎𝑡2 = 𝛼0 (27) 因此,若想要檢定條件異質變異是否存在著 ARCH 效果,虛無假設為: 𝐻0:𝛼1 = 𝛼2 = ⋯ = 𝛼𝑞 = 0 若不拒絕虛無假設,則表示此變數沒有條件異質變異,亦即其為同質變異;反之, 若拒絕虛無假設,則表示此變數為條件異質變異,可能會造成估計出來之迴歸模 型結果不具有「有效性」。
19
3.4.3 常態分配檢定
常態分配檢定目的就是為了檢測所估計模型之殘差是否為「常態分配」,若 其不為常態分配則可能會造成估計結果不具有「有效性」。為了避免此種情況, 常用來檢測是否為常態分配的檢定就是 Jarque-Bera 檢定(JB-test),以下說明 JB 統計量的設定:欲計算 JB 統計量,需要先計算出迴歸之殘差的偏態係數(skewness, S)及峰態係數(kurtosis, K),假設迴歸模型中待估計的參數個數為 n,殘差的 樣本總數為 T 個,則 JB 統計量可表示為: JB = 𝑇 − 𝑛 6 [𝑆 2+1 4(𝐾 − 3) 2] (28) JB 統計量的分配是屬於自由度為 2 的卡方分配,而其虛無假設為: 𝐻0 :被檢定之變數為常態分配 若不拒絕虛無假設,則表示此變數為常態分配;反之,若拒絕虛無假設,則表示 此變數之分配不為常態分配,可能會造成估計出來之迴歸模型結果不具有「有效 性」。20
第四章 實證結果分析
4.1 資料說明
本文主要探討台灣地區實質匯率是否影響了所得不均之情況,而本文採用行 政院主計處總體資料庫及國際清算銀行資料庫之資料,從其中取得「吉尼係數、 五等分位所得差距倍數、實質有效匯率指數、每人平均國內生產毛額、失業率、 女性工作者占總工作者之比例、工業生產毛額占 GDP 之比例及服務業生產毛額 占 GDP 之比例」以上各種變數之數據,其數據之說明如下: 1. 吉尼係數(GINI):資料來源為台灣行政院主計處。吉尼係數為一比例 數值,其值介於 0 和 1 之間,通常用以表示所得分配之公平程度的指標。 意即當吉尼係數越小,所得分配越平均(若吉尼係數為 0,則表示絕對 平均,每戶的所得都相同);若吉尼係數越大,則所得分配越不平均(若 吉尼係數為 1,則表示絕對不平均,所得只集中在一戶)。本文之迴歸模 型選用吉尼係數做為兩種被解釋變數之一,用來衡量所得分配不均的程 度。 2. 五等分位所得差距倍數(FIVE):資料來源為台灣行政院主計處。五等 分位所得差距倍數是將家庭所得由小到大排序,並將全部家庭分成五個 等分,將最高所得組與最低所得組相除所得到之倍數。所得差距倍數由 1(完全平均)至無窮大(最不平均,所得全部集中在一戶),其值越大 則表示所得分配越不平均。本文之迴歸模型選用五等分位所得差距倍數 做為兩種被解釋變數之一,用來衡量所得分配不均的程度。21 3. 實質有效匯率指數(REER):資料來源為國際清算銀行(BIS)。實質有 效匯率指數是用來衡量新台幣相對於主要貿易對手國一籃貨幣經考量物 價相對變動後之加權平均匯率,BIS 編製的實質有效匯率指數是以 2010 年為基期,當年的值為 100。實質有效匯率指數上升代表本國貨幣相對 價值的上升,下降則表示本國貨幣貶值。實質有效匯率指數為本文迴歸 模型之主要解釋變數,若迴歸分析結果出來其係數為負,意即當實質有 效匯率指數上升時,也就是本國貨幣相對升值時,所得分配不均之情況 會減少;反之,若迴歸分析結果出來其係數為正,意即當實質有效匯率 指數上升時,也就是本國貨幣相對升值時,所得分配不均之情況會惡化。 4. 每人平均國內生產毛額(GDP):資料來源為台灣行政院主計處。國內生 產毛額是對一國經濟在一段期間內所有單位生產的最終產品總量的價值, 通常做為國家經濟狀況的一個重要指標。每人平均國內生產毛額為本文 迴歸模型之控制變數,根據現有文獻資料顯示,其係數正或負都有可能。 由於根據 Kuznets curve 假說,國內生產毛額對所得分配不均之情況呈現 倒 U 曲線,其表明:在經濟發展過程開始的時候,尤其是在國內人均生 產毛額從最低上升到中等水平時,所得分配狀況先趨於惡化,接著隨著 經濟發展會漸漸改善,最後達到比較公平的所得分配狀況。 5. 失業率(UER):資料來源為台灣行政院主計處。失業率是指失業人口占 勞動人口的比率,通常被視為落後指標。失業率為本文迴歸模型之控制 變數,根據現有文獻資料顯示,其係數應為正,也就是說當失業率越高, 被解釋變數也會越高,意即台灣國民所得分配不均之狀況會惡化。
22 6. 女性就業人數占總就業人數之比例(FEMALE):資料來源為台灣行政院 主計處。顧名思義為女性就業人數除以總就業人數之值。女性就業人數 占總就業人數之比例為本文迴歸模型之控制變數,根據現有文獻資料顯 示,其係數應為負,也就是說當女性就業人數占總就業人數之比例越高, 被解釋變數會越低,則台灣國民所得分配不均之狀況會改善。 7. 工業生產毛額占 GDP 之比例(INDUSTRY):資料來源為台灣行政院主 計處。顧名思義為工業生產毛額除上當年 GDP 之值。工業生產毛額占當 年 GDP 之比例為本文迴歸模型之控制變數,根據現有文獻資料顯示,其 係數應為正,也就是說當此比例越高,被解釋變數會越高,則台灣國民 所得分配不均之狀況會惡化。 8. 服務業生產毛額占 GDP 之比例(SERVICE):資料來源為台灣行政院主 計處。顧名思義為服務業生產毛額除上當年 GDP 之值。服務業生產毛額 占當年 GDP 之比例為本文迴歸模型之控制變數,根據現有文獻資料顯示, 其係數應為正,也就是說當此比例越高,被解釋變數會越高,則台灣國 民所得分配不均之狀況會惡化。 本文為了探討台灣地區實質匯率是否影響了所得不均之情況,採用上述八種 變數之數據。由於台灣的吉尼係數及五等分位所得差距倍數之資料僅從 1981 年 才開始記錄,且只有年資料,雖然實質有效匯率為月資料;失業率、女性工作比 例等等變數為季資料,但礙於資料限制只能選擇年資料。基於以上原因,最後選 擇之資料時間為 1981 年到 2015 年的年資料,共計 35 年。 以下圖一至圖八為各變數由 1981 年至 2015 年之資料趨勢圖:
23 圖一 吉尼係數 圖二 五等分位所得差距倍數 0.2 0.22 0.24 0.26 0.28 0.3 0.32 0.34 0.36 1981 1986 1991 1996 2001 2006 2011 3 3.5 4 4.5 5 5.5 6 6.5 7 1981 1986 1991 1996 2001 2006 2011
24 圖三 實質有效匯率指數 圖四 每人平均國內生產毛額 (單位:新台幣) 80 90 100 110 120 130 140 150 1981 1986 1991 1996 2001 2006 2011 0 100000 200000 300000 400000 500000 600000 700000 800000 1981 1986 1991 1996 2001 2006 2011
25 圖五 失業率 圖六 女性就業人數占總就業人數之比例 0 1 2 3 4 5 6 7 1981 1986 1991 1996 2001 2006 2011 0.3 0.32 0.34 0.36 0.38 0.4 0.42 0.44 0.46 1981 1986 1991 1996 2001 2006 2011
26 圖七 工業生產毛額占 GDP 之比例 圖八 服務業生產毛額占 GDP 之比例 0.2 0.25 0.3 0.35 0.4 0.45 0.5 1981 1986 1991 1996 2001 2006 2011 0.3 0.35 0.4 0.45 0.5 0.55 0.6 0.65 0.7 0.75 0.8 1981 1986 1991 1996 2001 2006 2011
27 以下表 4-1 為所有變數資料之敘述統計表: 表 4-1:所有變數資料之敘述性統計表 平均數 標準差 最大值 最小值 吉尼係數 0.3206 0.0202 0.35 0.28 五等分位所得差距倍數 5.4535 0.6594 6.39 4.21 實質有效匯率指數 121.96 15.06 146.54 98.69 每人平均國內生產毛額 383697 188659 703697 100113 失業率 3.1165 1.2837 5.85 1.36 女性就業人數比例 0.3981 0.0311 0.4481 0.3333 工業占 GDP 之比例 0.3616 0.0511 0.4606 0.2974 服務業占 GDP 之比例 0.6048 0.0702 0.7447 0.4842 註 1:實質有效匯率指數是以 2010 年為基期,其值為 100,其餘年份則為比照基期經過計算 得出來的值。 註 2:每人平均國內生產毛額之單位為新台幣。 註 3:失業率之單位為% 表 4-1 為所有變數資料之敘述統計表,由此表之結果可以得知各個變數的平 均數、標準差以及最大值和最小值,配合圖一至圖八,可大致初步判斷各個變數 資料之走勢。其中,值得注意的是,每人平均國內生產毛額(GDP)變動之幅度 稍大,從 1981 年人均 GDP 為 100113 元(單位:新台幣),而到 2015 年時已增 長為 703697 元,這也正好是最小值與最大值,這也表示人均 GDP 是逐年增長的。
28
4.2 單根檢定結果
於實證迴歸模型進行前需先對所有變數做單根檢定,進行單根檢定是為了查 看這些時間序列資料狀態是否為穩定,若不穩定則需要進一步處理。假設時間序 列資料之分析中有一個根為 1,則我們稱此為一具有單根之序列。若時間序列資 料具有單根,則該變數即不符合定態之定義,此時估計出來之結果將不具有「有 效性」,為了避免此種狀況,因此進行單根檢定即可用來判斷時間序列資料是否 為定態。 本研究使用三種單根檢定的方法來檢驗這些時間序列變數資料是否具有單 根,分別為 ADF 單根檢定(Augmented Dickey-Fuller test)、PP 單根檢定(Phillips-Perron test)及 KPSS 單根檢定(Kwiatkowski-Phillips-Schmidt-Shin test), 其中的 ADF 和 PP 單根檢定的虛無假設皆為「資料具有單根」。若檢定結果拒絕 虛無假設,則表示沒有單根,亦即其資料為定態;反之,若檢定結果無法拒絕虛 無假設,則表示有單根,亦即其資料為非定態。而 KPSS 單根檢定跟上述兩種檢 定最大的不同之處在於其虛無假設,KPSS 單根檢定的虛無假設為「資料為定態」, 若檢定結果拒絕虛無假設,則表示該資料為非定態;反之,若檢定結果無法拒絕 虛無假設,則表示其資料為定態。 所有變數之單根檢定結果如下表 4-2 至表 4-9:
29
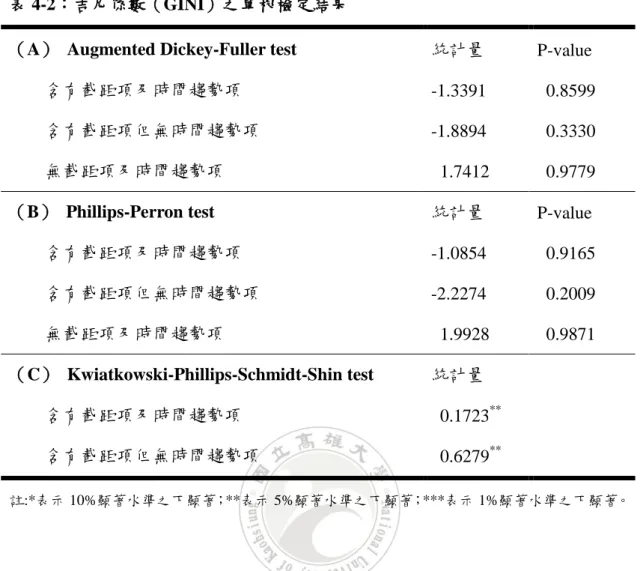
表 4-2:吉尼係數(GINI)之單根檢定結果
(A) Augmented Dickey-Fuller test 統計量 P-value 含有截距項及時間趨勢項 -1.3391 0.8599 含有截距項但無時間趨勢項 -1.8894 0.3330 無截距項及時間趨勢項 1.7412 0.9779 (B) Phillips-Perron test 統計量 P-value 含有截距項及時間趨勢項 -1.0854 0.9165 含有截距項但無時間趨勢項 -2.2274 0.2009 無截距項及時間趨勢項 1.9928 0.9871 (C) Kwiatkowski-Phillips-Schmidt-Shin test 統計量 含有截距項及時間趨勢項 0.1723** 含有截距項但無時間趨勢項 0.6279** 註:*表示 10%顯著水準之下顯著;**表示 5%顯著水準之下顯著;***表示 1%顯著水準之下顯著。 表 4-2 為吉尼係數之單根檢定結果,由表中可得知在 10%顯著水準之下, ADF 檢定之三種模型及 PP 檢定之三種模型中,結果均顯示不拒絕資料有單根之 虛無假設,意即資料為有單根,也就是說資料為非定態;而 KPSS 檢定之兩種模 型中,結果均顯示拒絕資料為定態之虛無假設,意即資料為非定態。
30
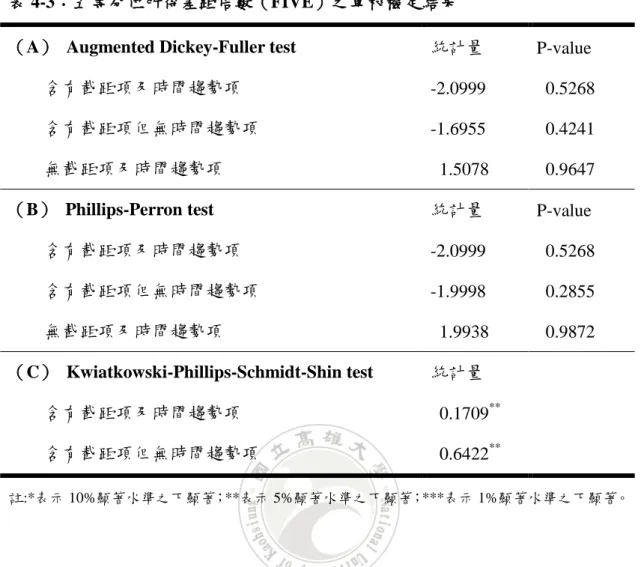
表 4-3:五等分位所得差距倍數(FIVE)之單根檢定結果
(A) Augmented Dickey-Fuller test 統計量 P-value 含有截距項及時間趨勢項 -2.0999 0.5268 含有截距項但無時間趨勢項 -1.6955 0.4241 無截距項及時間趨勢項 1.5078 0.9647 (B) Phillips-Perron test 統計量 P-value 含有截距項及時間趨勢項 -2.0999 0.5268 含有截距項但無時間趨勢項 -1.9998 0.2855 無截距項及時間趨勢項 1.9938 0.9872 (C) Kwiatkowski-Phillips-Schmidt-Shin test 統計量 含有截距項及時間趨勢項 0.1709** 含有截距項但無時間趨勢項 0.6422** 註:*表示 10%顯著水準之下顯著;**表示 5%顯著水準之下顯著;***表示 1%顯著水準之下顯著。 表 4-3 為五等分位所得差距倍數之單根檢定結果,由表中可得知在 10%顯著 水準之下,ADF 檢定之三種模型及 PP 檢定之三種模型中,結果均顯示不拒絕資 料有單根之虛無假設,意即資料為有單根,也就是說資料為非定態;而 KPSS 檢 定之兩種模型中,結果均顯示拒絕資料為定態之虛無假設,意即資料為非定態。
31
表 4-4:實質有效匯率指數(LNREER)之單根檢定結果
(A) Augmented Dickey-Fuller test 統計量 P-value 含有截距項及時間趨勢項 -2.1189 0.5168 含有截距項但無時間趨勢項 -1.1489 0.6842 無截距項及時間趨勢項 -1.0636 0.2538 (B) Phillips-Perron test 統計量 P-value 含有截距項及時間趨勢項 -2.1701 0.4897 含有截距項但無時間趨勢項 -1.0555 0.7212 無截距項及時間趨勢項 -1.3761 0.1536 (C) Kwiatkowski-Phillips-Schmidt-Shin test 統計量 含有截距項及時間趨勢項 0.1264* 含有截距項但無時間趨勢項 0.5735** 註:*表示 10%顯著水準之下顯著;**表示 5%顯著水準之下顯著;***表示 1%顯著水準之下顯著。 表 4-4 為實質有效匯率指數之單根檢定結果,由表中可得知在 10%顯著水準 之下,ADF 檢定之三種模型及 PP 檢定之三種模型中,結果均顯示不拒絕資料有 單根之虛無假設,意即資料為有單根,也就是說資料為非定態;而 KPSS 檢定之 兩種模型中,結果均顯示拒絕資料為定態之虛無假設,意即資料為非定態。
32
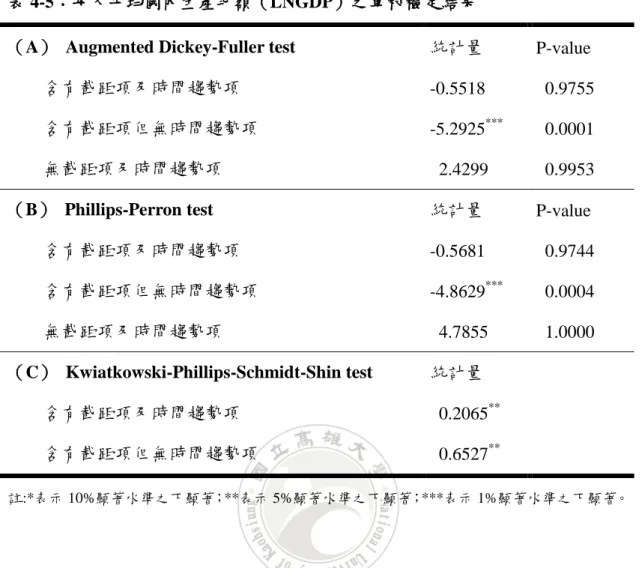
表 4-5:每人平均國內生產毛額(LNGDP)之單根檢定結果
(A) Augmented Dickey-Fuller test 統計量 P-value 含有截距項及時間趨勢項 -0.5518 0.9755 含有截距項但無時間趨勢項 -5.2925*** 0.0001 無截距項及時間趨勢項 2.4299 0.9953 (B) Phillips-Perron test 統計量 P-value 含有截距項及時間趨勢項 -0.5681 0.9744 含有截距項但無時間趨勢項 -4.8629*** 0.0004 無截距項及時間趨勢項 4.7855 1.0000 (C) Kwiatkowski-Phillips-Schmidt-Shin test 統計量 含有截距項及時間趨勢項 0.2065** 含有截距項但無時間趨勢項 0.6527** 註:*表示 10%顯著水準之下顯著;**表示 5%顯著水準之下顯著;***表示 1%顯著水準之下顯著。 表 4-5 為每人平均國內生產毛額之單根檢定結果,由表中可得知在 10%顯著 水準之下,ADF 檢定之三種模型及 PP 檢定之三種模型中,結果大多顯示不拒絕 資料有單根之虛無假設,意即資料為有單根,也就是說資料為非定態;而 KPSS 檢定之兩種模型中,結果均顯示拒絕資料為定態之虛無假設,意即資料為非定 態。
33
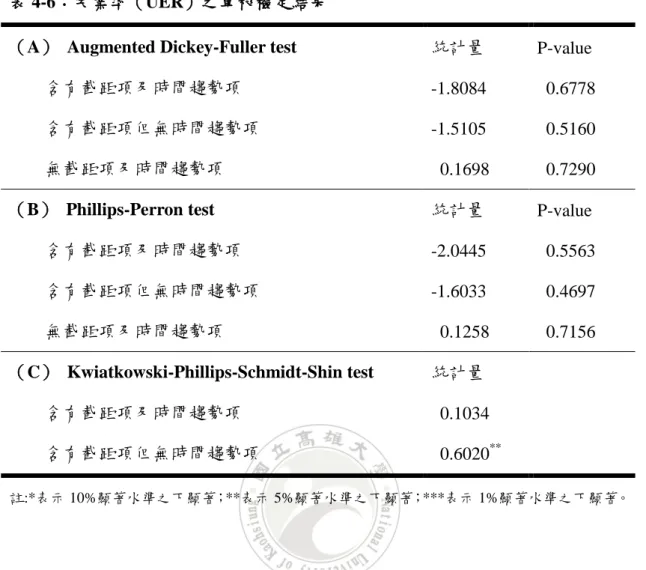
表 4-6:失業率(UER)之單根檢定結果
(A) Augmented Dickey-Fuller test 統計量 P-value 含有截距項及時間趨勢項 -1.8084 0.6778 含有截距項但無時間趨勢項 -1.5105 0.5160 無截距項及時間趨勢項 0.1698 0.7290 (B) Phillips-Perron test 統計量 P-value 含有截距項及時間趨勢項 -2.0445 0.5563 含有截距項但無時間趨勢項 -1.6033 0.4697 無截距項及時間趨勢項 0.1258 0.7156 (C) Kwiatkowski-Phillips-Schmidt-Shin test 統計量 含有截距項及時間趨勢項 0.1034 含有截距項但無時間趨勢項 0.6020** 註:*表示 10%顯著水準之下顯著;**表示 5%顯著水準之下顯著;***表示 1%顯著水準之下顯著。 表 4-6 為失業率之單根檢定結果,由表中可得知在 10%顯著水準之下,ADF 檢定之三種模型及 PP 檢定之三種模型中,結果均顯示不拒絕資料有單根之虛無 假設,意即資料為有單根,也就是說資料為非定態;而 KPSS 檢定之兩種模型中, 結果相反,故資料是否為定態皆有可能。但總結全部的檢定結果,推論資料為非 定態。
34
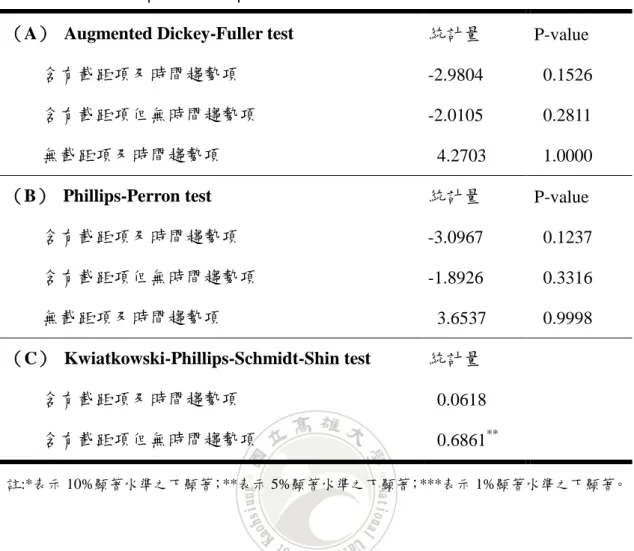
表 4-7:女性工作者占總工作者人數之比例(FEMALE)之單根檢定結果 (A) Augmented Dickey-Fuller test 統計量 P-value 含有截距項及時間趨勢項 -2.9804 0.1526 含有截距項但無時間趨勢項 -2.0105 0.2811 無截距項及時間趨勢項 4.2703 1.0000 (B) Phillips-Perron test 統計量 P-value 含有截距項及時間趨勢項 -3.0967 0.1237 含有截距項但無時間趨勢項 -1.8926 0.3316 無截距項及時間趨勢項 3.6537 0.9998 (C) Kwiatkowski-Phillips-Schmidt-Shin test 統計量 含有截距項及時間趨勢項 0.0618 含有截距項但無時間趨勢項 0.6861** 註:*表示 10%顯著水準之下顯著;**表示 5%顯著水準之下顯著;***表示 1%顯著水準之下顯著。 表 4-7 為女性工作者占總工作者人數之比例之單根檢定結果,由表中可得知 在 10%顯著水準之下,ADF 檢定之三種模型及 PP 檢定之三種模型中,結果均顯 示不拒絕資料有單根之虛無假設,意即資料為有單根,也就是說資料為非定態; 而 KPSS 檢定之兩種模型中,結果相反,故資料是否為定態皆有可能。但總結全 部的檢定結果,推論資料為非定態。
35
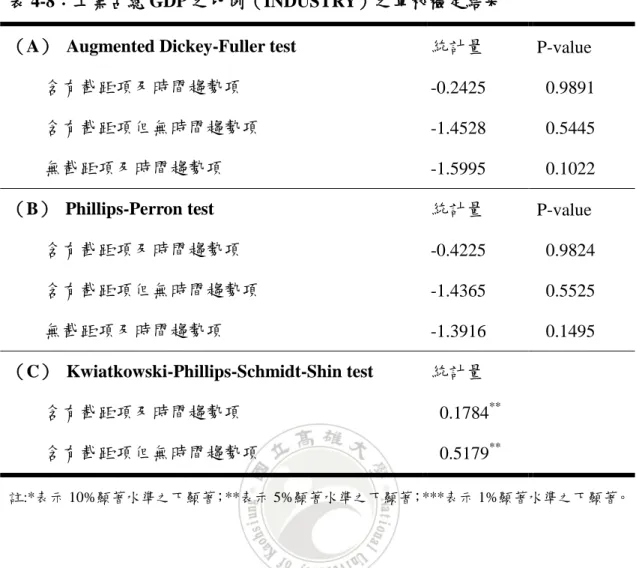
表 4-8:工業占總 GDP 之比例(INDUSTRY)之單根檢定結果
(A) Augmented Dickey-Fuller test 統計量 P-value 含有截距項及時間趨勢項 -0.2425 0.9891 含有截距項但無時間趨勢項 -1.4528 0.5445 無截距項及時間趨勢項 -1.5995 0.1022 (B) Phillips-Perron test 統計量 P-value 含有截距項及時間趨勢項 -0.4225 0.9824 含有截距項但無時間趨勢項 -1.4365 0.5525 無截距項及時間趨勢項 -1.3916 0.1495 (C) Kwiatkowski-Phillips-Schmidt-Shin test 統計量 含有截距項及時間趨勢項 0.1784** 含有截距項但無時間趨勢項 0.5179** 註:*表示 10%顯著水準之下顯著;**表示 5%顯著水準之下顯著;***表示 1%顯著水準之下顯著。 表 4-8 為工業占總 GDP 之比例之單根檢定結果,由表中可得知在 10%顯著 水準之下,ADF 檢定之三種模型及 PP 檢定之三種模型中,結果均顯示不拒絕資 料有單根之虛無假設,意即資料為有單根,也就是說資料為非定態;而 KPSS 檢 定之兩種模型中,結果均顯示拒絕資料為定態之虛無假設,意即資料為非定態。
36
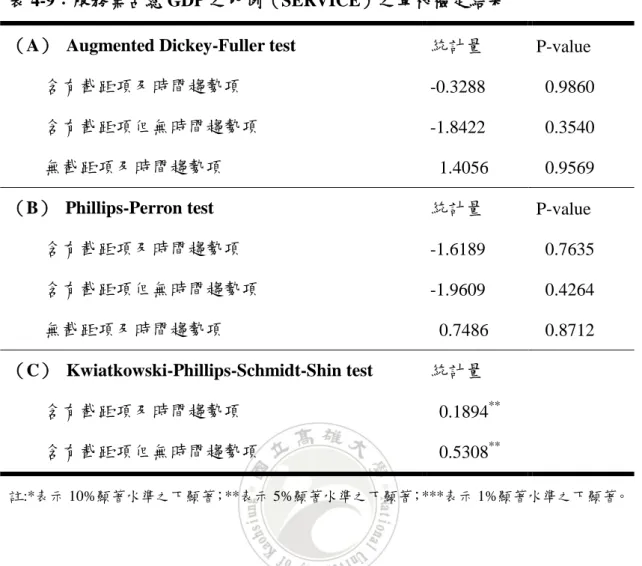
表 4-9:服務業占總 GDP 之比例(SERVICE)之單根檢定結果
(A) Augmented Dickey-Fuller test 統計量 P-value 含有截距項及時間趨勢項 -0.3288 0.9860 含有截距項但無時間趨勢項 -1.8422 0.3540 無截距項及時間趨勢項 1.4056 0.9569 (B) Phillips-Perron test 統計量 P-value 含有截距項及時間趨勢項 -1.6189 0.7635 含有截距項但無時間趨勢項 -1.9609 0.4264 無截距項及時間趨勢項 0.7486 0.8712 (C) Kwiatkowski-Phillips-Schmidt-Shin test 統計量 含有截距項及時間趨勢項 0.1894** 含有截距項但無時間趨勢項 0.5308** 註:*表示 10%顯著水準之下顯著;**表示 5%顯著水準之下顯著;***表示 1%顯著水準之下顯著。 表 4-9 為服務業占總 GDP 之比例之單根檢定結果,由表中可得知在 10%顯 著水準之下,ADF 檢定之三種模型及 PP 檢定之三種模型中,結果均顯示不拒絕 資料有單根之虛無假設,意即資料為有單根,也就是說資料為非定態;而 KPSS 檢定之兩種模型中,結果均顯示拒絕資料為定態之虛無假設,意即資料為非定 態。
37 由以上表格可得知,所有變數的單根檢定檢測出來的結果全部都是存在單根 的,意即資料均為非定態。而前文也有提到,若資料有單根是不能直接分析的, 因其具有隨機趨勢,可能會造成一些問題,而這些問題都會使得迴歸結果模型無 「有效性」,進而做出錯誤的分析。 為了解決本文所採用之時間序列資料存在單根的問題,因此我們將具有單根 的所有數列,包括「吉尼係數、五等分位所得差距倍數、實質有效匯率指數、每 人平均國內生產毛額、失業率、女性工作者占總工作者之比例、工業生產毛額占 GDP 之比例及服務業生產毛額占 GDP 之比例」以上各種變數皆取一階差分,文 獻上通常在變數前面加個 D 表示經過差分之變數,例如 LNREER 取差分後變為 DLNREER,而我們將這些一階差分過後的所有變數再次進行單根檢定。 所有一階差分後之變數的單根檢定結果如下表 4-10 至表 4-17:
38
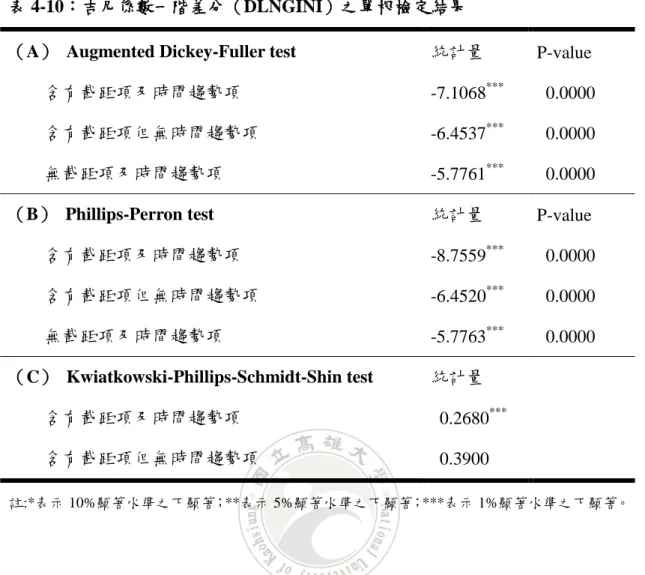
表 4-10:吉尼係數一階差分(DLNGINI)之單根檢定結果
(A) Augmented Dickey-Fuller test 統計量 P-value 含有截距項及時間趨勢項 -7.1068*** 0.0000 含有截距項但無時間趨勢項 -6.4537*** 0.0000 無截距項及時間趨勢項 -5.7761*** 0.0000 (B) Phillips-Perron test 統計量 P-value 含有截距項及時間趨勢項 -8.7559*** 0.0000 含有截距項但無時間趨勢項 -6.4520*** 0.0000 無截距項及時間趨勢項 -5.7763*** 0.0000 (C) Kwiatkowski-Phillips-Schmidt-Shin test 統計量 含有截距項及時間趨勢項 0.2680*** 含有截距項但無時間趨勢項 0.3900 註:*表示 10%顯著水準之下顯著;**表示 5%顯著水準之下顯著;***表示 1%顯著水準之下顯著。 表 4-10 為吉尼係數一階差分之單根檢定結果,由表中可得知在 1%顯著水準 之下,ADF 檢定之三種模型及 PP 檢定之三種模型中,結果均顯示拒絕資料有單 根之虛無假設,意即資料沒有單根,也就是說資料為定態;而 KPSS 檢定之兩種 模型中,結果相反,故資料是否為定態皆有可能。但總結全部的檢定結果,顯示 資料為定態之檢定結果較多,故推論資料為定態。
39
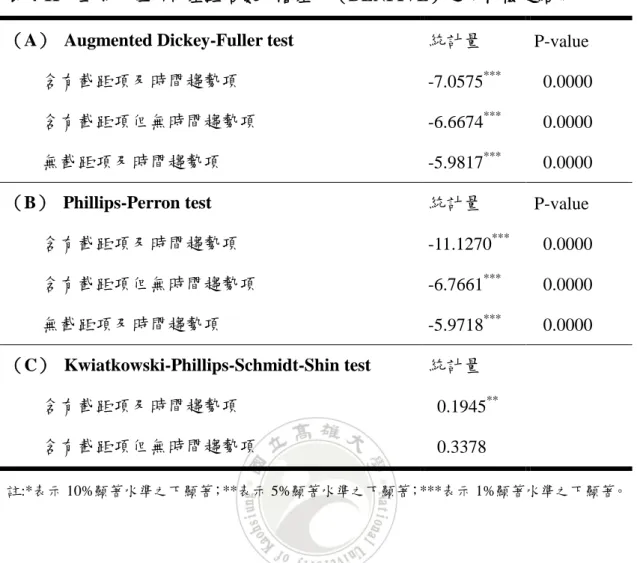
表 4-11:五等分位所得差距倍數一階差分(DLNFIVE)之單根檢定結果 (A) Augmented Dickey-Fuller test 統計量 P-value 含有截距項及時間趨勢項 -7.0575*** 0.0000 含有截距項但無時間趨勢項 -6.6674*** 0.0000 無截距項及時間趨勢項 -5.9817*** 0.0000 (B) Phillips-Perron test 統計量 P-value 含有截距項及時間趨勢項 -11.1270*** 0.0000 含有截距項但無時間趨勢項 -6.7661*** 0.0000 無截距項及時間趨勢項 -5.9718*** 0.0000 (C) Kwiatkowski-Phillips-Schmidt-Shin test 統計量 含有截距項及時間趨勢項 0.1945** 含有截距項但無時間趨勢項 0.3378 註:*表示 10%顯著水準之下顯著;**表示 5%顯著水準之下顯著;***表示 1%顯著水準之下顯著。 表 4-11 為五等分位所得差距倍數一階差分之單根檢定結果,由表中可得知 在 1%顯著水準之下,ADF 檢定之三種模型及 PP 檢定之三種模型中,結果均顯 示拒絕資料有單根之虛無假設,意即資料沒有單根,也就是說資料為定態;而 KPSS 檢定之兩種模型中,結果相反,故資料是否為定態皆有可能。但總結全部 的檢定結果,顯示資料為定態之檢定結果較多,故推論資料為定態。
40
表 4-12:實質有效匯率指數一階差分(DLNREER)之單根檢定結果 (A) Augmented Dickey-Fuller test 統計量 P-value 含有截距項及時間趨勢項 -5.7578*** 0.0002 含有截距項但無時間趨勢項 -5.8549*** 0.0000 無截距項及時間趨勢項 -5.7647*** 0.0000 (B) Phillips-Perron test 統計量 P-value 含有截距項及時間趨勢項 -5.8615*** 0.0002 含有截距項但無時間趨勢項 -5.9854*** 0.0000 無截距項及時間趨勢項 -5.8034*** 0.0000 (C) Kwiatkowski-Phillips-Schmidt-Shin test 統計量 含有截距項及時間趨勢項 0.1148 含有截距項但無時間趨勢項 0.1133 註:*表示 10%顯著水準之下顯著;**表示 5%顯著水準之下顯著;***表示 1%顯著水準之下顯著。 表 4-12 為實質有效匯率指數一階差分之單根檢定結果,由表中可得知在 1% 顯著水準之下,ADF 檢定之三種模型及 PP 檢定之三種模型中,結果均顯示拒絕 資料有單根之虛無假設,意即資料沒有單根,也就是說資料為定態;而 KPSS 檢 定之兩種模型中,結果均顯示不拒絕資料為定態之虛無假設,意即資料為定態。
41
表 4-13:每人平均國內生產毛額一階差分(DLNGDP)之單根檢定結果 (A) Augmented Dickey-Fuller test 統計量 P-value 含有截距項及時間趨勢項 -5.6609*** 0.0003 含有截距項但無時間趨勢項 -3.4906** 0.0149 無截距項及時間趨勢項 -1.2545 0.1882 (B) Phillips-Perron test 統計量 P-value 含有截距項及時間趨勢項 -5.6649*** 0.0003 含有截距項但無時間趨勢項 -3.7108*** 0.0087 無截距項及時間趨勢項 -1.3858 0.1509 (C) Kwiatkowski-Phillips-Schmidt-Shin test 統計量 含有截距項及時間趨勢項 0.1029 含有截距項但無時間趨勢項 0.5718** 註:*表示 10%顯著水準之下顯著;**表示 5%顯著水準之下顯著;***表示 1%顯著水準之下顯著。 表 4-13 為每人平均國內生產毛額一階差分之單根檢定結果,由表中可得知 在 1%顯著水準之下,ADF 檢定之三種模型及 PP 檢定之三種模型中,結果大多 顯示拒絕資料有單根之虛無假設,意即資料沒有單根,也就是說資料為定態;而 KPSS 檢定之兩種模型中,結果相反,故資料是否為定態皆有可能。但總結全部 的檢定結果,顯示資料為定態之檢定結果較多,故推論資料為定態。
42
表 4-14:失業率一階差分(DUER)之單根檢定結果
(A) Augmented Dickey-Fuller test 統計量 P-value 含有截距項及時間趨勢項 -4.5545*** 0.0051 含有截距項但無時間趨勢項 -4.6373*** 0.0008 無截距項及時間趨勢項 -4.6936*** 0.0000 (B) Phillips-Perron test 統計量 P-value 含有截距項及時間趨勢項 -4.4784*** 0.0061 含有截距項但無時間趨勢項 -4.5923*** 0.0009 無截距項及時間趨勢項 -4.6695*** 0.0000 (C) Kwiatkowski-Phillips-Schmidt-Shin test 統計量 含有截距項及時間趨勢項 0.0906 含有截距項但無時間趨勢項 0.1010 註:*表示 10%顯著水準之下顯著;**表示 5%顯著水準之下顯著;***表示 1%顯著水準之下顯著。 表 4-14 為失業率一階差分之單根檢定結果,由表中可得知在 1%顯著水準之 下,ADF 檢定之三種模型及 PP 檢定之三種模型中,結果均顯示拒絕資料有單根 之虛無假設,意即資料沒有單根,也就是說資料為定態;而 KPSS 檢定之兩種模 型中,結果均顯示不拒絕資料為定態之虛無假設,意即資料為定態。
43
表 4-15:女性工作者占總工作者之比例一階差分(FEMALE)單根檢定結果 (A) Augmented Dickey-Fuller test 統計量 P-value 含有截距項及時間趨勢項 -5.1705*** 0.0011 含有截距項但無時間趨勢項 -4.9499*** 0.0003 無截距項及時間趨勢項 -2.5392** 0.0130 (B) Phillips-Perron test 統計量 P-value 含有截距項及時間趨勢項 -5.2230*** 0.0009 含有截距項但無時間趨勢項 -4.9778*** 0.0003 無截距項及時間趨勢項 -3.5501*** 0.0009 (C) Kwiatkowski-Phillips-Schmidt-Shin test 統計量 含有截距項及時間趨勢項 0.0940 含有截距項但無時間趨勢項 0.1904 註:*表示 10%顯著水準之下顯著;**表示 5%顯著水準之下顯著;***表示 1%顯著水準之下顯著。 表 4-15 為女性工作者占總工作者人數之比例一階差分之單根檢定結果,由 表中可得知在 1%顯著水準之下,ADF 檢定之三種模型及 PP 檢定之三種模型中, 結果均顯示拒絕資料有單根之虛無假設,意即資料沒有單根,也就是說資料為定 態;而 KPSS 檢定之兩種模型中,結果均顯示不拒絕資料為定態之虛無假設,意 即資料為定態。
44
表 4-16:工業占總 GDP 之比例一階差分(DINDUSTRY)之單根檢定結果 (A) Augmented Dickey-Fuller test 統計量 P-value 含有截距項及時間趨勢項 -4.4521*** 0.0065 含有截距項但無時間趨勢項 -4.2345*** 0.0023 無截距項及時間趨勢項 -4.1511*** 0.0001 (B) Phillips-Perron test 統計量 P-value 含有截距項及時間趨勢項 -4.4406*** 0.0067 含有截距項但無時間趨勢項 -4.2233*** 0.0024 無截距項及時間趨勢項 -4.1946*** 0.0001 (C) Kwiatkowski-Phillips-Schmidt-Shin test 統計量 含有截距項及時間趨勢項 0.1297 含有截距項但無時間趨勢項 0.3150 註:*表示 10%顯著水準之下顯著;**表示 5%顯著水準之下顯著;***表示 1%顯著水準之下顯著。 表 4-16 為工業占總 GDP 之比例一階差分之單根檢定結果,由表中可得知在 1%顯著水準之下,ADF 檢定之三種模型及 PP 檢定之三種模型中,結果均顯示 拒絕資料有單根之虛無假設,意即資料沒有單根,也就是說資料為定態;而 KPSS 檢定之兩種模型中,結果均顯示不拒絕資料為定態之虛無假設,意即資料為定 態。
45
表 4-17:服務業占總 GDP 之比例一階差分(DSERVICE)之單根檢定結果 (A) Augmented Dickey-Fuller test 統計量 P-value 含有截距項及時間趨勢項 -7.0749*** 0.0000 含有截距項但無時間趨勢項 -6.4947*** 0.0000 無截距項及時間趨勢項 -6.1125*** 0.0000 (B) Phillips-Perron test 統計量 P-value 含有截距項及時間趨勢項 -9.1560*** 0.0000 含有截距項但無時間趨勢項 -7.8264*** 0.0000 無截距項及時間趨勢項 -8.0725*** 0.0000 (C) Kwiatkowski-Phillips-Schmidt-Shin test 統計量 含有截距項及時間趨勢項 0.0979 含有截距項但無時間趨勢項 0.1815 註:*表示 10%顯著水準之下顯著;**表示 5%顯著水準之下顯著;***表示 1%顯著水準之下顯著。 表 4-17 為服務業占總 GDP 之比例一階差分之單根檢定結果,由表中可得知 在 1%顯著水準之下,ADF 檢定之三種模型及 PP 檢定之三種模型中,結果均顯 示拒絕資料有單根之虛無假設,意即資料沒有單根,也就是說資料為定態;而 KPSS 檢定之兩種模型中,結果均顯示不拒絕資料為定態之虛無假設,意即資料 為定態。
46 而結果顯示,所有一階差分後之變數,包括「吉尼係數、五等分位所得差距 倍數、實質有效匯率指數、每人平均國內生產毛額、失業率、女性工作者占總工 作者之比例、工業生產毛額占 GDP 之比例及服務業生產毛額占 GDP 之比例」以 上各種變數的一階差分,皆拒絕有單根之虛無假設,表示這些一階差分之變數都 沒有單根,亦即所有一階差分後之變數皆為定態,因此可以使用這些資料來分析, 這也是之後本文迴歸模型中之變數。
4.3 共整合檢定結果
由於對初始的各個變數進行單根檢定時,檢測出來結果均有單根,若是此時 直接將變數做迴歸分析,將可能造成虛假迴歸之問題產生,因此進行完單根檢定 若君有單根時,則需要進行共整合檢定,檢查其是否有共整合關係,才能確定迴 歸式不會有虛假迴歸之問題。若有共整合關係,則表示可以把這些變數做線性組 合而成一個定態變數,方能進行分析;但若無共整合關係,則要進一步將變數取 一階差分來分析。 本文採用 Johansen 共整合檢定來檢測迴歸模型中各變數的時間序列資料之 間是否存在一組或多組的共整合關係,共整合檢定結果如下表 4-18: 表 4-18:Johansen 共整合檢定結果𝐻0:有 r 組的共整合關係 Trace test Max-Eigen test None 3.6279 3.6279 At most 1 15.0929** 11.4651* At most 2 18.9504*** 13.8575**
47
表 4-18 為 Johansen 共整合檢定結果,由表中可得知在 10%顯著水準之下, Johansen 共整合檢定之兩種檢定統計量─Trace Statistic 及 Max-Eigen Statistic,在 虛無假設為「有 0 組共整合關係」之下,結果均無法拒絕虛無假設,亦即接受虛 無假設,也就是說這些變數沒有共整合之關係。而在虛無假設為「最多有 1 組共 整合關係」及「最多有 2 組共整合關係」之下,結果均顯示拒絕了虛無假設,意 即這些變數並非有 1 組或 2 組共整合關係。總結以上結果,推論這些資料變數之 間並無共整合之關係。
4.4 迴歸模型分析結果
由於本文的目的主要是探討台灣的實質匯率對於所得不均情況的影響,因此 建構了實證迴歸模型,希望可以藉此來分析結果。而本文對於所得不均程度之衡 量指標有兩種,分別為「吉尼係數」和「五等分位所得差距倍數」,以下針對兩 種不同的被解釋變數分別建構四組採用不同解釋變數之模型,所以共有八組模型: Model 1 至 Model 8,而其中 Model 1 至 Model 4 為估計吉尼係數之模型;另外的 Model 5 至 Model 8 為估計五等分位所得差距倍數之模型。吉尼係數迴歸模型之分析結果如下表 4-19,而五等分位所得差距倍數迴歸模 型之分析結果如下表 4-20: